一种面向数据库的时空轨迹大数据存储方法与流程
本发明涉及数据库管理系统、时空数据库、浮动车辆跟踪、交通情报分析,位置相关服务,大数据计算等领域,提出一种面向数据库的时空轨迹大数据存储系统及方法,属于计算机互联网技术领域。
背景技术:
随着支持GPS的移动终端(如车辆导航仪、智能手机和物联网定位器等)以及在线地图服务(如Google Maps、百度地图、MapQuest)的不断推广与普及,使得人们可以记录他们当前的地理坐标并分享他们的运动信息到互联网上去,如互联网应用Bikely、GPS-Way-points、Share-My-Routes和Microsoft的GeoLife等项目。同时,越来越多的社交网络,诸如微博、微信、Twitter、Foursquare和Facebook等,也提供基于GPS位置和行程共享的功能。根据欧盟GSA的报告,在Apple和Android手机APP市场上大约一半的应用在不断手机用户的位置信息。藉此,越来越多的智能手机用户可以在日常生活中享受基于位置的服务LBS。
现今,空间数据专家和科学家把这类带有时间戳的地理点序列数据称作轨迹(Trajectory)。轨迹数据用来记录移动对象随着时间不断改变的空间位置。它的通用数据表示形式是:<id,(latitude1,longitude1,t1,o1),(latitude 2,longitude 2,t2,o2)…>,其中(latitudei,longitudei)为空间维度的位置信息,(ti)为时间戳,(oi)为其他扩展属性,比如速度、方向、状态等。基于轨迹数据,人们可以研究一个移动对象的运动和一组移动对象的运动行为,如游客在博物馆的游览习惯。随着巨量轨迹数据的生成,催生了许多新型的应用,比如社交网络、行程规划、线路推荐和通勤模式等。以轨迹相似性搜索和行程推荐类应用为例,其基本算法是:给定一些选中的位置(比如用户在地图上点击了几个坐标点),从数据库中检索出经过(或接近)这组坐标点的轨迹,Cyclopath就是一个生动的例子,它向用户提供能够匹配个人骑行需求的自行车路径来,并将个人骑行知识共享到社区去。
轨迹数据区别于其它地理空间数据类型(比如OSGeo规范中的Geometry和Raster数据)的一个主要特征是:轨迹是一种时间序列化的地理空间数据。轨迹数据的实践意义在于:离散的、孤立的GPS采样点难以被直接理解与检索,通过轨迹这种新型的数据模型,用户可以轻松跨越时空采样源数据与上层空间数据分析需求之间的语义间隔,进行高效快捷的轨迹大数据存储与检索。
近年来,科学家和学者已经提出了一些轨迹数据库的原型系统,比如美国UIC大学的Domino、德国FernUni大学的Secondo、希腊UP大学的Hermos、瑞士EPFL的ST-Toolkit和澳大利亚UQ大学的SharkDB等。在中国科研界在逐渐研发轨迹数据管理的原型系统,比如中国科学院软件研究所所提出的移动对象数据库DTNMOD系统,用以管理路网受限的运动轨迹。但是这些系统都是基于学术研究和教育目的开发的,难以适用于大数据级的实践应用中,具体不足之处体现为两点:(1)难以支持大规模并发的数据注入。在大数据时代进行数据系统设计必须遵守的一条规则是:“数据是有重量的”,需要考虑数据并发加载和注入的能力。比如一个城市有数万辆出租车,每秒钟有数万条GPS记录注入(参考当前最大叫车软件嘀嘀打车数据和最大交通数据服务商四维图新)。现有的轨迹数据库原型中均将GPS源数据转换为轨迹数据模型,无论是实时数据注入还是批量数据导入,其数据加载性能与扩展性非常有限。(2)难以支持复杂的数据分析场景。现在大数据系统具有2个技术特征:采用可以水平扩展的集群架构,提供可以灵活定制的OLAP分析技术。前者意味着数据需要在集群之间进行高速的交换(比如MapReduce架构下的shuffle技术或MPP架构下地interconnect技术),造成通讯风暴;后者意味着如果没有提供贴近高层语义的轨迹查询接口,用户将难以进行高效快捷的开发,甚至会造成通过商业智能软件(BI)生成非常复杂、难以解读和调优的查询计划,堵塞了大数据分析计算队列。
