图片标注方法及装置与流程
本发明涉及互联网技术领域,尤其涉及一种图片标注方法及装置。
背景技术:
随着互联网及智能终端的普及,互联网上的图片数据越来越多也越来越丰富。如何有效利用互联网图片数据,并通过对这些图片数据的采集处理形成训练样本,来完成相关机器学习及深度学习任务成为当前一个重要的问题。
目前,为了形成训练模型的样本通常采用做法是寻找网上已经开源可用的图片数据集直接使用,或者自己去拍照搜集相关图片数据,然后对这些数据进行逐一筛选审核,最后生成可用来训练的数据集合。
显然,上述方法存在数据类型相对单一,收集速度缓慢,数据量小,处理周期过长等问题。
技术实现要素:
针对现有形成训练模型的样本的方法存在数据类型单一,收集速度缓慢,数据量小,成本过高,处理周期过长等问题的缺陷,本发明提出如下技术方案:
本发明一方面提供了一种图片标注方法,包括:
根据目标任务需求获取互联网图片数据;
对获取的互联网图片数据进行数据清洗;
根据清洗后的互联网图片数据进行图片标注,并接收图片标注后对应的完成结果;
根据所述完成结果生成标注数据集。
可选地,所述根据目标任务需求获取互联网图片数据,包括:
通过预设通用数据资源平台或目标类别的垂直类网站获取所述互联网图片数据。
可选地,所述方法还包括:
获取所述互联网图片数据时,通过预设相同图片及相似图片检索算法将抓取的互联网图片数据与本地已存储的图片数据进行比对;
根据比对结果对重复的图片数据进行丢弃,以及,对未出现在本地的图片资源进行下载入库操作。
可选地,所述对获取的互联网图片数据进行数据清洗,包括:
利用计算机视觉和深度学习处理技术,对保存的互联网图片数据从内容和语义级别进行数据清洗,以滤除不符合预设要求的图片数据。
可选地,所述利用计算机视觉和深度学习处理技术,对保存的互联网图片数据从内容和语义级别进行数据清洗,包括:
识别所述互联网图片中的物体,并根据识别出的内容对所述互联网图片打标签,以根据打标签的结果滤除不符合预设要求的图片数据;
识别所述互联网图片的内容,并生成描述所述互联网图片的内容的短语,以根据短语生成的结果滤除不符合预设要求的图片数据;
检测所述互联网图片中的物体的显著性水平,滤除完全无显著性特征的图片;
检测所述互联网图片中出现的实体个数,滤除实体个数大于预设数量的图片。
可选地,所述检测所述互联网图片中的物体的显著性水平,包括:
分析所述互联网图片中像素点的亮度、对比度指标,并根据像素的梯度值和统计学原理确定所述互联网图片的显著性区域。
可选地,所述根据清洗后的互联网图片数据进行图片标注,包括:
根据清洗后的互联网图片数据生成标注候选数据集合,并根据所述标注候选数据集合确定当前待标注任务;
根据预设标注系统后台任务分配算法,将所述当前待标注任务按照预设指标进行标注。
可选地,所述根据所述标注任务的完成结果生成标注数据集之前,所述方法还包括:
审核所述标注任务的完成结果;
相应地,在审核成功后,根据所述标注任务的完成结果生成标注数据集。
另一方面,本发明还提供了一种图片标注装置,包括:
图片获取单元,用于根据目标任务需求获取互联网图片数据;
图片清洗单元,用于对获取的互联网图片数据进行数据清洗;
图片标注单元,用于根据清洗后的互联网图片数据进行图片标注,并接收图片标注后对应的完成结果;
数据集生成单元,用于根据所述标注任务的完成结果生成标注数据集。
可选地,所述图片获取单元具体用于通过预设通用数据资源平台或目标类别的垂直类网站获取所述互联网图片数据。
可选地,所述图片清洗单元具体用于利用计算机视觉和深度学习处理技术,对保存的互联网图片数据从内容和语义级别进行数据清洗,以滤除不符合预设要求的图片数据。
