基于http服务切面与日志系统的异步数据同步方法和系统与流程
本发明涉及异步数据同步领域,特别涉及基于http服务切面与日志系统的异步数据同步方法和系统。
背景技术:
Bloor研究所2010的一项调查显示,估计数据迁移市场将超过50亿美元并且还正在日益增长。现在许多公司有不同的方法进行数据库迁移,如抽取/转换/装载(简称ETL),复制和手动脚本。然而这些方法面临着一些问题,当一方面数据量在增长,而另一方面允许的停机时间在减少时,这项工作将变得更复杂。数据迁移下统计数据大致如下:
·16%的数据迁移部分项目取得了成功
·37%的预算超支
·64%没有按时完成
所以,迁移要经过精心策划和执行,以尽量减少停机时间并保持数据的完整性和数据库的性能,因为许多公司已经遍布全球,并且每天24小时都要操作数据库。
有些情况下公司会做异构数据库的迁移与切换:例如为了减少费用与技术灵活度,很多公司会选择从商用数据库迁移到开源数据库。迁移是件很麻烦的事情,因为迁移不可能一蹴而就而是一个慢慢变迁的过程,所以就需要同时运营新老两套系统。同时,迁移还需要考虑老的应用、其他服务的兼容。而兼容即包括:老系统接口的兼容、数据服务的兼容等。一般而言,接口的兼容容易实现,只需要对开发人员进行统一的约束、定期安排代码审查即可。麻烦的是数据的协调、确保其他使用老系统数据的系统可以正常提供优质服务。因此,就需要打通数据环节。如何采用正确的方式来打通这个环节是现有技术中的难点。另外,由于新系统替换老系统需要时间去过度,所以数据同步就需要考虑是双向同步、还是单向同步。一般而言,双向同要比单向同步复杂很多。而数据同步需要考虑的问题有很多,比如:同步的延迟不能太大、同步的数据要完备、数据不可丢失、对原有系统要有较低的侵入、数据库无关性等等。
异构数据库迁移的方法包括:1)利用Power Builder的数据管道技术;2)利用ODBC技术和SQL语句;3)利用系统工具实现数据迁移。然而,这些方法大多操作较为复杂、灵活性差,不能够实现对数据的良好组织管理;不能自动完成数据的迁移,用户需要清楚地了解数据库的储存结构,且需要花费大量时间进行调试;并且一旦数据库结构发生变化,代码需要作大量改动,后期维护很困难。另外,系统工具又有一定的局限性,比较依赖具体的数据库产品,通用性欠缺,需要利用这些工具编写适当的迁移程序。
技术实现要素:
本发明要解决的技术问题是,如何采用应用日志的方式来实现数据同步。
解决上述技术问题,本发明提供了基于http服务切面与日志系统的异步数据同步方法,包括如下步骤:
拦截客户端的接口请求,并记录接口访问日志,
将所述访问日志作为请求事件源传递至消息队列,解析所述消息队列中的访问日志,
解析后还原请求事件的入参和/或出参,将数据转换后进行新老系统的数据映射后再写入新数据库。
更进一步,拦截客户端的接口具体包括:采用切面技术来拦截接口请求。
更进一步,所述切面技术采用:jaxrs的请求过滤器、servlet的过滤器、spring mvc的拦截器中的一种或者多种,用以提取所述接口请求中的入参、出参、url以及method的数据。
更进一步,将所述访问日志作为请求事件源传递至消息队列的方法具体为:采用log4j2的kafka组件直接将日志写入到kafka队列。
更进一步,将所述访问日志作为请求事件源传递至消息队列的方法具体为:通过flume或者fluent的采集工具将数据提交到kafka队列。
更进一步,解析所述消息队列中的访问日志的方法至少包括:一处理程序,用以将正确的消息保存到本地库中,再去做同步,如果处理失败则自动重试,所述自动重试的次数不大于3次,若大于3次则进行人工处理。
更进一步,方法还包括:在写方法上加注释,再编写处理程序。
