一种基于双向张量分解模型的群推荐方法与流程
本发明属于群推荐领域,具体地说是一种基于双向张量分解模型的群推荐(BTF-GR)方法
背景技术:
社交网络早已成为社交媒体环境中一个重要活动部分,用户在社交网络平台会自发组成群体,而捕捉每一个群体的偏好将有利于我们对用户群体进行深入的行为分析,进而为群体推荐目标产品和服务。但群体推荐不同于个体推荐,因为群体通常是由具有多样化偏好的用户构成的,所以群体推荐不易实现。群推荐的核心任务就是要聚合个体偏好以产生一个群体推荐结果,但现有聚合策略都是将群体偏好的形成建模为一个单向过程,虽然即群体偏好是个体偏好聚合的结果,但在真实的社交环境中群体和个体存在交互作用,而现有聚合策略并不能捕捉群体对个体偏好产生的影响,导致群推荐准确性不高;用户的个体特性和群体的群体特性呈现多样化,所以群体对个体偏好的影响存在差异性,但现有聚合不能刻画这种影响的差异,使得群推荐结果并不理想;而且当现有群推荐方法应用于稀疏数据集时,推荐性能明显下降,所以现有群推荐方法并不能很好地解决大数据环境下的数据稀疏问题,不具备较好鲁棒性。
近年来,分解成为最受欢迎的推荐技术,通过分解可以描述用户与产品的交互作用,虽然将张量分解应用于标签推荐、广告点击预测等推荐问题中取得了较好的推荐性能,但张量分解的时间复杂度高,受限于数据规模,所以并不能很好地适用于大数据环境下的群推荐问题。
技术实现要素:
本发明针对现有群推荐策略存在的不足之处,提出一种基于双向张量分解模型的群推荐方法,以期能在个体偏好建模中体现群体与个体的交互作用,并刻画群体对个体偏好影响的差异性,通过聚合准确的个体偏好形成准确的群体偏好,从而提升群推荐精度,并适用于大规模、稀疏的数据环境下精准、稳定的群推荐。
为达到上述目的,本发明采用的技术方案为:
本发明一种基于双向张量分解模型的群推荐方法的特点是按照如下步骤进行:
步骤一、定义一个表示群体G、用户U和产品I的交互关系:所述交互关系DS中,G={G1,...,Gg,...,G|G|}表示群体集合,Gg表示任意第g个群体,1≤g≤|G|;U={U1,...,Uu,...,U|U|}表示用户集合,Uu表示第u个用户;I={I1,...,Ii,...,I|I|}表示产品集合,Ii表示第i个产品,
步骤二、利用式(1)构建第g个群体中第u个用户对第i个产品的张量分解模型
式(1)中,表示第g个群体中第u个用户对第i个产品的个体偏好;表示第u个用户对自身的个体偏好的影响,表示第u个用户所属的第g个群体对第u个用户的个体偏好的影响,bi表示第i个产品的偏差;表示第u个用户的个体特性对第u个用户的权重;Uu,l表示第u个用户的第l个隐变量,ku表示第u个用户的隐变量个数;表示与第u个用户产生交互的第i个产品的第l个隐变量;表示第u个用户所属的第g个群体的群体特性对第u个用户的权重;Gg,m表示第g个群体的第m个隐变量,kg表示第g个群体的隐变量个数;表示与第g个群体产生交互的第i个产品的第m个隐变量;
步骤三、利用贝叶斯个性化排序方法对所述张量分解模型进行优化求解,得到所述张量分解模型中的各个参数值;
步骤四、利用式(2)得到第g个群体对第i个产品的群体偏好从而获得第g个群体对所有产品的群体偏好:
式(2)中,Δ(·)为平均聚合函数;