可选地,所述图片清洗单元还用于:
识别所述互联网图片中的物体,并根据识别出的内容对所述互联网图片打标签,以根据打标签的结果滤除不符合预设要求的图片数据;
识别所述互联网图片的内容,并生成描述所述互联网图片的内容的短语,以根据短语生成的结果滤除不符合预设要求的图片数据;
检测所述互联网图片中的物体的显著性水平,滤除完全无显著性特征的图片;
检测所述互联网图片中出现的实体个数,滤除实体个数大于预设数量的图片。
可选地,所述图片标注单元具体用于根据清洗后的互联网图片数据生成标注候选数据集合,并根据所述标注候选数据集合确定当前待标注任务;以及,
根据预设标注系统后台任务分配算法,将所述当前待标注任务按照预设指标进行标注。
本发明的图片标注方法及装置,通过根据目标任务需求获取互联网图片数据,并对获取的互联网图片数据进行数据清洗,根据清洗后的互联网图片数据进行图片标注,并接收图片标注后对应的完成结果,以根据所述完成结果生成标注数据集,可以提高标注数据的数量、质量及标注速度,达到快速、低成本产出高质量数据标注结果的目的,可为后续模型训练提供有效训练数据集合。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明一个实施例的图片标注方法的流程示意图;
图2为本发明一个实施例的清洗互联网图片数据方法的流程示意图;
图3为本发明一个实施例的抓取并保存互联网图片数据方法的流程示意图;
图4为本发明另一个实施例的美食图片标注方法的流程示意图;
图5为本发明一个实施例的图片标注装置的结构示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
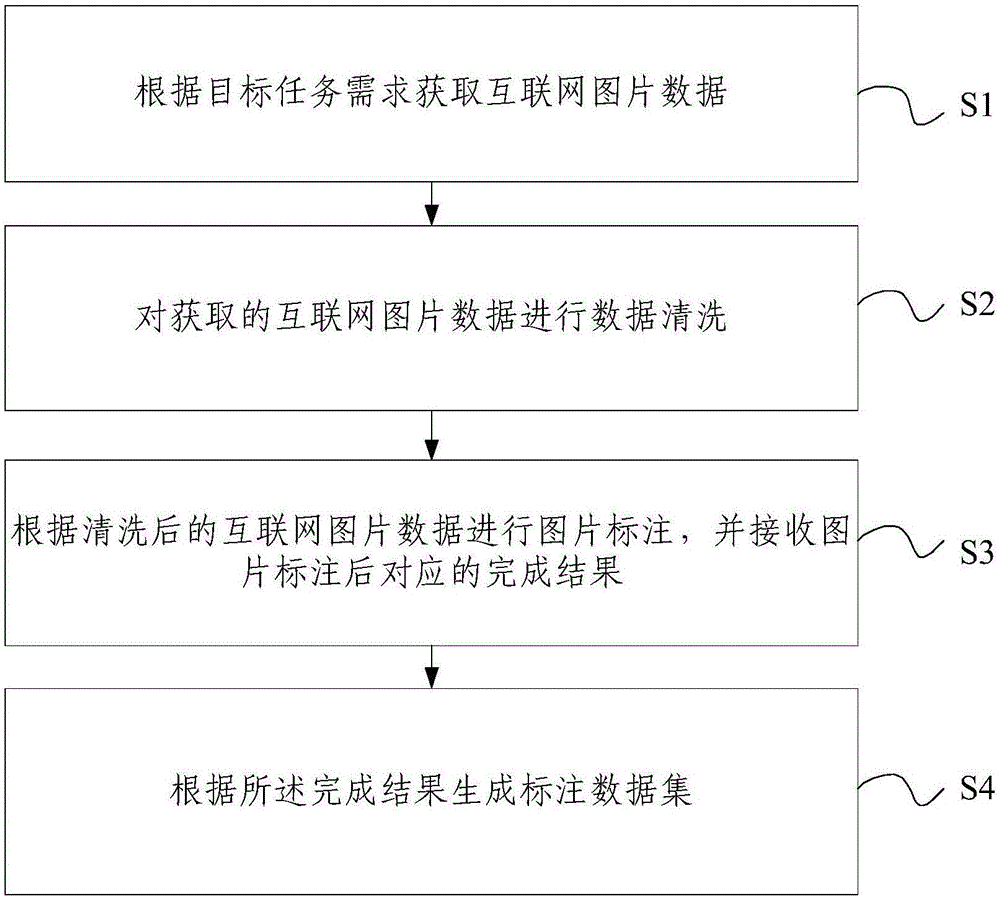
图1为本发明一个实施例的图片标注方法的流程示意图;如图1所示,该方法包括:
S1:根据目标任务需求获取互联网图片数据;
作为本实施例的优选,本步骤中可以通过预设通用数据资源平台或目标类别的垂直类网站获取所述互联网图片数据。
具体来说,本步骤中通过标注需求确定所需实体的大致范畴,明确需要查找的数据源;具体地,可将互联网图片数据的资源搜索查找分为两个方向:一是通过在预设通用数据资源平台(比如在百度、bing等图片搜素引擎)中搜索相关实体关键字,并获取通用检索结果;二是通过查找相关实体类别的垂直类网站(Vertical website)或资源,并从候选垂直类网站内选取已结构化好的图片数据及相关文字数据。
需要说明的是,所述的实体是对具有真实形态或结构,且能够为人们所感知与亲手接触的物体更抽象的统称。举例来说,实体可以指人,如教师、学生等,也可以指物,如书、仓库等客观对象,还可以指抽象的事件,如演出、足球赛等,还可以指事物与事物之间的的联系,如学生选课、客户订货等;
所述的结构化好的图片数据是指含有分类类别信息及相关属性信息的图片,例如,一张蛋糕的图片,如果在垂类站中将它显示在了巧克力类-慕斯子类下,而且有制作原料及工艺,那么这张图片就有一个层级的分类结构并且有制作属性信息。
S2:对获取的互联网图片数据进行数据清洗;
具体来说,当完成图片数据获取的步骤后,需要对图片数据进行清洗。
可以理解的是,根据对数据需求的不同,可采用的数据清洗方法也很多,传统的方式利用互联网图片的周边文本信息(例如包含图片的网页中的网页的标题、内容描述的副标题、图片的配文说明以及图片的上下文文本)辅助确定图片内容,并根据所需标注的实体名称对图片数据进行过滤。
上述做法存在的问题是:一、利用纯文字对图片进行过滤可能存在将有效图片滤除的问题;二、利用这种方式保留的文本相关的图片,从内容上看有可能是完全不相关的。
