一种基于深度学习的珍珠分类方法与流程
本发明涉及图像处理和模式识别技术领域,具体涉及一种基于深度学习的珍珠分类方法。
背景技术:
中国是淡水珍珠的生产大国,其产量占世界产量的95%,其中浙江省诸暨市是我国淡水珍珠养殖、加工和销售的最大基地,总产量占全国总产量一半以上,被誉为“中国珍珠之乡”。诸暨淡水珠养殖面积已达38万亩,拥有珍珠加工企业1500多家。
大部分珍珠企业在采集大量珍珠后,为了将珍珠分成不同的档次,需要人工对珍珠进行分类,用人量非常大,而且对分类人员的专业素养有较高的要求。由于人工分类会受多种因素的影响,尤其在珍珠体积小、数量多的情况下,分类的结果不稳定,受个人的主观影响比较大。因此,利用机器对珍珠进行快速准确地分类成了很多珍珠企业的迫切需要。
中国发明申请号201210411979.2公开了一种基于单目多视角机器视觉的珍珠颜色光泽度在线自动分级装置,包括用于对珍珠进行自动检测和分类的流水线,用于拍摄被检珍珠图像的单目多视角机器视觉装置,用于对被检珍珠图像进行图像处理、检测、识别、分类以及协调控制流水线上各动作机构的协调动作的微处理器,流水线包括上料动作机构、送检动作机构、下料动作机构、分级动作机构和分级执行机构。该发明对被检测珍珠进行颜色和色泽的检测,但是没有对珍珠进行螺纹的检测,在实际人工分类的场合,珍珠的有无螺纹是人工分类的一个很重要的评判标准。
早期的图像分类任务的解决方法主要含有两个步骤,一个是手动设计特征,利用SVM等分类器对这些设计的特征进行分类,另一个是构建浅层学习系统。
支持向量机(Support Vector Machine,SVM)是Vapnik等人于1995年首先提出的一种机器学习算法。SVM是建立在统计学习理论的VC维理论和结构风险最小原理基础上的,能根据有限的样本信息在模型的复杂性(即对特定训练样本的学习精度)和学习能力(即无错误地识别任意样本的能力)之间寻求最佳折中,以求获得最好的分类识别能力。
由于不同的珍珠,其螺纹的数量、位置各不相同,并且在珍珠图像采集时,珍珠螺纹的清晰程度受到其颜色和色泽的影响,因此人工手动设计特征并不容易,且设计的特征并不一定适用于当前的分类任务。
技术实现要素:
为了克服已有基于机器视觉的珍珠分类系统难以对珍珠的螺纹进行高精度的检测和分类,手工设计特征提取珍珠的螺纹特征并不容易等问题,本发明提供一种基于深度学习的珍珠分类方法,通过深度卷积网络训练大量珍珠图像数据,学习珍珠的螺纹特征,并结合SVM对珍珠进行分类,具有较高的识别率,实用性良好、分类效果较好。
本发明实现上述发明目的所采用的技术方案为:
一种基于深度学习的珍珠分类方法包括以下步骤:
1)采集珍珠图像作为样本数据,每颗珍珠包含设定数量幅图像;
2)将所采集的珍珠图像调整成所设定的大小,并对其进行图像预处理,去除图像的噪声;
3)划分样本数据为训练数据和测试数据;
4)设置深度卷积网络的各个网络层的初始参数,将步骤3)所划分的训练数据输入所述深度卷积网络,对网络进行训练;
5)利用训练好的深度卷积网络提取训练数据和测试数据的特征;
6)利用步骤5)提取的训练数据的特征构建SVM分类器,并利用该SVM分类器对测试数据进行分类。
进一步,所述步骤1)获取的珍珠图像包含两类,分别为含有螺纹的珍珠图像和无螺纹的珍珠图像。
进一步,所述步骤2)中采用双边滤波去除图像的噪声。当然,也可以采用其他去噪方法。
再进一步,所述步骤4)包括以下步骤:
4.1)确定深度卷积网络的结构;
4.2)用不同的小随机数初始化网络中待训练的参数;
4.3)将步骤3)所划分的训练数据输入所述深度卷积网络,计算所述深度卷积网络的输出与实际类别标签之间的误差,通过误差反向传播算法调整所述深度卷积网络各层的权值和偏置项,直到网络稳定或到达所设定的最大迭代次数。
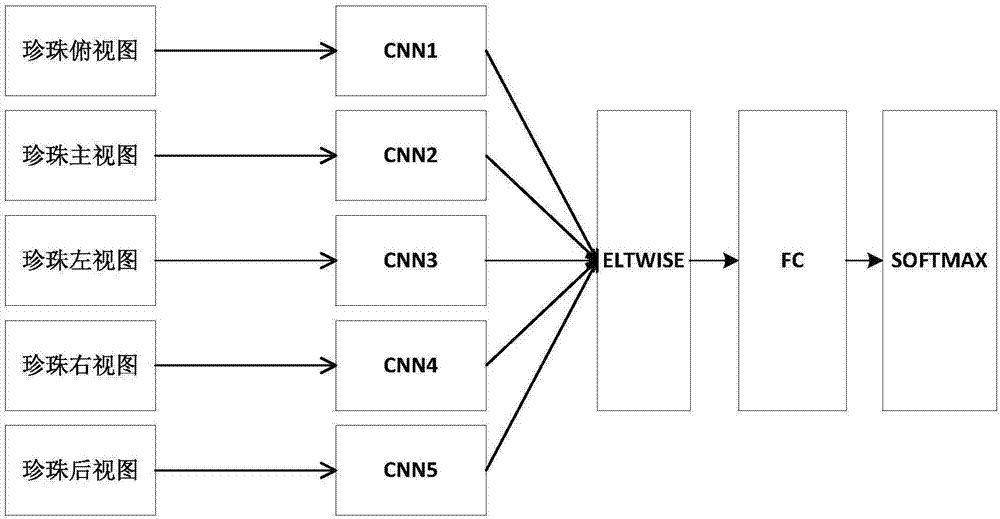
更进一步,所述步骤1)中,每颗珍珠包含5幅图像,分别为俯视图、左视图、右视图、后视图和主视图;所述步骤4)中构建的深度卷积网络是由5个卷积网络构成的,珍珠的5幅视图分别作为这5个卷积网络的输入以提取螺纹特征。
