对话模式分析系统及方法与流程
所揭露的实施例是关于对话模式分析系统及方法,更具体而言,是关于可用以解析连续型对话的对话模式分析系统及方法。
背景技术:
现有传统的自然语言处理技术中,往往透过语料库及语言学建构句法树进行自然语言内容的解析。由于建构句法树必须透过文法正确性且结构的完整的文句,因此所使用的语料库大多为句法结构完整的文章。然而在现今社群对话中,句法往往不完整且对话为两位或以上用户的聊天纪录,由传统语料库训练所得的模型其成效不彰。
因此,如何改善现有的自然语言分析方式,以适用于现今社群对话的特性进行语言内容解析,为目前本研究领域的重要议题。
技术实现要素:
所揭露的实施例是提供对话模式分析系统及方法。
该对话模式分析方法包含透过一处理器接收至少一对话数据,该对话数据包含依照时间排序的多个对话语句;透过该处理器对所述多个对话语句中出现的多个字词建构向量字词分群,以取得所述多个字词间的一字词排列顺序;透过该处理器分析所述多个对话语句中出现的所述多个字词,以根据该字词排列顺序取得一基本对话模式矩阵;透过该处理器将该基本对话模式矩阵进行模糊匹配,以根据该基本对话模式矩阵取得一对话模式矩阵;透过该处理器根据该对话模式矩阵侦测一对话主题趋势,以判断该对话数据的主题;以及透过该处理器将相应于该对话数据的该对话模式矩阵与该对话主题趋势输出至一数据库中。
该对话模式分析系统包含:一储存装置,配置以储存一数据库以及一计算机可执行指令,其中该数据库用以储存多个对话数据以及所述多个对话数据各自的一对话模式矩阵与一对话主题趋势,其中所述多个对话数据每一者分别包含依照时间排序的多个对话语句;以及一处理器,电性耦接于该储存装置,该处理器配置以执行该计算机可执行指令,以执行一对话模式分析方法,该对话模式分析方法包含:透过该处理器自该数据库接收所述多个对话数据的其中一者;透过该处理器对该对话数据中的所述多个对话语句中出现的多个字词建构向量字词分群,以取得所述多个字词间的一字词排列顺序;透过该处理器分析所述多个对话语句中出现的所述多个字词,以根据该字词排列顺序取得一基本对话模式矩阵;透过该处理器将该基本对话模式矩阵进行模糊匹配,以根据该基本对话模式矩阵取得该对话模式矩阵;透过该处理器根据该对话模式矩阵侦测该对话主题趋势,以判断该对话数据的主题;以及透过该处理器将相应于该对话数据的该对话模式矩阵与该对话主题趋势输出至该数据库中。
综上所述,本案透过解读对话纪录,预测后续对话内容,挖掘购物前潜在买家,以进行精准行销。此外,对话模式分析系统亦可以应用对话引擎,简化购物中复杂流程,透过与购物系统的自然对话方式实现极简购物,亦可以透析对话意涵及主题趋势的解析,协助购物后的重复问答,实现智能问答客服服务。
附图说明
图1为根据本揭示内容部分实施例所绘示的一种对话模式分析系统的示意图;
图2A为根据本揭示内容部分实施例所绘示的对话模式分析方法的流程图;
图2B为根据本揭示内容部分实施例所绘示的对话模式分析方法其中步骤的细部流程图;
图3A为根据本揭示内容部分实施例所绘示的原始字词矩阵的示意图;
图3B为根据本揭示内容部分实施例所绘示的水平共现矩阵的示意图;
图3C为根据本揭示内容部分实施例所绘示的垂直共现矩阵的示意图;
图3D为根据本揭示内容部分实施例所绘示的总和共现关联矩阵的示意图;