针对上述传统的数据清洗方式存在的问题,步骤S2所述所述对获取的互联网图片数据进行数据清洗,可以包括:
S2’:利用计算机视觉和深度学习处理技术,对保存的互联网图片数据从内容和语义级别进行数据清洗,以滤除不符合预设要求的图片数据;
举例来说,图2示出了本发明一个实施例的清洗互联网图片数据方法的流程,如图2所示,本步骤S2’具体可以包括:
S21’:图片识别,利用深度学习技术识别图片中的物体并对其打标签,本步骤中取top5的预测结果,根据标签的概率值,滤除50%以上不属于所需实体类别的图片;
需要说明的是,上述top5的预测结果即是指对当前图片所属标签的所有预测标签结果的概率打分进行排序,并取前5个,业界一般公认top5的结果可信度比较高。
S22’:图片语义理解,利用深度学习技术识别图片内容,结果用短语描述(即利用深度学习算法生成用于描述图片内容的短语),并提取其中的top3的预测结果,根据短语描述内容滤除文字中100%未出现实体名及所属网页周边文本的图片;
S23’:图片显著性检测,检测图片中物体的显著性水平,滤除完全无显著性特征的图片,即认为该图片中没有有效的实体存在,无有效的图片信息可用;
作为本实施例的优选,本步骤中可以利用现有的计算机视觉处理算法(如saliency detection算法),通过分析图片中像素点的亮度、对比度等指标,利用像素的梯度值和统计学原理计算出来或者说预测出来图片中哪一部分区域看起来更显著,即通过人类视觉一眼看去最吸引人。
S24’:图片实体个数检测,检测图片中出现的实体个数,滤除实体个数大于5个图片,降低后续标注任务的复杂度,减轻标注的工作量;
具体地,本步骤利用深度学习技术,可以统计出图片中大致含有的实体个数,其原理类似基于深度学习的图片分类方法,将含有不同实体个数的图片划分成大类,然后预测新的图片属于哪个类别。比如,含有1个实体的属于1类;含有2个实体的属于2类等。
S3:根据清洗后的互联网图片数据进行图片标注,并接收图片标注后对应的完成结果;
举例来说,在完成数据清洗之后,即可生成标注候选数据集合,根据预设的标注系统后台任务分配算法将标注候选数据集合作为当前待标注任务,按标注员账户数量及其标注工作量等指标,均等地下发到标注员账户,并接收图片标注后对应的完成结果,同时可以按照完成任务数量、质量进行相关的奖惩。
其中,所述奖惩的内容可以是经验值等,其可以用来兑换实物等奖品。
具体地,本步骤可以包括:
S31:获取预设的标注要求,用于详细描述标注需求,需求包含选取标注正负样本图片作辅助展示;
S32:根据需求进行试验标注,并获取试标数据、统计标注结果及标注员反馈,优化标注需求文字表述;
具体地,可以根据标注员反馈的结果,对标注要求中描述不清或者有歧义的地方做出修改,去除无效或者错误的标注要求,让标注要求和标注方法更清晰、明确。
S33:统计收集标注结果,并智能分配下发标注任务;
S34:获取标注结果的有效确认结果,以根据该确认结果进行奖惩;
举例来说,在批量标注任务中,抽样选取标注图片,接收通过人眼观看标注得到的确认结果,并判断是否标注正确、符合要求,如果抽样集合中98%以上标注符合要求,则认为是ok的,通过标注。这里需要说明的是,人眼观看的标注结果是一个统计结果,即每张图片会重复的找奇数个标注员来标注,比如3个或者5个,以5个为例,按照他们标注的结果选取3:2,4:1,5:0的结果为正确,剩余为错误的原则把标注结果赋予标注图片,通过人眼观看的标注结果既是此统计值
S35:对有效的批量标注结果进行确认,并根据该确认结果进行奖惩;
S4:根据所述完成结果生成标注数据集。
