基于移动互联网海量数据的服务层系统及其方法与流程
本发明属于大数据领域,尤其涉及一种基于移动互联网海量数据的服务层系统及其方法。
背景技术:
近年来,随着移动互联网上网速度的不断提升和资费价格的不断下降,移动互联网数据成爆炸性的生长,如何存储这些数据,如何在这些数据中快速提取到用户所需要的信息已成为一个热门课题。移动互联网拥有的数据源丰富多样,包括各种手机客户端产生的业务数据、网页、音频数据、视频文件和图片等结构化和非结构化的一些数据。针对不同种类数据的存储也出现了各类SQL以及NoSQL数据库。
在互联网行业,业务营销人员如果需要在海量数据中要查找到有用的信息,需要奔走于各个业务部门,查询各套系统,大大影响了工作效率。
技术实现要素:
本发明的目的在于克服现有技术中存在的缺点和不足,提供一种基于移动互联网海量数据的服务层系统及其方法,实现以下功能:①统一各种异构数据库(SQL/NoSQL)的访问方式;②数据表的自定义(用户自定义表视图)。
实现本发明目的的技术方案是:
一、基于移动互联网海量数据的服务系统(简称系统)
本系统包括依次连接的ETL、数据中心、服务层平台和业务系统。
二、基于移动互联网海量数据的服务方法(简称方法)
本方法包括下列步骤:
①业务系统注册
业务系统访问服务层平台300,需要先在服务层平台300中注册,生成系统的唯一号。
②业务系统查询。
本发明具有下列优点和积极效果:
①提供了通用的服务层访问平台,按照标准的http post和get方法调用接口方法,提供标准的json格式数据返回;
②处理速度快,且具有容错性;
③通过整合Hadoop分布式文件系统、Solr全文检索系统、ibatis等数据库接口和服务层平台融合等技术,为其它大数据技术之间的模块化整合以及统一操作接口提供了参考。
总之,本发明能够对所有移动互联网的海量数据进行统一查询接口,为各应用系统统一查询服务提供技术支持。
附图说明
图1是本系统的结构方框图;
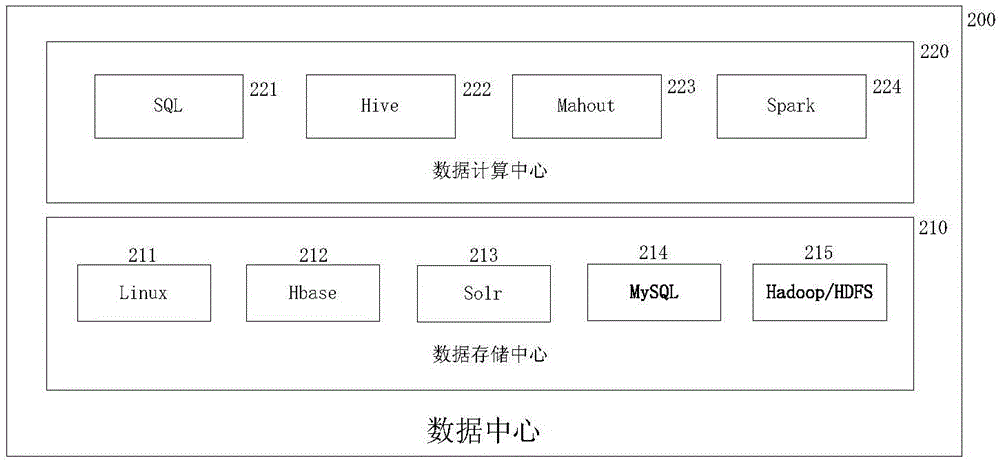
图2是数据中心的结构方框图;
图3是服务中心的结构方框图;
图4是系统注册流程图;
图5是系统查询请求流程图。
其中:
100—ETL;
200—数据中心,
210—数据存储中心,
201—Linux(本地文件系统),202—HBase(海量数据库),
203—Solr(全文数据库), 204—MySQL(业务数据库),
205—Hadoop;
220—数据计算中心,
211—SQL(查询模块),212—Hive(统计分析模块),
213—Mahout(数据挖掘模块),214—Spark(数据处理模块);
300—服务层平台,
310—底层数据访问服务模块,
320—业务接口模块,
321—通用业务接口,322—原始业务接口,323—基础业务接口;
330—控制模块,
331—日志,332—授权;
400—业务系统,
410—第1业务系统,
420—第2业务系统,……
4N0—第N业务系统,其中N≤100。
英译汉
1、Storm:是一个免费开源、分布式、高容错的实时计算系统。Storm令持续不断的流计算变得容易,弥补了Hadoop批处理所不能满足的实时要求;
2、Kafka:是一种高吞吐量的分布式发布订阅消息系统;
3、HDFS:Hadoop的分布式文件系统;
4、Flume:是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
5、Linux:一种操作系统;
6、Hadoop:一种能够对大量数据进行分布式处理的软件框架;
7、MySQL:MySQL是一个关系型数据库管理系统;
8、HBase:一种分布式的,面向列的Hadoop数据库;
9、Solr:一种基于Lucene的搜索服务器;
