一种基于改进型LeNet的鲁棒蒙面人脸检测方法与流程
本发明涉及蒙面人脸检测,尤其是涉及一种基于改进型LeNet的鲁棒蒙面人脸检测方法。
背景技术:
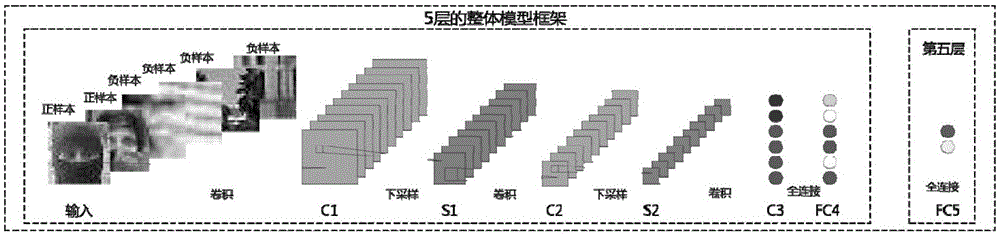
:随着社会的发展,科学技术的提高,以及多媒体技术的普及,越来越多的人们在网络上上传各种各样的网络视频,其中也包括不少犯罪分子企图利用多媒体渠道,开始传播暴力恐怖视频,这种行为已经在一定程度上影响社会的稳定发展。若能在海量的视频帧中快速且准确地定位出恐怖分子,将极大地减少人力资源和维护社会稳定。作为一种大尺度视频库的管理的基本需要,准确地检索出拥有恐怖分子的暴恐视频帧对整个社会稳定起到重大的作用。在给定的视频帧中如何准确定义存在恐怖分子,这是一个困难的问题,因为恐怖分子表现形式多种多样。通常情况下,恐怖分子都是蒙面的,所以在本发明中,将恐怖分子认为是具有蒙面特征的人。蒙面人人脸检测作为一种人脸检测的特殊任务,它跟传统的人脸检测技术不同的是面临着更多的挑战。一方面,蒙面人人脸检测包含着传统人脸检测技术无法处理的姿势变化,光照等影响条件。另一方面,蒙面人的脸部是严重遮挡的,大大丢失了原本人脸的正常结构,使得传统算法对于蒙面人人脸检测失效。目前,大量的人脸检测技术依赖于手动设置的特征,比如:广泛使用的Fisherface[1],基于Haar-like特征的级联分类器[2],基于Gabor-like高维特征的AdaBoost检测器[3]。由于这种手动设置的特征需要大量的训练样本以及蒙面人失去了完整的人脸结构使得手动设计的特征无法准确表征蒙面人人脸结构的,最终使得这些方法无法准确检测到蒙面人人脸。近来,基于模板的(exemplar-based)人脸检测方法[4]表现出了较好的效果,主要因为庞大的模板数据库覆盖了所有可能的人脸视觉变化(visualvariations),其中包括遮挡,光照,人脸姿势等变化,但该方法需要大量的模板数据集,且在高度散乱的背景情况下,很容易产生虚警(falsealarm)结果。为了减少需要模板的个数,文献[5]提出了一种有效的基于提升的模板人脸检测方法。该方法能够进一步提高人脸检测率,加速检测过程,以及通过判别式训练和有效性的结合模板作为弱分类器的方式,大大地节约内存开销。近年来,由于深度学习的兴起,使得带有强大的GPU计算能力的卷积神经网络(convolutionalneuralnetworks,CNN)在人脸领域也取得了很大的突破,如LFW[6][7][8]。特别地,卷积网络能够通过训练样本自动学习有效的特征表示。在2012年大尺度识别竞赛中(LargeScaleVisualRecognitionChallenge)中,文献[9]利用深度卷积神经网络取得了突破性的进展。此外,为了进一步处理只有少量的训练样本的情况,文献[10]引入了预训练初始化深度网络的权重,加快网络的收敛以及得到一个较优的局部解。文献[11]提出了LeNet模型,在手写体字符识别中,显示了很好的性能。随着这些深度学习技术的发展,基于深度学习的人脸检测方法成为了可能。参考文献:[1]H.J.P.BelhumeurPN,K.D.J.Eigenfacesvs.fisherfaces:Recognitionusingclassspecificlinearprojection.IEEETransactionsonPatternAnalysisandMachineIntelligence,1997,19(7):711-720.[2]P.Viola,M.Jones,Rapidobjectdetectionusingaboostedcascadeofsimplefeatures.inProceedingsofCVPR,2001.[3]C.Liu,H.Wechsler,Gaborfeaturebasedclassificationusingtheenhancedfisherlineardiscriminantmodelforfacerecognition.IEEETransactionsonImageProcessing,2002,11(4):467-476.