一种基于数据挖掘的车辆停留行为模式预测与评估方法与流程
本发明涉及数据挖掘的方法、车辆的停留行为模式以及相关的预测与评估方法,特别是涉及一种基于数据挖掘的车辆停留行为模式预测与评估方法。
背景技术:
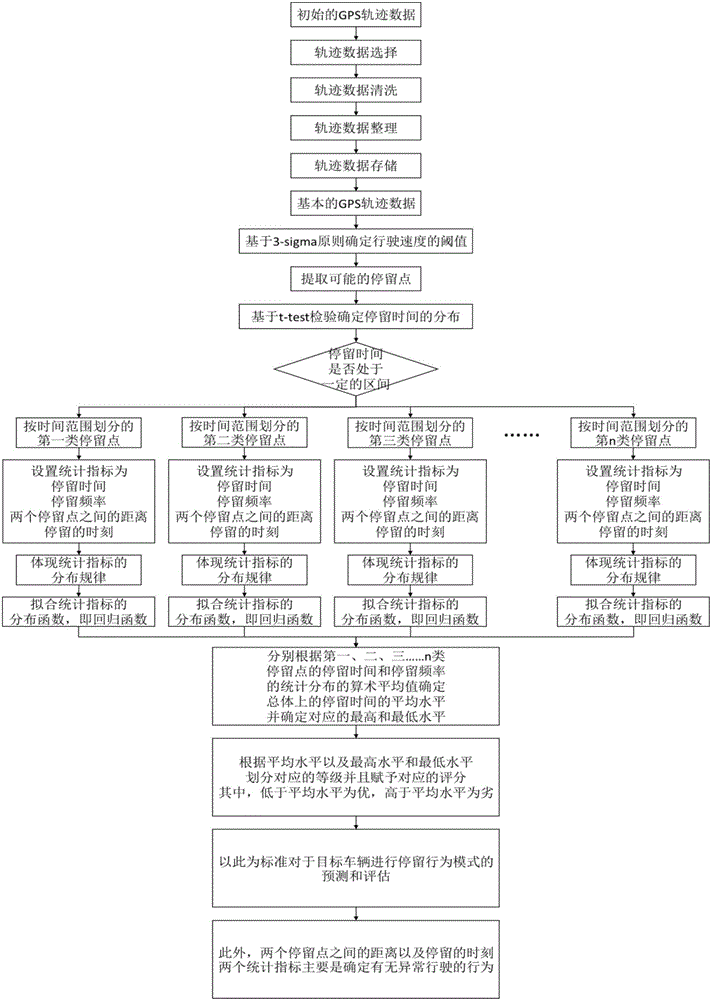
:数据挖掘的方法是一个从大量数据中提取出人们所感兴趣的知识的复杂的方式,人们所感兴趣的知识是有实际意义的并且以可以被理解的模式蕴含在数据之中。20年左右的发展,数据挖掘的相关研究已经越来越成熟,并且应用到其他领域。移动对象的数据挖掘主要是通过数据的处理与分析,数学,以及统计学等一系列数据挖掘的方法从移动对象的历史活动数据——轨迹数据中挖掘,并进一步发现有意义的和有价值的信息。轨迹数据是移动对象的历史活动数据,在一定水平上可以体现移动对象的性质、状态、行为等等内部特征和外部特征,此外,还可以体现内部环境和外部环境的变化对于移动对象的活动的影响。行为模式是从大量的行为活动中提取出来的,是行为的基本的理论、模型和规律。具体到车辆的停留行为模式,指的是车辆,特别是货运车辆,在一次行驶过程中,因为某一种因素的影响,所导致停留行为的时刻、间隔、频率、距离等一系列的指标所体现出来的特征。相关的预测与评估方法,主要有常规的预测与评估,灰色系统理论以及模型等,一般情况下,是通过对于现有的数据的整理及进一步处理,统计及进一步分析,建立一个回归函数进行预测,并且建立一个指标体系进行评估,在这一过程中,这个回归函数的类型还要求根据所使用的数据进一步确定,这个指标体系可以是单值函数或者集值函数。另外,对于规律性不大的系统也可以用灰色系统方法。技术实现要素:本发明的目的是为了解决上述问题,提出一种基于数据挖掘的车辆停留行为模式预测与评估方法。本发明是一种基于数据挖掘的车辆停留行为模式预测与评估方法,如图1所示,包括以下几个步骤:步骤一,导入初始的GPS轨迹数据,进行数据预处理;步骤二,从SQL数据库之中提取数据预处理之后的基本的GPS轨迹数据,并且进一步的进行停留点的提取;步骤三,对于每一种类型的停留点,分别对于以下四个统计指标;步骤四,对于每一种类型的停留点的四个统计指标的统计分布进一步的拟合,拟合过程主要是根据最小二乘法按照线性回归的方式提取统计分布的回归函数,可以利用一系列的常规函数拟合统计分布,并且比较拟合效果以确定回归函数,这里所采用的的函数是相关研究中通常会采用的函数。步骤五,根据每一种类型的停留点的停留时间和停留频率的统计分布平均值来确定总体上的停留时间的平均水平。本发明的优点在于:(1)本发明基于数据挖掘的车辆停留行为模式预测与评估方法,基本的主要流程是基于大量的GPS轨迹数据,采取数据挖掘技术相关的方法,对于以上轨迹数据进行选择、清洗、整理、存储等一系列的处理步骤,以保证接下来所使用的数据的真实性、实时性、准确性,进一步的利用相关的统计学理论来进行货运车辆的停留点的提取和停留点的分类,以保证接下来的统计分析过程的具体性和合理性,在此基础之上,对于行为模式理论相关的一系列统计指标进行统计分析,以提取分布规律和分布函数,与此同时,分析总体和个体的统计指标的分布之间的关系,为预测和评估提供数据和理论上的支持;(2)本发明基于数据挖掘的车辆停留行为模式预测与评估方法,其中预测与评估的主要方法选择了回归函数与指标体系二者相结合的方式,以保证总体的完整性,回归函数的确定主要是通过对于实际数据的统计指标的统计分析,体现其合理性,指标体系的确定主要是通过对于大量的统计分析的结果的处理,以总体反映个体,如此,可以保证预测与评估方法体系的正确性,以实现所要达到的效果。附图说明图1为本发明基于数据挖掘的车辆停留行为模式预测与评估方法流程图;具体实施方式下面将结合附图和实施例对本发明作进一步的详细说明。