优选的,所述5个卷积网络采用相同的结构,分别包括2个卷积层,2个下采样层和1个全连接层。
所述5个卷积网络的输出特征需要由ELTWISE层对其进行累加,合并为1个特征向量,并将该特征向量输入FC全连接层,由FC全连接层将特征向量映射到二维后,输入到SOFTMAX层,SOFTMAX层由2个独立的神经元组成,对应有螺纹的珍珠和无螺纹的珍珠。
进一步,所述步骤5)中利用训练好的深度卷积网络提取特征是指将样本数据作为训练好的深度卷积网络的输入,将深度卷积网络的ELTWISE层的输出作为该样本珍珠的螺纹特征。
进一步,所述步骤6)包括以下步骤:
6.1)对步骤5)提取的训练数据的特征进行预处理;
预处理:对得到的特征数据进行归一化处理,将特征数据每一维度的数值映射到[0,1]区间;转换函数为其中xmax为特征数据的最大值,xmin为特征数据的最小值;
6.2)利用6.1)归一化后的训练数据构建SVM分类器;
6.3)将测试数据按照训练数据归一化时的映射关系进行归一化;
6.4)利用SVM分类器对归一化后的测试数据进行分类,判断珍珠是否有螺纹。
本发明的技术构思为:深度学习是近几年的热点,深度学习的概念源于人工神经网络的研究,含多隐藏层的多层感知器就是一个深度学习结构。深度学习通过组合低层特征形成更加抽象的高层表示(属性类别或特征),以发现数据的分布式特征表示。卷积网络是深度学习的一种结构,卷积网络在图像分类等问题上取得了很大的突破。卷积网络由一个或多个卷积层和顶端的全连接层组成,同时也包括关联权重和下采样层,这一结构使得卷积神经网络能够利用输入数据的二维结构,可以用图像直接作为网络的输入,避免了传统识别算法中复杂的特征提取和数据重建的过程。它的权值共享网络结构更接近生物神经网络,降低了模型的复杂度,减少了权重的数量。本发明的有益效果为:1)使用深度卷积网络提取珍珠的螺纹特征,充分发挥深度学习的自我学习优势,机器自动学习良好的特征,免去了繁琐的手动提取特征和设计特征的过程,避免人工手动设计特征的弊端,简化了流程,节约时间;2)针对珍珠的5幅视图构建了5个卷积网络,充分利用了整颗珍珠的图像信息,避免了单一视角下的图像没有整体代表性的弊端;3)由于深度卷积网络提取图像的局部特征,然后再将特征进行组合,使得提取的特征具有一定平移和旋转不变性,在一定程度上避免了在采集珍珠图像时,珍珠摆放位置随机性带来的影响;4)将深度卷积网络与支持向量机(Support Vector Machine,SVM)有机地结合起来,深度卷积网络用于提取特征,SVM用于分类识别,保证了分类的准确度。
附图说明
图1为整个分类方法的流程示意图。
图2为深度卷积网络整体结构的示意图。
图3为卷积网络具体网络结构的示意图。
具体实施方式
下面结合说明书附图对本发明的具体实施方式作进一步详细描述。
参照图1~图3,一种基于深度学习的珍珠分类方法,步骤如下:
1)采集珍珠图像作为样本数据,每颗珍珠包含5幅图像,分别为俯视图、左视图、右视图、后视图、主视图;
所采集的图像包含两类珍珠图像,分别为含有螺纹的珍珠图像和无螺纹的珍珠图像。
2)将所采集的珍珠图像调整成150×150像素,并对其进行图像预处理,去除图像的噪声;
利用双边滤波去除图像的噪声,由于采集的图像是彩色图,需要分别对R、G、B三个颜色通道进行双边滤波;珍珠图像记为I,当前像素点记为(x,y),则当前像素的R分量的亮度值记为Ir(x,y),当前像素的G分量的亮度值记为Ig(x,y),当前像素的B分量的亮度值记为Ib(x,y),当前像素点与相邻像素点(x-i,y-j)的亮度差记为的计算公式为:
像素点(x,y)滤波后的像素亮度值记为F(x,y),其计算公式为:
其中σr、σd是平滑参数,m和n分别是滤波窗口的长和宽;分别计算R、G、B三个颜色通道滤波后的F,得到滤波后的图像。
3)划分样本数据为训练数据和测试数据;