步骤四、将所述第g个群体对所有产品的群体偏好进行降序排序,并选择前N个群体偏好所对应的产品作为推荐产品列表推送给第g个群体。
本发明所述的群推荐方法的特点也在于,所述步骤三是按如下步骤进行:
步骤3.1、利用式(3)得到所述张量分解模型的目标函数
式(3)中,表示第g个群体中第u个用户对第ia个产品的个体偏好与对第ib个产品的个体偏好的差值;表示第ia个产品属于第g个群体中第u个用户的正反馈集合,所述正反馈集合为与第g个群体中第u个用户交互过的所有产品集合;表示第ib个产品属于第g个群体中第u个用户的负反馈和缺失值集合,负反馈和缺失值集合为与第g个群体中第u个用户没有交互过的所有产品集合;表示logistic函数;Θ表示所述张量分解模型中的参数集合,并有λΘ表示正则化参数;
步骤3.2、初始化参数集合Θ和正则化参数λΘ;
步骤3.3、遍历所述第g个群体中第u个用户的正反馈集合中的所有产品,并在遍历每个产品的过程中从所述第g个群体中第u个用户的负反馈和缺失值集合中任意选择一个产品;
步骤3.4、利用随机梯度下降方法求得所述参数集合Θ中参数的梯度;在参数和为定值时,对所述参数分别进行迭代更新,直到收敛为止,从而获得参数的最优值;
步骤3.5、遍历所述第g个群体中第u个用户的正反馈集合中的所有产品,并在遍历每个产品的过程中从第g个群体中第u个用户的负反馈和缺失值集合中任意选择一个产品;
步骤3.6、利用随机梯度下降方法求得所述参数集合Θ中参数和的梯度;在参数为最优值时,对所述参数和分别进行迭代更新,直到收敛为止,从而获得参数和的最优值。
与已有技术相比,本发明的有益效果体现在:
1、本发明首次将群体偏好的形成建模为聚合个体偏好和群体对个体偏好产生影响的双向过程,相比于现有群推荐方法将群体偏好建模为聚合个体偏好的单向过程,本发明的建模思想更符合群体偏好形成的真实场景,本发明不仅可以捕捉群体与个体之间的交互作用,而且还可以刻画群体对不同用户的个体偏好产生影响的差异性,从而有效提高了群推荐精度,获得了满意的群推荐结果。
2、本发明通过将用户、群体、产品三者建模为成对交互的张量分解,解决了张量分解模型存在的高时间复杂度问题,同时本发明提出的张量分解模型由于集成了群体偏好,可以有效减少数据稀疏的负面影响,所以本发明使得张量分解模型可以应用于大数据环境下的群推荐问题,本发明中成对交互的张量分解模型可以在线性时间复杂度内获得更高的预测质量。
3、大数据环境下存在大量稀疏的隐反馈数据,直接通过预测偏好分值求解模型的方法预测的个体偏好存在较大偏差,从而导致推荐精度和满意度下降,而本发明将模型求解转化为排序问题,排序方法针对稀疏的隐反馈数据具有很好的适应性,可得到准确的偏好排序。本发明使用贝叶斯个性化排序方法求解模型可获得准确的个体偏好排序,进而聚合为准确的群体偏好排序,所以有效提升了群推荐的准确性和满意度。
4、本发明为用户设置了个性化权重,用以捕捉个体偏好和群体影响对不同用户的差异化作用,个性化权重的设置使得模型更加贴近个体偏好形成的真实情景,有助于获得更好的群推荐精度。
5、真实群推荐环境中,通常采取的策略是提供一个尽可能长的推荐列表以实现尽可能多地涵盖群体中所有用户的偏好。当推荐列表越长,本发明所提出的群推荐方法不仅具有较好鲁棒性,而且性能更优,所以本发明适用于群推荐环境。
