一种RTB竞价广告位价值分析方法及系统与流程
本发明属于大数据处理技术领域,具体地涉及一种RTB竞价广告位价值分析方法及系统。
背景技术:
实时竞价(Real-Time Bidding)广告简称为RTB广告,2010年最先在美国兴起,并很快被引入国内。对于RTB广告,从不同的角度有不同的理解。从用户数据分析的角度,RTB广告是一种在用户数据分析基础上针对每个用户的广告展示行为展开实时竞价的广告类型。而从技术和平台的宏观角度出发,RTB广告是一种模仿股票交易模式,通过机器算法实现实时自动买卖的广告类型。
在RTB广告的交易过程中,实时竞价技术是最关键的技术,需求方(Demand Side Platform,简称DSP)会向媒体采购广告位,广告位的价值是DSP出价高低的关键因素。一般情况下,DSP会接入海量的网站的广告位,如何判断广告位是否值得竞价购买或出价多少购买是困扰DSP的一个难题。
但是,从经济和高效的角度出发,DSP更愿意购买访问量不高且页面较为优质的网站的广告位,主要原因有两个,第一,在以前这是不被重视的市场,因此往往具有相对低廉的价格优势;第二是此类网站市场份额虽小,但由于数量众多,是一个巨大的微小市场,却也占据了市场中客观的份额,也因此会存在众多优质的广告。
同时,近年来随着技术的进步、互联网速度不断提升、以及移动互联网的更新换代,都使得我们对海量网络数据分析的需求不断加深。而面对成几何级数增长的海量网络数据,很多行业都开始设法将其变“数”为宝,并从中分析挖掘出更具商业价值的数据信息。将大数据分析应用到网站广告位的价值分析上,将更能体现出大数据的商业和技术优势。
但是,面对海量网络数据分析之前需要面对如下的一些问题,诸如未能与时俱进的磁盘数据读取速度问题、硬件故障常态化的问题等等。Hadoop集群是一种专门为存储和分析海量非结构化数据而设计的特定类型的集群。本质上,它是一种计算集群,即将数据分析的工作分配到多个集群节点上,从而并行处理数据。使用Hadoop集群最大的好处在于它非常适合大数据分析,而它的两大核心技术HDFS和MapReduce更是将大数据处理提高到了一个新的水平。HDFS是分布式文件系统,它所具有的高容错高可靠性、高可扩展性、高获得性、高吞吐率等特征为海量数据提供了不怕故障的存储,为超大数据集的应用处理带来了很大的便利。而MapReduce是指一种处理海量数据的并行编程模型和计算框架,用于对大规模数据集的并行计算。
因此,有必要提供出一种RTB竞价广告位价值分析方法。
技术实现要素:
本发明的目的在于提供一种RTB竞价广告位价值分析方法。
本发明的技术方案如下:一种RTB竞价广告位价值分析方法,包括如下步骤:一、输入互联网的网络数据到Hadoop集群中,并运用Hadoop集群的MapReduce模块,编写Mapper和Reducer函数,统计出每个host出现的数目,并将统计结果写入Hadoop FS文件系统中;二、将统计结果从Hadoop FS文件系统中导出,并导入Redis数据库,在Redis中,过滤掉访问大于上限次数和小于下限次数的网站的URL,并使得文本以特定的格式保存,得到URL列表文件;三、依据上述获得RTB竞价中高价值网站的host列表,编写网络爬虫去爬取每个网站的html源码,依据广告的特征计算出html源码中广告的属性,并将所述属性保存为广告统计结果文件;四、将所述广告统计结果文件与URL列表文件合并,依据访问量进行排序,获得RTB竞价中高价值网站网站的广告统计列表,对网站广告价值评分标准建模,并对Hadoop筛选结果和爬虫结果进行量化分析。
