大数据精准营销模型的构建方法及装置与流程
本发明涉及大数据营销模型领域,特别涉及一种大数据精准营销模型的构建方法及装置。
背景技术:
传统的精准营销模型有很多,不同的模型和不同的数据处理手段都会导致模型的准确率不同,但是传统的精准营销模型中有一个通病,就是缺乏步骤之间的连接线,往往需要在中间步骤加入人工的操作,其操作较为复杂,另外,还需要每一个用户都要有数据分析的能力,当不具有数据分析能力的用户想要对传统的精准营销模型进行操作时,其面临的问题是不能进行操作。传统的精准影响模型只能针对特定的人群(即有数据分析能力的用户)才能进行操作,非分析人员不便于对传统的精准营销模型进行操作,其使用范围受限。
技术实现要素:
本发明要解决的技术问题在于,针对现有技术的上述缺陷,提供一种模型效果更加精准、中间不需要任何的人工操作、操作较为简便、非分析人员也能使用模型的大数据精准营销模型的构建方法及装置。
本发明解决其技术问题所采用的技术方案是:构造一种大数据精准营销模型的构建方法,包括如下步骤:
A)读取建模数据样本文件并输入建模数据样本;所述建模数据样本文件包含影响变量和目标变量;
B)按照设定的比例将所述建模数据样本划分为训练样本和测试样本;
C)采取众数的方法对所述训练样本和测试样本进行缺失值补全;
D)对所述训练样本中的连续型的影响变量做离散化处理;
E)计算离散化处理后的每个影响变量中各属性的信息熵,并对缺失值补全后的数据进行替换,并存储替换规则;
F)采用二元逻辑回归的方法固定所述建模数据样本文件的最后一列为目标变量,其他为自变量,利用所述训练样本训练所述大数据精准营销模型;
G)利用所述测试样本对所述大数据精准营销模型进行测试,并输出测试结果,利用AUC(Area Under roc Curve,曲线下面积)值来判断所述大数据精准营销模型的好坏;
H)读取目标数据样本文件并输入目标数据样本;所述目标数据样本文件包含影响变量;
I)利用统计的方法对所述目标数据样本进行缺失值补全;
J)对所述目标数据样本中连续型的影响变量按照所述建模数据样本的规则做离散化替换,替换成离散型数据;
K)按照所述替换规则对所述离散型数据做离散化替换;
L)计算所述目标数据样本中每一个目标数据的概率值;
M)输出概率列表。
在本发明所述的大数据精准营销模型的构建方法中,所述步骤A)进一步包括:
A1)读取建模数据样本文件,并判断是否找到所述建模数据样本文件,如是,执行步骤A2);否则,退出;
A2)校验写入的所述建模数据样本是否具有所述目标变量且所述目标变量为二元变量,如是,执行步骤B);否则,报错后返回步骤A1)。
在本发明所述的大数据精准营销模型的构建方法中,所述步骤H)进一步包括:
H1)读取所述目标数据样本文件,并判断是否找到所述建模数据样本文件,如是,执行步骤H2);否则,退出;
H2)校验所述目标数据样本文件中的字段与所述建模数据样本是否一致,如是,执行步骤I);否则,报错后返回步骤H1)。
在本发明所述的大数据精准营销模型的构建方法中,所述设定的比例为7:3。
在本发明所述的大数据精准营销模型的构建方法中,当所述AUC值小于0.6时,确定所述大数据精准营销模型的测试结果不好。
本发明还涉及一种实现上述大数据精准营销模型的构建方法的装置,包括:
建模数据样本输入单元:用于读取建模数据样本文件并输入建模数据样本;所述建模数据样本文件包含影响变量和目标变量;
样本划分单元:用于按照设定的比例将所述建模数据样本划分为训练样本和测试样本;
样本缺失值补全单元:用于采取众数的方法对所述训练样本和测试样本进行缺失值补全;
离散处理单元:用于对所述训练样本中的连续型的影响变量做离散化处理;
信息熵计算替换单元:用于计算离散化处理后的每个影响变量中各属性的信息熵,并对缺失值补全后的数据进行替换,并存储替换规则;
模型训练单元:用于采用二元逻辑回归的方法固定所述建模数据样本文件的最后一列为目标变量,其他为自变量,利用所述训练样本训练所述大数据精准营销模型;
测试单元:用于利用所述测试样本对所述大数据精准营销模型进行测试,并输出测试结果,利用AUC值来判断所述大数据精准营销模型的好坏;
目标数据样本输入单元:用于读取目标数据样本文件并输入目标数据样本;所述目标数据样本文件包含影响变量;
目标数据补全单元:用于利用统计的方法对所述目标数据样本进行缺失值补全;
离散化替换单元:对所述目标数据样本中连续型的影响变量按照所述建模数据样本的规则做离散化替换,替换成离散型数据;
信息熵替换单元:用于按照所述替换规则对所述离散型数据做离散化替换;
概率计算单元:用于计算所述目标数据样本中每一个目标数据的概率值;
结果输出单元:用于输出概率列表。
在本发明所述的装置中,所述建模数据样本输入单元进一步包括:
建模数据样本文件读取判断模块:用于读取建模数据样本文件,并判断是否找到所述建模数据样本文件,如是,进入建模数据样本校验模块;否则,退出;
建模数据样本校验模块:用于校验写入的所述建模数据样本是否具有所述目标变量且所述目标变量为二元变量,如是,进入所述样本划分单元;否则,报错后返回所述建模数据样本文件读取判断模块。
在本发明所述的装置中,所述目标数据样本输入单元进一步包括:
目标数据样本文件读取判断模块:用于读取所述目标数据样本文件,并判断是否找到所述建模数据样本文件,如是,进入样本判断模块;否则,退出;
样本判断模块:用于校验所述目标数据样本文件中的字段与所述建模数据样本是否一致,如是,进入目标数据补全单元;否则,报错后返回所述目标数据样本文件读取判断模块。
在本发明所述的装置中,所述设定的比例为7:3。
在本发明所述的装置中,当所述AUC值小于0.6时,确定所述大数据精准营销模型的测试结果不好。
实施本发明的大数据精准营销模型的构建方法及装置,具有以下有益效果:由于采用信息熵技术,对数据进行预处理,即采取众数的方法对训练样本和测试样本进行缺失值补全,利用统计的方法对缺失值进行补全,使得该大数据精准营销模型的效果更加精准,并且对该大数据精准营销模型的整个流程进行了封装,加入了程序自动化的思想,中间不需要任何的人工操作,既使是非分析人员也能使用模型;所以其模型效果更加精准、中间不需要任何的人工操作、操作较为简便、非分析人员也能使用模型。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明大数据精准营销模型的构建方法及装置一个实施例中方法的流程图;
图2为所述实施例中读取建模数据样本文件并输入建模数据样本的具体流程图;
图3为所述实施例中读取目标数据样本文件并输入目标数据样本的具体流程图;