[4]X.Shen,Z.Lin,J.Brandt,etal.Detectingandaligningfacesbyimageretrieval.inProceedingsofCVPR,2013:3460-3467.[5]H.Li,Z.Lin,J.Brandt,etal.Efficientboostedexemplar-basedfacedetection.InProceedingsofCVPR,2014:1843-1850.[6]X.W.YiSun,X.Tang.Deeplearningfacerepresentationfrompredicting10,000classes.inProceedingsofCVPR,2014:1891-1898.[7]Y.Sun,X.Wang,X.Tang.Deeplylearnedfacerepresentationsaresparse,selective,androbust.arXivpreprintarXiv:1412.1265.[8]Y.Sun,X.Wang,X.Tang.Hybriddeeplearningforfaceverification.inProceedingsofICCV,2013:1489-1496.[9]A.Krizhevsky,I.Sutskever,G.E.Hinton.Imagenetclassificationwithdeepconvolutionalneuralnetworks.inProceedingsofNIPS,2012:1097-1105.[10]G.E.Hinton,R.R.Salakhutdinov.Reducingthedimensionalityofdatawithneuralnetworks.Science,2006,313:504-507.[11]Y.LeCun,L.Bottou,Y.Bengio,etal.Gradient-basedlearningappliedtodocumentrecognition.ProceedingsoftheIEEE,1998,86(11):2278-2324.技术实现要素:本发明的目的在于针对训练样本少,以及蒙面人完整结构特征无法获取的特点,提供MLeNet通过引入预训练及微调(pre-trainingandfine-tuning)等手段,且结合滑动窗口方法,能够快速且准确地定位蒙面人人脸位置的一种基于改进型LeNet的鲁棒蒙面人脸检测方法。本发明包括以下步骤:1)通过水平翻转原始训练图片,扩充训练数据;2)通过修改传统的LeNet模型的结构,提出新的MLeNet模型,使之适应于蒙面人类的检测问题,具体方法可为:调整卷积核大小和特征图个数,另外,改变原来的输出层的节点数10为2,使之适合于人类检测的2分类问题;3)借用原始的LeNet模型中的参数预训练MLeNet结构,并微调MLeNet模型,得到适合于蒙面人脸的检测器;4)结合滑动窗口及非最大化抑制技术准确定位出蒙面人人脸的位置。本发明具有以下突出优点:本发明在原始LeNet模型的基础上,通过修改卷积层的卷积核(convolutionalfilter)大小、特征图(featuremap)的个数以及全连接层的节点个数,提出了一种新的MLeNet模型。同时通过扩充训练样本以及结合预训练和微调等手段进一步提高了MLeNet的性能。最后,通过结合滑动窗口及非最大化抑制(non-maximumsuppression)准确定位出蒙面人人脸的位置。在本发明中,对于设备的要求较低,只需要一块8GU盘用于存储训练MLeNet模型的数据集,此外还需要一块高性能CPU用于计算MLeNet模型中的各种卷积计算。本发明的技术效果如下:通过修改的LeNet模型,提出新的MLeNet模型,利用预训练、微调、以及数据扩充等技术,并引入一些后处理技术,本发明提出的模型能够准确的检测出蒙面人人脸,且在背景散乱,环境变化等干扰条件下,该模型依然有较强的鲁棒性。MLeNet模型能够有效的解决因小样本问题而引起的模型过拟合问题,以及能够在自然环境下,准确的定位蒙面人人脸位置,在视频监控,公共安全等领域存在大量的应用前景。本发明建立了MLeNet模型,该模型修改了原始LeNet模型,使得该模型更适合蒙面人人脸检测。