图4A为根据本揭示内容部分实施例所绘示的基本对话模式矩阵的示意图;
图4B为根据本揭示内容部分实施例所绘示的对话模式矩阵的示意图;
图5为根据本案部分实施例所绘示的待测对话模式矩阵的示意图。
具体实施方式
下文是举实施例配合所附附图作详细说明,以更好地理解本案的态样,但所提供的实施例并非用以限制本揭露所涵盖的范围,而结构操作的描述非用以限制其执行的顺序,任何由元件重新组合的结构,所产生具有均等功效的装置,皆为本揭露所涵盖的范围。此外,根据业界的标准及惯常做法,附图仅以辅助说明为目的,并未依照原尺寸作图,实际上各种特征的尺寸可任意地增加或减少以便于说明。下述说明中相同元件将以相同的符号标示来进行说明以便于理解。
在全篇说明书与权利要求书所使用的用词(terms),除有特别注明外,通常具有每个用词使用在此领域中、在此揭露的内容中与特殊内容中的平常意义。某些用以描述本揭露的用词将于下或在此说明书的别处讨论,以提供本领域技术人员在有关本揭露的描述上额外的引导。
此外,在本文中所使用的用词“包含”、“包括”、“具有”、“含有”等等,均为开放性的用语,即意指“包含但不限于”。此外,本文中所使用的“及/或”,包含相关列举项目中一或多个项目的任意一个以及其所有组合。
于本文中,当一元件被称为“连接”或“耦接”时,可指“电性连接”或“电性耦接”。“连接”或“耦接”亦可用以表示二或多个元件间相互搭配操作或互动。此外,虽然本文中使用“第一”、“第二”、…等用语描述不同元件,该用语仅是用以区别以相同技术用语描述的元件或操作。除非上下文清楚指明,否则该用语并非特别指称或暗示次序或顺位,亦非用以限定本发明。
请参考图1。图1为根据本揭示内容部分实施例所绘示的一种对话模式分析系统100的示意图。如图1所示,在部分实施例中,对话模式分析系统100包含储存装置120以及处理器140。
具体来说,储存装置120配置以储存数据库122以及计算机可执行指令CMD。数据库122用以储存多个对话数据D1~Dn以及对话数据D1~Dn各自的对话模式矩阵与对话主题趋势。具体来说,对话数据D1~Dn每一者分别包含依照时间排序的多个对话语句,其相应的具体操作将在后续段落中搭配附图进行详细说明。
此外,如图1所示,在部分实施例中,对话模式分析系统100更用以连接至使用者界面UI,使得使用者可根据对话模式分析系统100进行的分析执行后续操作。举例来说,使用者可利用对话模式分析系统100对社群网站、网络讨论区、留言板、即时通讯系统等等不同数字平台上的对话主题进行分析,并将分析结果用于购物前针对不同消费者的精准行销、购物过程中的简化购物流程,或是购物后的智能问答客服等等,以透过解析连续对话的语意内容实现上述操作的简化或是自动化。在部分实施例中,使用者界面UI可包含网页、应用程序(App)或是包含对话引擎的其他界面等等各种形式,但本揭示内容并不以此为限。
在部分实施例中,处理器140电性耦接于储存装置120。处理器140配置以执行储存装置120内所储存的计算机可执行指令CMD,以执行一对话模式分析方法。具体来说,处理器140依据计算机可执行指令CMD执行对话模式分析方法时,是透过处理器140中数据收集模块141、向量字词分群模块143、对话样式探勘建模模块145、趋势侦测样式比对模块147的协同操作实现针对对话模式的分析。