6、大规模群体因为偏好多样性增加,使得针对大规模群体的推荐十分困难和不精确,而本发明提出的群推荐方法针对不同规模的群体都具有较好稳健性。
7、本发明可用于家电和食品等实体产品、音乐和电影等数字产品、旅游路线和度假安排等服务产品的群推荐系统,可以在电脑和手机的网页和APP等平台使用,应用范围广泛。
附图说明
图1为本发明的流程示意图;
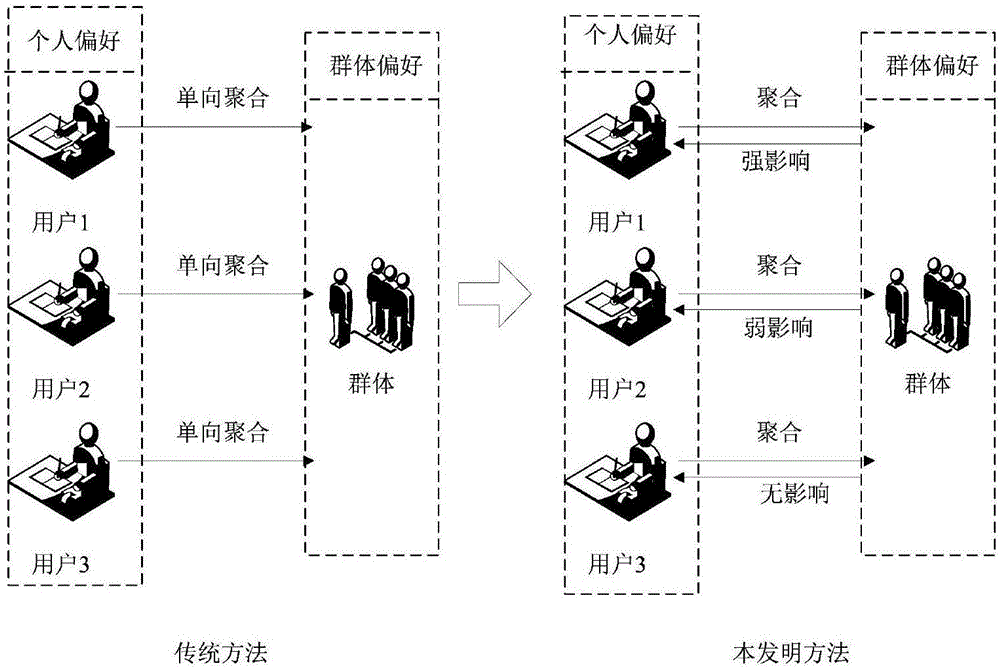
图2为本发明所提方法与传统方法的对比图;
图3为本发明的数据表示和解决方案;
图4a为本发明与基准算法的平均准确率均值对比图;
图4b为本发明与基准算法的推荐列表长度为5的召回率对比图;
图4c为本发明与基准算法的平均排序倒数对比图;
图5a为个性化权重与固定权重的平均准确率均值对比图;
图5b为个性化权重与固定权重的推荐列表长度为5的召回率对比图;
图5c为个性化权重与固定权重的平均排序倒数对比图。
具体实施方式
本发明提出的张量分解模型是一种双向的成对交互式张量分解模型,即群体偏好的形成为双向过程,而且将用户、群体、产品三者建模为成对交互关系。本发明提出的群推荐方法建立在以下两点假设的基础上:
1、一个群体中的每个用户对于产品都有一种内在偏好。每个用户对于一个产品的内在偏好可能会受到所属群体的影响;
2.群体对于个体偏好的影响在用户之间是显著不同的。用户的最终偏好是内在偏好和群体影响的综合作用结果。
本实施例中,如图1所示,一种基于双向张量分解模型的群推荐方法,按照如下步骤进行:
步骤一、定义一个表示群体G、用户U和产品I的交互关系:交互关系DS中,G={G1,...,Gg,...,G|G|}表示群体集合,Gg表示任意第g个群体,1≤g≤|G|;U={U1,...,Uu,...,U|U|}表示用户集合,Uu表示第u个用户;I={I1,...,Ii,...,I|I|}表示产品集合,Ii表示第i个产品,传统群体偏好建模只考虑用户U和产品I的交互,而本发明不仅考虑了用户U和产品I的交互,同时也考虑了群体G和用户U之间的交互,而且针对不同用户这种交互作用的强度存在差异,本发明提出的群体偏好建模思想与传统的群体偏好建模思想的区别如图2所示。
步骤二、将群体G、用户U和产品I的交互关系进行成对交互式分解,群体G、用户U和产品I的数据表示和本发明提出的成对交互式张量分解模型如图3所示,图3还显示了本发明提出的张量分解模型与传统的张量分解模型的差异,再利用式(1)便可构建第g个群体中第u个用户对第i个产品的张量分解模型
式(1)中,表示第g个群体中第u个用户对第i个产品的个体偏好;表示第u个用户对自身的个体偏好的影响,表示第u个用户所属的第g个群体对第u个用户的个体偏好的影响,bi表示第i个产品的偏差;表示第u个用户的个体特性对第u个用户的权重;Uu,l表示第u个用户的第l个隐变量,ku表示第u个用户的隐变量个数;表示与第u个用户产生交互的第i个产品的第l个隐变量;表示第u个用户所属的第g个群体的群体特性对第u个用户的权重;Gg,m表示第g个群体的第m个隐变量,kg表示第g个群体的隐变量个数;表示与第g个群体产生交互的第i个产品的第m个隐变量;