在训练样本较少的情况下,训练该模型容易导致过拟合现象的发生,因此通过扩充训练数据集,并结合预训练、微调等技术,克服了过拟合问题以及提高的MLeNet模型的分类准确率。后处理方法的使用,如非极大值抑制,使得检测蒙面人人脸更加准确。附图说明图1为具体蒙面人脸检测总流程图。图2为修改的卷积神经网络MLeNet模型:MLeNet输出层只有两个节点,在所有的卷积层中拥有较小的卷积核大小,同时每层拥有较大的特征图个数。图3为LeNet损失函数值(包括训练和验证阶段的函数损失值)。图4为LeNet分类错误率(包括正负样本的分类错误率)。图5为无预训练与微调的MLeNet损失函数值(包括训练和验证阶段的函数损失值)。图6为无预训练与微调的MLeNet分类错误率(包括正负样本的分类错误率)。图7为有预训练和微调的MLeNet损失函数值(包括训练和验证阶段的函数损失值)。图8为有预训练和微调的MLeNet分类错误率(包括正负样本的分类错误率)。图9为蒙面的恐怖分子人脸检测的部分结果(为了保护隐私性,蒙面人的人脸区域由马赛克处理过)。具体实施方式本发明的目的在于针对训练样本少,以及改进传统的手动调整人脸特征问题,提供MLeNet模型,并通过简单的扩展样本、预训练及微调等手段,训练得到准确鲁棒的人脸模型,同时结合滑动窗口、非最大化抑制方法,得到快速、鲁棒及准确的人脸检测器。具体的算法流程如图1所示。具体的每个模块如下:1、扩充数据集本发明所用的训练及测试数据集为公安部提供的部门暴恐视频中的一些关键帧组合而成。总共包含1140张图片,其中240张正样本(即,包含蒙面人脸),900张负样本(即,不含蒙面人脸),实验通过随机选取150张正样本和750张负样本作为训练集(trainingset),50张正样本和50张负样本作为验证集(validationset),留下140张图片作为测试集(testset)。考虑到人脸的特殊的对称信息,本发明利用了水平翻转(horizontalreflection)技术将原本的数据集扩充了两倍。2、MLeNet模型该MLeNet模型是改进原有的LeNet模型。LeNet模型总共有5层,分别3个卷积层(convolutionallayer)和2个全连接层(fullyconnectedlayer),卷积层含有卷积和下采样的运算。首先考虑到是否存在蒙面人人脸的问题,这是一个二分类问题,通过修改最后一层全连接层的节点个数,从原来的10变成2,并将原始的LeNet中的卷积核大小减少到3×3,但增加每层特征图的个数。特别地,改变第一个全连接层(FC4)的节点个数由原来的84增加到500。MLeNet与LeNet模型的每层信息都详细列在了表1中,另外,最终的MLeNet模型如图2所示。MLeNet与LeNet模型参见表1:每个模型包含3个卷积层和2个全连接层,详细的各个模型的各层参数列在最后两行,其中卷积核大小“num×size×size”,卷积核移动间隔“st.”,空间填充“pad”,及最大池因子。表1令N个训练样本为其中标签yi是标签变量(本发明中取值为0或1)。最后的损失函数为Softmax损失函数(即,预测值与标签的误差),定义为:其中,为模型输出的概率值,l{yi=j}为示性函数,可定义为若模型输出值与真实标签值越相近,则误差输出越小。w,b分别为各层的权值和偏差。预测标签可由一系列w,b前向传播得到。另外,网络的各个参数可结合背向传播(back-propagating)各层误差,和随机梯度下降法(stochasticgradientdescent)更新所有的参数。具体地,本发明利用梯度下降法来训练MLeNet模型(即,更新每层的变量w,b),将批量(batch)大小设置为20,动量(momentum)设为0.9,权重衰减(weightdecay)设为0.0005,学习率(learningrate)设为0.001,训练回合数(epoch)为100。权重w和偏置b更新规则如下:其中,i是迭代索引值,u,v为动量变量,表示为第i个批量图像Di所对应的目标函数对权重w的偏导,表示为第i个批量图像Di所对应的目标函数对权重b的偏导。