一种超大规模数据的时序检索索引系统及方法与流程
本发明涉及数据处理领域,尤其是一种超大规模数据的时序检索索引系统及方法。
背景技术:
时序数据库的时序数据管理领域也涉及了对数据库中的数据的时序检索操作。时序数据库内部也是通过对时序数据建立数据索引从而高效地实现各种时序数据管理的功能。总的来说,时序数据库中的这些数据索引主要分成两大类,一类是基于B+树结构的索引,另外一类是基于R树的结构的索引。比如Time Index,Snapshot Index,Checkpoint Index,Archivable Time Index,Overlapping B+树等等几类比较具体的索引结构。
Timeline Index是由Martin Kaufman等人在2013年提出的一种索引结构,它主要服务于时序数据库里的时序数据管理,能够极大地提升时序数据库各种时序检索的效率。
如图1所示为时序数据库中数据格式,参数Start和End表示数据记录的有效时间的起止点,参数Name和Balance分别表示姓名和账目。
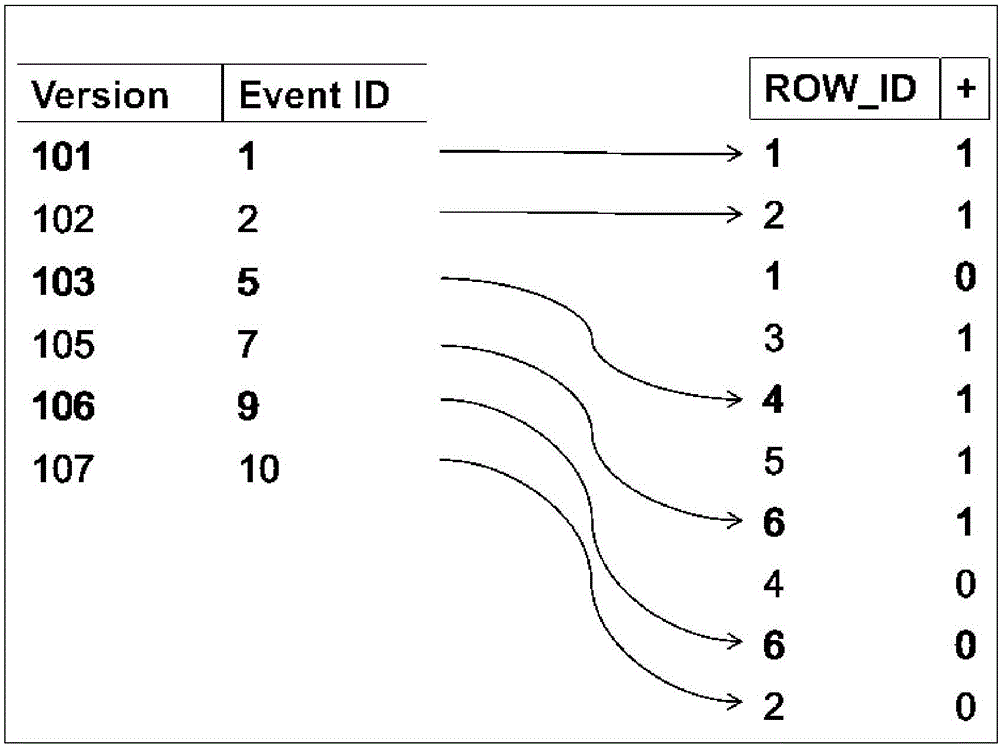
如图2所示,Timeline Index主要由图中左边的Version Map和图中右边的Event List两个部分组成。图1中的每条数据记录可以拆分为两个事件:在Start时刻记录被激活;在End时刻记录被撤销。Event List记录了所有的被激活和被撤销的事件(1为激活,0为撤销)。而Version Map记录了所有事件发生的顺序。通过对这两个列表的操作,Timeline Index能够实现高效的时序检索性能。
对于每张数据表,都需要建立一个对应的Timeline Index。Timeline index比原始的数据表要小很多,尤其是当原始数据表具有很多列属性的时候。
上述提到了各种时序数据库的时序索引都能够有效地解决时序数据库中的各种时序数据管理的问题,但是,它们有个共同的特点是它们都是为传统的关系型时序数据库而设计的,它们所面向处理的是常规规模的数据量,通常为几百万级别的数据,它们无法应对当前大数据时代10亿以上级别的超大规模数据所带来的技术挑战。当待处理的数据集的数据总量越来越大,上述的时序数据库的时序索引就会出现严重的性能和效率问题,导致无法在可接受的时间内返回有效的时序检索的结果。
术语解释
标准化时序数据:R=(ID,A,T,(S,E))是一条标准化时序数据;其中ID表示记录R在数据表中的行号,A表示时序数据本身的静态属性,T表示时序数据的时间点属性,(S,E)表示时序数据的真实有效时间范围[Start,End)。
静态属性:静态属性是指在时序数据中所有与时间无关的属性。
时序检索:在原始标准化时序数据集中检索满足特定时间约束的数据记录。时序检索主要包含三类:基于时间点条件的检索操作,基于时间段包含关系条件的检索操作和基于时间段相交关系条件的检索操作。
基于时间点条件的检索操作:给定具体的时间点M,找出全集U中的最大子集合D,使得D满足,且
基于时间段包含关系条件的检索操作:给定具体的时间范围[Start,End),找出全集U中的最大子集合D,使得D满足,且