本发明是一种基于数据挖掘的车辆停留行为模式预测与评估方法,如图1所示,包括以下几个步骤:步骤一,导入初始的GPS轨迹数据,进行数据预处理;一般情况下,车辆的GPS轨迹数据包括以下字段,如时间、车辆ID、经度、纬度、速度、方向,根据数据所反映的车辆的类型、行驶路线、行驶时间、行驶区域的相关的信息,选择所需要的GPS轨迹数据,并且主要关注时间、车辆ID、经度、纬度以及速度,这里所需要导入的数据是若干车辆行驶一段时间的GPS轨迹数据,主要包括时间、车辆ID、经度、纬度、速度几个字段;初始的数据往往存在一定的问题,如字段的记录是否正确、规范、或者存在缺失,因此还需要对数据进行清洗和整理,根据相应的字段的性质,选择其中的记录正常的数据,并且保证数据的完整性,具体的方法是将GPS轨迹数据记录中,时间、车辆ID、经度、纬度、速度几个字段的记录存在不正确、不规范、或者存在缺失问题的条目筛选出来并且去除掉,将处理之后的数据根据车辆ID分类,并且对于每一个车辆ID分类下的数据按照时间的顺序重新排列,如果其中有时间不连续的情况,还需要进一步对时间字段进行补全,并且对于相应的条目中的经度、纬度、速度字段,结合车辆行驶的实际情况的合理性,进行理论的估计和补全,以保证时间、经度、纬度、速度的前后连贯性,并且将数据存储入SQL数据库中。步骤二,从SQL数据库之中提取数据预处理之后的基本的GPS轨迹数据,并且进一步的进行停留点的提取;为了进行停留点的提取,必须判断数据记录中的速度是否为零,因为轨迹数据可能存在一定的误差,所以依据记录判断不合理,因此,可以进行以下处理,将总体的轨迹数据中的速度字段提取出来为一条数据,定义为x1,x2,x3,……xM,其中,xn为某一车辆在某一时刻的速度数值,并且,xn≥0,M为所有具有速度数值的有效记录的个数,在此基础之上,根据3-sigma原则,判断总体的速度数据是否符合正态分布,若符合正态分布,则可以根据一个区间来判断速度是否为零,和分别为区间的下限和上限,表示均值,δ表示方差,在这一区间范围内的速度为零,不在这一区间范围内的速度不为零,其中,定义为其中,δ定义为若不符合正态分布,则需要对数据进行正态化处理,公式如下所示,其中,x表示不符合正态分布的数据,y表示经过正态化处理后符合正态分布的数据,γ为幂指数,对于x1,x2,x3,……xM一系列数值,可以将使以下公式达到其最大值的式中的参数γ的理论值作为参数γ的实际值,其中,l(γ)表示目标函数值,yi表示y中数据的单个值,表示y中数据的平均值,以上处理方法可以参考非正态数据的正态变换处理方法;上述处理过程之后,选择出来的速度为零的数据记录,可能存在的情况是,一系列连续的速度为零的数据记录实际上属于一个停留点,对于某一辆ID为XXX的车辆,获得其一部分连续的行驶轨迹数据记录,时间记录为t1、t2……、tn,经度和纬度记录分别为lon1、lon2……、lonn和lat1、lat2……、latn,并且数值变化比较小(两点之间实际距离误差范围为s米以内,s=1),速度记录均为0,具体形式如下所示,时间车辆ID经度纬度速度t1XXXlon1lat10…………………………tnXXXlonnlatn0对于这样一系列连续的速度为零的数据记录,可以将其整理为一条数据记录,将这一条数据记录的时间取为上述数据中第一条数据条目的时间,记为t,经度和纬度分别取为上述数据中所有经度和纬度的平均值,记为lonave和latave,速度取为0,持续时间取为上述数据中第一条数据条目和最后一条数据条目的时间之差,记为tlast,车辆的ID还是为XXX,具体形式如下所示,时间车辆ID经度纬度速度持续时间tXXXlonave1atave0tlast时间记为t=t1,经度记为lonave=(lon1+lon2+lon3+……+lonn)/n,纬度记为latave=(lat1+lat2+lat3+……+latn)/n,速度记为0,持续时间记为tlast=(tn–t1),到