图4为所述实施例中装置的结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
在本发明大数据精准营销模型的构建方法及装置实施例中,其大数据精准营销模型的构建方法的流程图如图1所示。图1中,该大数据精准营销模型的构建方法包括如下步骤:
步骤S01读取建模数据样本文件并输入建模数据样本:本步骤中,读取建模数据样本文件,并输入建模数据样本。上述建模数据样本文件为csv格式的文件,该建模数据样本文件包含影响变量和目标变量。
步骤S02按照设定的比例将建模数据样本划分为训练样本和测试样本:本步骤主要是进行数据划分,具体的,本步骤中,按照设定的比例将建模数据样本划分为训练样本和测试样本,该设定的比例为7:3,也就是按照7:3的比例把建模数据样本划分为训练样本和测试样本。当然,实际应用中,该设定比例可根据具体情况进行相应调整。
步骤S03采取众数的方法对训练样本和测试样本进行缺失值补全:本步骤主要是进行数据预处理,具体的,本步骤中,采取众数的方法对训练样本和测试样本进行缺失值补全。
步骤S04对训练样本中的连续型的影响变量做离散化处理:本步骤主要是进行离散化处理,具体的,本步骤中,对训练样本中的连续型的影响变量做离散化处理。
步骤S05计算离散化处理后的每个影响变量中各属性的信息熵,并对缺失值补全后的数据进行替换,并存储替换规则:本步骤主要是进行信息熵的计算,具体的,本步骤中,计算离散化处理后的每个影响变量中各属性的信息熵,并对缺失值补全后的数据进行替换,并且存储替换规则。这里的影响变量就是用户在前端界面输入的字段,如年龄、性别等。
步骤S06采用二元逻辑回归的方法固定建模数据样本文件的最后一列为目标变量,其他为自变量,利用训练样本训练大数据精准营销模型:本步骤主要是进行模型的训练,具体的,本步骤中,采用二元逻辑回归的方法固定建模数据样本文件的最后一列为目标变量(y),其他为自变量(X1-Xn),其中,n为自变量的个数,n为≥1的整数,利用训练样本训练大数据精准营销模型。当y为0时,表示坏样本;当y为1时,表示好样本。
步骤S07利用测试样本对大数据精准营销模型进行测试,并输出测试结果,利用AUC值来判断大数据精准营销模型的好坏:本步骤主要是进行模型的测试,具体的,本步骤中,利用测试样本对大数据精准营销模型进行测试,并输出测试结果,利用AUC值来判断大数据精准营销模型的好坏,AUC值是一种用来度量分类模型好坏的一个标准,本实施例中,当AUC值小于0.6时,说明测试效果不好,也即是确定该大数据精准营销模型的测试结果不好,建议重新输入一些新的影响变量。当然,上述的0.6也可以改成其他值,具体根据实际需求进行调整即可。
步骤S08读取目标数据样本文件并输入目标数据样本:本步骤中,读取目标数据样本文件并输入目标数据样本,该目标数据样本文件包含与建模数据样本一致的影响变量。
步骤S09利用统计的方法对目标数据样本进行缺失值补全:本步骤主要是进行数据预处理,具体是利用统计的方法对目标数据样本进行缺失值补全。
步骤S10对目标数据样本中连续型的影响变量按照建模数据样本的规则做离散化替换,替换成离散型数据:本步骤主要是进行离散化处理,具体的,本步骤中,对目标数据样本中连续型的影响变量按照建模数据样本的规则做离散化替换,替换成离散型数据。
