一种基于多特征融合的网络学术报告分类方法与流程
本发明属于基于机器学习的文本分类技术领域,主要涉及一种基于多特征融合的学术报告预告分类方法。
背景技术:
学术报告有助于开拓视野和知识面并获得前沿研究信息,学术报告的内容通常是报告者的最新研究成果,有助于科技工作者了解学科的最新研究进展情况,还可以藉此途径获得跨学科的知识,通过当面聆听这一形式,还可能获取到专家的知识思维,有助于科技工作者开启自己固有的直觉能力,也可以借助环境气氛来开启自己这种天赋固有的直觉能力。
另外,随着科技工作者的不断增多,他们对最新科技的渴望也是逐渐增加的,但是又没有太多的时间去挑选需要关注的学术报告,这就需要我们事先进行学术报告的分类,然后对这些科技工作者进行推荐和推送,能极大的减少占用做科研的时间。然而网上学术报告信息量巨大,如果通过人工分类的方法,费时费力,无法进行及时的推荐和推送。进行简单的机器学习的方法进行推荐和推送又浪费了学术报告能提供的众多信息,分类准确度也得不到很好的保障。
目前,进行短文本分类的方法主要分为三大类:
1.人工分类
2.利用机器学习的方法进行分类
3.融合机器学习的方法以及数据包含的其他信息进行融合分类。
利用人工进行分类的方法很简单,但是只适合在数据量极其小的情况下,人工分类需要投入大量的人力和精力,而且需要专业的人士参与,否则准确率不会很高,该方法实用性差。利用机器学习的方法进行分类适合那些文本中不包含对分类有帮助的信息的情况下,目前使用机器学习进行文本分类的方法很多,但是始终达不到较高的准确率。融合机器学习的各种方法并且在其基础上加入文本中包含的其他有用特征进行融合分类,但是仍然无法满足实际分类精度要求。
技术实现要素:
本发明是为了避免现有技术存在的不足之处,提出一种基于多特征融合的网络学术报告分类方法,以期充分利用学术报告中包含的各种特征,并且结合多种机器学习的算法,以实现学术报告分类的最大准确率,从而保证实际应用的分类准确率。
本发明为解决技术问题采用如下技术方案:
本发明一种基于多特征融合的网络学术报告分类方法的特点是按如下步骤进行:
步骤1、收集并建立学术报告数据库;
步骤1.1、利用爬虫工具收集网络学术报告的信息并作为相应条目,所述网络学术报告的信息包括:报告标题、报告时间、报告地点、报告人、报告人简介、报告简介和报告举办单位;
步骤1.2、添加学术报告所属的学科分类信息的条目,从而建立学术报告数据库;
步骤2、获得第一匹配结果集合;
步骤2.1、收集并建立学院名称集合及其包含的各个学科名称集合;
步骤2.2、将所述报告举办单位与所述学院名称集合中的各个学院进行匹配,从而获得第一匹配结果集合;所述第一匹配结果集合为所述报告举办单位所对应的学院所包含的所有学科;
步骤3、获得第二匹配结果集合;
步骤3.1、收集并建立研究人员集合及其对应的研究领域集合;
步骤3.2、将所述报告人与所述研究人员集合中的各个研究人员姓名进行匹配,从而获得第二匹配结果集合;所述第二匹配结果集合为所述报告人所属的研究领域;