更进一步,将日志写入老系统的数据库,然后配置flume或者fluent来sink日志到kafka队列。
更进一步,方法还包括:采用hibernate、mybatis或者任一db框架来进行新老数据库中数据的提取和写入。
基于上述,本申请还提供了基于http服务切面与日志系统的异步数据同步系统,包括:
一拦截单元,用以拦截客户端的接口请求,并记录接口访问日志,
一队列单元,用以将所述访问日志作为请求事件源传递至消息队列,解析所述消息队列中的访问日志,
一处理程序,用以解析后还原请求事件的入参和/或出参,将数据转换后进行新老系统的数据映射后再写入新数据库。
本发明的有益效果:
由于本发明的方法包括拦截客户端的接口请求,并记录接口访问日志,将所述访问日志作为请求事件源传递至消息队列,解析所述消息队列中的访问日志,解析后还原请求事件的入参和/或出参,将数据转换后进行新老系统的数据映射后再写入新数据库。通过对接口记录日志,将日志提交到任意一种数据源,由处理程序处理数据源的日志、做数据转换、同步到新的库中。从而可让异步数据同步的延迟降低、复杂度可控。
此外,本发明提供的系统,并不针对特定的数据库,同时可扩展能力较高。
附图说明
图1是本发明中的方法流程示意图;
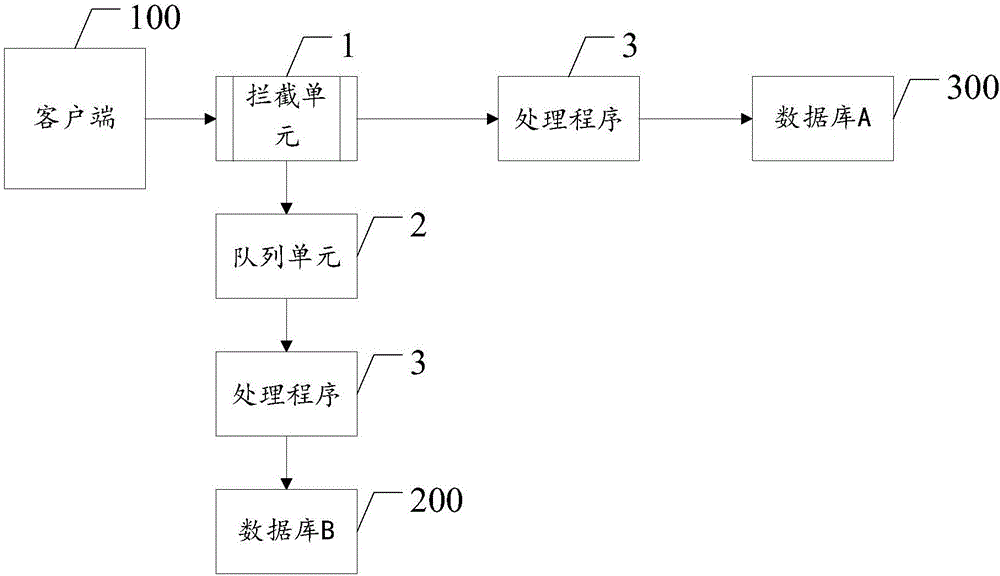
图2是本发明中的系统的结构示意图;
图3图1中的进一步处理步骤示意图;
图4是图1中的请求接口数据的类型示意图;
图5是图1中的方法具体实施方式示意图;
图6是图1中的方法另一具体实施方式示意图。
具体实施方式
现在将参考一些示例实施例描述本公开的原理。可以理解,这些实施例仅出于说明并且帮助本领域的技术人员理解和实施例本公开的目的而描述,而非建议对本公开的范围的任何限制。在此描述的本公开的内容可以以下文描述的方式之外的各种方式实施。
如本文中所述,术语“包括”及其各种变体可以被理解为开放式术语,其意味着“包括但不限于”。术语“基于”可以被理解为“至少部分地基于”。术语“一个实施例”可以被理解为“至少一个实施例”。术语“另一实施例”可以被理解为“至少一个其它实施例”。
可以理解,本申请中的客户端是指基于http协议的客户端,如:浏览器、编程语言使用的http client等。HTTP协议(HyperText Transfer Protocol,超文本传输协议)是用于从www服务器传输超文本到本地浏览器的传输协议。可以使浏览器更加高效,使网络传输减少。它不仅保证计算机正确快速地传输超文本文档,还确定传输文档中的哪一部分,以及哪部分内容首先显示(如文本先于图形)等。需要说明的是,本申请的基于的HTTP协议是客户端浏览器或其他程序与Web服务器之间的应用层通信协议。在Internet上的Web服务器上存放的都是超文本信息,客户机需要通过HTTP协议传输所要访问的超文本信息。HTTP包含命令和传输信息,不仅可用于Web访问,也可以用于其他因特网/内联网应用系统之间的通信,从而实现各类应用资源超媒体访问的集成。
HTTP协议能够支持客户/服务器模式,客户向服务器请求服务时,只需传送请求方法和路径。请求方法包括但不限于:GET、HEAD、POST。每种方法规定了客户与服务器联系的类型不同。另外,HTTP协议允许传输任意类型的数据对象,正在传输的类型由Content-Type加以标记。
在本申请中的Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。Flume最早是Cloudera提供的日志收集系统,目前是Apache下的一个孵化项目,Flume支持在日志系统中定制各类数据发送方,用于收集数据。数据处理方面:Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力Flume提供了从console(控制台)、RPC(Thrift-RPC)、text(文件)、tail(UNIX tail)、syslog(syslog日志系统,支持TCP和UDP等2种模式),exec(命令执行)等数据源上收集数据的能力。