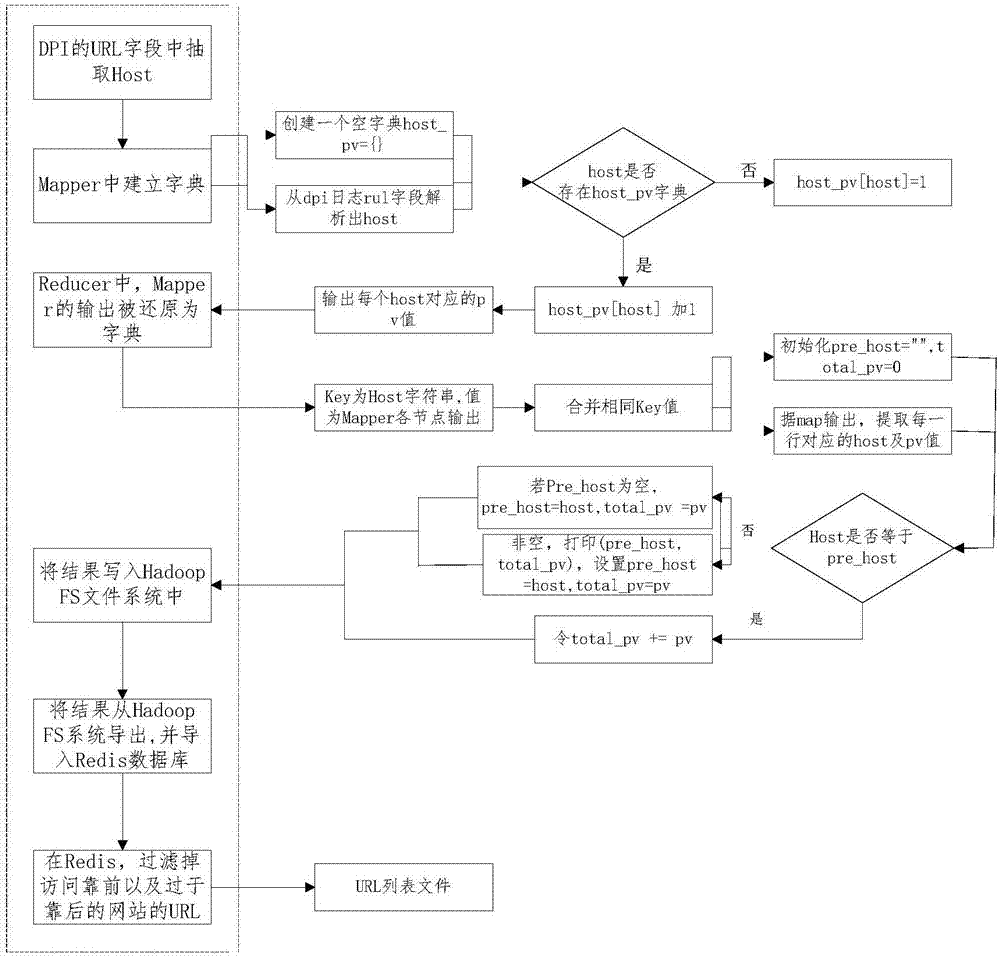
优选地,在步骤一中,具体包括如下步骤:从每条DPI日志的URL字段中抽取Host;在每个Mapper中建立字典,字典的Key为Host字符串,值为该Key出现的频次,每当有重复的Key出现时,对应的值就增加一,当Mapper的循环结束时,将字典的信息Key和Value打印出来交由Reducer汇总统计;在Reducer中,Mapper的输出被还原为字典,Key为Host字符串,值为Mapper阶段各个节点的输出,随后Reducer对相同的Key进行值合并,得到最终的频次之和,并统计输出;将统计结果写入Hadoop FS文件系统中。
优选地,在步骤二中,网站访问次数的上限次数和下限次数均建模得出,建模公式为:
其中,Nf表示判断RTB竞价高价值网站访问次数上限次数,Nb表示高价值网站访问次数下限次数,M表示网站的总个数,N1、N2、…NM分别代表网站访问从第一至第M个的网站的访问次数。
优选地,所述高价值网站为网站访问量处于Nf、Nb之间的网站。
优选地,在步骤三中,具体包括如下步骤:根据URL对指定网页进行内容获取;使用爬虫爬取网页的标题、关键字、描述和正文的字段,并将爬取的结果作为值,网页URL作为键,以文本的形式存入HDFS中,随后利用基于hadoop的分布式分词软件,对海量文本数据进行分词处理;对于源码本身,则进行多模式匹配,寻找源码中的加载广告位的代码,用于分析其网页中广告位的信息,并输出到爬虫结果文件中;爬取网站网页的编写模板和插件,以及图片超链接数量和文字超链接数量,来确定网站精美度。
优选地,在步骤三中,所述广告的属性包括网站精美度、网站广告位数量和网站非法性。
优选地,在步骤四中分析得到的结果为:网站广告位的价值分别与网站访问量及排名、网站精美度、网站广告位数量和网站非法性有关。
优选地,在对所述网站访问量及排名的量化分析中,适中访问量Na的量化标准为:
在对所述网站精美度的量化分析中,精美度影响系数Q的量化标准为:
其中,G为网站精美度的贡献系数,T和W分别为网页中图片链接数和文字链接数;
在对所述网站广告位数量的量化分析中,设内嵌广告位的数量价值系数为P,q为内嵌广告为数量,计算公式为
在对所述网站非法性的量化分析中,设非法系数为F,根据经验对所述非法系数F进行判断。
优选地,长尾网站广告价值系数为V,其计算公式为:
其中,N为进行价值评估的网站的访问量。
一种根据权利要求任一上述的RTB竞价广告位价值分析方法的系统,包括:Hadoop集群数据处理模块,用于导入互联网的网络数据,并运用Hadoop集群的MapReduce模块,编写Mapper和Reducer函数,统计出每个host出现的数目,并将统计结果写入Hadoop FS文件系统中;Redis数据库过滤模块,按访问上限次数和下限次数确定合适RTB竞价的网站;网络爬虫广告计算模块,依据上述获得RTB竞价中高价值网站的host列表,爬取每个网站的html源码,依据广告的特征计算出html源码中广告的属性,并将所述属性保存为广告统计结果文件;网站广告价值评分标准建模,将所述广告统计结果文件与URL列表文件合并,依据访问量进行排序,获得RTB竞价中高价值网站网站的广告统计列表,对网站广告价值评分标准建模,并对Hadoop筛选结果和爬虫结果进行量化分析。
本发明提供的技术方案具有如下有益效果:
1.基于位置信息形成融合的、标准化的位置输出能力。通过从移动网DPI中提取基站小区位置、从移动网DPI中提取GPS位置信息、从4G信令数据中提取基站位置信息,弥补单一从2G基站获取的位置信息精度不高及实时性不高的问题。融合多数据源后,形成的位置数据基础能力,提高用户位置信息的精确度、持续性、完整性,形成完整的位置信息能力输出。
