图像稀疏表征多字典学习的联合优化训练方法与流程
本发明提供了一种图像数据压缩方法,属于多媒体通信和数据压缩交叉领域,特别设计一种针对低码率的图像数据压缩算法,对图像纹理进行聚类与结构化字典建模,将图像进行稀疏表征,主要用于降低通信时传输的数据量,既适用于特定主题的图像如人脸,又适用于一般的自然图像,应用广泛。
背景技术:
数字多媒体通信是当前通信技术众多领域中最具挑战性、发展最快的领域之一。大数据时代对数据的压缩和传输提出了更高的需求。为了有效减轻带宽压力,对数据进行有效传输,图像压缩被研究者们广泛的研究。
传统的图像压缩方法在低码率时不能对图像产生良好的压缩效果,在低码率时,恢复图像难以产生较好的视觉效果。如基于离散余弦变换(DCT)的JPEG图像压缩方法在重建时会产生较明显的块效应,图像块进行变换编码,随着码率的降低,在块的边界出现了不连续。基于离散小波变换(DWT)的JPEG2000压缩方法将高频的小波系数进行了阈值收缩,造成了高频信息的丢失,会对图像产生振铃现象,其典型表现是图像灰度剧烈变化的领域出现类似吉伯斯分布的震荡,严重影响复原图像的质量,并且使得后续图像处理难以进行。
近年来,字典学习方法取得了较好的压缩效果,即将数据(图像)用一组基的稀疏的线性组合的基来表示,所述字典,指的是“基”。与离散余弦变换和小波变换相同,字典学习也是根据基进行变换,在变换域中对图像进行表征,以求取得比像素域更优越的表达效果,即在变换域能用更少的比特来表征图像,实现图像压缩。在这里,字典这组基所对应的系数是稀疏的,大部分为零,只有少部分非零系数,利用这种优越的性质对图像进行稀疏编码(Sparse Coding,SC)。其不同之处在于,离散余弦基与小波基是根据数学函数得到的基,而字典学习的基,是从实际图像中用机器学习的算法学习得到的。这样做的好处在于,从实际样本中学出来的基更吻合图像,而根据数学函数得到的基难以完美的刻画图像的规律。字典学习的原理在于,对训练集的图像学习得到一组冗余基,所述冗余基,指字典的原子(即字典的一列)个数大于其维数,有理论保障,测试集中的样本可以用该冗余基的少数几个分量线性组合来唯一地表示,称这种表示为稀疏表征。稀疏表征旨在用最少的字典原子表示一个信号,以实现将图像用少数数据来表示,达到数据压缩的目的。经典的字典学习算法有K-SVD,每次学习更新一个原子和其对应的稀疏系数,直到所有的原子更新完毕,重复迭代几次即可求出过完备字典。该算法的不足在于,字典训练的时间较长。于是,有研究提出在线字典学习算法(Online Dictionary Learning),该方法通过随机梯度下降算法达到最优值,几次迭代即可求出字典,能更快地收敛。
对图像进行稀疏编码,字典一般分为单一字典和多字典两种形式。单一字典形式是对所有图像学习一个统一的字典,这种字典是紧致的,但缺乏不同特征的分辨能力,难以对所有的特征进行最优的表征。这种用统一的字典对图像进行压缩表征的代表算法有学者Karl Skretting提出的递归最小二乘字典学习算法(Recursive Least Squares Dictionary Learning Algorithm,RLS_DLA),该方法从像素域或者小波域对不同的图像学习出统一的字典,以稀疏的系数对图像进行低比特编码,算法迭代收敛较快。