一种面向图像检索的对象级深度特征聚合方法与流程
本发明属于数字媒体领域,涉及一种面向图像检索的对象级深度特征聚合方法。
背景技术:
基于内容的图像检索作为计算机视觉领域的一个重要研究问题,在过去的十年里受到国内外学者的广泛关注。基于内容的图像检索是指从图像数据库中查找出与查询图像相似的图像。因为拍摄时角度、距离、环境等因素的不同,会造成相似或相同的拍摄对象在不同图像有着很大的变化,如尺度、视角、布局等变化。因此生成一个对各种图像变化具有高鲁棒性的图像特征,是解决图像检索问题的关键。
相对于传统的基于人工设计的图像特征,基于学习的方法尤其是卷积神经网络已经在图像特征提取上显示出的强大的能力,在图像分类和目标检测等计算机视觉任务上取得了巨大的成功。在图像检索问题中,目前有基于全局和基于局部两种卷积神经网络特征表示方法。
基于全局的方法,直接使用卷积神经网络提取整幅图像的特征,作为最终的图像特征。但是因为卷积神经网络主要对全局空间信息进行编码,导致所得特征缺乏对图像的尺度、旋转、平移等几何变换和空间布局变化的不变性,限制了其对于高度易变图像检索的鲁棒性。
对于基于局部的方法,使用卷积神经网络提取图像局部区域的特征,然后聚合这些区域特征生成最终的图像特征。虽然这些方法考虑到了图像的局部信息,使得特征相对于全局方法对各类变化具有更高的鲁棒性,但是这些方法中仍有一些缺陷。例如使用滑动窗口的方法来得到图像区域(参考Yunchao Gong,Liwei Wang,Ruiqi Guo,Svetlana Lazebnik在European Conference on Computer Vision 2014年第392-407页发表的文章“Multi-scale orderless pooling of deep convolutional activation features”),因没有考虑到图像的颜色、纹理、边缘等视觉内容,产生大量无语义意义的区域,为之后的聚合过程带来冗余和噪声信息。另外,区域特征融合通常所使用的最大池化算法(参考Konda Reddy Mopuri,R.Venkatesh Babu在Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops 2015年第62-70页发表的文章“Object level deep feature pooling for compact image representation”),因只保留了特征的最大响应而没有考虑特征间的关联,丢失大量信息,降低了所得的最终图像特征的区分性。
本发明通过基于对象的方法来解决以上问题。在生成图像区域时,使用基于内容的无监督对象生成方法,即通过图像颜色、纹理、边缘等视觉信息以聚类的方式来生成图像区域。因为图像中同一个语义对象会有一定的视觉相似性,这样得到的图像区域在很大概率上会包含一个对象或者对象的一部分。同时,一幅场景图像通常是由一些对象构成,对这些对象的解析是理解场景的关键。因此基于内容生成的图像区域相对于简单的滑动窗口包含更多有语义意义的视觉信息,其特征描述也具有更高的区分性,同时基于对象特征进行融合,所得最终特征对场景中对象的空间布局变化也具有很好的鲁棒性。在聚合特征的过程时,采用VLAD(Vector of Locally Aggregated Descriptors)算法,先将图像区域特征进行聚类,然后统计一幅图像中所有区域特征与其相近聚类中心的累积残差来表示最终的图像特征。相对于最大池化算法,该方法考虑了区域特征间关联的同时对图像的局部信息有更细致的刻画,使得得到的最终图像特征对各类图像变换具有更高鲁棒性。
技术实现要素:
针对现有技术的不足,本发明提供一种面向图像检索的对象级深度特征聚合方法,生成对图像几何变换和对象空间布局变化具有高鲁棒性的图像特征用于图像检索应用。
本发明的技术方案为:
一种面向图像检索的对象级深度特征聚合方法,包括以下步骤:
步骤1,对数据库中的每一张图像采用Selective Search算法提取候选区域,生成很可能包含物体的图像候选区域。所述的Selective Search(Selective Search for Object Recognition)算法为一种利用视觉信息基于分层区域合并的图像分割方法,能够生成类独立且高质量的多尺度候选区域。相对于滑动窗口,包含物体的候选区域的特征描述具有更高的区分性,同时基于对象的方式也能提高融合特征对空间布局变换的鲁棒性。