步骤4、利用中文关键词提取算法对所述报告标题进行提取,获得所述报告标题的关键词;
步骤5、使用同义词扩展算法对所提取的关键词进行同义词扩展,得到所述关键词的近义词特征集合;
步骤6、使用SVM分类器对所述关键词及其近义词特征集合进行文本分类,得到第一分类结果;所述第一分类结果为所述关键词及其近义词所对应的第一学科集合;所述第一学科集合中包含各个学科名称及其相应的概率;
步骤7、使用朴素贝叶斯分类器NB对所述关键词及其近义词特征集合进行文本分类,得到第二分类结果;所述第二分类结果为所述关键词及其近义词所对应的第二学科集合;所述第二学科集合中包含各个学科名称及其相应的概率;
步骤8、得到初步分类结果集合;
步骤8.1、从所述第一分类结果和第二分类结果分别选出概率最高的前2个学科所对应的概率,分别记为第一SVM概率和第二SVM概率、第一NB概率和第二NB概率;
步骤8.2、设置一个置信度值C;
步骤8.3、判断第一SVM概率和第二SVM概率之差≥置信度值C是否成立,若成立,则表将所述第一SVM概率所对应的学科作为第一初步分类结果;否则,则将所述第一SVM概率和第二SVM概率所对应的学科作为第一初步分类结果;
步骤8.4、判断第一NB概率和第二NB概率之差≥置信度值C是否成立,若成立,则表将所述第一NB概率所对应的学科作为第二初步分类结果;否则,则将所述第一NB概率和第二NB概率所对应的学科作为第二初步分类结果;
步骤8.5、将所述第一初步分类结果和第二初步分类结果取并集,得到初步分类结果集合;
步骤9、得到最终分类结果
步骤9.1、为所述第一匹配结果集合、第二匹配结果集合和初步分类结果集合设定相应的权重,记为A、B、C;
步骤9.2、将所述第一匹配结果集合、第二匹配结果集合和初步分类结果集合取并集,得到综合分类结果集合;
步骤9.3、统计所述综合分类结果集合中的每个学科分别在所述第一匹配结果集合、第二匹配结果集合和初步分类结果集合中相应权重的总和;
步骤9.4、以权重的总和最高的学科作为所述网络学术报告的最终分类结果并用于预告和推荐。
与现有技术相比,本发明的有益效果在于:
1.本发明充分使用了数据自身包含的信息,将学术报告中报告人和报告单位的匹配结果于用机器学习方法得到的结果进行融合,提高了分类的准确率,保证了实际应用的需求。
2.本发明首先建立研究单位数据库和研究人员数据库,将学术报告中的举办单位以及报告人信息与数据库中的信息进行匹配,得到一系列学术报告人对应的学科以及一系列报告单位对应的学科,解决了数据利用不充分的问题,提高了学术报告数据利用效率。
3.本发明结合了多种传统的机器学习方法,并加入置信度策略,使用支持向量机的分类方法得到分类结果,判断第一概率与第二概率的差值大于置信度是否成立,成立则取第一概率对应的学科,否则取第一概率和第二概率对应的学科,得到支持向量机分类结果;再同样的使用使用朴素贝叶斯的方法进行分类,得到朴素贝叶斯分类结果,将两种分类方法的结果取并集,得到机器学习方法的分类结果,本方法结合了多种机器学习方法的优点,提高了融合分类结果的准确率。