多字典形式是对图像中不同的特征分别建模,学习多个专门化的字典,这种字典有分辨能力。学者Michael Elad最先提出用多个专门化字典的对人的正脸图像进行表征,即对人脸的特征如眼、鼻、眉毛、嘴等分别建立专门化的K-SVD字典,每个图像块独立地表征,这种人脸特征字典非常紧致,实现低比特编码,效果优于传统的JPEG2000等编码标准。但是,该方法适应能力有限,不能对除人脸以外的其他图像的进行压缩。学者李少阳采用非参贝叶斯学习的方法,对自然图像数据学习出多个字典,字典的个数由算法根据先验信息自动的确定,这种方法能学习到一组最优的字典,对不同的图像进行表征。
另一方面,自然图像有很多内在的共性,相同的特征可能出现在不同图像中,甚至是大多数图像共有的。图像也有自身的特性,如某些图像块有鲜明的方向性,几何特征明确。基于以上考虑,需要建立一种新的压缩算法,对图像的共性特征建立统一的共享字典,而对图像的特性特征建立多个专门化的字典,实现两种形式的字典的优势互补,共享字典能对大多数特征实现紧致的表征,专门化的字典能更加有分辨力,对共享字典与专门化字典进行联合的优化,学习到一组最优的字典对图像进行稀疏表征。
技术实现要素:
一种通过学习图像中的各向同性图像的共性得到的共享字典和通过学习图像中的个性得到的专有字典进行联合优化训练方法,以便实现压缩图像在保证含有丰富信息量的同时,又能最大限度提高压缩比。
本发明的优点在于,通过建模图像不同特征的几何分量,即低频分量和多个不同梯度方向的高频分量,使得压缩后重建的图像保留更完整的细节,有更好的客观图像质量,以及更符合人的主观感受。
本发明的特征在于,是一种自然图像编码方法,学习最优的基对图像进行稀疏表征,是在计算机中依次按以下步骤实现的:
步骤(1),计算机初始化,设定下述各参数和系数:
将训练图像X切分后得到各图像小块i=1,2,…,i,…,I,I为xi的总数,xi∈Rm,m是矩阵R的行,简称xi,
图像小块xi中的像素用表示,简写成j,j=1,2,…,J,同时,j也是像素的序号,J是像素的总数,用u表示所述像素的水平分量,用v表示垂直分量。
用gj表示所述像素j的梯度,用Gi表示所述图像小块xi的梯度矩阵,Gi=[g1,g2,…,gJ]T,Gi∈RJ×2,列数n=2,用行表示像素梯度的数目J,列表示像素梯度的水平与垂直分量,分别用表示。
用ω表示像素j在梯度方向的方向角
用K0表示各向同性子图像块的集合为,简称K0,用D0表示学习K0得到的共享字典。
用K表示各向异性的图像块的集合,K={K1,K2,…,Kk,…,K6}={Kk},称为6类梯度方向角的区域k,其中,K1对应(0°,30°),K2对应(30°+,60°),K3对应(60°+,90°),K4对应(90°+,120°),K5对应(120°+,150°),K6对应(150°+,180°),其中,30°+表示大于30°,其余类推,符号“{}”表示“含有”元素,下同。
用DK表示学习K后得到的专有字典,简称DK,相应地,用D1~D6分别表示对应的学习6个所述梯度角区域的各向异性图像块后得到的6个专有子字典,而DK由6个专有子字典组成,DK={D1,D2,…,D6}={Dk}。