此为止,完成了停留点的提取,提取出来的停留点的形式为一条一条的数据条目,每一条数据条目包括时间、车辆ID、经度、纬度、速度、持续时间几个字段的内容,因为表示的是停留点,所以这里的速度字段的值均为0,则这一条条目的含义就是某一个ID的车辆,在某一时间(时间表示的),于某一位置(经度和纬度表示的),停留了多少时间(持续时间表示的),接下来,进一步的来进行停留点的分类,将提取出来的总体的停留点的数据,按照持续时间的长短,体现其统计分布结果,以持续时间的长短为横坐标,单位为分钟,区间为(0,480),间隔为10,并且以停留点的个数为纵坐标,单位为个数,表示出总体的停留点的数据的统计分布,按照统计分布中所反映的停留点的持续时间的分布情况,结合可能的行驶过程中导致停留行为的因素的种类,将停留点划分为n种类型,持续时间的区间分别设为(0,t1),(t1,t2),(t2,t3),……(tn-1,∞)。此处,统计分布主要是为了直观的表示,划分为n种类型主要还是根据实际的经验。步骤三,对于每一种类型的停留点,分别对于以下四个统计指标,表示出其统计分布规律,(1)停留时间,指的是某一次停留中停留行为的持续时间,(2)停留频率,指的是某一段时间内停留行为的重复次数,(3)两个停留点之间的距离,指的是某一车辆的两次停留位置之间的距离,可以依据停留点的经度和纬度的信息来计算,两个停留点的经纬度坐标分别为(lonend,latend),(lonstart,latstart),两者之间其实还有一系列的点的坐标,例如(lon1,lat1),(lon2,lat2),……可以逐个计算两点之间的距离,再一一加起来,也就是两个停留点之间的距离,计算公式如下所示,C=(sin(MlatA)*sin(MlatB)*cos(MlonA-MlonB)+cos(MlatA)*cos(MlatB))(6)Distance=R*arccos(C)*π/180(7)其中,(lonA,latA)和(lonB,latB)为两点的经纬度坐标,东经取经度的正值(longitude),西经取经度负值(-longitude),北纬取90-纬度值(90-latitude),南纬取90+纬度值(90+latitude),进行以上处理的两点的经纬度坐标分别为(MlonA,MlatA),(MlonB,MlatB),R为地球的平均半径,(4)停留时刻,指的是某一车辆的某一次停留行为发生的时间,对于根据某一车辆的停留点的数据和根据所有车辆的停留点的数据所获得的上述某一类型停留点(指的是之前划分的n种停留点的类型)的某一个统计指标(指的是之前提到的四个统计指标,也就是停留时间、停留频率、两个停留点之间的距离、停留时刻)的统计分布,还要确定是否为类似分布,这个可以根据t-test检验进行判断,检验主要用于检测两个分布是否为类似分布,其功能可以通过MATLAB或者其他的数学软件实现。步骤四,对于每一种类型的停留点的四个统计指标的统计分布进一步的拟合,拟合过程主要是根据最小二乘法按照线性回归的方式提取统计分布的回归函数,可以利用一系列的常规函数拟合统计分布,并且比较拟合效果以确定回归函数,这里所采用的的函数是相关研究中通常会采用的函数。可以考虑采用的常规函数有,(1)指数分布函数f(x)=a·eb·x(8)(2)高斯分布函数(3)幂律分布函数f(x)=a·xb(10)(4)对数正态分布函数其中,f(x)为目标函数,也就是上述的四个统计指标所对应的横坐标的量,x为变化的量,也就是数据的个数所对应的纵坐标的量,a,b,c分别为其参数,可以考虑采用R-Square公式来比较拟合效果,其中,R-Square为一个(0,1)的数值,通常用来描述数据对模型的拟合程度的好坏,yi,wi四个参数分别表示第i个数据点的实际值,拟合值,平均值,数据点的数据量占数据总量的权重,R-Square的值越趋于0表示效果越差,R-Square的值越趋于1表示效果越好。