图1是本发明中的方法流程示意图;步骤S100拦截客户端的接口请求,并记录接口访问日志,所述拦截客户端的接口具体包括:采用切面技术来拦截接口请求,所述切面技术采用:jaxrs的请求过滤器、servlet的过滤器、spring mvc的拦截器中的一种或者多种,用以提取所述接口请求中的入参、出参、url以及method的数据。如图4是图1中的请求接口数据的类型示意图;请求接口数据包括但不限于:请求ID、时间ID、请求URL、请求数据类型、返回数据类型等。
步骤S101将所述访问日志作为请求事件源传递至消息队列,解析所述消息队列中的访问日志,在所述步骤S101中将所述访问日志作为请求事件源传递至消息队列的方法具体为:采用log4j2的Kafka组件直接将日志写入到Kafka队列。在一些实施例中,将所述访问日志作为请求事件源传递至消息队列的方法具体为:通过flume或者fluent的采集工具将数据提交到Kafka队列。
Kafka是一种分布式的基于发布/订阅的消息系统,以时间复杂度为O(1)的方式提供消息持久化能力,并保证即使对TB级以上数据也能保证常数时间的访问性能。所以,在上述实施例中采用log4j2的Kafka组件直接将日志写入到Kafka队列,由于Kafka具备高吞吐率,同时支持离线数据处理和实时数据处理,所以可以将所述访问日志作为请求事件源传递至消息队列的优选方法。
步骤S102解析后还原请求事件的入参和/或出参,将数据转换后进行新老系统的数据映射后再写入新数据库。
在上述步骤S101中,解析包括但不限于:日志以JSON的格式存储,可以采用JSON库将对应的请求消息转换成封装好的对象。JSON是一种轻量级的数据格式,易于程序员阅读和编写,同时也易于机器解析和生成。JSON可以将JavaScr ipt对象中表示的一组数据转换为字符串,然后就可以在函数之间轻松地传递这个字符串,或者在异步应用程序中将字符串从Web客户机传递给服务器端程序。
在一些实施例中,解析所述消息队列中的访问日志的方法至少包括:一处理程序,用以将正确的消息保存到本地库中,再去做同步,如果处理失败则自动重试,所述自动重试的次数不大于3次,若大于3次则进行人工处理。
在一些实施例中,方法还包括:在写方法上加注释,再编写处理程序。在本申请中使用该注解的目的是用来找出需要做数据同步的服务,系统在做处理的时候会查看服务上有没有该注解,如果有就输出同步日志到队列。如果没有就不做处理。比如:会员模块有注册、更新、查询等服务,这里只有注册、更新需要做数据同步,而查询是不需要的。这种情况下只需要对注册、更新加上注解即可。
在本申请中,使用注解可以减少无效的日志写入队列,同时,也可以提升同步处理效率。
在一些实施例中,将日志写入老系统的数据库,然后配置flume或者fluent来sink日志到kafka队列。
在一些实施例中,方法还包括:采用hibernate、mybatis或者任一db框架来进行新老数据库中数据的提取和写入。
上述实施例中,基于HTTP协议限制每次连接只处理一个请求,服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。另外,HTTP协议是无状态协议,即是指协议对于事务处理没有记忆能力,在服务器不需要先前信息时的应答就较快。另外,JSON格式可以表示数组和复杂的对象,而不仅仅是键和值的简单列表,对于异步数据同步而言具有更好地适应性。