借此,处理器140便可将数据训练和数据解析所需或是所得的模型和数据储存于数据库122中,以透过数据库122与使用者界面200进行互动。为便于说明起见,以下段落将以实施例配合附图,针对处理器140透过数据收集模块141、向量字词分群模块143、对话样式探勘建模模块145、趋势侦测样式比对模块147执行对话模式分析方法的步骤进行详细说明。
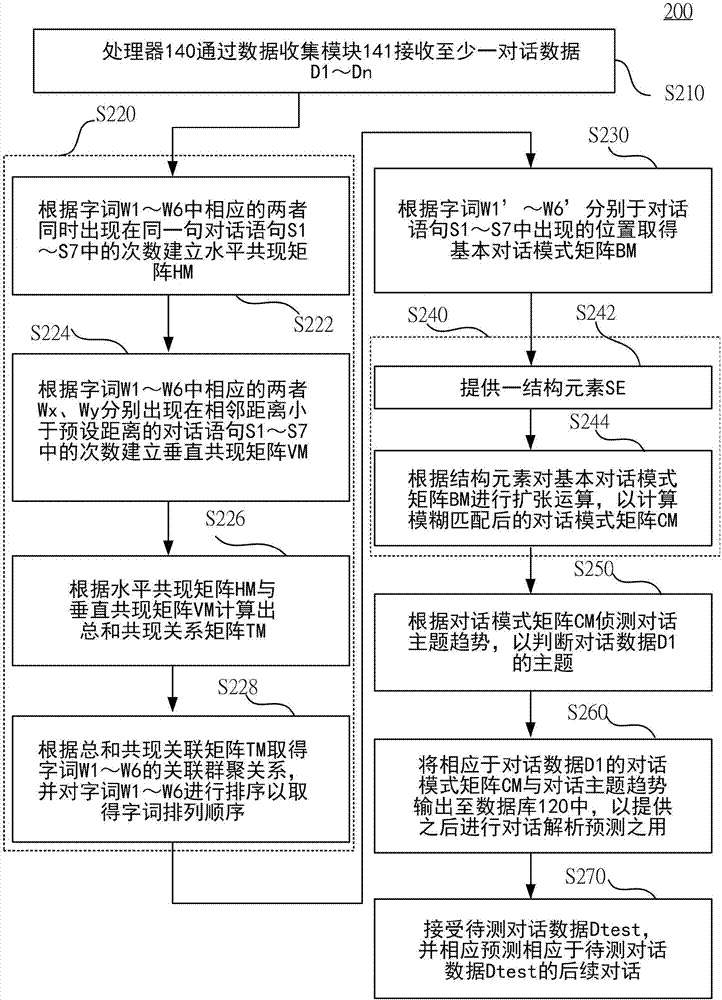
请一并参考图2A与图2B。图2A为根据本揭示内容部分实施例所绘示的对话模式分析方法200的流程图。图2B为根据本揭示内容部分实施例所绘示的对话模式分析方法200的步骤S270的细部流程图。为方便及清楚说明起见,图2A、图2B中所述的对话模式分析方法200是配合图1所示的对话模式分析系统100进行说明,但不以此为限,任何熟悉此技艺者,在不脱离本案的精神和范围内,当可对其作各种更动与润饰。
如图2A所示,在部分实施例中,对话模式分析方法200包含步骤S210、S220、S230、S240、S250、S260以及S270。
首先,在步骤S210中,处理器140透过数据收集模块141接收至少一对话数据D1~Dn。具体来说,对话模式分析系统100可自电子布告栏、讨论区和各个社群网站上搜集社群对话的内容作为对话数据D1~Dn。如先前段落所述,对话数据D1~Dn每一者(如:对话数据D1)包含依照时间排序的多个对话语句S1~Sm,其中对话语句S1~Sm可为同一个对话讨论串中依时序的对话内容。
举例来说,在某个社群网站中针对化妆品进行讨论的讨论串中,数据收集模块141搜集到的对话语句S1~S7依序分别为“甲品牌饰底乳这罐珠光不知道会不会太强烈”、“甲品牌没有控油喔,纯粹就是增加光泽,想要控油就选乙品牌”、“甲品牌还是有控油的效果吧?但不是主打”、“乙品牌主要是治粉刺啦”、“甲品牌感觉没有很控油耶”、“乙品牌控油效果真的很好,而且不会爆粉刺”、“乙品牌的饰底乳效果最好,会不会粉刺看个人”等七个针对不同品牌的功能和效果所进行的对话单句。
在部分实施例中,数据收集模块141可针对搜集到的对话语句S1~S7进行字库建构,以取得对话语句S1~S7中出现的字词W1~Wx。举例来说,数据收集模块141可将搜集到的对话内容进行断词,以断词内容作为字库。在部分实施例中,数据收集模块141更可将断词后内容去除一些常用字词,如“的”、“我”一类的常见字后,将剩下的字词作为字库。此外,在其他部分实施例中,数据收集模块141亦可根据特定领域搜集特定用字及领域中惯用字,再搭配社群对话内容的字词作为字库。
举例来说,根据上述对话语句S1~S7,数据收集模块141可选择六个字词W1~W6以建立字库,其中字词W1~W6分别为“甲品牌”、“控油”、“乙品牌”、“粉刺”、“饰底乳”、“效果”。
接着,在步骤S220中,处理器140透过向量字词分群模块143对上述对话语句S1~S7中出现的字词W1~W6建构向量字词分群,以取得字词W1~W6间的字词排列顺序。
具体来说,在将自然语言的句子转换成向量方式表示的过程中,不同字词群聚与排列顺序会影响后续的比对分析。因此,在步骤S220中,向量字词分群模块143可取得字词W1~W6间的字词排列顺序,以利后续操作。