步骤2,选择被广泛采用的卷积神经网络结构模型,并在公共数据库上对卷积神经网络进行预训练。
步骤3,采用训练完成的卷积神经网络提取所有图像候选区域的特征
3.1)将图像候选区域进行缩放填充到固定大小后,作为卷积神经网络的输入;
3.2)将卷积神经网络的全连接层FC7的输出作为该图像候选区域的描述特征。
步骤4,对步骤3得到的候选区域的描述特征采用主成分分析算法进行降维,将其维度降为N维,得到低维候选区域特征;降维能够减少之后计算的复杂度,提高效率。
步骤5,对步骤4得到的低维候选区域特征采用K均值聚类算法进行无监督聚类,聚成K个聚类中心。
步骤6,对步骤4得到的属于同一张图像的低维候选区域特征和步骤5得到的K个聚类中心,采用VLAD算法进行聚合,每张图像得到一个维度为N*K维的VLAD特征。所述的VLAD(Vector of Locally Aggregated Descriptors)算法为基于统计的融合方法,其统计了区域特征与其相近聚类中心的累积残差来表示最终的图像特征;相对于简单的池化算法,该算法对图像内容具有更加细致的描述,生成的特征对图像变换具有更高鲁棒性。
步骤7,对步骤6得到的VLAD特征采用主成分分析算法进行降维,将其维度降为D维,生成简洁的图像特征。降维能够减少相似度计算复杂度和噪声,其中图像间的相似度由图像特征间的欧式距离来度量。
本发明的有益效果为生成的图像特征具有对图像几何变换和空间布局变换的高鲁棒性,极大地提高了图像检索的准确率,其次得到的图像特征十分紧凑简洁,减少了图像间相似度计算的复杂度。
附图说明
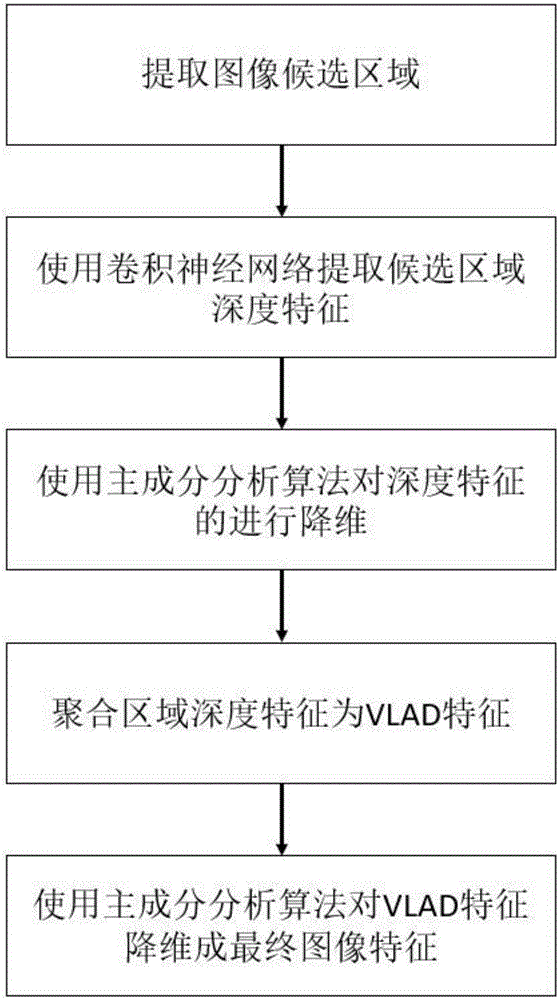
图1为本发明深度特征聚合的流程图。
图2为图像检索结果的示意图,最左图为查询图像,其余图像为检索到的相似图像,从左到右依次按照相似度由高到低排序。
具体实施方式
以下结合技术方案和附图详细叙述本发明的具体实施例。
实施例1:相似图像的检索
1.图1为本发明的流程图,首先对库图像的所有图像使用Selective Search算法的快速模式进行候选区域的提取,平均每张图像能够得到约2000个尺寸不一的候选区域。
2.本发明采用Krizhevsky等人的卷积神经网络结构Alex网络,输入为224*224的RGB图像,包括五层卷积层、三层最大池化层和三层全连接层。使用Caffe框架训练该网络,训练数据为ILSVRC12比赛中的1000类分类数据集。
3.网络训练完成后,将步骤1得到的候选区域通过填充和缩放到固定大小224*224后作为网络的输入,提取全连接层fc7的输出作为对应候选区域的特征,其大小为4096维。
4.使用主成分分析算法对所有候选区域的特征进行降维,得到低维候选区域特征,其中相应的字典维度大小为512*4096,即将所有候选区域的特征维度从4096维降到512维。
5.使用K均值聚类算法对低维候选区域特征进行无监督聚类,聚成256个聚类中心{c1,c2,…,c256}。
6.使用VLAD算法将每一张图像的低维候选区域特征编码为VLAD特征。首先,分配图像中每一个低维候选区域特征pj到离它最近的5个聚类中心rNN(pj),然后聚合所有低维候选区域特征减去其分配的聚类中心的残差,得到x作为图像的VLAD特征:
其中,j为一张图像中候选区域的下标;pj为下标为j的候选区域的低维特征;c1、ck分别为第一个和第K个聚类中心;rNN(pj)为离pj最近的5个聚类中心;wj1、wjk为pj分别与c1和ck的高斯核相似度,代表对应聚类中心的权重,对每一个候选区域,标准化它到最近5个聚类中心的权重和为1。最终每张图像得到相应的VLAD特征,其大小为512*256=131072维。
7.使用主成分分析算法对步骤6得到的VLAD特征进行降维,得到简洁的图像特征,其中相应的字典维度为512*131072,即将VLAD特征的特征维度从131072维降到512维。
8.对于查询图像,使用步骤1生成候选区域,步骤3提取候选区域特征,然后使用已经在步骤4,5训练完成的主成分分析算法字典和聚类中心,通过步骤6得到其对应的VLAD特征,最后使用步骤7训练完成的主成分分析算法字典降维,得到512维的简洁的图像特征。
9.计算查询图像的特征和库图像的图像特征间的欧氏距离,并按大小排序,距离值越小表示图像间相似度越高。图2为检索的结果的示意图。
- 还没有人留言评论。精彩留言会获得点赞!