图2是本发明中的系统的结构示意图;系统包括:拦截单元1,用以拦截客户端的接口请求,并记录接口访问日志,队列单元2,用以将所述访问日志作为请求事件源传递至消息队列,解析所述消息队列中的访问日志,以及,处理程序3,用以解析后还原请求事件的入参和/或出参,将数据转换后进行新老系统的数据映射后再写入新数据库。在所述拦截单元1采用切面技术来拦截接口请求。具体地,所述切面技术采用:jaxrs的请求过滤器、servlet的过滤器、spring mvc的拦截器中的一种或者多种,用以提取所述接口请求中的入参、出参、url以及method的数据。在所述队列单元2中将所述访问日志作为请求事件源传递至消息队列的方法具体为:采用log4j2的kafka组件直接将日志写入到kafka队列。和/或,将所述访问日志作为请求事件源传递至消息队列的方法具体为:通过flume或者fluent的采集工具将数据提交到kafka队列,也可以将日志写入老系统的数据库,然后配置flume或者fluent来sink日志到kafka队列。作为本实施例中的优选,在所述处理程序3中,解析所述消息队列中的访问日志的方法至少包括:一处理程序,用以将正确的消息保存到本地库中,再去做同步,如果处理失败则自动重试,所述自动重试的次数不大于3次,若大于3次则进行人工处理。
本实施例中的系统,由于采用了队列单元2,可以有效地降低延迟,同时具备高可扩展能力。由于处理程序3解析后还原请求事件的入参和/或出参,将数据转换后进行新老系统的数据映射后再写入新数据库,使得整个系统复杂度可控、数据库无关。另外,由于拦截单元1,拦截客户端的接口请求,并记录接口访问日志降低了应用侵入性。
图3图1中的进一步处理步骤示意图;解析所述消息队列中的访问日志的方法至少包括:一处理程序,用以将正确的消息保存到本地库中,再去做同步,如果处理失败则自动重试,所述自动重试的次数不大于3次,若大于3次则进行人工处理。
具体包括步骤为:
步骤S200从kafka提取数据同步的日志
步骤S201解析日志
步骤S202提取URL等数据放入exchange头
步骤S203保存数据同步请求事件
步骤S204根据URL匹配到对应的处理程序
步骤S205调用对应的处理程序处理同步请求
若处理失败且失败次数小于3,则进入步骤S206数据放回队列
若处理成功或者失败的次数不小于3,则进入步骤S207处理完成更新完成数据
图5是图1中的方法具体实施方式示意图;
step1客户发起写入请求到新的系统;
step 2系统接收请求后分析该请求是否需要做数据同步;
step 3如果需要做数据同步,则DataSyncFilter数据同步过滤器会将对应的请求和响应信息进行封装,然后写入队列;
step 4处理程序会从队列里提取消息;
step 5处理程序解析消息,将其转换回封装的对象;
step 6处理程序根据请求和响应去新的库里提取数据;
step 7处理程序将新的数据映射成老的数据;
step 8处理程序保存老的数据到老系统的数据库。
首先,拦截应用系统的接口日志。这里采用切面技术(切面如:jaxrs的请求过滤器、servlet的过滤器、spring mvc的拦截器等)来拦截系统的请求,通过过滤器来提取请求的入参、出参、url、method等数据。其次,本方案采用log4j2的kafka组件直接将日志写入到kafka队列的。当然,也可以通过flume、fluent这样的采集工具将数据提交到kafka。接着,构建处理程序从kafka提取数据进行处理、做好数据转换、保存数据到新的库里。处理程序会将正确的消息保存到本地库中,然后再去做同步,如果处理失败会自动重试。重试是有次数限制的,系统默认的重试次数是3次,大于3次说明需要人工介入进行特殊处理了。大于3次的原因有很多,可能是数据映射做错了,或者是数据库磁盘满了等。
