一种异常信息检测方法及系统与流程
本申请涉及电子技术领域,尤其涉及一种异常信息检测方法及系统。
背景技术:
当前,网络约车已经逐渐普及,用户可以通过客户端生成订单,系统将根据客户端发送来的订单来为客户端分配对应的司机端,这里的司机端为提供乘车服务的司机对应终端设备。司机端根据系统发送来的可以确定客户端所在位置,从而行驶到客户端所处位置为客户端提供乘车服务。
当前,某些司机端为了套取更多的非法利益,采用一车多端的作弊方式,即一辆车上放置多个手机,并安装多个司机端,在拉一个真(或假)单子的同时,顺带拉一到多个假单以获取更多非法利益。这种行为严重损害了平台的利益,并扰乱了正常的用车秩序,影响平台的安全性。
技术实现要素:
本发明实施例提供了一种异常信息检测方法及系统,用以解决现有技术中司机使用多司机端造假单,导致平台安全性降低的问题。
其具体的技术方案如下:
一种异常信息检测方法,所述方法包括:
获取指定位置区域内的所有第一记录信息,并提取每个所述第一记录信息的轨迹信息,其中,所述指定位置区域为选择出的位置坐标范围;
在所述轨迹信息中提取位置特征值;
根据所述位置特征值,在所述所有第一记录信息中筛选满足预设相似度的第二记录信息;
将所述第二记录信息作为异常信息。
可选的,获取指定区域内的所有第一记录信息,并提取每个第一记录信息中的轨迹信息,包括:
调取筛选时间段,其中,所述筛选时间段为筛选第三记录信息的指定时间段;
在第三记录信息中筛选所述筛选时间段内的第四记录信息;
在所述第四记录信息中获取指定区域内的所有第一记录信息,并提取每个第一记录信息中的轨迹信息。
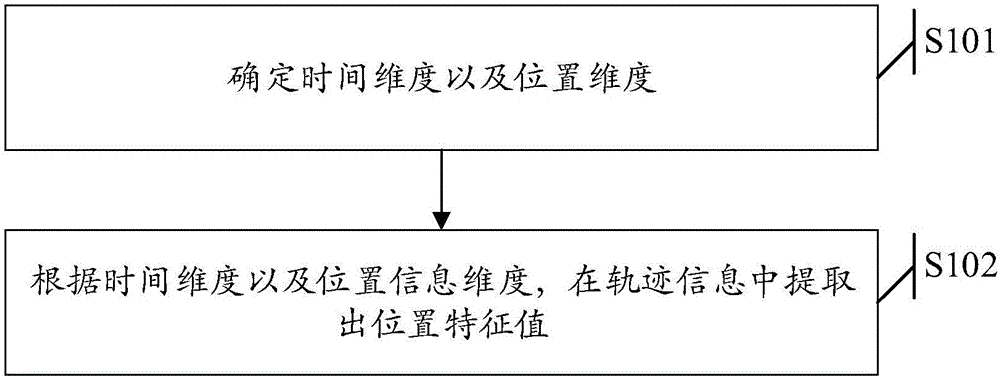
可选的,在所述轨迹信息中提取位置特征值,包括:
确定时间维度以及位置信息维度,其中,所述时间维度表征每个定位点的定位时刻,所述位置信息维度表征位置信息的精度;
根据所述时间维度以及所述位置信息维度,在所述轨迹信息中提取位置特征值。
可选的,根据提取的位置特征值,在所述所有第一记录信息中筛选满足预设相似度的第二记录信息,包括:
根据提取的位置特征值,按照第一粒度值对所述位置特征值进行筛选,得到符合第一粒度值的第一记录轨迹集合,其中,第一粒度值表征进行第一次筛选时的筛选数值取值范围;
按照第二粒度值对所述第一记录轨迹集合进行筛选,得到满足预设相似度的第二记录信息,其中,第二粒度值表征进行第二次筛选时的筛选数值取值范围,所述第二粒度值小于所述第一粒度值。
可选的,进一步包括:
监测异常司机端被检测为异常的总次数,其中,所述异常信息对应的司机端为异常司机端;
判定所述总次数是否超过预设阈值;
若是,则调取预设告警规则,并执行所述预设告警规则;
若否,则继续监测所述异常司机端。
一种异常信息检测系统,所述系统包括:
获取模块,用于获取指定位置区域内的所有第一记录信息,并提取每个所述第一记录信息中的轨迹信息;
提取模块,用于在所述轨迹信息中提取位置特征值;
筛选模块,用于根据提取的位置特征值,在所述所有第一记录信息中筛选满足预设相似度的第二记录信息,所述第二记录信息为异常信息。
可选的,所述获取模块,具体用于:
调取筛选时间段,在第三记录信息中筛选所述筛选时间段内的第四记录信息;
在所述第四记录信息中获取指定位置区域内的所有第一记录信息,并提取每个第一记录信息的轨迹信息;
其中,所述筛选时间段为筛选第三记录信息的指定时间段。
可选的,所述提取模块,具体用于:
确定时间维度以及位置信息维度;
根据所述时间维度以及所述位置信息维度,在所述轨迹信息中提取位置特征值;
其中,所述时间维度表征每个定位点的时间,所述位置信息维度表征位置信息的精度。
可选的,所述筛选模块,具体用于:
根据提取的位置特征值,按照第一粒度值对所述位置特征值进行筛选,得到符合第一粒度值的第一记录轨迹集合;
按照第二粒度值对所述第一记录轨迹集合进行筛选,得到满足预设相似度的第二记录信息,所述第二粒度值小于所述第一粒度值;
其中,所述第一粒度值表征进行第一次筛选时的筛选数值取值范围,所述第二粒度值表征进行第二次筛选时的筛选数值取值范围。
可选的,进一步包括处理模块,所述处理模块用于:
监测异常司机端被检测为异常的总次数,其中所述异常司机端是所述异常信息对应的司机端;
判定所述总次数是否超过预设阈值;
若是,则调取预设告警规则,并执行所述预设告警规则;
若否,则继续监测所述作弊司机端。
在本发明技术方案中,系统可以在指定区域内筛选出筛选时间段内的订单信息,通过第一粒度值筛选以及第二粒度值筛选,确定出相似度较高的订单轨迹,最后根据相似度较高的订单轨迹确定出作弊司机端。并且根据作弊司机端的作弊次数来对司机端进行对应惩罚,这样就可以较低司机端一带多的造假单的出现,进而提升了系统的成单效率,节约了系统成本,提升了系统安全性。
附图说明
图1为本发明实施例中一种异常信息检测方法流程图;
图2为本发明实施例中位置特征值提取方法流程图;
图3为本发明实施例中一种异常信息检测系统结构示意图。
具体实施方式
下面通过附图以及具体实施例对本发明技术方案做详细的说明,应当理解,本发明实施例以及实施例中的具体技术特征只是对本发明技术方案的说明,而不是限定,在不冲突的情况下,本发明实施例以及实施例中的具体技术特征可以相互组合。
如图1所示为本发明实施例中一种异常信息检测方法,该方法包括:
S101,获取指定位置区域内的所有第一记录信息,并提取每个所述第一记录信息的轨迹信息;
S102,在订单轨迹中提取出位置特征值;
S103,根据位置特征值,在所有第一记录信息中筛选满足预设相似度的第二记录信息;
S104,将第二记录信息作为异常信息。
具体来讲,在本发明实施例中,为了解决司机端一带多的作弊行为,所以需要在所有第一记录信息中筛选出相似的记录信息。
首先,系统需要获取到第一记录信息,在本发明实施例中,为了保证第一记录信息筛选的准确性,系统首先调取出一个筛选时间段,该筛选时间段为筛选第三记录信息的指定时间段。
基于该筛选时间段,在接收到的记录信息中筛选出该筛选时间段内的第三记录信息,比如说,该筛选时间段可以是周一至周五,那么系统就将获取到周一至周五的所有记录信息,这样就筛选出了筛选时间段内的所有记录信息。
当然,由于一带多的司机端都是位于一个区域中,所以基于筛选时间段筛选出的所有第三记录信息之后,在筛选出的第三记录信息中获取指定区域内的所有第二记录信息,并提取出每个第二记录信息中的轨迹信息。这里的指定位置区域为选择出的位置坐标范围,比如说,针对北京的司机端进行作弊检测,则在筛选时,就筛选出周一至周五北京的所有记录信息。
通过上述的方法就可以在系统中筛选出具有筛选时间段内指定区域的所有第一记录信息。
在筛选出需要的第二信息之后,系统将提取出每个第二记录信息中的轨迹信息,并在轨迹信息中提取出位置特征值,提取位置特征值的方法如图2所示,该方法包括:
S201,确定时间维度以及位置维度;
系统首先会对第二记录信息中的轨迹信息进行特征值的提取,轨迹信息的特征值有两个维度,一个为时间维度,一个为位置信息维度。
系统将首先确定特征值的时间维度,这里时间维度比如说,时间维度设置为1分钟,也就是每个轨迹点的时间保留到分钟的精确度。
另外,系统还将确定一个位置信息维度,这里的位置信息维度是将二维位置信息转换为一维位置信息。比如说,使用某一数据库中的s2库,这里的s2库可以是一个结构化查询语言数据库,将二维的地理信息转换为一维信息。当前使用的s2的level是15,大概范围是1000米内的区域,生成的id完全相同,这里的id为每个划分出的区域范围的标识。
S202,根据时间维度以及位置信息维度,在轨迹信息中提取出位置特征值。
具体来讲,在本发明实施例中确定出的时间维度以及位置信息维度之后,就可以在筛选出的轨迹信息中提取出对应的位置特征值,该特征值就包含了时间维度以及位置信息维度。
在本发明实施例中,位置特征值表征了记录信息中该行车轨迹的特征参数,该特征参数可以是一定间隔规则的位置坐标,比如说按照时间检测采集到的位置坐标点。
在提取出位置特征值之后,系统将对特征值进行两次筛选,首先根据提取出的特征值,按照第一粒度值对位置特征值进行筛选,得到符合第一粒度值的第一记录轨迹集合。第一次筛选过程为初步筛选过程,这样可以滤除掉部分轨迹信息。
