一种基于空间连贯特征的快速任意姿态人脸表情识别方法与流程
本发明属于情感识别领域,具体涉及一种基于空间连贯特征的快速任意姿态人脸表情识别方法及系统。
背景技术:
人脸表情识别是模式识别、人机交互和计算机视觉等领域涉及的重要研究方向,目前已成为国内外的研究热点。一般来说,人类最常见的六种基本表情为高兴、悲伤、愤怒、惊讶、厌恶与恐惧。近年来,随着各种对姿态具有鲁棒性的特征的不断提出,促进了多姿态自动人脸表情识别技术的发展。比如传统的人脸识别模型只能基于正脸或者接近正脸的图片进行表情识别,而对侧脸或者有一定角度的人脸表情识别效果非常差。接着有研究者提出针对不同姿态的人脸图片训练不同的表情识别模型。然而自然环境下姿态的变化是非线性的。即使将其设定为固定的几种姿态,随着姿态的不断增多,模型的训练也是非常耗时的。最近,通过机器学习的方法自动从图像中学习得到对表情识别有用的特征的方法大大的推进了这一领域的发展,但是传统的特征学习方法多是直接基于一张人脸图像学习得到相关特征,而忽略了对表情识别任务有很大贡献的几何特征,从而无法保证任意姿态人脸表情识别的准确率。这就促使了是否可以通过级联特征学习方法所得特征以及几何特征来进行任意姿态人脸表情识别,从而再提高效率的同时得到更好的表情识别的结果的研究。
(1)在S.Eleftheriadi等人,名为“Discriminative Shared Gaussian Processes for Multiview and View-Invariant Facial Expression Recognition”的论文中,利用一种判别式高斯过程隐变量模型进行多姿态的人脸表情识别,但是该方法应用的是传统的手工特征,它对于物体的遮挡,人脸的变形以及姿态的不断变化不具备很好的鲁棒性。(2)在H.Jung等人,名为“Joint Fine-Tuning in Deep Neural Networks for Facial Expression Recognition”的论文中,通过级联卷积神经网络学习得到的人脸特征以及人脸关键区域几何特征的方法得到了不错的表情识别结果,但是该方法在通过卷积神经网络学习特征时是基于一张完整的人脸进行的,这使得其学习得到的结合特征与通过特征学习方法学习得到的特征不具备空间连贯特征,这降低了模型的识别率。
技术实现要素:
为了解决上述问题,本发明通过深度学习的方法进一步拓展了背景技术中论文(2)的方法,通过基于关键区域的无监督特征学习方法得到具有空间连贯特性的特征,进而得到一个可用于任意姿态的统一表情识别模型。实现本发明的技术方案如下:
一种基于空间连贯特征的快速任意姿态人脸表情识别方法,包括如下步骤:
S1,对任意姿态的人脸图像通过姿态归一化方法合成其所对应的正脸图像,然后对合成的正脸图像进行预处理得到统一像素的灰度图像。
S2,对步骤S1所得的灰度图像进行关键区域采样,首先对合成的正脸图像通过特征点定位方法检测得到51个位于眼睛、鼻子、嘴巴、眉毛等对表情贡献较大区域的关键特征点。并以此特征点为中点采样得到尺寸为m×m大小的51个关键区域,对所得的51个关键区域提取尺寸为w×w大小的特征块。
S3,将步骤S2中所得特征块送入无监督特征学习方法自动编码器中进行特征学习,得到图像的底层RGB特征与更具有分辨力的高层特征之间的映射关系,通过权重W以及偏置b来表示。
S4,将步骤S2得到的51个关键区域利用步骤S3的映射关系进行卷积和池化得到高层特征,级联每个关键区域的高层特征与其几何位置特征得到用于表示此关键区域的具有空间关系的特征。级联51个关键区域的特征得到具有空间连贯特性的特征。
S5,将步骤S4所得的具有空间连贯特性的特征送入支持向量机SVM中进行识别模型的训练,得到一个针对任意姿态人脸图像的统一识别模型;