最后,接入并使用数据同步呢,在需要做数据同步的写方法上加@DataSyncLogged,然后编写处理程序即可。这里的处理程序需要接入者完成新老表的数据映射,保存数据到新的库。使用@DataSyncLogged该注解的目的是用来找出需要做数据同步的服务,系统在做处理的时候会查看服务上有没有该注解,如果有就输出同步日志到队列。如果没有就不做处理。
优选地,接入者如果觉得使用log4j2直接写入日志到kafka对应用有比较大的影响,可以考虑将日志写入本低文件系统。然后配置flume或者fluent来sink日志到kafka队列也可以。
优选地,接入者如果不想使用kafka,那么可以更换掉。只是要注意下对应的处理程序的数据来源需要调整为新的数据源,如:hbase等。
优选地,接入者可以选择自己喜欢的数据库框架来做数据的提取和写入,hibernate、mybatis或者其他的db框架任君选择。
上述方法,可以适用于本申请中的系统,拦截单元1,用以拦截客户端的接口请求,并记录接口访问日志,队列单元2,用以将所述访问日志作为请求事件源传递至消息队列,解析所述消息队列中的访问日志,以及,处理程序3,用以解析后还原请求事件的入参和/或出参,将数据转换后进行新老系统的数据映射后再写入新数据库。
图6是图1中的方法另一具体实施方式示意图。
Step1客户发起写入请求到新的系统;
Step2系统接收请求后分析该请求是否需要做数据同步;
Step3如果需要做数据同步,那么DataSync Filter数据同步过滤器会将对应的请求和响应信息进行封装,然后写入日志文件;
Step4采集程序(如:flume、fluent)会采集日志并写入队列;
Step5处理程序会从队列里提取消息;
Step6处理程序解析消息,将其转换回封装的对象;
Step7处理程序根据请求和响应去新的库里提取数据;
Step8处理程序将新的数据映射成老的数据;
Step9处理程序保存老的数据到老系统的数据库。
首先,拦截应用系统的接口日志。这里采用切面技术(切面如:jaxrs的请求过滤器、servlet的过滤器、spring mvc的拦截器等)来拦截系统的请求,通过过滤器来提取请求的入参、出参、url、method等数据。其次,本方案采用log4j2的kafka组件直接将日志写入到kafka队列的。当然,也可以通过flume、fluent这样的采集工具将数据提交到kafka。接着,构建处理程序从kafka提取数据进行处理、做好数据转换、保存数据到新的库里。处理程序会将正确的消息保存到本地库中,然后再去做同步,如果处理失败会自动重试。重试是有次数限制的,系统默认的重试次数是3次,大于3次说明需要人工介入进行特殊处理了。大于3次的原因有很多,可能是数据映射做错了,或者是数据库磁盘满了等。
最后,接入并使用数据同步呢,在需要做数据同步的写方法上加@DataSyncLogged,然后编写处理程序即可。这里的处理程序需要接入者完成新老表的数据映射,保存数据到新的库。使用@DataSyncLogged该注解的目的是用来找出需要做数据同步的服务,系统在做处理的时候会查看服务上有没有该注解,如果有就输出同步日志到队列。如果没有就不做处理。
上述方法,可以适用于本申请中的系统,拦截单元1,用以拦截客户端的接口请求,并记录接口访问日志,队列单元2,用以将所述访问日志作为请求事件源传递至消息队列,解析所述消息队列中的访问日志,以及,处理程序3,用以解析后还原请求事件的入参和/或出参,将数据转换后进行新老系统的数据映射后再写入新数据库。
虽然本公开以具体结构特征和/或方法动作来描述,但是可以理解在所附权利要求书中限定的本公开并不必然限于上述具体特征或动作。而是,上述具体特征和动作仅公开为实施权利要求的示例形式。
- 还没有人留言评论。精彩留言会获得点赞!