可以理解的是,数据处理任务的多样性使得数据标注任务同样存在多样性。本步骤可以采用预先定义的标注模板导入待标注图片提供给标注员账户,标注任务发起者也可以根据需求自定义标注模板完成特定任务的数据标注,该模板会保存在模板库中,使得以后的类似标注工作有规范的流程。
本实施例的图片标注方法,通过根据目标任务需求获取互联网图片数据,并对获取的互联网图片数据进行数据清洗,根据清洗后的互联网图片数据进行图片标注,并接收图片标注后对应的完成结果,以根据所述完成结果生成标注数据集,可以提高标注数据的数量、质量及标注速度,达到快速、低成本产出高质量数据标注结果的目的,可为后续模型训练提供有效训练数据集合。
进一步地,作为上述方法实施例的优选,步骤S1中所述根据目标任务需求获取互联网图片数据,还可以包括:
S1’:通过网络爬虫技术对所述互联网图片数据进行抓取并保存;
作为本实施例的优选,本步骤中可以通过预设相同图片及相似图片检索算法将抓取的互联网图片数据与本地已存储的图片数据进行比对;并根据比对结果对重复的图片数据进行丢弃,以及,对未出现在本地的图片资源进行下载入库操作。
具体来说,在选定需要抓取下载的图片数据资源后,可利用网络爬虫等抓取工具及手段对该互联网数据进行获取;由于互联网图片数据量大,可能存在对很多已下载图片数据进行重复下载的情况,不但占用带宽流量而且重复存储会造成占用额外存储空间的问题。针对该问题,本步骤通过利用相同图片及相似图片检索算法进行本地及互联网图片数据资源的比对,以实现对重复的数据丢弃,以及对未出现在本地库中的图片资源进行下载入库操作。具体地,图3示出了本发明一个实施例的抓取并保存互联网图片数据方法的流程,如图3所示,本步骤具体可以包括:
S11’:对已下载及标注的数据建立数据库,并保存相关图片的信息,例如来源、属性(宽高,格式,size大小,exif信息等)以及该图片的用于相似及相同图片搜索的唯一编码;
S12’:针对需要获取的图片数据的url链接,查找数据库中具有相同url链接的数据,并使用数据库中保存的有效的图片数据;
S13’:对数据库中找不到相应url,不存在的数据进行下载,利用预设编码算法(如一致性哈希算法、加密哈希算法、MD5/SHA1/SHA256算法等)生成图片唯一编码,与数据库中图片数据的编码进行比较,比较方式为:
若下载图片的编码50%以上与库中某张图片编码一致,则认为该数据为相似图片;
若100%一致,则认为是相同图片;
其中,相似图片是指对原始图片做过裁剪、旋转、添加文字以及缩放等简易的图片操作;相同图片是指完全一样的图片。
S14’:根据最终筛选出的结果建立数据库,并保存相关图片的信息。
下面以美食识别的实施例来说明本发明,但不限定本发明的保护范围。
美食识别是根据图片中出现的菜品样式,来推测其菜品名称的过程。图4示出了本发明另一个实施例的美食图片标注方法的流程,如图4所示,该方法包括:
A1:根据美食识别需求,获取互联网图片数据;
举例来说,上述需求指需要找到美食名称及大量跟名称对应的相关美食图片数据,且每种美食的图片数据量需要达到几百条以上。
根据上述需求,可以先从一些网站上查找并筛选出一批美食名称列表(实体列表),然后用该列表中的美食去通用图片搜索引擎(如百度,bing等)中搜索相关实体关键字;然后观察检索结果数据质量。如果该菜品美食的外观形态比较一致且数据量大,则可认为是符合要求的候选数据资源;
还可以在互联网上搜索一些垂直类美食网站(如下厨房,美食杰等),在站内查找美食实体名称及图片资源和文字数据,根据垂直站内的数据质量及相关文字数据结构化程度高低来筛选站点,进而筛选美食列表中的具体类别。