步骤S11按照替换规则对离散型数据做离散化替换:本步骤主要是进行信息熵的替换,具体的,本步骤中,按照上述替换规则对离散型数据做离散化替换。
步骤S12计算目标数据样本中每一个目标数据的概率值:本步骤中,计算目标数据样本中每一个目标数据的概率值,也就是计算目标数据样本中每一个id的概率值,该id可以为用户。
步骤S13输出概率列表:本步骤中,输出概率列表。
对比传统的精准营销模型,本发明的方法采用信息熵技术对数据进行预处理,使得该大数据精准营销模型的效果更加精准,并且对该大数据精准营销模型的整个流程进行了封装,加入了程序自动化的思想,中间不需要任何的人工操作,操作较为简便,既使是非分析人员也能使用模型。
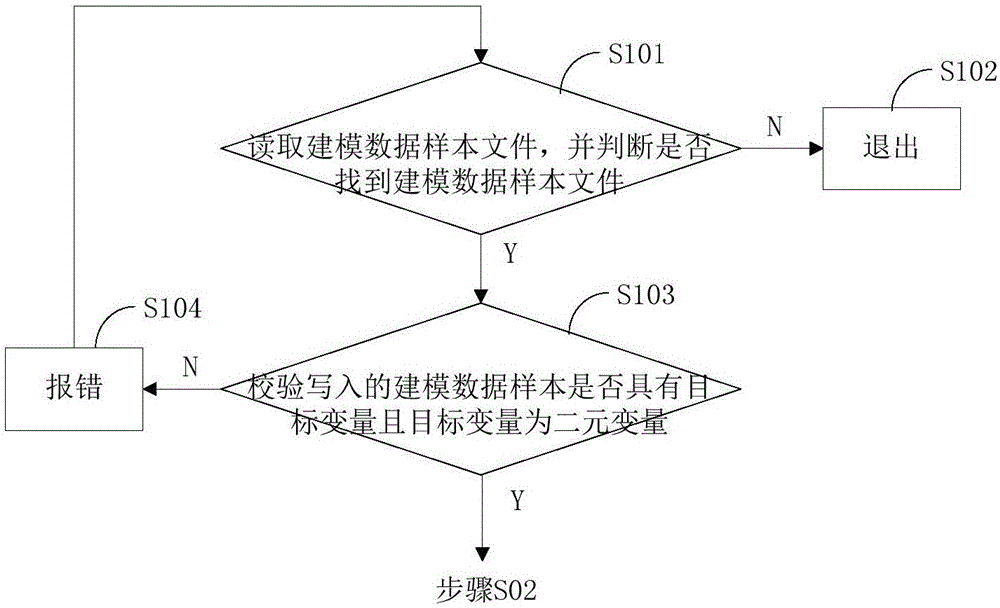
对于本实施例而言,上述步骤S01还可进一步细化,其细化后的流程图如图2所示。图2中,该步骤S01进一步包括:
步骤S101读取建模数据样本文件,并判断是否找到建模数据样本文件:本步骤中,读取建模数据样本文件,并判断是否找到建模数据样本文件,如果判断的结果为是,则执行步骤S103;否则,执行步骤S102。
步骤S102退出:如果上述步骤S101的判断结果为否,则执行本步骤。本步骤中,退出。
步骤S103校验写入的建模数据样本是否具有目标变量且目标变量为二元变量:本步骤主要是对写入的建模数据样本进行校验,具体的,本步骤中,校验写入的建模数据样本是否符合要求,即是否具有目标变量、目标变量是否为二元变量,如果判断的结果为是,即符合要求,则执行步骤S02;否则,执行步骤S104。
步骤S104报错:如果上述步骤S103的判断结果为否,即不符合要求,则执行本步骤。本步骤中,进行报错,执行完本步骤,返回步骤S101。这样就可以完成对写入的建模数据样本的校验。
对于本实施例而言,上述步骤S08还可进一步细化,其细化后的流程图如图3所示。图3中,上述步骤S08进一步包括:
步骤S801读取目标数据样本文件,并判断是否找到建模数据样本文件:本步骤中,读取目标数据样本文件,并判断是否找到建模数据样本文件,如果判断的结果为是,则执行步骤S803;否则,执行步骤S802。
步骤S802退出:如果上述步骤S801的判断结果为否,则执行本步骤。本步骤中,退出。
步骤S803校验目标数据样本文件中的字段与建模数据样本是否一致:如果上述步骤S801的判断结果为是,则执行本步骤。本步骤主要就是对写入的目标数据样本进行校验,具体的,本步骤中,校验目标数据样本文件中的字段与建模数据样本是否一致,如果一致,则执行步骤S09;否则,执行步骤S804。
步骤S804报错:如果上述步骤S803的校验结果为不一致,则执行本步骤。本步骤中,进行报错。执行完本步骤,返回步骤S801。这样就完成了对写入的目标数据样本的校验。
本实施例还涉及一种实现上述大数据精准营销模型的构建方法的装置,其结构示意图如图4所示。图4中,该装置包括建模数据样本输入单元1、样本划分单元2、样本缺失值补全单元3、离散处理单元4、信息熵计算替换单元5、模型训练单元6、测试单元7、目标数据样本输入单元8、目标数据补全单元9、离散化替换单元10、信息熵替换单元11、概率计算单元12和结果输出单元13。