在部分实施例中,步骤S220中取得字词W1~W8间的字词排列顺序的步骤可进一步细分为步骤S222、S224、S226、S228。
在步骤S222中,向量字词分群模块143根据字词W1~W6中相应的两者同时出现在同一句对话语句S1~S7中的次数建立水平共现矩阵HM。
请一并参考图3A与图3B,其中图3A为根据本揭示内容部分实施例所绘示的原始字词矩阵OM的示意图,图3B为根据本揭示内容部分实施例所绘示的水平共现矩阵HM的示意图。如图3A所示,分别根据对话语句S1~S7中是否出现相应的字词W1~W6,便可取得原始字词矩阵OM,其中OM(x,y)的值若为1,表示对话语句Sx中出现了字词Wy。举例来说,对话语句S1“甲品牌饰底乳这罐珠光不知道会不会太强烈”中出现了字词W1“甲品牌”、字词W5“饰底乳”,因此OM(1,1)与OM(1,5)的值为1,该行其余的OM(1,2)、OM(1,3)、OM(1,4)与OM(1,6)则为0,其余行以此类推,于此不再赘述。
如图3B所示,在水平共现矩阵HM中,HM(x,y)的值代表字词W1~W6中相应的两者Wx、Wy同时出现在同一句对话语句S1~S7中的次数。举例来说,字词W1“甲品牌”、字词W2“控油”同时出现在对话语句S2、S3、S5这三句话中,因此HM(1,2)的值为3。相似地,字词W1“甲品牌”、字词W3“乙品牌”只同时出现在对话语句S2这一句话中,因此HM(1,3)的值为1,其余以此类推,于此不再赘述。
借此,向量字词分群模块143便可建立水平共现矩阵HM,以代表字词W1~W6是否容易出现在同一句话当中,以评价字词W1~W6之间的关联程度。
接着,在步骤S224中,向量字词分群模块143根据字词W1~W6中相应的两者Wx、Wy分别出现在相邻距离小于预设距离的对话语句S1~S7中的次数建立垂直共现矩阵VM。请一并参考图3C,图3C为根据本揭示内容部分实施例所绘示的垂直共现矩阵VM的示意图。
和水平共现矩阵HM相比,垂直共现矩阵VM代表的是整体对话过程中沿特定方向的一定距离内的不同句子之间,字词W1~W6是否容易在前后文中接连出现,以评价字词W1~W6之间的关联程度。举例来说,上述距离可根据实际需求设定为1句话、2句话或是其他任意数值。
换言的,VM(x,y)代表的是字词Wx、Wy在同一段话中沿特定方向的一定距离内的不同句子中共同出现的次数。
举例来说,在部分实施例中,特定方向可设定为往下、预设距离可设定为1句话。如此一来,由于相邻的对话语句S1与S2中分别出现了字词W1“甲品牌”、字词W2“控油”,而相邻的对话语句S2与S3中,先是在对话语句S2出现了字词W1“甲品牌”,对话语句S3出现了字词W2“控油”,又在对话语句S2出现了字词W2“控油”,对话语句S3出现了字词W1“甲品牌”,最后在相邻的对话语句S5与S6中分别出现了字词W1“甲品牌”、字词W2“控油”,因此字词W1、W2在对话语句S1~S7中沿下方的距离1以内的不同句子中共同出现的次数为四次,因此VM(1,2)的值为4。
相似地,由于字词W4“粉刺”和字词W5“饰底乳”仅在相邻的对话语句S6与S7出现一次,因此VM(4,5)的值为1,其余以此类推,于此不再赘述。
如此一来,向量字词分群模块143便可根据水平共现矩阵HM与垂直共现矩阵VM计算各个字词W1~W6之间各关联程度。
具体来说,在步骤S226中,向量字词分群模块143根据水平共现矩阵HM与垂直共现矩阵VM计算出总和共现关联矩阵TM。