2.利用Spark计算集群的实时处理能力,对海量的多数据源实现不间断的连续在线处理分析,处理能力达到每秒20000条以上记录,处理的时延小于5min,而传统的数据入库-处理-分析的流程,至少有3-6个小时的时延,无法提供实时准确的位置数据。同时,使用Spark的离线数据分析处理能力对历史存量数据进行挖掘分析,相较于传统的Map/Reduce的方式提高了10倍以上的性能。
3.形成基于位置数据的实时应用能力。基于实时的位置数据,以系统的方式提供:实时客流分析,游客来源地分析,游客属性分析,停留时间统计,客流对比分析,客流预测分析,景区关联分析等实时分析功能。
附图说明
图1是本发明实施例提供的RTB竞价广告位价值分析方法的流程示意图;
图2是图1所示RTB竞价广告位价值分析方法中步骤一和步骤二的流程示意图;
图3是图1所示RTB竞价广告位价值分析方法中步骤三的流程示意图;
图4是基于图1所示RTB竞价广告位价值分析方法的系统的结构框图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
除非上下文另有特定清楚的描述,本发明中的元件和组件,数量既可以单个的形式存在,也可以多个的形式存在,本发明并不对此进行限定。本发明中的步骤虽然用标号进行了排列,但并不用于限定步骤的先后次序,除非明确说明了步骤的次序或者某步骤的执行需要其他步骤作为基础,否则步骤的相对次序是可以调整的。可以理解,本文中所使用的术语“和/或”涉及且涵盖相关联的所列项目中的一者或一者以上的任何和所有可能的组合。
请参阅图1,本发明实施例提供的RTB竞价广告位价值分析方法包括如下步骤:
一、输入互联网的网络数据到Hadoop集群中,并运用Hadoop集群的MapReduce模块,编写Mapper和Reducer函数,统计出每个host出现的数目,并将统计结果写入Hadoop FS文件系统中。
请结合参阅图2,具体地,在步骤一中,具体包括如下步骤:
a、从每条DPI日志的URL字段中抽取Host;
b、在每个Mapper中建立字典,字典的Key为Host字符串,值为该Key出现的频次,每当有重复的Key出现时,对应的值就增加一,当Mapper的循环结束时,将字典的信息Key和Value打印出来交由Reducer汇总统计;
c、在Reducer中,Mapper的输出被还原为字典,Key为Host字符串,值为Mapper阶段各个节点的输出,随后Reducer对相同的Key进行值合并,得到最终的频次之和,并统计输出;
d、将统计结果写入Hadoop FS文件系统中。
其中,在步骤b中,其具体算法为:
1,创建一个空字典host_pv={};
2,从dpi日志rul字段解析出host;
3,如果host存在于host_pv字典中,host_pv[host]加1,否则初始化host_pv[host]=1;
4,一个map处理结束时,遍历host_pv字典,以(host,pv)格式输出每个host对应的pv值。
在步骤c中,得到了Host在全部日志中的计数和,即为总的PV数,其具体算法为:
1、初始化pre_host="",total_pv=0;
2、根据map阶段输出,提取每一行对应的host及pv值;
3、如果host不等于pre_host,进行如步骤a)的判断,否则转到步骤4,