本实施例中,建模数据样本输入单元1用于读取建模数据样本文件并输入建模数据样本;上述建模数据样本文件包含影响变量和目标变量;样本划分单元2用于按照设定的比例将建模数据样本划分为训练样本和测试样本;该设定的比例为7:3,也就是按照7:3的比例把建模数据样本划分为训练样本和测试样本。当然,实际应用中,该设定比例可根据具体情况进行相应调整。样本缺失值补全单元3用于采取众数的方法对训练样本和测试样本进行缺失值补全;离散处理单元4用于对训练样本中的连续型的影响变量做离散化处理;信息熵计算替换单元5用于计算离散化处理后的每个影响变量中各属性的信息熵,并对缺失值补全后的数据进行替换,并存储替换规则;模型训练单元6用于采用二元逻辑回归的方法固定建模数据样本文件的最后一列为目标变量,其他为自变量,利用训练样本训练大数据精准营销模型。
本实施例中,测试单元7用于利用测试样本对大数据精准营销模型进行测试,并输出测试结果,利用AUC值来判断大数据精准营销模型的好坏;本实施例中,当AUC值小于0.6时,说明测试效果不好,也即是确定该大数据精准营销模型的测试结果不好,建议重新输入一些新的影响变量。当然,上述的0.6也可以改成其他值,具体根据实际需求进行调整即可。
本实施例中,目标数据样本输入单元8用于读取目标数据样本文件并输入目标数据样本;上述目标数据样本文件包含影响变量;目标数据补全单元9用于利用统计的方法对目标数据样本进行缺失值补全;离散化替换单元10对目标数据样本中连续型的影响变量按照建模数据样本的规则做离散化替换,替换成离散型数据;信息熵替换单元11用于按照替换规则对离散型数据做离散化替换;概率计算单元12用于计算目标数据样本中每一个目标数据的概率值;结果输出单元13用于输出概率列表。
对比传统的精准营销模型,本发明的装置采用信息熵技术对数据进行预处理,使得该大数据精准营销模型的效果更加精准,并且对该大数据精准营销模型的整个流程进行了封装,加入了程序自动化的思想,中间不需要任何的人工操作,操作较为简便,既使是非分析人员也能使用模型。
本实施例中,建模数据样本输入单元1进一步包括建模数据样本文件读取判断模块11和建模数据样本校验模块12;其中,建模数据样本文件读取判断模块11用于读取建模数据样本文件,并判断是否找到建模数据样本文件,如是,进入建模数据样本校验模块12;否则,退出;建模数据样本校验模块12用于校验写入的建模数据样本是否具有目标变量且目标变量为二元变量,如是,进入样本划分单元;否则,报错后返回建模数据样本文件读取判断模块11。这样就可以完成对写入的建模数据样本的校验。
本实施例中,目标数据样本输入单元8进一步包括目标数据样本文件读取判断模块81和样本判断模块82;其中,目标数据样本文件读取判断模块81用于读取目标数据样本文件,并判断是否找到建模数据样本文件,如是,进入样本判断模块82;否则,退出;样本判断模块82用于校验目标数据样本文件中的字段与建模数据样本是否一致,如是,进入目标数据补全单元9;否则,报错后返回目标数据样本文件读取判断模块81。这样就完成了对写入的目标数据样本的校验。
总之,本发明通过采用信息熵技术对数据进行预处理,使得该大数据精准营销模型的效果更加精准,并且对该大数据精准营销模型的整个流程进行了封装,加入了程序自动化的思想,中间不需要任何的人工操作,操作较为简便,既使是非分析人员也能使用模型。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!