综上所述,对于面向数据库的轨迹大数据存储方法,目前已有的相关方案难以适用于大数据级的实践应用,难以支持大规模高并发的数据注入以及难以支持复杂的数据分析场景。
技术实现要素:
本发明的目的在于:克服现有技术的不足,提供一种面向数据库的轨迹大数据存储方法,确保大规模高并发的数据注入,以及对复杂的数据分析场景提供支持。
本发明技术解决问题:针对快速增长的海量时空轨迹数据的存储需求,提供一种面向数据库的轨迹大数据存储方法(Database-oriented Trajectory big data Storage method,简称DOTS),提供源时空采样数据的高并发注入、轨迹数据查询计划高效执行和丰富的轨迹语义查询扩展框架,所提方法涉及时空轨迹数据在数据库管理系统中的存储、表征与查询等环节,充分考虑实践性,具有大规模源数据并发加载、轻量级轨迹数据表征和灵活查询处理等先进技术特征。基于本发明所提方法,数据工程师和数据科学家们可以搭建轨迹大数据存储系统,向手机APP应用、企业Cloud服务和个人行程管理等提供基础软件支撑。
本发明技术解决方案包括:一种面向数据库的轨迹大数据存储方法,实现步骤为:
步骤1,利用信息采集终端对某一具有位置信息采样的对象所处的状态信息如经纬度、速度等等进行信息采集,通过必要的传输设备将采集到的信息发送到数据处理系统;
步骤2,在数据处理系统,对接收到的原始数据信息进行必要的噪音过滤和数据清洗,之后将简单处理过的数据信息直接注入数据库,通过以上步骤得到数据存储层。以下步骤中所述轨迹信息的源轨迹数据都是通过此步骤的操作得到的;
步骤3,对上述步骤得到的源空间数据进行建模与处理,并通过截取、投影、度量、拟合等内部函数操作,得到轨段(Track)数据,通过以上操作步骤得到轨迹层;
步骤4,在基于步骤3得到的轨段数据的基础上,提供时空数据分析的复杂查询功能。
步骤1所述的某一具有位置信息采样的对象所处的状态信息为:信息采集对象的状态信息包括唯一识别id号,经纬度信息<latitude,longitude>,时间信息time,运行速度speed以及其他信息,可以表示为<id,latitude,longitude,time,speed,others>。
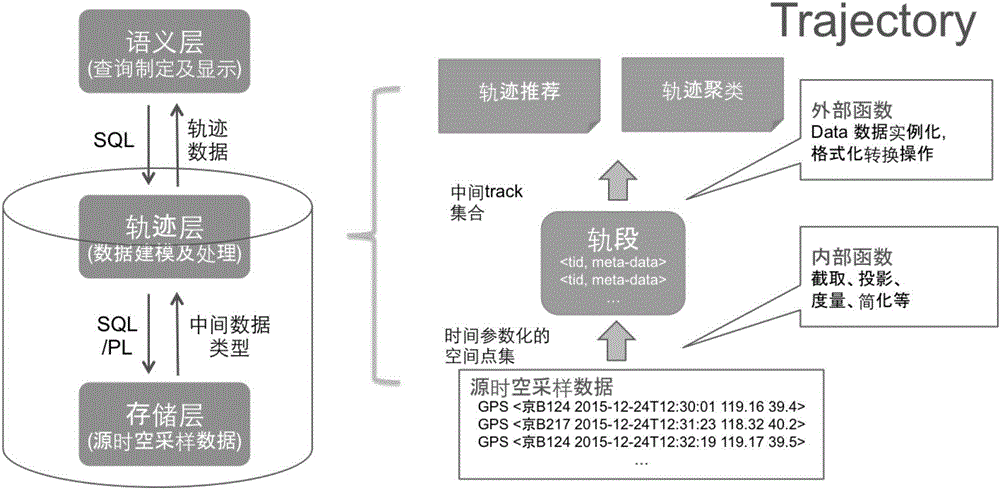
所述步骤2中对接收到的原始数据信息进行必要的噪音过滤和数据清洗,这是为了将一些明显的存在数据信息误差的错误数据丢弃掉,避免因为错误数据对后续的操作带来更多的累计影响。对接收到的原始数据信息进行必要的噪音过滤和数据清洗之后将简单处理过的数据信息直接注入数据库,这么做对数据库的好处是:短事务、高并发、可水平扩展。轨迹大数据注入的数量和速度都会对数据库系统造成致命威胁,比如占用连接池、消耗锁资源、耗尽内存空间等,所以除了基本的数据清洗和噪音过滤外,对于数据注入不能进行太复杂的处理。数据将以“元数据表+数据子表”的方式进行组织,具体形式如下:轨迹数据库由一组轨迹池构成,每个轨迹池由一组轨迹构成;轨迹池和子表的对应关系保存在元数据表中,元数据表中每一行对应一条轨迹,同一个轨迹池的轨迹保存在同一个子表中;元数据表除了保存轨迹池和轨迹对应关系,还保存该轨迹的唯一ID号,以及时空范围、最后一次更新时间、所采用的坐标系、时空精度误差等等源数据。