S6,对测试图片经过步骤S1,S2得到51个关键区域,利用步骤S3所述的映射关系,S4所述的特征级联方法以及步骤S5所述的统一识别模型识别出任意姿态人脸图像所属的人脸表情类别。
作为优选技术方案,所述步骤S1中姿态归一化方法的过程包括:给定一张标准正面人脸,通过一个树模型进行特征点定位,然后根据特征点估计投影矩阵,根据投影矩阵合成任意姿态的人脸图像所对应的正脸图像。
作为优选技术方案,所述步骤S1中预处理的过程包括:对合成的正面人脸图像通过二值化方法进行灰度处理得到灰度图像,然后对所得灰度图像进行大小归一化得到统一像素的灰度图像。
作为优选技术方案,所述步骤S2中采样得到51个关键区域的尺寸大小设为19*19,特征块大小设置为8*8。
作为优选技术方案,所述步骤S2中所述51个关键特征点,具体分布如下:其中9个特征点位于鼻子区域,12个特征点位于眼睛区域,10个特征点位于眉毛区域,20个特征点位于嘴巴区域,共计51个特征点。
作为优选技术方案,所述步骤S3中无监督特征学习的过程包括:
步骤S3-1,对正脸图像进行白化处理;
步骤S3-2,基于步骤S2采样得到的关键区域进行特征块提取;
步骤S3-3,基于提取到的特征块训练自动编码器,通过计算输入特征和输出特征之间的重构误差函数得到平均误差值,并以此平均误差反向传播更新各层卷积核,当此平均误差值趋于收敛时,算法停止,得到输入特征和输出特征之间的映射关系,所述映射关系由权重W以及偏置b构成。
作为优选技术方案,所述步骤S3-1中白化处理的过程:
读取正脸图像的像素特征,然后以步长大小为1、特征块大小为8*8对得到的像素特征进行分块处理,然后对每一个小的特征块串联得到一个一维的特征,对此一维的特征均除以其标准差,从而得到具有相同方差的特征。
作为优选技术方案,所述步骤S4中卷积和池化的过程:
用所得权重W以及偏置b对合成的正脸图像以关键区域为单位进行卷积以及池化,得到针对每个关键区域的特征。即以8*8大小的感受野对每一个关键区域的从左上角到右下角卷积得到大小为(19-8+1)*(19-8+1)的矩阵,生成矩阵的元素值是感受野矩阵与图像对应像素的乘积之和。池化过程即对生成的矩阵平均划分为若干区域,对每个区域的值求和并除以每个区域的元素个数,即得到平均值池化的结果。连接每个关键区域的特征以及其几何位置特征得到具有空间关系的特征。最终将51个关键区域的特征串联起来形成具有空间连贯特征的鲁棒性特征。
作为优选技术方案,所述步骤S6中识别出任意姿态人脸图像所属的人脸表情类别的具体过程包括:
对任意一张待测人脸图像,采用步骤S1所述的姿态归一化方法得到其所对应的正脸图像,采用步骤S2所述的关键区域采样方法得到51关键区域,然后按照步骤S3所述的映射关系、S4所述的特征生成方法得到该待测图片的表示特征,最后将此特征送入步骤S5中训练好的统一识别模型中得到此待测人脸图片所属的表情类别。
本发明的有益效果:
(1)本发明提出的基于空间连贯特征的快速任意姿态人脸表情识别方法,通过基于关键区域的无监督特征学习方法,将通过机器学习方法所得的特征及其所对应的几何特征相连接,得到具有空间关系的特征,从而提高模型的识别率。
(2)通过姿态归一化方法以及无监督特征学习方法得到特征之间的映射关系的方法,使得不同姿态的人脸图像的表情识别可以在一个完整统一的模型中进行,而无需再为每一种姿态分别建立不同的识别模型。
(3)本发明解决了传统特征学习方法学习得到的特征不具有空间关系的问题,使得训练得到的模型对图形的形变等因素更具有鲁棒性。
(4)本发明解决了多姿态人脸表情识别中需要为每种姿态分别建立模型的问题,使得训练得到的模型不受姿态,光照等因素的干扰,能够有效地提高多姿态人脸表情识别的准确率
附图说明
图1是基于空间连贯特征的快速任意姿态人脸表情识别流程图;
图2是具有空间连贯特性特征提取流程图;
具体实施方式
