一种基于MapReduce的度量空间相似连接处理方法与流程
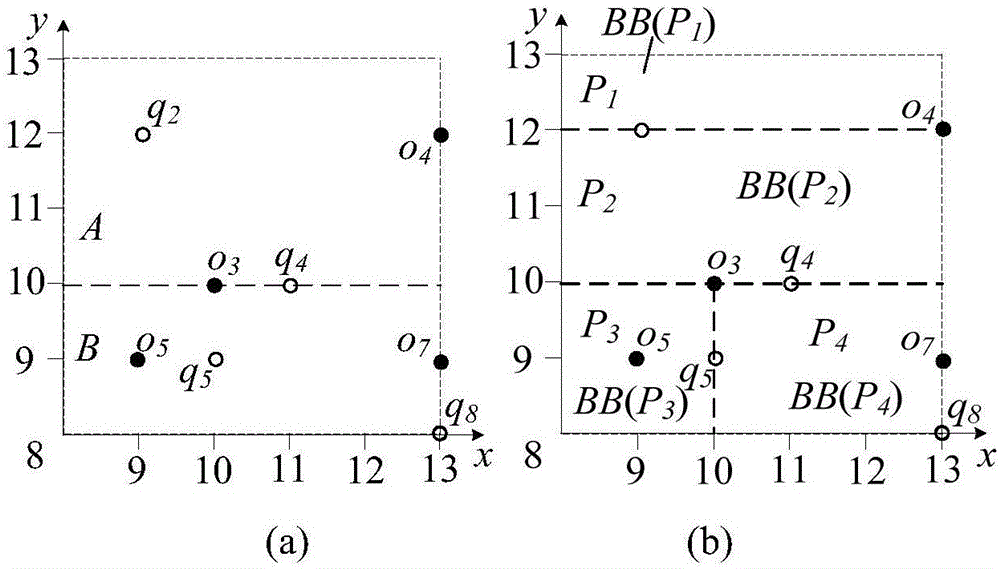
本发明涉及计算机数据库领域中度量空间下的连接处理技术,特别是涉及一种基于MapReduce的度量空间相似连接处理方法。
背景技术:
度量空间相似连接是指:在给定的度量空间中两个数据集之间的笛卡尔积中找到所有相似性高于(或者距离小于)给定阈值的数据对。度量空间相似连接处理被广泛地应用在社会的各个领域中,其中包括重复数据检测和删除。
随着以社交网络、电子商务为代表的新型信息发布方式的不断涌现,以及云计算、物联网计算机技术的兴起,数据正以前所未有的速度不断地增长和累积,随之而来是以MapReduce为代表的各类大数据分布式系统蓬勃发展,大数据的时代已经到来。在这样一个大数据时代,传统集中式的相似连接算法已经渐渐满足不了当前快速地对海量数据进行重复数据检测和删除的要求。因此,设计一个具有高可扩展性、高效率的分布式相似连接处理方法成为了学术界与工业界的迫切需求。
针对基于MapReduce的度量空间相似连接处理方法,目前国内外学者已经做出了一些工作。其中,最具代表性的算法是基于球形划分技术的MAPSS方法和基于二分超平面划分技术的ClusterJoin方法。然而,这些方法主要有两个缺陷:(1)这些方法随机地选择划分的中心点,这可能导致数据划分不均衡,需要对数据进行进一步的重划分;(2)这些方法只关注数据划分方案,而忽略了数据划分完成后,对各划分内部数据之间进行相似度计算时,设计剪枝策略以提高效率的方式。我们的方法很好地弥补了上述两个缺陷,提升了相似连接处理的效率,高效地对重复数据进行检测和删除。
技术实现要素:
针对现有技术的不足,本发明提供一种基于MapReduce的度量空间相似连接处理方法,该方法基于MapReduce分布式计算框架,先在Map阶段对给定的数据集进行划分,而后在Reduce阶段进行相似性计算以得到重复数据结果,进而进行删除。
为了达到上述目的,本发明所采用技术方案如下:一种基于MapReduce的度量空间相似连接处理方法,具体包括如下步骤:一种基于MapReduce的度量空间相似连接处理方法,该方法的步骤如下:
(1)对应用中给定的度量空间数据集进行随机采样,得到样本数据;
(2)对得到的样本数据进行支枢点选择;
(3)将应用中给定的整个数据集(包括样本数据)从度量空间映射至向量空间;
(4)利用步骤(3)中得到的映射到向量空间的样本数据构建KD树,得到相应的空间划分;
(5)在Map阶段,根据步骤(4)中得到的空间划分,对步骤(3)中得到的整个数据集进行划分;
(6)在Reduce阶段对划分后的数据进行相似度计算,得到相似连接的处理结果。
进一步的,所述步骤(2)具体为:
(2.1)在样本数据中找出离群点作为支枢点的备选集合;
(2.2)根据支枢点的选择目标,对备选集合中的点进行增量式的贪心选择。
进一步的,所述步骤(3)具体为:对于每一个在度量空间中的数据,计算与步骤(2)中得到的支枢点之间的距离,并以求得的距离作为向量空间中各维度的坐标值,以得到度量空间数据在向量空间中的坐标。
进一步的,所述的步骤(4)具体为:对步骤(3)中得到的样本数据,构建KD树,得到的KD树中包含数据点个数相等的叶子节点,各叶子节点对应的空间区域即为空间划分的结果。
进一步的,所述的步骤(5)在Map阶段,将步骤(3)中得到的映射至向量空间后的整个数据集划分至步骤(4)中得到的相应空间划分中去。
进一步的,所述步骤(6)具体为:
(6.1)在Reduce阶段,对于每个划分,将各划分内部的数据在随机选定的一个维度上,使用快速排序算法进行排序整理;
(6.2)利用平面扫描法,对排序后的数据集进行度量空间距离计算以验证结果,并结合区域过滤技术对距离计算进行剪枝。
进一步的,所述区域过滤技术是指:若两个数据对象在向量空间任意维度上的差值大于给定的距离阈值,则它们不可能成为最终结果,从而可以不经过度量空间距离计算就被剪掉。
本发明具有的有益效果是:本发明在MapReduce分布式计算框架下,充分利用了计算机数据库领域中与度量空间相似连接处理相关的技术,在Map阶段中保证结果正确的前提下,对数据集进行了尽可能均匀的划分,并在Reduce阶段设计了有效的剪枝策略,进行相似度计算;大大降低了CPU时间、网络通信开销和I/O开销,提供了高效的相似连接处理性能,以实现快速地对海量数据进行重复检测和删除。