在筛选出第一记录轨迹集合之后,按照第二粒度值对第一记录轨迹集合进行筛选,得到满足预设相似度的第二记录信息,这里的第一粒度值表征了进行第一筛选时的筛选数值取值范围,第二粒度值表征了进行第二次筛选时的筛选数值取值范围。
比如说,第一次利用粗粒度的特征值进行筛选,以特征值作为key,关联所属的订单。第二次精确粒度值筛选,对上一步筛选出的需要两两比较的订单,依次进行精确判断,因为线上踩点数据的采集间隔是5秒,所以判断两点相似,对时间点进行5秒的分组,相同组的点的s2的id如果相同,认为这两个点相同。
最后,基于筛选结果就可以确定出对应的司机端是否存在作弊行为,也就是说,是否存在一带多的情况。如果是存在一带多的情况,那么多个订单轨迹的相似度就较高,从而可以直接判断出该司机端作弊。
进一步,在本发明实施例中,当确定出一个司机端作弊之后,该系统还将实时监测该作弊司机端被检测出作弊的总次数,并判定总次数是否超过预设阈值,若是,则调取出预设告警规则,并执行该预设告警规则,若否,则继续监测该作弊司机端。也就是说,作弊司机端的作弊次数超过预设阈值之后,系统将调取出对应的惩罚机制,并按该惩罚机制执行。
当然,这里本发明实施例中,该预设阈值以及预设告警规则都可以基于系统运行要求来调。这样可以保证系统的安全性以及判定作弊的准确性。
综上来讲,在本发明实施例中,系统可以在指定区域内筛选出筛选时间段内的订单信息,通过第一粒度值筛选以及第二粒度值筛选,确定出相似度较高的轨迹信息,最后根据相似度较高的轨迹信息确定出作弊司机端。并且根据作弊司机端的作弊次数来对司机端进行对应惩罚,这样就可以较低司机端一带多的造假单的出现,进而提升了系统的成单效率,节约了系统成本,提升了系统安全性。
对应本发明实施例中一种异常信息检测方法,本发明实施例中还提供了一种异常信息检测系统,如图3所示为本发明实施例中一种异常信息检测系统,该系统包括:
获取模块301,用于获取指定位置区域内的所有第一记录信息,并提取每个所述第一记录信息中的轨迹信息;
提取模块302,用于在所述轨迹信息中提取位置特征值;
筛选模块303,用于根据提取的位置特征值,在所述所有第一记录信息中筛选满足预设相似度的第二记录信息,所述第二记录信息为异常信息。
进一步,在本发明实施例中,所述获取模块301,具体用于:
调取筛选时间段,在第三记录信息中筛选所述筛选时间段内的第四记录信息;
在所述第四记录信息中获取指定位置区域内的所有第一记录信息,并提取每个第一记录信息的轨迹信息;
其中,所述筛选时间段为筛选第三记录信息的指定时间段。
进一步,在本发明实施例中,所述提取模块302,具体用于:
确定时间维度以及位置信息维度;
根据所述时间维度以及所述位置信息维度,在所述轨迹信息中提取位置特征值;
其中,所述时间维度表征每个定位点的时间,所述位置信息维度表征位置信息的精度。
进一步,在本发明实施例中,所述筛选模块303,具体用于:
根据提取的位置特征值,按照第一粒度值对所述位置特征值进行筛选,得到符合第一粒度值的第一记录轨迹集合;
按照第二粒度值对所述第一记录轨迹集合进行筛选,得到满足预设相似度的第二记录信息,所述第二粒度值小于所述第一粒度值;
其中,所述第一粒度值表征进行第一次筛选时的筛选数值取值范围,所述第二粒度值表征进行第二次筛选时的筛选数值取值范围。
进一步,在本发明实施例中,进一步包括处理模块,所述处理模块用于:
监测异常司机端被检测为异常的总次数,其中所述异常司机端是所述异常信息对应的司机端;
判定所述总次数是否超过预设阈值;
若是,则调取预设告警规则,并执行所述预设告警规则;
若否,则继续监测所述作弊司机端。
尽管已描述了本申请的优选实施例,但本领域内的普通技术人员一旦得知了基本创造性概念,则可对这些实施例作出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本申请范围的所有变更和修改。
显然,本领域的技术人员可以对本申请进行各种改动和变型而不脱离本申请的精神和范围。这样,倘若本申请的这些修改和变型属于本申请权利要求及其等同技术的范围之内,则本申请也意图包含这些改动和变型在内。
- 还没有人留言评论。精彩留言会获得点赞!