本发明首先对原始图像进行姿态归一化,合成任意姿态的人脸图像所对应的正脸图像,然后对合成的正脸图像进行预处理,包括图像灰度化以及图像大小归一化。然后对经过预处理的正脸图像通过树模型进行关键区域采样,基于采样完成的关键区域训练无监督特征学习方法自动编码器,学习得到输入特征与输出特征之间的映射关系,此映射关系是通过不断更新输入特征与输出特征之间的重构误差函数得到的,当重构误差函数值趋于收敛时函数停止,此时函数的权重以及偏置构成了最终的映射关系。对所有合成的正脸图像采用该映射关系得到统一的正脸特征,然后输入支持向量机SVM进行训练和人脸表情识别。
下面结合附图和具体实施例来对本发明作进一步详细描述。
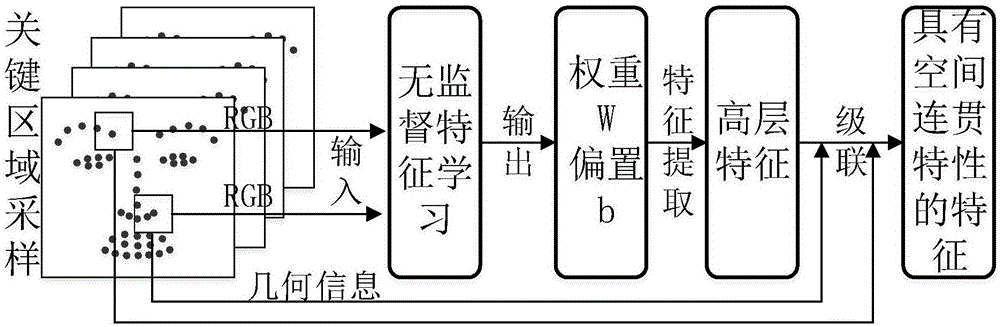
图1为本发明提出的基于空间连贯特征的快速任意姿态人脸表情识别的流程图。本发明首先对任意姿态的人脸图像进行姿态归一化得到其所对应的正脸图像,利用关键特征点定位方法进行关键区域采样得到51个对表情贡献较大的关键区域。然后利用无监督特征学习方法自动编码器进行特征提取,学习得到输入底层特征与高层特征之间的映射关系,然后利用此特征映射关系提取姿态归一化后的的人脸图像的特征,得到对姿态具有鲁棒性的统一正脸特征。最终利用此特征训练得到可用于任意姿态的人脸表情的统一识别模型。具体包括以下步骤:
S1,姿态归一化:对任意姿态的人脸图像通过姿态归一化方法合成其所对应的正脸图像,然后对合成的正脸图像进行预处理得到统一像素的灰度图像。
具体实现:给定一张标准正面人脸,通过一个树模型进行特征点定位,然后根据特征点估计投影矩阵,根据投影矩阵合成任意姿态的人脸图像所对应的正脸图像。对合成的正面人脸图像通过二值化方法进行灰度处理得到灰度图像,然后对所得灰度图像进行大小归一化得到统一像素的灰度图像。
S2,关键区域采样:首先对步骤S1合成的正脸图像通过特征点定位方法检测得到51个位于眼睛、鼻子、嘴巴、眉毛等对表情贡献较大区域的关键特征点。并以此特征点为中点采样得到尺寸为大小m×m的51个关键区域,对所得的51个关键区域提取尺寸为w×w大小的特征块。
具体实现:步骤S2中所述51个关键特征点,具体分布如下:其中9个特征点位于鼻子区域,12个特征点位于眼睛区域,10个特征点位于眉毛区域,20个特征点位于嘴巴区域,共计51个特征点。基于51个关键特征点采样得到51个关键区域,每个关键区域的尺寸大小设为19*19,特征块大小设置为8*8。
S3,无监督特征学习:将步骤S2中所得特征块送入无监督特征学习方法自动编码器中进行特征学习,得到图像的底层RGB特征与更具有分辨力的高层特征之间的映射关系,通过权重W以及偏置b来表示。
具体实现:首先对正脸图像进行白化处理,然后基于步骤S2采样得到的关键区域进行特征块提取。基于提取到的特征块训练自动编码器,通过计算输入特征和输出特征之间的重构误差函数得到平均误差值,并以此平均误差反向传播更新各层卷积核,当此平均误差值趋于收敛时,算法停止,得到输入特征和输出特征之间的映射关系,所述映射关系权重W以及偏置b构成。
进一步,所述步骤S3中无监督特征学习中白化处理的具体过程为:读取正脸图像的像素特征,然后以步长大小为1、特征块大小为8*8对得到的像素特征进行分块处理,然后对每一个小的特征块串联得到一个一维的特征,对此一维的特征均除以其标准差,从而得到具有相同方差的特征。通过此操作可以降低输入的冗余性。
S4,生成空间连贯特征:将步骤S2得到的51个关键区域利用步骤S3的映射关系进行卷积和池化得到高层特征,级联每个关键区域的高层特征与其几何位置特征得到用于表示此关键区域的具有空间关系的特征。