附图说明
图1是本发明的实施步骤流程图;
图2为基于KD树的空间划分示意图;
图3为基于KD树的数据划分示意图;
图4为Reduce阶段相似连接处理示意图。
具体实施方式
现结合附图和具体实施对本发明的技术方案作进一步说明:
如图1所示,本发明具体实施过程和工作原理如下:
步骤(1):对应用中给定的度量空间数据集进行随机采样,得到样本数据。
步骤(2):对得到的样本数据进行支枢点选择;选出的支枢点要求保证数据在向量空间中相互之间的距离与其在原度量空间中的距离尽可能的接近,其选择的具体步骤包括:
1)在样本数据中找出离群点作为支枢点的备选集合;
2)根据枢纽点的选择目标,对备选集合中的点进行增量式的贪心选择。
步骤(3):将应用给定的整个数据集(包括样本数据)从度量空间映射至向量空间;向量空间映射的方式是对于每一个在度量空间中的数据,计算与步骤(2)中得到的支枢点之间的距离,并以求得的距离作为向量空间中各维度的坐标值,得到度量空间数据在向量空间中的坐标。
步骤(4):利用步骤(3)中得到的样本数据构建KD树,得到相应的空间划分;具体如下:对步骤(3)中得到的样本数据建立KD树,得到的KD树中包含数据点个数相等的叶子节点,各叶子节点对应的空间区域即为空间划分的结果;下面以图2为例对KD树的构建进行说明,其中样本数据为{q2,o3,q4,o4,o5,q5,o7,q8}:
1)在一个随机选择的维度上,图2(a)中选到维度y,将所有的采样数据进行排序,进而将样本数据等分为A、B两个节点,即A={q2,o3,q4,o4}和B={o5,q5,o7,q8};
2)分别对A、B两个节点进行迭代划分,最终得到图2(b)所示的四个节点,即P1={q2,o4},P2={o3,q4},P3={o5,q5}和P4={o7,q8};
3)最终得到各叶子节点对应的空间划分,即为图2(b)中节点P1、P2、P3和P4对应的包围盒BB(P1)、BB(P2)、BB(P3)和BB(P4)。
步骤(5):在Map阶段,根据步骤(4)中得到的空间划分,对步骤(3)中得到的整个数据集进行划分;具体如下:所述的步骤(5)在Map阶段,将步骤(3)中得到的映射至向量空间后的整个数据集,划分至相应的步骤(4)中得到的空间划分中去,以图3为例,假定应用给定的数据集为Q={q1,q2,…,q8}、O={o1,o2,…,o8},具体划分步骤如下:
1)如图3(a)所示,将数据集Q划分至对应的划分中,得到四个数据集Q的划分P1Q={q1,q2},P2Q={q3,q4},P3Q={q5}以及P4Q={q6,q7,q8};
2)如图3(a)所示,在得到的划分PiQ后,计算能将PiQ中所有数据对象包围住的最小包围盒MBB(P1Q)、MBB(P2Q)、MBB(P3Q)以及MBB(P4Q);
3)计算各划分PiQ的搜索范围,划分PiQ的搜索范围为其对应包围盒范围外扩距离阈值大小对应的区域,如图3(b)所示,虚线所示区域即为MBB(P2Q)的搜索范围SR(P2Q);
4)根据得到的各个划分的搜索范围,将数据集O划分至对应划分的搜索范围中,如图3(b)所示,数据集O划分的结果为P1O={o2},P2O={o2,o3,o5,o6},P3O={o3,o5}和P4O={o3,o6,o7}。
步骤(6):在Reduce阶段对划分后的数据进行相似度计算,得到相似连接的处理结果;具体步骤包括:
1)在Reduce阶段,对于每个划分,各划分内部的数据在随机选定的一个维度上,使用快速排序算法进行排序整理,如图4所示,对划分P2进行处理时,选定了维度x对数据进行排序;
2)利用平面扫描法,对排序后的数据集进行度量空间距离计算以验证结果,并结合区域过滤技术对距离计算进行剪枝;如图4(a)所示,有一扫描平面从左扫描到右,现在扫描至数据对象q2,需为现在处于扫描平面的q2验证处于扫描平面右方距离阈值以内的数据对象o5,o2和o3;另外,根据区域过滤技术,如图4(b)所示,o5和o3因为处于q2的搜索范围SR(q2)之外可以被剪去,最终只需要为q2验证其与o2的距离。
- 还没有人留言评论。精彩留言会获得点赞!