附图说明
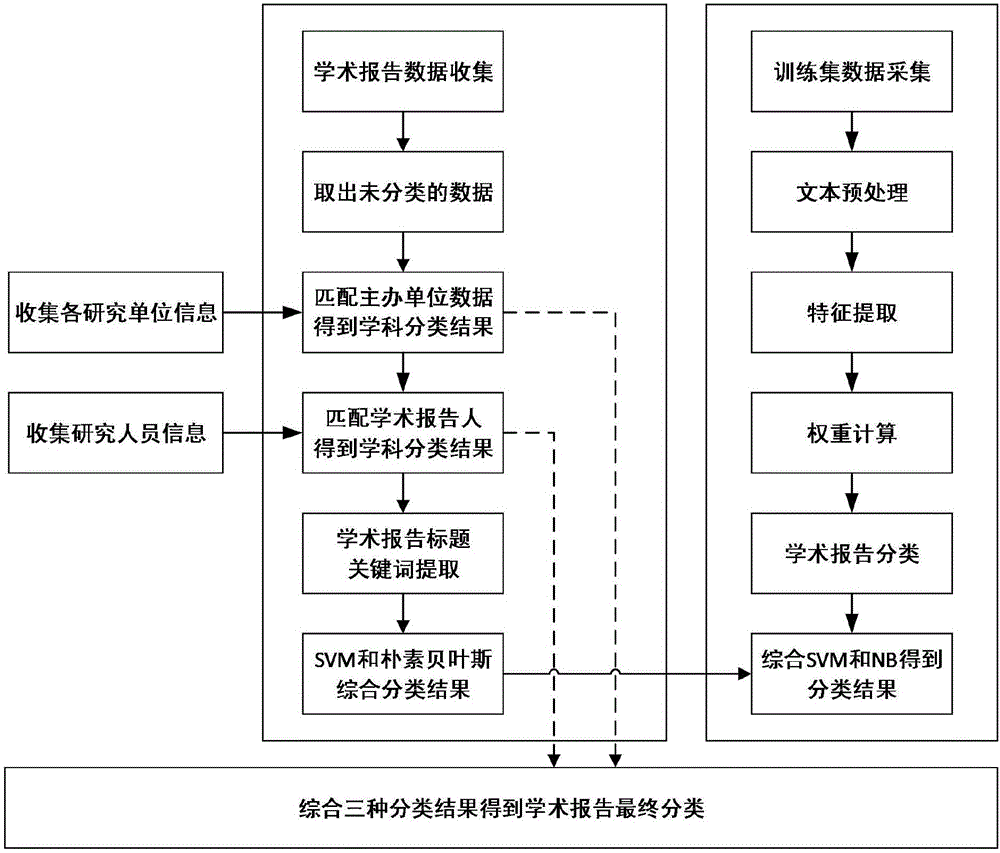
图1为本发明的整体流程图;
图2为本发明多特征融合分类流程图。
具体实施方式
在本实施例中,一种基于多特征融合的网络学术报告分类方法,是通过多因素的方法对学术报告进行分类,其整体流程图如图1所示,并按如下过程进行:
步骤1、收集并建立学术报告数据库;
步骤1.1、利用爬虫工具收集网络学术报告的信息并作为相应条目,网络学术报告的信息包括:报告标题、报告时间、报告地点、报告人、报告人简介、报告简介和报告举办单位;
步骤1.2、添加学术报告所属的学科分类信息的条目,从而建立学术报告数据库;
步骤2、获得第一匹配结果集合;
步骤2.1、收集并建立学院名称集合及其包含的各个学科名称集合;
步骤2.2、将报告举办单位与学院名称集合中的各个学院进行匹配,从而获得第一匹配结果集合;第一匹配结果集合为报告举办单位所对应的学院所包含的所有学科;
步骤3、获得第二匹配结果集合;
步骤3.1、收集并建立研究人员集合及其对应的研究领域集合;
步骤3.2、将报告人与研究人员集合中的各个研究人员姓名进行匹配,从而获得第二匹配结果集合;第二匹配结果集合为报告人所属的研究领域;
步骤4、利用中文关键词提取算法对报告标题进行提取,获得报告标题的关键词;
步骤4.1、收集关键词提取的训练集,训练集保存在同一个文件夹中,其中每个文件都是以文本文件的形式存储,总的文件数为D。
步骤4.2、对训练集中所有的文本文件进行分词处理,并且使用一个字典记录每个词出现的次数。
步骤4.3、遍历字典中的每个词,计算每个词在所有文本文件中出现的词频的总和,这样得到每个词的词频TF;同时也计算每个词在文本文件中出现的次数,在每个文本文件中不管是只出现一次或出现多次,都只是把出现的次数加1,这样得到某个词在文件中出现的次数i,这样可以得到每个词的逆向文件频率IDF的值;
步骤4.4、计算的每个词的TFIDF值即为的TF*IDF,根据得到的TFIDF值的大小进行排序,取出前N1个词作为这一文档的关键词;
步骤4.5、对取出的学术报告的报告标题进行分词处理;
步骤4.6、依次匹配每个词在训练集中的所对应的TFIDF值,取出前N2个词作为当前学术报告标题的关键词。
步骤5、使用同义词扩展算法对所提取的关键词进行同义词扩展,得到所述关键词的近义词特征集合;
步骤6、使用SVM分类器对关键词及其近义词特征集合进行文本分类,得到第一分类结果;第一分类结果为关键词及其近义词所对应的第一学科集合;第一学科集合中包含各个学科名称及其相应的概率;
步骤6.1、首先使用网上提供的论文的数据模型进行训练,首先要进行的是分词,需要对分词的词库进行扩充,添加专业词,分词的结果保存到文件model.seg中。