步骤三、利用贝叶斯个性化排序方法对张量分解模型进行优化求解,得到张量分解模型中的各个参数值,即将个体偏好的直接求解转化为个体偏好的排序;
步骤3.1、求解张量分解模型即给定第g个群体中的第u个用户,求得第u个用户的最优参数,所以根据贝叶斯个性化排序方法得出张量分解模型的学习目标就是最大化式(2)中的后验概率
式(2)中,Θ表示张量分解模型中的参数集合,并有表示第g个群体中的第u个用户对所有产品的偏好排序;表示由样本集得到的第g个群体中的第u个用户对所有产品的个体偏好似然函数;表示参数的先验知识。其中似然函数可以表示为公式(3):
式(3)中,表示第g个群体中的第u个用户对所有产品的偏好排序中,产品排在产品前面,且每对产品的排序独立于其他产品对的排序;表示第g个群体的第u个用户相比于产品ib对于产品的个体偏好概率,同时可以表示为公式(4):
式(4)中,表示第g个群体中第u个用户对第ia个产品的个体偏好与对第ib个产品的个体偏好的差值;表示logistic函数。根据这种转化方式,并假设参数的先验知识服从均值为0,协方差矩阵为∑Θ的高斯分布,则公式(2)中后验概率的对数形式可以简化为公式(5):
张量分解模型的学习目标便转化为最小化公式(6)的目标函数
式(6)中,表示第ia个产品属于第g个群体中第u个用户的正反馈集合,正反馈集合为与第g个群体中第u个用户交互过的所有产品集合;表示第ib个产品属于第g个群体中第u个用户的负反馈和缺失值集合,负反馈和缺失值集合为与第g个群体中第u个用户没有交互过的所有产品集合;λΘ表示正则化参数;
步骤3.2、初始化参数集合Θ和正则化参数λΘ;
步骤3.3、遍历第g个群体中第u个用户的正反馈集合中的所有产品,并在遍历每个产品的过程中从第g个群体中第u个用户的负反馈和缺失值集合中任意选择一个产品;
步骤3.4、利用随机梯度下降方法求得参数集合Θ中参数的梯度;在参数和为定值时,对参数分别进行迭代更新,直到收敛为止,从而获得参数的最优值;
步骤3.5、遍历第g个群体中第u个用户的正反馈集合中的所有产品,并在遍历每个产品的过程中从第g个群体中第u个用户的负反馈和缺失值集合中任意选择一个产品;
步骤3.6、利用随机梯度下降方法求得参数集合Θ中参数和的梯度;在参数为最优值时,对参数和分别进行迭代更新,直到收敛为止,从而获得参数和的最优值。
步骤四、利用式(7)得到第g个群体对第i个产品的群体偏好从而获得第g个群体对所有产品的群体偏好:
式(7)中,Δ(·)为平均聚合函数;
步骤四、将第g个群体对所有产品的群体偏好进行降序排序,并选择前N个群体偏好所对应的产品作为推荐产品列表推送给第g个群体。
针对本发明方法进行实验论证,具体包括:
1)准备标准数据集
本发明使用CiteULike和Last.fm这两个在推荐领域应用广泛的数据集作为标准数据集验证本发明提出的群推荐方法的性能。第一个数据集CiteULike是一个科学研究者在线社区网站。在CiteULike上,学者可以使用标签标注学术文章,同时也可以创建和加入群来分享引用的文章。实验使用的CiteULike数据集包含130321个“群体-用户-产品”三元组,其中的11168篇文章由来自584个群体的1310个用户标注而成,平均群体大小是5.4,从每个群体中选出前10篇文章作为测试集,剩余的数据作为训练集;第二个数据集Last.fm是个面向音乐迷的在线社区网站。