A2:利用HBase(开源的非关系型分布式数据库,NoSQL)预先建立图片数据库,用于对下载及标注的数据进行存储,保存图片来源url、宽高、尺寸、格式以及哈希编码等信息。
在选择好需要抓取下载的美食图片数据资源后,利用网络爬虫(web crawler)等抓取工具及手段对搜索引擎结果及美食垂直站内图片数据进行获取,具体步骤包括:
A21:抓取图片url链接,并查找数据库中具有相同url链接的数据,如果查到匹配数据则使用有效的图片数据;
A22:对数据库中不存在的url数据进行下载,利用哈希算法生成图片唯一编码,与图片数据库中图片数据的哈希编码进行比较:
若下载图片的编码有50%以上与数据库中某张图片哈希编码一致认为该数据为相似图片;
若100%一致则认为是相同图片。
其中,相似图片是指对原始图片做过裁剪、旋转、添加文字或缩放等简易的图片操作;相同图片是指,完全一样的图片。
A23:对符合上述条件的图片进行丢弃处理,对最终筛选的剩余结果进行写入图片数据库操作。
A3:当完成美食图片数据下载及预处理筛选的步骤后,需要对美食图片数据进行清洗,具体包括:
A31:图片识别,利用深度学习技术识别图片中的物体并对其打粗分类标签,本步骤中取top5的预测结果,根据粗分类标签的概率值,滤除50%以上不属于所需粗分类类别中的图片;
A32:图片语义理解,利用深度学习技术识别图片内容,并用短语描述,本步骤中取top3的预测结果,根据短语描述内容,滤除文字中100%未出现美食菜品名称及美食图片周边文本的图片;
A33:图片显著性检测,检测抓取图片中物体的显著性水平,滤除完全无显著性特征的图片,即该图片中没有有效的实体存在,无有效的图片信息可用;
A34:图片实体个数检测,检测图片中出现的实体个数,滤除实体个数大于5个图片,降低后续标注任务的复杂度,减轻标注的工作量;
A4:数据清洗之后,生成美食标注候选数据集合,该集合的内容是有一个美食列表及列表中每种美食对应的图片数据集合。
本步骤中预先建立了标注系统用来筛选标注数据,该系统具有用户操作界面及后台管理界面,可供管理员利用任务分配算法从后台管理界面分配任务供标注标注数据,以将当前待标注任务按标注数量及其标注工作量等指标,均等地下发到标注员账户,并按照完成任务数量,质量进行相关的奖惩,具体包括:
A41:获取预设的美食标注要求,用于详细描述标注需求,需求包含选取标注正负样本图片作辅助展示;
A42:根据需求进行试验标注,并获取试标数据、统计标注结果及标注员反馈,优化标注需求文字表述;
A43:统计收集标注结果,并智能分配下发标注任务;
A44:对标注结果进行检查及审核,确定标注结果有效性;
A45:获取标注结果的有效确认结果,以根据该确认结果进行奖惩;
A5:根据标注结果生成标注数据集;
具体来说,数据处理任务的多样性使得数据标注任务同样存在多样性。本步骤可以采用预先定义的标注模板导入待标注图片提供给标注员账户,标注任务发起者也可以根据需求自定义标注模板完成特定任务的数据标注,该模板会保存在模板库中,使得以后的类似标注工作有规范的流程。
图5为本发明一个实施例的图片标注装置的结构示意图,如图5所示,该装置包括:图片获取单元10、图片清洗单元20、图片标注单元30以及数据集生成单元40,其中:
图片获取单元10用于根据目标任务需求获取互联网图片数据;
作为本实施例的优选,图片获取单元10可以通过预设通用数据资源平台或目标类别的垂直类网站获取所述互联网图片数据。
具体地,可将互联网图片数据的资源搜索查找分为两个方向:一是通过在预设通用数据资源平台(比如在百度、bing等图片搜素引擎)中搜索相关实体关键字,并获取通用检索结果;二是通过查找相关实体类别的垂直类网站(Vertical website)或资源,并从候选垂直类网站内选取已结构化好的图片数据及相关文字数据。