用D表示所述共享字典D0与专有子字典Dk的集合,表示为:D={D0,DK}={D0,D1,D2,D3,D4,D5,D6}。
用k=1,2,…,6表示各专有子字典的下标序列。用k′=0,1,2,3,4,5,6表示字典D中所含有的全部子字典的下标序列。
用A表示字典编码系数矩阵,A={A0,AK},其中:A0表示所述共享字典D0的编码系数矩阵,AK表示所述专有字典DK的编码系数矩阵,其中,表示AK包括:专有子字典集合{Dk}中对应于各向异性子图像块集合内各个共性图像那部分的字典的编码系数以及6类各向异性子图像的各专有子字典Dk的编码系数矩阵k=1,2,…,6。
各所述编码系数矩阵的元素称为编码系数a,δ<a<<1,设定编码系数为联合优化训练的参变量之一,其目的在于:在后续研究中,当判定先经步骤(2.3)中目标得到,后又经参数变量联合优化的压缩图像与实际的原输入图像在图像相似度上不满足误差要求时,能通过对各编码系数的调节来提高压缩图像与原图像的相似度,以克服误差。
用表示共享字典的自相关矩阵,用表示各专有字典的自相关矩阵。用表示所述字典D={D0,D1,D2,D3,D4,D5,D6}中一区任何一个子字典后余下的各个字典的连接矩阵。
用η表示自相关矩阵调节系数序列,包括:
共享字典D0的自相关矩阵的调节系数η0,0<η0<<1,各专有子字典Dk的自相关矩阵的调节系数ηk,k=1,2,…,6,0<ηk<<1。
用η‘表示字典D中各子字典之间的互相关系数矩阵的调节系数,k′=0,1,2,…,6,0<ηk′′<<1,
用λ表示对所述字典编码系数矩阵A进行正则化的正则化系数,0<λ<<1。
步骤(2),从所述Xi中提取所述K0和K:
步骤(2.1),从图像数据库中随机选取任意大小相等的训练图像,把每一张所述训练图像切分为设定数量且大小相等的图像小块xi,用向量形式表示为xi∈Rm;
步骤(2.2),求取每个所述xi中各像素j在水平和垂直两个方向的梯度gj,得到所述xi的梯度矩阵Gi,简称Gi,再按式Gi=UΣWT进行奇异值分解,得到:
m×m阶酉矩阵U,半正定m×2阶对角矩阵Σ∈Rm×2,对角线上的元素称为奇异值,其中的非零元素代表相应梯度方向的能量大小;2×2阶酉矩阵W,W∈R2×2,每个列向量代表所述xi内各像素的梯度方向;
步骤(2.3),用ρ表示梯度方向能量的差值参数,把目标xi中各方向能量相对均衡且比较平稳的子图像块作为所述各向同性的图像块K0,作为所述公有特征;而把具有明显方向性的子图像块作为所述各项异性图像块K,作为专有特征,根据梯度方向角ω,把所述K分为6个所述的梯度方向角区域,ρ在(0,1)间取值,Σ1,1,Σ2,2为两个所述梯度方向各自对应的奇异值;
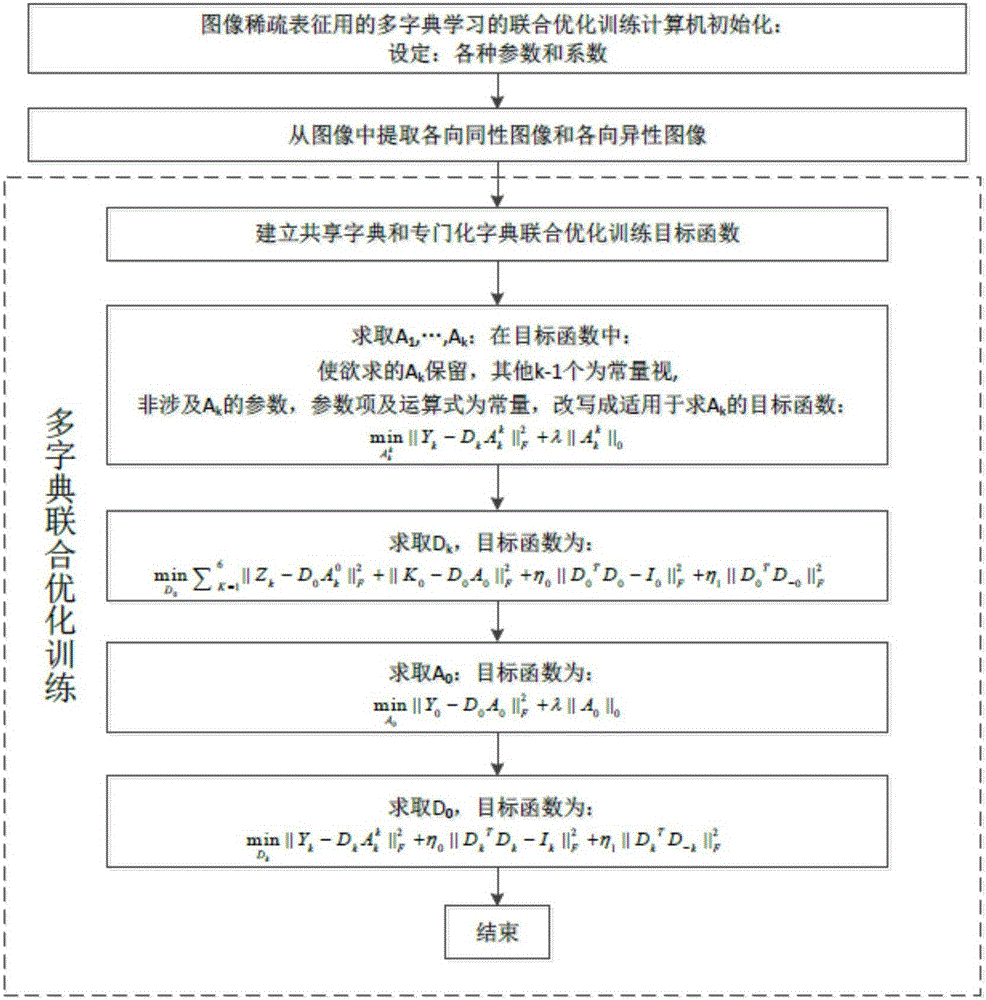
步骤(3),对所述共享字典D0和专有字典Dk按以下步骤进行联合优化训练:
设联合优化的目标函数为:
其中,dj是单位向量,表示矩阵Di的列向量。表示求使得目标函数最小的变量Di,Ai的取值;[D0,Dk]表示将矩阵D0与Dk横向拼接起来成一个大矩阵;||.||F表示矩阵的Frobenius范数;||.||0表示矩阵的L0范数,即非零元素的个数;Qk′是对应于自相关矩阵的单位矩阵;||.||2是向量的欧几里得范数。