具体实现:用所得权重以及偏置对合成的正脸图像以关键区域为单位进行卷积以及池化,得到针对每个关键区域的特征。即以8*8大小的感受野对每一个关键区域的从左上角到右下角卷积得到大小为(19-8+1)*(19-8+1)的矩阵,生成矩阵的元素值是感受野矩阵与图像对应像素的乘积之和。池化过程即对生成的矩阵平均划分为若干区域,对每个区域的值求和并处以每个区域的元素个数,即得到平均值池化的结果。连接每个关键区域的特征以及其几何位置特征得到具有空间关系的特征。最终将51个关键区域的特征串联起来形成具有空间连贯特征的鲁棒性特征。
S5,任意姿态人脸表情识别模型训练:利用步骤S5所得的具有空间连贯特性的特征送入支持向量机SVM中进行识别模型的训练。由于所得特征均是从正脸图像上学习得到,是一种统一姿态的特征,因此可以训练得到一个针对任意姿态的统一识别模型。
S6,任意姿态人脸表情识别:对任意一张待测人脸图片,采用步骤S1,S2所述姿态归一化方法以及关键区域采样方法得到51个统一大小的关键区域,然后按照步骤S4所述生成空间连贯特征的方法表示此待测人脸图像,得到具有空间连贯特性的人脸表示特征,将此特征送入步骤S5中训练好的统一识别模型中即可得到此待测人脸图像所属的表情类别。
下面通过具体实施例对本发明进行说明。本发明的实现包括模型的训练过程和图像的识别过程,下面分别详细描述。
1.模型的训练过程,包括如下:
1.1任意姿态人脸图像姿态归一化过程
此过程又可细分为三个部分:首先对任意姿态的人脸图像进行特征点定位,其次估计投影矩阵,进而进行正脸图像合成。
特征点定位:通过树模型对任意姿态的人脸图像进行基于眼睛,鼻子,嘴巴,眉毛的关键特征点定位,得到68个关键特征点(其中的51个关键特征点如上文所述,其余17个特征点位于人脸边缘区域)。
投影矩阵估计:给定一张标准正面人脸,通过特征点定位,设所定位到的特征点用p′i=(x′i,y′i)T,x′i,y′i表示特征点的坐标位置,其中。对任意一张人脸,用同样的方法进行特征点定位,设所定位到的特征点用pi=(xi,yi)T表示,xi,yi表示所定位到的特征点的坐标。生成一个关于标准正面人脸的3D模型,其中包括图像大小、所检测到的68个特征点坐标、关于此图像完整的3维像素特征、关键特征点处的像素特征以及一个固有矩阵AM。依据特征点定位技术可求得此测试图像对于标准人脸图像的旋转矩阵RM以及偏移矩阵tM,因此可得此测试图像到标准人脸图像的投影矩阵为CM=AM[RMtM]。
正脸图像合成:通过上述投影矩阵可计算任意一张测试图像映射到此标准人脸图像上的像素信息:
p~CMP, (1)
其中,CM为某图像到标准人脸图像的投影矩阵,P=(X,Y,Z)T∈R3×mm为标准人脸图像的三维像素特征,X,Y,Z分别为三维像素的像素值。p∈R2×mm为测试图像通过映射矩阵映射得到的正面人脸图像的像素特征。然后通过线性插值法估计测试图像的可见性,计算哪边人脸被遮挡,进而对被遮挡部分进行对称填充,得到该测试图像所对应的正脸图像。
1.2关键区域采样过程
通过树型模板人脸检测模型对合成的正脸图像进行关键特征点检测,得到眼睛,鼻子,嘴巴周围的51个关键特征点。以此关键特征点为中心截取m×m大小的关键区域R,因此对于任意一张人脸图像I可用此51个关键区域R来表示I={R1,R2,...,R51},其中Ri∈Rm×m。然后对每一个关键区域R,以感受野大小为w,步长为s截取w×w的特征块,因此最终对于任意一张人脸表情图像I可由组成。
1.3无监督特征学习
假设共有人脸表情图像张,J表示J种人脸表情图片,包括了S个表演者和Y种人脸表情,其中每张人脸图像的表情标签可以表示为y={1,...,Y}。从每张图像随机选取若干特征片向量组成大小为N的特征向量X,表示为:
其中每个x(i)包含了若干个从图像i中随机选取的特征向量。J'表示用于训练无监督特征学习方法稀疏自动编码器的人脸图像个数。