图片清洗单元20用于对获取的互联网图片数据进行数据清洗;
进一步地,作为上述装置实施例的优选,所述图片清洗单元20可以具体用于利用计算机视觉和深度学习处理技术,对保存的互联网图片数据从内容和语义级别进行数据清洗,以滤除不符合预设要求的图片数据。
作为一种可选地实施方式,所述图片清洗单元20可以用于识别所述互联网图片中的物体,并根据识别出的内容对所述互联网图片打标签,以根据打标签的结果滤除不符合预设要求的图片数据;
例如,利用深度学习技术识别图片中的物体并对其打标签,本步骤中取top5的预测结果,根据标签的概率值,滤除50%以上不属于所需实体类别的图片;
进一步地,所述图片清洗单元20还可以用于识别所述互联网图片的内容,并生成描述所述互联网图片的内容的短语,以根据短语生成的结果滤除不符合预设要求的图片数据;
例如,利用深度学习技术识别图片内容,结果用短语描述(即利用深度学习算法生成用于描述图片内容的短语),并提取其中的top3的预测结果,根据短语描述内容滤除文字中100%未出现实体名及所属网页周边文本的图片;
进一步地,所述图片清洗单元20还可以用于检测所述互联网图片中的物体的显著性水平,滤除完全无显著性特征的图片;
例如,利用深度学习技术识别图片内容,结果用短语描述(即利用深度学习算法生成用于描述图片内容的短语),并提取其中的top3的预测结果,根据短语描述内容滤除文字中100%未出现实体名及所属网页周边文本的图片;
进一步地,所述图片清洗单元20还可以用于检测所述互联网图片中出现的实体个数,滤除实体个数大于预设数量的图片。
例如,检测图片中出现的实体个数,滤除实体个数大于5个图片,降低后续标注任务的复杂度,减轻标注的工作量;
图片标注单元30用于根据清洗后的互联网图片数据进行图片标注,并接收图片标注后对应的完成结果;
进一步地,作为本实施例的优选,所述图片标注单元30还可以具体用于根据清洗后的互联网图片数据生成标注候选数据集合,并根据所述标注候选数据集合确定当前待标注任务;以及,
根据预设标注系统后台任务分配算法,将所述当前待标注任务按照预设指标进行标注。
具体地,在完成数据清洗之后,即可生成标注候选数据集合,根据预设的标注系统后台任务分配算法将标注候选数据集合作为当前待标注任务,按标注员账户数量及其标注工作量等指标,均等地下发到标注员账户,并接收图片标注后对应的完成结果,同时可以按照完成任务数量、质量进行相关的奖惩。
其中,所述奖惩的内容可以是经验值等,其可以用来兑换实物等奖品。
数据集生成单元40用于根据所述标注任务的完成结果生成标注数据集。
进一步地,作为上述装置实施例的优选,所述装置还包括结果审核单元,其可以用于审核所述标注任务的完成结果;
相应地,在审核成功后,所述数据集生成单元40还可用于根据所述标注任务的完成结果生成标注数据集。
本实施例的图片标注装置,通过根据目标任务需求获取互联网图片数据,并对获取的互联网图片数据进行数据清洗,根据清洗后的互联网图片数据进行图片标注,并接收图片标注后对应的完成结果,以根据所述完成结果生成标注数据集,可以提高标注数据的数量、质量及标注速度,达到快速、低成本产出高质量数据标注结果的目的,可为后续模型训练提供有效训练数据集合。
需要说明的是,对于装置实施例而言,由于其与方法实施例基本相似,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
以上实施例仅用于说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!