步骤(3.1),用递归最小二乘字典学习算法RLA_DLA对所述D0和Dk进行初始化。即对所述各项同性的图像块K0进行字典学习,得到初始化的共享字典D0,及其所对应的初始化的编码系数矩阵A0对所述各项异性的图像块Kk,k=1,2,…,6,分别进行字典学习,得到初始化的专有子字典Dk,k=1,2,…,6,及其所对应的初始化的编码系数矩阵
步骤(3.2),求解所述专有字典Dk及对应的
步骤(3.2.1),改变步骤(3)中出现的联合优化训练的目标函数的表达形式:找出并忽略常数项,保留Dk,项,交替求解。
步骤(3.2.1.1),表示所述各项同性图像集合K0用共享字典D0进行稀疏表征后的残差,该项为常数,不影响目标函数取值,可忽略;
步骤(3.2.1.2),由于A={A0,AK},因而在λ||A||0项中,忽略A0及项,就简化为
步骤(3.2.1.3),改写
被改写项表示第Kk个梯度方向角区域内各向异性子图像块Kk用相对应的编码系数矩阵调节后的共享字典D0和相对应的编码系数矩阵调节后的专有子字典Dk共同进行稀疏表征后的残差。同理,能把项改写为令因而得到的被改写结果的表达式为:
步骤(3.2.1.3),得到改变后的所述联合优化训练的目标函数:
其中,k=1,2,…,6,λ,ηk,η′k均为设定值。
步骤(3.2.2),求解各专有子字典的编码系数矩阵
步骤(3.2.2.1),仅保留与所述编码系数相关的项,忽略其他项,
步骤(3.2.2.2),在Dk不变的条件下,得到用于求解所述编码系数矩阵的目标函数:
步骤(3.2.2.3),设定稀疏度L,根据已知的Kk和D0,用正交匹配追踪算法OMP求得从而得到Yk。带入步骤(3.2.2.2)的目标函数中得到对应的
步骤(3.2.3),求解专有字典DK=[D1,D2,…,D6]:
步骤(3.2.3.1),在步骤(3.2.1.3)所述联合优化训练的目标函数中,忽略常数项保留与各专有子字典Dk相关的项,得到:
步骤(3.2.3.2),按一下步骤求出联合优化训练后的各专有子字典D′k:
步骤(3.2.3.3)令:dγ表示Dk的列向量,称为字典原子,γ为所述列向量的序号,
步骤(3.2.3.4),用下述梯度下降算法更新dγ,γ更新后得到的dγ′构成的子字典用D′k表示:
k=1,2,…,6,符号表示对变量求导,aγ表示系数矩阵的第γ行,得到:ζ1为步长。步长ζ1由armijo准则确定,所述armi jo准则,是一维搜索步长的算法。
步骤(3.3),求解共享字典D0:
步骤(3.3.1),改变步骤(3)中联合优化训练的目标函数的表达形式:
步骤(3.3.1.1),把各Dk及相关的自相关调节系数序列ηk,互相关调节系数η′k,各专有子字典编码系数矩阵视为常数,且A={A0,AK},保留D0,
步骤(3.3.1.2)改写下述各项表达式
改写为:
改写为:
改写为和
λ||A||0改写为还有一项λ||A0||0。
步骤(3.3.1.3),改写后的所述联合优化训练目标函数为:
步骤(3.3.1.4),按步骤(3.3.1.3)求解A0:
固定更新后的专门化字典D′k,令Dk=D′k,保持D0不变,得到用于求解A0的所述联合优化训练目标函数:
用步骤(3.2.2.3)所述的正交匹配追踪算法OMP算法求得A0。
步骤(3.3.1.5),按照步骤(3.3.1.3)提出的所述联合优化训练目标函数求解
在Zk,A0,D0不变的条件下,除了和得以保留外,忽略其他项,得到用于求解的所述联合优化训练目标函数:
用与步骤(3.3.1.4)相同的方法求出
步骤(3.3.1.6),按步骤(3.3.1.3)提出的所述联合优化训练目标函数求解D0:
步骤(3.3.1.6.1),固定更新后的专门化字典D′k,保留与共享字典D0相关的项,得到求解D0的所述联合优化训练目标函数:
其中,D-0表示所有的专有子字典横向拼接起来的矩阵,其表达式为D-0=[D′1,D′2,…,D′6]。
步骤(3.3.1.6.2),用步骤(3.2.3.4)所述的梯度下降算法,所述已更新过的专有子字典Dk′和原子dγ′,再次更新后的原子记为d″γ,得到:
其中:表示中的第γ′行,ζ2表示步长,由步骤(3.2.3.4)中所述armijo准则确定。
附图说明
图1,多几何字典图像压缩方法系统框图。
图2,联合优化训练程序流程框图。
图3,图像块能量差值参数ρ概率分布统计图,横坐标表示能量差值,纵坐标表示图像块数量。
图4,训练完成的字典:
图4.1,共享字典,图4.2,部分专门化字典。
图5,Lena图像压缩客观评价指标:
图5.1,系数非零值个数,
图5.2,率-失真曲线。
图6,图像woman在码率为0.15bpp进行编码的图像:
图6.1,JPEG(PSNR=28.68dB,SSIM=0.63),
图6.2,JPEG2000(PSNR=29.29dB,SSIM=0.77),
图6.3,RLS_DLA(PSNR=28.5dB,SSIM=0.73),
图6.4,本发明,PSNR=29.76dB,SSIM=0.77)。
具体实施方式
选取Berkeley Segmentation Image database作为训练图像集,随机选取200张图像中的8×104个图像块作为训练集,每个图像块的大小为8×8。测试图像来自USC-SIPI数据集,包括一些标准图像,如Lena,boat,man,couple,camera man,woman等。训练得到的字典的大小为200维,即每个字典有200个原子。图像块的能量差值参数的分布情况。将测试图像块求梯度,统计每个图像块的梯度方向的能量分布,即两个主要的梯度方向的能量差值,其概率分布函数如说明书附图2所示。训练得到的共享字典和部分专门化字典展示在说明书附图3中。
实验参数由表1所示。
表1.实验参数
选取图像压缩标准JPEG,JPEG2000方法,以及字典学习算法RLS_DLA,K-SVD作为对比方法进行实验。
以Lena图像为例,其字典所对应的非零值的个数,以及率-失真曲线显示在说明书附图4中。以woman图像为例,其在比特率为0.15bpp时进行编码,重建图像显示在说明书附图5中。其他测试图像在0.5bpp和0.4bpp时进行编码,其客观评测指标PSNR显示在表2中。
表2.码率为0.5bpp(上行)和0.4bpp(下行)时的编码效果
由此可得出结论,所提压缩方法在低码率时能得到相对其他方法更高质的图像,细节保留更完好,失真率较低。
- 还没有人留言评论。精彩留言会获得点赞!