步骤五,根据每一种类型的停留点的停留时间和停留频率的统计分布平均值来确定总体上的停留时间的平均水平,对于类型M的停留点,对其所包含的停留点的数据统计如下,表1类型M的停留点所包含的停留点的数据序号123……m个数num(1)num(2)num(3)……num(m)停留时间t1t2t3……tm平均停留时间为其中tMmean表示平均停留时间,num(i)表示停留时间为ti的停留点个数,ti表示停留时间,nfrequentMmean表示类型M的停留点的停留频率的平均值,tMmean为类型M的停留点的停留时间的平均水平,并且可以根据数据t1,t2,t3,…tm中的最大值和最小值,来分别确定停留时间的最高水平和最低水平,分别设为tMmax,tMmin,此外,还可以将(tMmin,tMmean,tMmax)之间进一步的划分对应的等级并且赋予对应的评分,如下,表2类型M的停留点对应的等级和评分的划分tMmin~tM1tM1~tM2tM2~tM3tM3~tMmeantMmean~tM4tM4~tM5tM5~tM6tM6~tMmaxP1P2P3P4P5P6P7P8其中tM1、tM2、tM3、tM4、tM5、tM6表示时间常数,用于划分tMmin,tMmean,tMmax之间的等级,P1、P2、P3、P4、P5、P6、P7、P8表示对应等级的评分,具体来说,等级指的是根据类型M的停留点的停留时间所进行的分类,如tMmin~tM1、tM1~tM2、tM2~tM3、tM3~tMmean、tMmean~tM4、tM4~tM5、tM5~tM6、tM6~tMmax分别对应8个等级,评分指的是人为规定的对应于各个等级的分数,以用于进一步的评价,如P1、P2、P3、P4、P5、P6、P7、P8指的就是对应于8个等级的评分;所划分的等级和赋予的评分可以是均匀的,并且规则是时间增加,评分减少,考虑到之前划分了n种类型的停留点,对于每一种类型的停留点均进行上述的处理,如下所示,表3任意类型的停留点对应的等级和评分的划分其中,t11、t12、t13、t14、t15、t16和t21、t22、t23、t24、t25、t26和tn1、tn2、tn3、tn4、tn5、tn6表示时间常数,A1、A2、A3、A4、A5、A6、A7、A8和B1、B2、B3、B4、B5、B6、B7、B8和C1、C2、C3、C4、C5、C6、C7、C8表示对应等级的评分,这里与P1、P2、P3、P4、P5、P6、P7、P8没有直接的关系,也可以人为的设为1、2、3、4、5、6、7、8,并不影响进一步的评分,具体的如上所述,等级指的是根据相应类型的停留点的停留时间所进行的分类,评分指的是人为规定的对应于各个等级的分数,以用于进一步的评价。对于某一车辆在某一个时间区间之内正常行驶过程中的停留时间t,可以应用上述体系进行预测和评估,对其进行预测的方法具体是,根据目标车辆预期的行驶路线过程中可能出现的停留点的类型和频率,对照上述表3显示的结果,可以计算出对应于不同等级情况下的车辆可能的用于停留的时间,作为停留行为模式的预测,对其进行评估的方法具体是,根据目标车辆实际的行驶路线过程中确实出现的停留点的类型、时间、频率,计算出车辆在不同类型的停留点停留的时间,对照上述表3显示的结果,可以给出相应的等级和评分,作为停留行为模式的评估,并且可以以此为依据,进一步调整其行驶的方案,另外,两个停留点之间的距离以及停留的时刻这两个统计指标主要可以用来确定是否有异常驾驶的行为,也就是根据大量的历史数据发现这两个统计指标的正常情况下的数值,并且与某一车辆在某一个时间区间之内行驶过程中的对应的统计指标的数值相比较,若一致,则没有异常驾驶的行为,若不一致,则有异常驾驶的行为。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1