步骤6.2、加载model.seg文件,进行特征选择,选出比较能代表当前学科的n个词语,存入文件model.temp中,这些词语作为代表当前学科的特征词。
步骤6.3、根据model.temp文件中的内容,计算其中每个词语的权重值,存入model.model文件中。
步骤6.4、从数据库中取出所有未被分类的学术报告的标题,将其存入文件中,存入的名称为每个学术报告存储在数据库中的id,将这些文件统一放在默认的分类名称的文件夹中。
步骤6.5、使用步骤6.1中添加了专业词汇的分词工具对这些学术报告的标题进行分词,存入test.seg文件夹中。
步骤6.6、使用步骤4中的方法进行同义词扩展,得到当前词汇的一系列描述,将这些描述加入到特征中作为当前特征的扩展。
步骤6.7、计算得到的这些词语的权重值,存入文件test.model文件中。
步骤6.8、加载model.model文件,使用SVM工具对当前的test.model文件进行测试,得到的测试结果即为当前test文件的分类结果,将结果存入test.result文件中,存入文件每行为一个记录,每个记录的格式为当前文件的路径+制表符+所属分类id。
步骤6.9、按行读取test.result文件,分割出文件路径和所属分类id,从文件路径中得到当前的学术报告在数据库中的id。
步骤7、使用朴素贝叶斯分类器NB对关键词及其近义词特征集合进行文本分类,得到第二分类结果;第二分类结果为关键词及其近义词所对应的第二学科集合;第二学科集合中包含各个学科名称及其相应的概率;
步骤8、得到初步分类结果集合;
步骤8.1、从第一分类结果和第二分类结果分别选出概率最高的前2个学科所对应的概率,分别记为第一SVM概率和第二SVM概率、第一NB概率和第二NB概率;
步骤8.2、设置一个置信度值C;
步骤8.3、判断第一SVM概率和第二SVM概率之差≥置信度值C是否成立,若成立,则表将第一SVM概率所对应的学科作为第一初步分类结果;否则,则将所述第一SVM概率和第二SVM概率所对应的学科作为第一初步分类结果;
步骤8.4、判断第一NB概率和第二NB概率之差≥置信度值C是否成立,若成立,则表将第一NB概率所对应的学科作为第二初步分类结果;否则,则将第一NB概率和第二NB概率所对应的学科作为第二初步分类结果;
步骤8.5、将第一初步分类结果和第二初步分类结果取并集,得到初步分类结果集合;
步骤9、得到最终分类结果,如图2所示;
步骤9.1、为第一匹配结果集合、第二匹配结果集合和初步分类结果集合设定相应的权重,记为A、B、C;
步骤9.2、将第一匹配结果集合、第二匹配结果集合和初步分类结果集合取并集,得到综合分类结果集合;
步骤9.3、统计综合分类结果集合中的每个学科分别在第一匹配结果集合、第二匹配结果集合和初步分类结果集合中相应权重的总和;
步骤9.4、以权重的总和最高的学科作为网络学术报告的最终分类结果并用于预告和推荐。
- 还没有人留言评论。精彩留言会获得点赞!