请一并参考图3D,其中图3D为根据本揭示内容部分实施例所绘示的总和共现关联矩阵TM的示意图。
在部分实施例中,向量字词分群模块143可分别将水平共现矩阵HM与垂直共现矩阵VM乘上各自的比重,再将两者相加以计算出总和共现关联矩阵TM。在图3D所示实施例中,向量字词分群模块143设定两者的比重皆为1以计算总和共现关联矩阵TM,但本案并不以此为限,水平共现矩阵HM与垂直共现矩阵VM各自的比重可根据实际需求进行调整。
最后,在步骤S228中,根据总和共现关联矩阵TM取得各个字词W1~W6的向量后,向量字词分群模块143便可通过各种分群演算法,根据总和共现关联矩阵TM取得字词W1~W6的关联群聚关系,并对字词W1~W6进行排序以取得字词排列顺序。
举例来说,在部分实施例中,分群演算法可根据总和共现关联矩阵TM将字词W1~W6分为两群,其中字词W1、W2、W3、W6为一群,字词W4、W5为一群。接着,可分别将群内字词W1、W2、W3、W6作为完全图中的顶点,使用最短汉米尔顿路径将关联度较高的字词排在邻近位置。相似地,群与群之间亦可根据各群各自的质心作为顶点,使用最短汉米尔顿路径将关联度较高的群排在邻近位置。
如此一来,透过适当演算法处理后,便可取得字词W1~W6的字词排列顺序。举例来说,将关联程度较高的字词排列在邻近位置后,依序可得新排序后的字词W1’“控油”、W2’“乙品牌”、W3’“甲品牌”、W4’“效果”、W5’“粉刺”、W6’“饰底乳”。
接着,在步骤S230中,处理器140透过对话样式探勘建模模块145分析对话语句S1中出现的字词W1’~W6’,以根据字词排列顺序取得基本对话模式矩阵BM。请一并参考图4A,图4A为根据本揭示内容部分实施例所绘示的基本对话模式矩阵BM的示意图。
在部分实施例中,在步骤S230中,对话样式探勘建模模块145将字词W1~W6根据字词排列顺序重新排序为字词W1’~W6’后,根据字词W1’~W6’分别于对话语句S1~S7中出现的位置取得基本对话模式矩阵BM。
如图4A所示,分别根据对话语句S1~S7中是否出现相应的经重新排序后的字词W1’~W6’,便可取得基本对话模式矩阵BM,其中BM(x,y)的值若为1,表示对话语句Sx中出现了字词Wy’。举例来说,对话语句S1“甲品牌饰底乳这罐珠光不知道会不会太强烈”中出现了字词W3’“甲品牌”、字词W6’“饰底乳”,因此OM(1,3)与OM(1,6)的值为1,该行其余的OM(1,1)、OM(1,2)、OM(1,4)与OM(1,5)则为0,其余行以此类推,于此不再赘述。
接着,在步骤S240中,处理器140透过对话样式探勘建模模块145将基本对话模式矩阵BM进行模糊匹配,以根据基本对话模式矩阵BM取得对话模式矩阵CM。请一并参考图4B,图4B为根据本揭示内容部分实施例所绘示的对话模式矩阵CM的示意图。
在部分实施例中,在步骤S240中取得对话模式矩阵CM的步骤进一步包含步骤S242、S244。
在步骤S242中,对话样式探勘建模模块145提供一结构元素SE。接着,在步骤S244中,对话样式探勘建模模块145根据结构元素对基本对话模式矩阵BM进行扩张运算,以计算模糊匹配后的对话模式矩阵CM。
如图4B所示,结构元素SE可为[1,1,1]的垂直向量。在部分实施例中,扩张运算可表示为:
在上式中,为A的镜射并平移z个单位。由于进行对话内容检索时,若采用直接比对方式会有资讯不足的问题,且在对话过程中,前句叙述所使用过的字词在下一句通常会被省略。因此,对话样式探勘建模模块145可针对基本对话模式矩阵BM进行形态学的扩张运算达到模糊匹配,获取更多回复对话的选择性,并取得相应的对话模式矩阵CM。
接着,在步骤S250中,处理器140透过趋势侦测样式比对模块147,根据对话模式矩阵CM侦测对话主题趋势,以判断对话数据D1的主题。举例来说,在部分实施例中,步骤S250包含计算对话模式矩阵CM的质心座标,以根据质心座标判断对话数据D1的对话主题趋势。具体来说,经过上述的关联性字词群聚后,对话模式矩阵CM的质心便可表示上述对话中的互动对话主轴。
此外,在部分实施例中,若是在比较对话样式相似度时,其相应的质心位置迥异,则代表对话主题差异极大。借此,在数据库122中寻找最相似的对话内容时,趋势侦测样式比对模块147可排除质心位置迥异的点,以节省计算量。
举例来说,在部分实施例中,透过质心的比对可以快速比对两段对话内容是否谈论相似的对话主题。借以侦测判断对话主题。另一方面,若一段对话内容包含两个以上的主题时,也可以透过侦测数句对话间质心的偏移程度借以切割不同主题的对话。
具体来说,质心座标可表示为:
其中,m00表示对话模式矩阵CM的零阶动差(Moment),值为1的加总。m10、m01分别为两个维度的一阶离散动差,其公式可表示为:
上式中,对话模式矩阵CM的尺寸为M×N,CM(i,j)表示对话模式矩阵CM于(i,j)位置的值,p、q分别为动差的阶数。
举例来说,根据图4B中所示的对话模式矩阵CM,若左上角定义为位置(0,0),则可分别求出:
m00=35
m10=0×4+1×5+2×5+3×5+4×5+5×6+6×5=110
m01=0×6+1×6+2×6+3×6+4×5+5×4=76
因此,对话模式矩阵CM的质心位置便为(110/35,76/35)。
接着,在步骤S260中,处理器140便可将相应于对话数据D1的对话模式矩阵CM与对话主题趋势(即:质点位置)输出至数据库122中,以提供之后进行对话解析预测之用。
举例来说,在部分实施例中,对话模式分析方法200包含步骤S270。在步骤S270中,对话模式分析系统100接受待测对话数据Dtest,并相应预测相应于待测对话数据Dtest的后续对话。
请一并参考图2B。如图2B所示,具体来说,步骤S270中可包含步骤S272、S274、S276、S278。
在步骤S272中,处理器140透过数据收集模块141接收待测对话数据Dtest,其中待测对话数据Dtest包含依照时间排序的待测对话语句Stest1~Stestm。举例来说,待测对话数据Dtest中的待测对话语句Stest1~Stest4可分别为“请问甲品牌这罐饰底乳好吗?”、“控油效果好的是Sofina,VDL控油不是主打”、“使用上VDL好像没有很控油”、“Sofina控油效果真的很好而且没有爆粉刺的问题”。
接着,在步骤S274中,处理器140透过向量字词分群模块143分析待测对话语句Dtest中出现的字词W1~Wx,以根据字词排列顺序取得待测对话模式矩阵TestM。值得注意的是,根据字词排列顺序取得待测对话模式矩阵TestM的详细步骤与先前段落中所述基本对话模式矩阵BM的取得方式相似,故不再于此赘述。请一并参考图5,图5为根据本案部分实施例所绘示的待测对话模式矩阵TestM的示意图。