10、Hive:是基于Hadoop的一种数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行;
11、Spark:一种快速的大数据分布式处理引擎;
12、Mahout: ASF旗下的一种开源项目,提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序;
13、Zookeeper:是一种分布式的,开放源码的分布式应用程序协调服务,它是一个为分布式应用提供一致性服务的软件。
具体实施方式
以下结合附图和实施例详细说明:
一、系统
1、总体
如图1,本系统包括依次连接的ETL100、数据中心200、服务层平台300和业务系统400。
2、功能部件
1)ETL100
ETL100是指各类移动互联网数据源提取和清洗后转换技术的总称。
2)数据中心200
如图2,数据中心200是海量数据存储与处理的核心部件,包括数据存储中心210和数据计算中心220;
数据存储中心210包括Linux-211、HBase-212、Solr-213、MySQL-214和Hadoop-215;
数据计算中心220包括SQL-221、Hive-222、Mahout-223和Spark-224。
3)服务层平台300
服务层平台300是数据中心200对外提供服务的窗口,包括底层数据访问服务模块310、业务接口模块320和控制模块330;
底层数据访问服务模块310根据数据中心200通用API获取各类数据;
业务接口模块320包括通用业务接口321、原始业务接口322和基础业务接口323;通用业务接口321和原始业务接口322分别与基础业务接口323交互。
提供原始业务接口322、基础业务接口323以及通用业务接口321供上层应用系统400调用访问。
控制模块330用于接入控制,只有经过授权332的业务系统才能提供访问接口的服务,并对操作的动作记录日志331;否则不能提供服务。
4)业务系统400
如图1,业务系统400包括第1业务系统410、第2业务系统420、……第N业务系统4N0,N是自然数,N≤100。
2、工作机理
本系统接收到移动互联网的原始数据文件之后,ETL100按照指定的标准对数据进行提取、清洗、存入到数据中心200中;数据中心200提供各种数据算法模型和数据挖掘模型,对数据进行深度挖掘以及统计分析;服务层平台300为上层业务系统400提供基础服务,上层应用系统400按需通过HTTP GET/POST调用服务层平台300的通用业务接口321、原始业务接口322、基础业务接口323获取数据中心200各类数据。
二、方法
*步骤①:业务系统注册
如图4,业务系统注册流程如下:
A、接收业务系统注册请求-10;
B、判断业务系统传入的应用名是否存在-11,是则请求失败-13后
跳转到步骤D,否则进入步骤C;
C、分配系统唯一号给业务系统-12
D、结束-14。
*步骤②:业务系统查询
如图5,业务系统查询的工作流程如下:
a、收到业务系统请求-20;
b、判断业务系统是否注册-21,是则进入步骤c,否则即请求失败-29后跳转到步骤j;
c、判断业务系统参数是否合法-22,是则进入步骤d,否则即请求失败-29后后跳转到步骤j;
d、判断AppKey、 会话、方法版本号和请求方式是否合法-23,是则进入步骤e,否则即请求失败-29后跳转到步骤j;
e、判断业务参数校验流程是否合法-24,是则进入步骤f,否则即请求失败-29后跳转到步骤j;
f、判断校验业务是否受限访问、会话是否超过频次、上传文件大小是否超过限制-25,是则进入步骤g,否则即请求失败-29后跳转到步骤j;
g、请求业务层接口-26;
h、请求DAO层接口-27;
i、请求成功-28;
j、结束-30。
- 还没有人留言评论。精彩留言会获得点赞!