在Last.fm上,音乐迷们可以标注音乐家或者曲目,创建或者和有类似品位的人形成群体。实验使用的Last.fm数据集包含了317907个“群体-用户-产品”三元组,其中的1992位音乐家由来自2716个群体的3605个用户标注而成,均群体大小是21.2,选择每个群体中的前10位音乐家作为测试集,剩余的数据用于训练集。
2)评价指标
采用推荐长度为N的召回率(Rec@N),平均准确率均值(MAP)和平均排序倒数(MRR)作为本实验的评价指标。召回率评估群推荐系统返回所有相关产品的能力,平均准确率均值和平均排序倒数揭示在推荐列表中相关产品的准确性。推荐列表长度为N的召回率Rec@N计算公式为:
式(8)中,Nrelated是在排序列表和测试集中同时出现的产品数目;N是测试集中相关产品的数目。
平均准确率均值计算公式为:
式(9)中,其中|G|是测试集中群体的数目,是一个指示变量,如果群体的推荐列表中排名第n的产品也出现在测试集中,则值为1,其余情况都为0。表示的推荐结果的准确率,公式为:
式(10)中,其中是在排序列表和测试集中同时出现的产品数目,是推荐列表中相关产品的数目。
平均排序倒数是第一个排序正确的产品的逆的连乘,计算公式为:
3)在标准数据集上进行实验
为了验证本发明所提模型的有效性,我们将本发明提出的用于群推荐的双向张量分解(BTF-GR)模型和4种基准方法进行比较,4种基准方法为:基于用户的协同过滤(UserCF)方法—基于用户的最近邻(UserKNN)算法,基于产品的协同过滤(ItemCF)方法—基于产品的最近邻(ItemKNN)算法,基于隐反馈的矩阵分解(IMF)方法,基于矩阵分解的贝叶斯个性化排序(BPRMF)方法。在CiteULike数据集和Last.fm数据集上用5种方法进行建模和推荐,并将推荐结果进行比较。实验结果如图4a、图4b、图4c所示。与4种基准方法相比,本发明提出的群推荐方法在Last.fm和CiteULike数据集上都获得了更优的推荐精度,且对于稀疏的隐反馈数据,本发明的性能优势更加明显。
为了检测个性化权重对于本发明所提模型的影响,我们通过为所有个体设置统一的固定权重构造了一个变体模型,将其作为对照实验。图5a、图5b、图5c中实线表示本发明的双向张量分解(BTF-GR)模型的结果,虚线是变体模型的结果。结果显示在CiteULike数据集和Last.fm数据集上,双向张量分解(BTF-GR)模型总是优于具有固定权重的变体模型。这个结果说明,用户偏好和群体影响在个人偏好的形成过程中发挥不同的作用,而双向张量分解(BTF-GR)模型可以捕获这种差异,从而获得更好的推荐精度。
为验证本发明所提模型的鲁棒性,以及了解与4种基准方法的鲁棒性对比情况,我们通过改变推荐列表长度和群体规模,分别设计了2个实验组进行验证。实验结果显示本发明的双向张量分解(BTF-GR)模型在推荐列表长度和群体规模上都具有具有较好的鲁棒性,且推荐精度始终优于4种基准方法,同时当推荐列表越长,本发明的双向张量分解(BTF-GR)模型性能越优,即本发明适用于群推荐环境。
- 还没有人留言评论。精彩留言会获得点赞!