所述步骤3中对存储层的源空间数据进行建模与处理,存储层的源数据是对连续的运行轨迹的离散采样数据存储,离散的采样点是难以解读的,所以需要将其进行整体或局部建模,并提供包括截取、投影、度量、拟合等内部加工函数。得到轨段数据,因为中间数据需要在数据库集群环境下进行交换,为了提高集群节点之间的交换效率,所以提出轨段概念。对源空间数据进行操作后得到轨段数据,每个轨段是一个虚拟的轨迹子段,它只是对一个轨迹特定时间、空间范围内连续轨迹段的元数据表示,并没有记录真实数据(GPS序列),所以轨段结构简单,单项数据的尺寸小而固定,数据规模很小,适合在数据库中作为中间数据类型进行计算与加工。对源空间数据进行操作后得到轨段数据,每个轨段数据对应着某条轨迹的子段,它负责保存该轨段的数据分布特性,比如数据划分效率、时间区间、空间闭包等功能,但是只有经过实例化的轨段才具有真实数据。
所述步骤4在基于轨段数据的基础上,提供时空数据分析的复杂查询功能,其中所依赖的支撑函数包括数据实例化、格式转换和I/O操作等。可以提供包括基于语义的轨迹特征分析以及其他复杂功能,如轨迹推荐(给出一组点或一条轨迹,找出经过这些点的其他相似轨迹)和轨迹聚类(给定一组轨迹,找出并行时间足够长的轨迹子组来),以及轨迹异常检测(给定一组轨迹,找出其中可能存在的异常轨迹)。
本发明与现有技术相比的优点和积极效果如下:
(1)本发明支持大规模高并发的数据注入,在数据库中以扩展方式进行相关的用户定义数据类型和用户定义函数,并提供了四种源轨迹数据注入数据库的方法,以“元数据表+数据子表”的方式进行数据组织,确保大规模高并发的数据注入的实时运行。
(2)本发明支持复杂的数据分析场景,可以根据数据库的标准SQL接口来访问轨迹相关的扩展函数,并提供了不同的数据输出方式以应对基于语义的轨迹特征分析以及其他复杂功能的应用,扩展了方法的应用范围。
附图说明
图1为本发明的实施例流程图。
具体实施方式
如图1所示,本发明实例建立的面向数据库的轨迹大数据存储方法为:利用信息采集终端对某一具有位置信息采样的对象所处的状态信息如经纬度、速度等等进行信息采集并通过必要的传输设备将采集到的信息发送到数据处理系统,在数据处理系统,对接收到的原始数据信息进行必要的噪音过滤和数据清洗,之后将简单处理过的数据信息直接注入数据库,对数据库中的源空间数据进行建模与处理,并通过截取、投影、度量、拟合等内部函数操作,得到轨段数据,并在轨段数据的基础上,提供时空数据分析的复杂查询功能。本发明方法提供源时空采样数据的高并发注入、轨迹数据查询计划高效执行和丰富的轨迹语义查询扩展框架,涉及时空轨迹数据在数据库管理系统中的存储、表征与查询等环节,充分考虑实践性,具有大规模源数据并发加载、轻量级轨迹数据表征和灵活查询处理等先进技术特征。以目前世界上用户最多的开源数据库PostgreSQL及其集群方案(如PG-XL,PG-XC,GPDB)为例,说明一下如何在其中实施本发明所提方法,对本发明的具体实施方式做详细描述。
具体实现步骤如下:
该框架分为三层,分别为存储层,轨迹层和语义层:
1、存储层,负责保存源时空采样数据,除了进行必要的噪音过滤和数据清洗外,不对数据进行太多加工,比如将GPS采样直接注入数据库。这么做的对数据库的好处是:短事务、高并发、可水平扩展。轨迹大数据注入的数量和速度都会对数据库系统造成致命威胁,比如占用连接池、消耗锁资源、耗尽内存空间等,所以除了基本的数据清洗和噪音过滤外,对于数据注入不能进行太复杂的处理。