生成特征向量组之后便可以训练无监督特征学习算法,共包括两个阶段:编码阶段和解码阶段。编码阶段,即学习输入层与隐藏层的映射关系。解码阶段,即学习隐藏层与输出层的映射关系。在编码阶段假设共有L个隐藏层节点,输入层和隐藏层的映射关系可表示为:
h=f(x)=g(WX+b), (3)
其中,g(z)=1/(1+exp(-z)),W∈RL×ww表示权重,RL×ww表示W为一个L*ww大小的矩阵,b为偏置向量。在解码阶段将隐藏层数据映射为输出数据:
z=f'(x)=g(WTX+b'), (4)
公式(3)和公式(4)中的权重矩阵W和WT互为转置,b'为解码阶段的偏置向量。通过LBFGS算法最小化均方误差,从而训练求得参数{W,b,b'}。
1.4空间连贯特征的生成
由图2可知该具有空间连贯特性的特征的生成是通过级联通过特征学习方法学习得到的高层特征与每个关键区域所对应的几何特征得到,具体来说其生成过程如下:
基于训练好的实验参数W,b以及b',既可以从有标签的训练数据集上提取特征。对于任意一张人脸图像均有51个大小为m*m的关键区域组成,它们均是从对表明贡献较大的眼睛,鼻子,嘴巴,眉毛等区域采样得到,每个关键区域又包含了个特征块。通过公式(4)对每个关键区域进行卷积,得到特征为维的矩阵。此处并非像传统稀疏自动编码器的池化过程一样,首先得到整张图像的特征,然后再将特征均等分为若干份进行池化,而是基于每个关键区域直接进行池化,且将此关键区域的中心坐标串联于池化后的特征,此时对于每个关键区域可以通过特征与几何特征共同表示,构成具有空间连贯特征的特征,即[yi,j,pi,j,qi,j]∈Rww+2,其中yi,j表示所得高层特征,(pi,j,qi,j)表示此高层特征所对应的关键特征点的坐标位置。对每一个关键区域均进行此卷积和池化操作,因此对于一张人脸图像i,其最终可以被表示为:
yi=[yi,1,pi,1,qi,1,yi,2,pi,2,qi,2,...,yi,51,pi,51,qi,51]. (5)
1.5识别模型的训练
对于所有的任意姿态的训练图片,通过1.1节中公式(1)的投影矩阵得到针对任意姿态的统一正脸图像,通过1.2节进行关键区域采样,得到51个基于眼睛,鼻子,嘴巴,眉毛等区域的关键区域,然后通过1.4节所述的卷积和池化操作对51个关键区域进行特征提取,并通过公式(5)提取得到具有空间连贯特性的人脸表示特征,将此特征送入支持向量机SVM中进行训练得到一个可用于任意姿态的统一识别模型。
2.图像识别过程
采用1.1节所述的任意姿态人脸图像姿态归一化过程,对一张任意姿态的待测图片,经过公式(1)得到其所对应的正脸图像,通过1.2节采样得到51个关键区域,然后通过1.4节公式(5)得到其所对应的具有空间连贯特性的特征,最后送入已训练好的SVM中进行表情识别,得到其所属的人脸表情类别。
综上所述,本发明公开了一种基于空间连贯特征的快速任意姿态人脸表情识别方法。把任意姿态人脸表情识别过程划分为四个步骤:首先对输入的任意姿态的人脸表情图像通过一个三维人脸归一化方法合成其所对应的正面人脸表情图像,然后对合成后的正脸图像基于眼睛,鼻子,眉毛,嘴巴等对表情识别贡献最大的部位检测得到51个关键特征点,并以此特征点为中点采样得到一定大小的51个关键区域,其次基于此关键区域进行无监督特征学习与优化,得到具有空间连贯特性的特征,并用于最终的任意姿态人脸表情识别。通过以上四个步骤得到了一个可用于任意姿态人脸表情识别的统一模型。因此本发明解决了传统特征由于不具有空间约束关系而导致的识别率低的问题,以及传统多姿态人脸表情识别中需要为每种姿态分别建立模型而导致的效率低的问题,能够有效地提高多姿态人脸图像表情识别的准确率及效率。
尽管已经示出和描述了本发明的实施例,本领域的普通技术人员可以理解:在不脱离本发明的原理和宗旨的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!