一种基于CPU+MIC的序列模式挖掘方法及流程与流程
本发明涉及数据挖掘,尤其涉及MIC众核协处理器端以及CPU+MIC协同计算模式。
背景技术:
序列模式挖掘可以应用在包括顾客购买行为的分析、网络访问模式分析、科学实验的分析、疾病治疗的早期诊断、自然灾害的预测、DNA 序列的破译等方面。
项目集或称项集:是各种项目组成的集合。设I={i1,i2,…,im}是一个项目集合,事务数据库D={t1,t2,…tn}是由一系列具有惟一标识TID 的事务组成,每个事务ti(i=1,2,…,n) 都对应I上的一个子集。设I1⊆I,项目集I1在D上的支持度(support) 是包含I1的事务在D中,即 support(I1)=||{t∈D|I1⊆t}||/||D||。
序列:I={i1,i2,…,im}是项集,ik(1<=k<=m)是一个项,序列S记为S=<s1,s2,…,sn>其中sj(1<=j<=n)为项集),即sj⊆I,每个元素由不同项组成,序列的元素可表示为(i1,i2,…,ik), 若一个序列只有一个项,则括号可以省略。
子序列:序列T=<ti1, ti2,…,tim>是另一个序列S=<s1,s2,…,sn>的子序列,满足下面条件:对于每一个j,1<=j<=m-1, 有ij<ij+1i且对于每一个j,1<=j<=m存在1<=k<=n,使得tij ⊆sk。即序列S包含序列T。称T为S的子序列,S为T的超序列。
序列模式挖掘:就是找出数据库中所有的序列模式,即那些在序列集合中出现频率超过最小支持度(用户指定最小支持度阀值)的子序列。基本过程就是首先利用客户标识作为关键字进行排序;然后利用关联规则挖掘算法找出所有的频繁项目集;接着在已经转换的客户序列中,每一个事务被包含于该事物中的所大项目集来替换;最后利用核心算法找出所有的序列模式。
MIC(Many Integrated Core):是Intel公司推出的众核处理器,跟通用的多核至强处理器相比,MIC众核架构具有更小的内核和硬件线程,众核处理器计算资源密度更高,片上通信开销显著降低,更多的晶体管和能量,能够胜任更为复杂的并行应用。Intel MIC产品基于X86架构,基于重核的众核处理器,包含50个以上的核心,以及512bit的向量位宽,双精性能超过1TFlops。
MIC拥有极其灵活的编程方式,MIC卡可以作为一个协处理器存在,也可以被看作是一个独立的节点。基本的MIC编程模型是将MIC看作一个协处理器,CPU根据程序的指令,将一部分代码运行在MIC端。此时存在两类设备,即CPU端和MIC众核协处理器端。
但是,目前还没有一种能快速有效地序列模式挖掘的技术来提高用户的操作体验。
技术实现要素:
本发明针对在序列模式挖掘中计算复杂度过大的问题,为此,本发明提供一种基于CPU+MIC的序列模式挖掘方法及流程,它具有实现整个系统效率大幅提升,并解决传统CPU计算方法以及系统应用的性能低下、生产效率低等问题优点。
为了实现上述目的,本发明采用如下技术方案。
一种基于CPU+MIC的序列模式挖掘方法,CPU端负责序列数据,然后对序列数据进行分块,优化负载均衡,向MIC卡传递数据,CPU+MIC协同计算模式的框架搭建以及任务调度和参数初始化工作。
进一步地,且在整个序列挖掘的计算任务CPU以openmp多线程模式。
MIC众核协处理器负责多线程并行地使用序列模式挖掘算法查找发现每个并行区图数据中的频繁项集。在MIC卡上也采用openmp多线程的方式来运算。
进一步地,CPU负责CPU+MIC协同计算模式的框架搭建以及任务调度。
基于CPU+MIC的序列模式挖掘流程,包括:
S1、输入大项集阶段转换后的序列数据库,进行大项集阶段处理。
S2、对序列进行挖掘,首先生产新的候选者。然后对数据库中的每一个顾客序列进行候选者统计,接着得到满足最小支持度的候选者。直至循环结束,则挖掘过程结束。基于CPU+MIC的协同并行计算模式,该过程分成N段进行并行处理,利用多线程技术处理。
本发明的有益效果:本发明提高了并行挖掘的效率,根据数据流的特点,基于MIC协同计算模式,本发明MIC协同计算并行计算结构, 基于序列模式挖掘并行计算方法发现当前序列数据的频繁项集,这样大大提高了处理速度。
附图说明
图1是获取当前并行线程内频繁项集流程图。
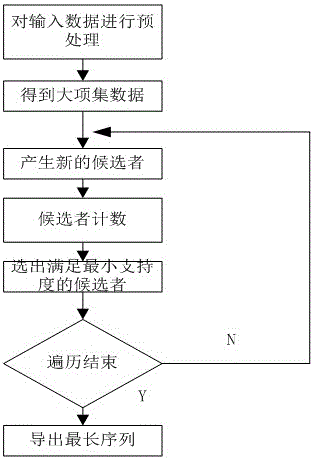
图2是基于CPU+MIC的算法流程图。
具体实施方式
下面结合附图与实施例对本发明作进一步说明。
单节点服务器采用由双路6核CPU和2块KNF MIC卡组成的桌面服务器。在CPU+MIC协同计算中,我们把双路CPU和MIC卡都作为计算设备,这样每个单节点就相当于有3个计算设备,每个设备通过一个OpenMP线程进行控制。假设单节点上,MIC卡的总数为M个(本项目采用每个节点2块MIC卡),则节点上共M+1个设备。
根据图1的序列模式挖掘及流程。
第一步输入: 输入大项集阶段转换后的序列数据库,进行大项集阶段处理。
第二步序列挖掘:对序列进行挖掘,首先生产新的候选者。然后对数据库中的每一个顾客序列进行候选者统计,接着得到满足最小支持度的候选者。直至循环结束,则挖掘过程结束。
在此,考虑到序列挖掘的加速需求,基于CPU+MIC的协同并行计算模式,该过程分成N段进行并行处理,利用多线程技术,增加了线程和内存开销,大大提高了运行速度,减少执行时间。
对于每个并行区子图数据,基于MPI并行计算模型,使用多线程技术,进行并行计算处理,完成第一层并行计算,算法流程如图2所示。
上述虽然结合附图对本发明的具体实施方式进行了描述,但并非对本发明保护范围的限制,所属领域技术人员应该明白,在本发明的技术方案的基础上,本领域技术人员不需要付出创造性劳动即可做出的各种修改或变形仍在本发明的保护范围以内。
- 还没有人留言评论。精彩留言会获得点赞!