接着,在步骤S276中,处理器140透过趋势侦测样式比对模块147计算待测对话模式矩阵TestM与数据库122中的对话模式矩阵BM之间的相似度。
具体来说,在部分实施例中比较两个矩阵B1与B2之间的相似度时,可分别计算B1对于B2的相似度SB1B2以及B2对于B1的相似度SB2B1,并取其平均值作为矩阵B1与B2之间的相似度。相似度SB1B2以及相似度SB2B1可分别透过下式表示:
SB1B2=P(B2(i,j)=1|B1(i,j)=1)
SB2B1=P(B1(i,j)=1|B2(i,j)=1)
在上式中,B1(i,j)与B2(i,j)分别为B1与B2于区块(i,j)位置的值。根据上式,趋势侦测样式比对模块147计算待测对话模式矩阵TestM与数据库122中的对话模式矩阵BM之间的相似度。
值得注意的是,以上采取像素匹配相似度(pixel matching similarity)的计算方式仅为本案中多个实施方式的其中一种释例,并非用以限制本案。本领域具通常知识者亦可透过其他各种相似度或关联性计算方式取得待测对话模式矩阵TestM与对话模式矩阵BM之间的相似度。
最后,在步骤S278中,处理器140透过趋势侦测样式比对模块147,便可根据计算所得的相似度输出相应的对话主题趋势以预测相应于待测对话数据Dtest的后续对话。举例来说,当相似度高于一目标值时,趋势侦测样式比对模块147便可判断待测对话数据Dtest的主题与相关内容与此对话模式矩阵BM接近,并据以输出对话主题趋势或提供相关数据给对话引擎,以输出相应内容至使用者界面200。
如此一来,透过以上步骤S210~S270中各个模块的偕同操作,对话模式分析系统100便可透过收集社群对话后进行字词共现关联分群以建构对话样式区块取代语料库和语言学的方法。接着,再以对话模糊匹配,对话相似样式比对及对话主题趋势侦测等方法进行对话内容及对话主题趋势的解析,并预测后续对话内容。针对每组对话都分别存下样式,提供多样话的对话样式区块,能提供较高准确率。
值得注意的是,虽然本文将所公开的方法示出和描述为一系列的步骤或事件,但是应当理解,所示出的这些步骤或事件的顺序不应解释为限制意义。例如,部分步骤可以以不同顺序发生和/或与除了本文所示和/或所描述的步骤或事件以外的其他步骤或事件同时发生。另外,实施本文所描述的一个或多个态样或实施例时,并非所有于此示出的步骤皆为必需。此外,本文中的一个或多个步骤亦可能在一个或多个分离的步骤和/或阶段中执行。
本案透过应用上述多个实施例,透过解读对话纪录,预测后续对话内容,挖掘购物前潜在买家,以进行精准行销。此外,对话模式分析系统100亦可以应用对话引擎,简化购物中复杂流程,透过与购物系统的自然对话方式实现极简购物,亦可以透析对话意涵及主题趋势的解析,协助购物后的重复问答,实现智能问答客服服务。
虽然本揭示内容已以实施方式揭露如上,然其并非用以限定本揭示内容,任何熟悉此技艺者,在不脱离本揭示内容的精神和范围内,当可作各种更动与润饰,因此本揭示内容的保护范围当视所附的权利要求书所界定的范围为准。
- 还没有人留言评论。精彩留言会获得点赞!