该更新的规则说明每层变量(权重w和偏差b)更新方式是使得目标损失函数沿着局部最小值方向移动,最终获得局部最优解。本发明初始化的权重及偏置值直接来自于已训练好的LeNet模型参数,利用随机梯度下降法微调MLeNet。在6GB内存,1.90GHzAMDA8-4500MAPU普通PC机上,就可以训练MLeNet模型100回合,不需要采用GPU,训练时间只需要花费10min。3、提高检测准确率技巧:预训练、微调本发明通过预训练和微调手段学习MLeNet模型。首先,利用MNIST数据集预先训练LeNet模型,然后通过学习到的LeNet参数初始化MLeNet参数。最后,使用随机梯度下降法微调MLeNet的参数。4、检测蒙面人人脸利用上面介绍的训练MLeNet方法,就可以得到一个准确率较高的蒙面人人脸检测器能够判断出给定的窗口中是否存在蒙面人人脸。但是,没有考虑到多尺度以及检测窗口重叠问题,所以本发明利用图像金字塔匹配方案并结合非极大值抑制来后处理此类问题。简而言之,为了进行金字塔匹配,需要在多尺度图像不同位置采集目标图像,每个取样的图像放入已训练好的MLeNet蒙面人人脸检测器中,MLeNet检测器就能给每个窗口产生一个是否存在人脸的得分值。然后,利用非极大值抑制融合一些高得分的子窗口,最终,完成检测。基于一种新的MLeNet模型的蒙面人人脸检测技术。MLeNet通过引入预训练及微调(pre-trainingandfine-tuning)等手段,且结合滑动窗口方法,能够快速且准确地定位蒙面人人脸位置。具体实验结果如下:随着社会的发展,科学技术的提高,以及多媒体技术的普及,越来越多的人们在网络上上传各种各样的网络视频,其中也包括不少犯罪分子企图利用多媒体渠道,开始传播暴力恐怖视频,这种行为已经在一定程度上影响社会的稳定发展。若能在海量的视频帧中快速且准确地定位出恐怖分子,将极大地减少人力资源和维护社会稳定。在给定的视频帧中如何准确定义存在恐怖分子,这是一个困难的问题,因为恐怖分子表现形式多种多样。通常情况下,恐怖分子都是蒙面的,所以在本发明中,将恐怖分子认为是具有蒙面特征的人。因此,能否准确地定位出蒙面人人脸位置,是判断出视频帧中是否存在恐怖分子的关键。在给定少量的训练样本及蒙面人无法获取完整人脸结构情况下,传统的人脸检测技术无法准确地定位蒙面人人脸位置。人脸检测是计算机视觉方向一个重要的应用,传统的人脸检测算法能够较为准确地检测到正面的,无遮挡的人脸,但对于遮挡的,特别是低分辨率,蒙面的情况,得不到良好的检测效果。在本发明中提出了一种新的模型用于蒙面人人脸检测,能够获得很好的性能,本发明可用于视频监控、人机交互、暴恐视频检索、公共安全等领域。图3和4给出LeNet模型在给定的蒙面人脸数据集上的性能。图5和6为没有预训练与微调的MLeNet的性能,图7和8为有预训练和微调的MLeNet的训练结果。从实验的曲线图可知,加入预训练及微调等手段训练出来的MLeNet模型大大提高了蒙面人脸分类结果。在自行创建的蒙面人数据集中检测蒙面人人脸的实验结果见表2。从表2中可知,通过加入预训练及微调等手段的MLeNet模型(即,Ours)相比于传统的AdaBoost算法、LeNet模型,以及没有加入预训练及微调的MLeNet模型,本发明的方法更适合于蒙面人脸检测问题。表2OursAdaBoost[2]LeNet[11]MLeNetRecall0.9250.750.820.85Precision0.710.60.640.68F1-score0.8030.6670.7190.756“Ours”表示加入预训练与微调的MLeNet;“MLeNet”表示无预训练与微调的MLeNet模型。公式说明如下:(定义的公式变量与符号可参考具体公式表达说明)公式(1)定义了模型的损失函数,目的用于衡量模型输出的结果与原始标签值的误差。公式(2)为示性函数的定义,目的用于判断两个值是否相等,若相等,则值设为1,反之,则为0。公式(3)定义了随机梯度下降法的更新规则,其目的为更新每层变量(权重w和偏差b)使得目标损失函数沿着局部最小值方向移动,获得最终的局部最优解。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1