基于时间段相交关系条件的检索操作:给定具体的时间范围[Start,End)。R=(ID,A,T,(S,E))是一条标准化时序数据。设L(R)=Max(Start,S),V(R)=Min(End,E)。找出全集U中的最大子集合D,使得D满足,且满足L(R)≤V(R)。
技术实现要素:
为了解决上述技术问题,本发明的目的是:提供一种用于超大规模数据可实现高效返回有效时序检索结果的索引系统。
为了解决上述技术问题,本发明的另一目的是:提供一种用于超大规模数据可实现高效返回有效时序检索结果的索引方法。
本发明所采用的技术方案是:一种超大规模数据的时序检索索引系统,包括有
垂直层级索引模块,包括有多层索引,每层索引均包括有哈希函数和多个数据集,所述原始数据通过第一层级索引的哈希函数映射至数据集中,所述数据集中数据通过下一层级索引的哈希函数映射至下一层级的数据集中;
时间轴索引模块,用于对最下层级索引中数据集的数据建立事件列表和时间列表;所述事件列表用于记录数据对应的事件在某个定点时间的激活状态,所述时间列表用于记录在某个定点时间之前的所发生的事件的总数。
进一步,所述垂直层级索引模块包括有三层索引。
进一步,所述多层索引中,最下层级索引用于存储热点查询信息,其余层级索引只存储映射关系数据。
进一步,所述热点查询信息包括有用户ID、时间属性、时间范围属性。
进一步,所述垂直层级索引模块还用于在原始数据的时间范围属性大于最下层级索引中时间范围属性时,将原始数据映射至其对应的所有数据集中。
进一步,所述时间轴索引模块用于将每一个层级索引中数据集中数据拆分为两个事件,分别用激活时间和撤销时间表示,并根据时间先后进行排序形成事件列表。
进一步,所述时间轴索引模块还用于记录在某个定点时间T之前的所发生的事件的总数,所述定点时间T的取值的间隔时间固定。
本发明所采用的另一技术方案是:一种应用上述超大规模数据的时序检索索引系统的索引方法,根据时间的有效时间起止点,从垂直层级索引模块中的数据集检索所需的信息,并返回所有检索到的数据集中的信息。
本发明的有益效果是:本发明系统通过设置层级索引模块和时间轴索引模块,将原始的大数据集经过层层的哈希映射,最终会被分配到若干个相对较小的数据集中去,使每一个小数据集上可以独立执行查询处理、数据加载、存储优化等操作,从而结合时间轴索引模块避免了时序检索操作的过程中进行全表扫描操作的风险,极大地提高了时序检索的速度。
本发明的有益效果是:由于层级索引模块和时间轴索引模块将原始的大数据集经过层层的哈希映射,最终会被分配到若干个相对较小的数据集中去,使每一个小数据集上可以独立执行查询处理、数据加载、存储优化等操作,从而结合时间轴索引模块使本发明方法避免了时序检索操作的过程中进行全表扫描操作的风险,极大地提高了时序检索的速度。
附图说明
图1为时序数据库追踪的数据格式示例;
图2为图1中数据对应的Timeline Index结构图;
图3为本发明系统的结构示意图;
图4为一对多映射关系示例;
图5为时间轴索引模块示例。
具体实施方式
下面结合附图对本发明的具体实施方式作进一步说明:
参照图1,一种超大规模数据的时序检索索引系统,包括有:
垂直层级索引模块,包括有多层索引,每层索引均包括有哈希函数和多个数据集,所述原始数据通过第一层级索引的哈希函数映射至数据集中,所述数据集中数据通过下一层级索引的哈希函数映射至下一层级的数据集中;
时间轴索引模块,用于对最下层级索引中数据集的数据建立事件列表和时间列表;所述事件列表用于记录数据对应的事件在某个定点时间的激活状态,所述时间列表用于记录在某个定点时间之前的所发生的事件的总数。
进一步作为优选的实施方式,如图3所示的垂直层级索引模块包括有三层索引,图中每一个层级索引均包括有哈希函数和多个数据集,其中每一个数据集又对应一个下一层级的索引。
垂直层级索引建立的目的在于把大数据变小。每一个层级索引都包括一个哈希函数映射,这个哈希函数的实现具体取决于数据的属性以及查询的需求。原始的大数据集经过层层的哈希映射,最终会被分配到若干个相对较小的数据集中去。在每一个小数据集上,可以独立执行查询处理、数据加载、存储优化等操作。
如图3所示,当原始数据经过第一层索引时,它会根据第一层的哈希函数被映射到若干个数据集中,从而使得一个大数据集分成若干个相对小的数据集。而后,每个数据集的数据都会通过第二层索引,映射到更多更小的数据集中去。如此类推,第二层索引里面的每个数据集的数据都会通过第三层索引,可通过精细条件的哈希函数,映射到更小的数据集中去。通过三层索引的层层转发过滤,一个大数据集最终会变成很多个底层数据集。
进一步作为优选的实施方式,所述多层索引中,最下层级索引用于存储热点查询信息,其余层级索引只存储映射关系数据。如图3所示,第一、二层级的索引中不存储任何的实际数据,只是相当于路由器,用于把数据转发到下一层。
进一步作为优选的实施方式,所述热点查询信息包括有用户ID、时间属性、时间范围属性。层级索引保证每个底层数据集都是按Start时间有序的,虽然会使得建立层级索引的时间开销有所增大,但是它却能极大地提高查询的性能以及降低查询复杂度。
针对不同的时间属性,上述的哈希映射采取的具体映射的策略有所不同。对于时间点属性,它必定会属于特定的某一天,在这种情况下的哈希映射必定是一对一的,也就是说当前的数据记录通过三层索引的层层转发,最终必定会转发到某一个特定的底层数据集中。而对于时间范围属性[S,E),当这个范围是属于一天之内的时候,其三层哈希映射也是一对一的。但是也有可能出现的一种状况是[S,E)跨越了几天,跨越了几个月甚至跨越了几年的情况。
因此,对于上述时间范围属性跨度较大的情况,进一步作为优选的实施方式,所述垂直层级索引模块还用于在原始数据的时间范围属性大于最下层级索引中时间范围属性时,将原始数据映射至其对应的所有数据集中。
例如,一条数据记录了一位住客在某一家酒店从2014年3月10日开始登记入住一直到2014年5月12日才退房。在这种情况下,哈希映射不再是一对一的了,这条数据记录不会被映射到特定的某一天所对应的底层数据集中。本发明方法采取的是一对多的哈希映射,如图4所示,把这条数据记录映射到从2014年3月10日到2014年5月12日所覆盖的每一天所对应的底层数据集中去。虽然一对多的哈希映射会造成空间信息冗余的产生,但是这些冗余却极大地加速了时间轴索引的索引效率,使得相应的查询算法更加高效更加准确。此外,因为索引里面只会存储数据的时间属性和一些关键的静态属性,因此,其冗余所消耗的空间其实十分有限。