按照训练数据和测试数据的比例为8:2划分样本数据,训练数据用于训练深度卷积网络的参数,测试数据用于测试分类器的性能。
4)设置深度卷积网络的各个网络层的初始参数,将步骤3)所获得的训练数据输入所述深度卷积网络,对网络进行训练;
4.1)确定深度卷积网络的结构;
这里的深度卷积网络的结构示意图如图2所示,将经过预处理的珍珠俯视图、左视图、右视图、后视图、主视图分别作为5个卷积网络CNN1~5的输入;
ELTWISE层将5个卷积网络的输出进行叠加,得到珍珠图像的特征向量,将特征向量作为FC全连接层的输入;
FC层将特征向量映射到二维向量并作为SOFTMAX层的输入;
SOFTMAX层主要是对全连接层之后的数据进行归一化操作使其范围在[0,1]之间,由2个独立的神经元组成,对应有螺纹的珍珠和无螺纹的珍珠;
5个卷积网络CNN1~5采用相同的网络结构,如图3所示,包括:
CONV1卷积层,采用20个5×5的卷积核与所述图像样本数据的对应元素相乘、求和并加上偏置项后得到CONV1卷积层的特征图;
POOLING1下采样层,下采样层可以利用图像局部相关性的原理,对图像进行子采样,可以在减少数据处理量的同时保留有用的信息;POOLING1下采样层采用20个2×2采样核对CONV1卷积层的特征图进行子采样,得到POOLING1下采样层的特征图;下采样层的采样方法常用的包括平均值下采样,随机下采样和最大值下采样,所述下采样层采用了最大值下采样。所述的平均值下采样是指将采样窗口内的所有元素的平均值作为采样结果输出;随机下采样是指在采样窗口内随机的选择一个元素的值作为采样结果输出;最大值下采样是指将采样窗口中所有元素的最大值作为采样结果;
CONV2卷积层,采用50个5×5的卷积核与POOLING1下采样层的特征图做卷积操作后,求和并加上偏置项后得到CONV2卷积层的特征图;
POOLING2下采样层,采用50个2×2采样核对CONV2卷积层的特征图进行子采样,得到POOLING2下采样层的特征图;
FC全连接层,将POOLING2的特征图映射到500维的向量;
RELU激活层,采用激活函数max(x,0),当x>0时,输出x,否则,输出0,x指的是FC全连接层输出向量的数值;
4.2)用不同的小随机数初始化网络中待训练的参数;
4.3)将步骤3)所划分的训练数据输入所述深度卷积网络,计算所述深度卷积网络的输出与实际类别标签之间的误差,通过误差反向传播算法调整所述深度卷积网络各层的权值和偏置项,直到网络稳定或到达所设定的最大迭代次数;
构建好深度卷积网络并用不同的小随机数初始化网络中待训练参数后,将步骤3)划分的训练数据作为网络的输入,将网络得到的预测输出与训练数据的真实类别标签进行对比,将两者的误差进行反向传播,根据所述误差利用随即梯度下降法来更新所述深度卷积网络的参数,使得预测输出与真实类别标签之间的误差逐步减少;
对多个训练数据进行多次训练,每次训练均对深度卷积网络的参数进行更新,以不断缩小预测输出与所述训练数据的真实类别标签之间的误差,当所述误差小于预定值时或训练迭代次数超过预设定的最大迭代次数,就可确定当前学习到的模型参数为训练好的模型参数,从而获得训练好的深度卷积网络。
5)利用训练好的深度卷积网络提取训练数据和测试数据的特征;
将训练数据和测试数据作为训练好的深度卷积网络的输入,将深度卷积网络的ELTWISE层的输出作为该训练数据和测试数据的螺纹特征;
6)利用步骤5)提取的训练数据的螺纹特征构建SVM分类器,并利用该SVM分类器对测试数据进行分类;
6.1)对步骤5)提取的训练数据的特征进行预处理;
预处理:对得到的特征数据进行归一化处理,将特征数据每一维度的数值映射到[0,1]区间;转换函数为其中xmax为特征数据的最大值,xmin为特征数据的最小值;
6.2)利用6.1)归一化后的训练数据构建SVM分类器;
6.3)将测试数据按照训练数据归一化时的映射关系进行归一化;
6.4)利用SVM分类器对归一化后的测试数据进行分类,判断珍珠是否有螺纹。
- 还没有人留言评论。精彩留言会获得点赞!