在数据库中以extension方式的方式实现Trajectory相关的用户定义数据类型UDT和用户定义函数UDF。关于计算几何相关算法,可以基于GEOS库和GDAL库两个开源的OSGeo标准库实现。关于时空索引,可以基于PostgreSQL的GiST索引框架进行扩展。对于需要数据分发的场景(如GPDB),可以采用三种方式进行解决:增加时空数据的分发策略,提供基于UDF的数据分发机制,或通过扩展不可见列来保存数据降维数据(如保存其GeoHash值,后者为一维字符串,可以适用于原有分发策略)。
数据注入:有四种方式可以将轨迹源数据注入数据库,一种是调用trajectory.append()函数操作trajectory的meta-data元数据表;一种是直接通过SQL的INSERT语句往raw源数据表中添加新的时空采样值;或者通过数据库的COPY TO语句进行DDL操作;最后一种是通过ETL工具进行加载。数据注入方式的灵活性保证了本发明所提方法的实用性。
在存储层,数据将以“元数据表+数据子表”的方式进行组织具体形式如下:
(1)轨迹数据库由一组轨迹池构成,每个轨迹池由一组轨迹构成;
(2)轨迹池和子表的对应关系保存在元数据表中,元数据表中每一行对应一条轨迹,同一个轨迹池的轨迹保存在同一个子表中;
(3)元数据表除了保存轨迹池和轨迹对应关系,还保存该轨迹的唯一ID号,以及时空范围、最后一次更新时间、所采用的坐标系、时空精度误差等等源数据。
2、轨迹层,负责对存储层的源空间数据进行建模与处理,存储层的源数据是对连续的运行轨迹的离散采样数据存储,离散的采样点是难以解读的,所以需要将其进行整体或局部建模,并通过截取、投影、度量、拟合等内部函数操作,得到轨段数据,因为中间数据需要在数据库集群环境下进行交换,为了提高集群节点之间的交换效率,所以提出轨段概念。每个轨段是一个虚拟的轨迹子段,它只是对一个轨迹特定时间、空间范围内连续轨迹段的元数据表示,并没有记录真实数据(GPS序列),所以轨段结构简单,单项数据的尺寸小而固定,数据规模很小,适合在数据库中作为中间数据类型进行计算与加工。每个轨段数据对应着某条轨迹的子段,它负责保存该轨段的数据分布特性,比如数据划分效率、时间区间、空间闭包等功能,但是只有经过实例化的轨段才具有真实数据。
3、语义层,在基于轨段数据的基础上,提供时空数据分析的复杂查询功能,其中所依赖的支撑函数包括数据实例化、格式转换和I/O操作等。
数据查询:根据数据库的标准SQL接口来访问轨迹相关的扩展函数。数据的输出,可以通过SQL返回,也可以保存在单独的结果临时表中,仅返回该临时表的名称或者其ID信息。数据输出以OSGeo的字符串标准输出,亦或可以通过JSON格式进行输出,以便于直接服务于当前互联网应用。
可以提供包括基于语义的轨迹特征分析以及其他复杂功能,如轨迹推荐(给出一组点或一条轨迹,找出经过这些点的其他相似轨迹)和轨迹聚类(给定一组轨迹,找出并行时间足够长的轨迹子组来),以及轨迹异常检测(给定一组轨迹,找出其中可能存在的异常轨迹。
关于DOTS的内部查询函数定义及其完整列表,不在本发明范围内,本发明仅对起轨迹大数据的存储方法进行约定。
以上通过实例对本发明进行了详细的描述,本领域的技术人员应当理解,在不超出本发明的精神和实质的范围内,对本发明做出一定的修改和变动,比如对数据库返回数据的具体表示格式进行修改,或对索引的组织方式及搜索过程进行局部修改,仍然可以实现本发明的目的。
本发明未详细阐述部分属于本领域技术人员的公知技术。
- 还没有人留言评论。精彩留言会获得点赞!