而本发明应用超大规模数据的时序检索索引系统的索引方法,根据时间的有效时间起止点,即参数Start和End,从垂直层级索引模块中的数据集检索所需的信息;例如图4所示的数据记录覆盖了很多天的数据,因此数据将映射到每一天所对应的底层数据集中去,所以需要返回所有检索到的数据集中的信息,虽然这样的数据在建立索引时会造成空间信息冗余的产生,但是本方法进行时序检索时却极大地加速了时间轴索引的索引效率,使得相应的查询算法更加高效更加准确。
进一步作为优选的实施方式,所述时间轴索引模块用于将每一个层级索引中数据集中数据拆分为两个事件,分别用激活时间和撤销时间表示,并根据时间先后进行排序形成事件列表。
设某天所对应的原始数据集为D,|D|=n。Ri为D数据集里的记录,满足Ri∈D,Ri=(ID,A,T,(S,E)),i=1,2,3,…,n则对于每条数据记录Ri,可拆分为两个事件:1、记录Ri在S时间被激活;2、记录Ri在E时间被撤销。然后对所有由D中拆分出来的事件按时间先后顺序进行排序,排序后的结果就是事件列表。因此,事件列表中的每一条数据Evt,其形式化定义如下:
Evt=(EID,DID,T,V)
其中,EID表示当前时间在事件列表中的ID,此值唯一;DID表示当前事件的数据记录在底层数据集中的ROW_ID;T表示此事件发生的时间;V表示该事件是被激活还是被撤销,1表示被激活,0表示被撤销。
进一步作为优选的实施方式,所述时间轴索引模块还用于记录在某个定点时间T之前的所发生的事件的总数,所述定点时间T的取值的间隔时间固定。
时间列表负责记录在某个定点时间之前的所发生的事件的总数。定点时间T的取值范围是为0:00≤T≤24:00,取值的间隔时间固定。
具体的间隔大小可视具体应用场景的数据量而定,当数据量过大的时候,则调整为更小的时间间隔做一次记录,比如15分钟做一次记录。当数据量小的时候可以调整为更大的时间间隔做一次记录,比如3小时做一次记录。时间列表里存储的数据TM的形式化定义如下:
TM=(T,EID,[C])
其中T表示整点时间值,EID指向事件列表的EID属性,表示所有EID小于当前EID的事件,都是在T时刻前发生的,即表示截止T时刻前总共有value(EID)个事件发生。[C]表示Checkpoint,是一个列表结构,它记录着到截止某个时刻的所有的有效记录的ROW_ID编号。
如图5所示是一个时间轴模块的具体的应用例子,比如说数据表中的第一条数据(ROW_ID为1)显示陈一在1:03分在就某酒店Check-in,在3:46分的时候Check-out。因此上述数据记录就能被拆分为两个事件:1、ROW_ID为1的数据在1:03被激活;2、ROW_ID为1的数据在3:46被撤销。所述时间轴索引模块将这两个事件记录到事件列表中。对应的时间列表中,其第一条数据表示,截止于2:00为止,最后一个发生的事件是编号为1的事件,仍然处于激活状态的数据记录的集合是{1}。
以上是对本发明的较佳实施进行了具体说明,但本发明创造并不限于所述实施例,熟悉本领域的技术人员在不违背本发明精神的前提下还可以作出种种的等同变换或替换,这些等同的变形或替换均包含在本申请权利要求所限定的范围内。
- 还没有人留言评论。精彩留言会获得点赞!