a)如果pre_host是为空,则pre_host=host,total_pv=pv;否则打印(pre_host,total_pv),并设置pre_host=host,total_pv=pv;
4、如果host等于pre_host,令total_pv+=pv;
5、reduce最后结束时,如果pre_host不为空,打印(pre_host,total_pv)。
二、将统计结果从Hadoop FS文件系统中导出,并导入Redis数据库,在Redis中,过滤掉访问大于上限次数和小于下限次数的网站的URL,并使得文本以特定的格式保存,得到URL列表文件。
具体地,请结合参阅图2,在步骤二中,网站访问次数的上限次数和下限次数均建模得出。而且,建模公式为:
其中,Nf表示判断RTB竞价高价值网站访问次数上限次数,Nb表示高价值网站访问次数下限次数,M表示网站的总个数,N1、N2、…NM分别代表网站访问从第一至第M个的网站的访问次数。
需要说明的是,在本实施例中,所述高价值网站定义为网站访问量处于Nf、Nb之间的网站。
三、依据上述获得RTB竞价中高价值网站的host列表,编写网络爬虫去爬取每个网站的html源码,依据广告的特征计算出html源码中广告的属性,并将所述属性保存为广告统计结果文件。
具体地,在步骤三中,使用Kafka+flume的分布式架构,既可在单一爬虫服务器上实现多线程爬取,又可便捷地部署在多个爬虫集群中加快爬取进度。可选择地,所述广告的属性包括网站精美度、网站广告位数量和网站非法性。
请参阅图3,所述步骤三具体包括如下步骤:
A)根据URL对指定网页进行内容获取;
B)使用爬虫爬取网页的标题、关键字、描述和正文的字段,并将爬取的结果作为值,网页URL作为键,以文本的形式存入HDFS中,随后利用基于hadoop的分布式分词软件,对海量文本数据进行分词处理;
C)对于源码本身,则进行多模式匹配,寻找源码中的加载广告位的代码,用于分析其网页中广告位的信息,并输出到爬虫结果文件中;
D)爬取网站网页的编写模板和插件,以及图片超链接数量和文字超链接数量,来确定网站精美度。
其中,在步骤B中,分词的结果是网页URL做键、中文单词和词频计数结果为值的文本结果。利用开源工具Apache Mahout这一分布式可扩展的的机器学习和数据挖掘算法包,使用k-Means聚类算法对分词结果进行聚类分析,点之间的距离建模使用cosine余弦夹角算法。通过分词技术,可以得知网站的属性,可以判断网站的内容类型。而网站的非法性通过判断内容类型可以得出。
在步骤C中,爬虫模拟用户访问网页后,网页通过JavaScript代码请求在指定的位置加载广告,一个内嵌广告位的网站会将与如下代码类似的代码加入到页面的HTML代码中:
爬虫在爬取了页面的HTML源码后,对网页源码内容进行建立HTML的DOM树,对所有的<script>tag进行依次分析,比对<script>tag中的src字段和目标集合进行比对,如果符合,则这个JavaScript会在后续的浏览器内容的加载中发出广告展示的请求,并加载广告内容。
通过对几大主流广告媒体的JavaScript的分析,总结得出了会加载广告的以下域名等等:
a.alimama.cn;
cbjs.baidu.com;
cpro.baidustatic.com;
googlesyndication.com;
p.tanx.com。
通过分析<script>的src字段有哪些包含以上的域名结果,就可以得知有各种类型的广告位的具体数目。
在步骤D中,网站的网页架构的使用从某种程度决定了网站的精美度,根据经验,设定主流网页架构的对网站精美度的贡献系数G的取值如下表所示:
而且,近两年比较精美的网站,出现了图片链接多而文字链接少的趋势。因此,本次爬虫对网页的图片链接数T和文字链接数W进行了统计。
四、将所述广告统计结果文件与URL列表文件合并,依据访问量进行排序,获得RTB竞价中高价值网站网站的广告统计列表,对网站广告价值评分标准建模,并对Hadoop筛选结果和爬虫结果进行量化分析。
具体地,在步骤四中,分析得到的结果为:网站广告位的价值分别与网站访问量及排名、网站精美度、网站广告位数量和网站非法性有关。因此,在本实施例中,将所有因素量化分析,建立网站广告价值的分析模型。
其中,在对所述网站访问量及排名的量化分析中,但若访问量过少,其关注度过低,则其广告价值也不大;若访问量较大,其网站广告位价格较高,广告价值也较小。因此,RTB竞价高价值网站的访问量约适中,网站广告位价值越大。具体地,适中访问量Na的量化标准为:
在对所述网站精美度的量化分析中,根据网站模板和嵌套精品模板的数量进行量化,精美度影响系数Q的量化标准为:
在对所述网站广告位数量的量化分析中,设内嵌广告位的数量价值系数为P,q为内嵌广告为数量,计算公式为
在对所述网站非法性的量化分析中,设非法系数为F,根据经验对所述非法系数F进行判断。而且,F的定义标准为:
根据上述分析,将所有因素进行综合建模处理,即为长尾网站广告价值系数为V,其计算公式为:
其中,N为进行价值评估的网站的访问量。
而且,对于最终的网站广告价值系数V,其对应评价为:
一般来说,高价值、较高价值的网站的商用价值很大。
请参阅图4,一种基于图1所示RTB竞价广告位价值分析方法的系统包括Hadoop集群数据处理模块10、Redis数据库过滤模块20、网络爬虫广告计算模块30和网站广告价值评分标准建模40。
其中,所述Hadoop集群数据处理模块10用于用于导入互联网的网络数据。
具体地,在所述Hadoop集群数据处理模块10中,将某个时段内的海量的网络数据输入到Hadoop集群中,存储在Hadoop的HDFS(分布式文件管理系统),由于网络数据的数据量较大,数据将会被分配HDFS的多个数据节点上,这可以便于实现数据的并行处理和分析。在集群中编写shell脚本,配置数据处理路径和调用模块;接着编写MapRedue模块中的Mapper和Reducer函数,其中Mapper函数提取其中的URL字段,将URL字段根据“com”、“net”、“org”、“co”、“gov”、“edu”、“biz”、“info”、“name”、“.cn”域名分析出其host字段,每出现一次,Mapper将此记录推送到Reducer处理,而Reducer函数接受排序分组后的Mapper的输出,统计每个host出现的数目,并写入到HDFS文件管理系统中。
所述Redis数据库过滤模块20按访问上限次数和下限次数确定合适RTB竞价的网站。
具体地,在所述Redis数据库过滤模块20中,将Reducer写入的HDFS的结果数据导出,并导入Redis数据库进行分析。在Redis数据库过滤模块中,编写python脚本,留存访问量在网站访问次数上限次数和上限次数之间的网站,从而也可以根据其他需求,过滤掉不需要处理的网站。接着,将Redis过滤之后的数据导出为一个待处理的文本:此文本的格式为:每行一个仅有host字段的短URL,这就是要获取的长尾网站的URL列表,并将此长尾URL列表文本交由网络爬虫模块。
所述网络爬虫广告计算模块30依据上述获得RTB竞价中高价值网站的host列表,爬取每个网站的html源码,依据广告的特征计算出html源码中广告的属性,并将所述属性保存为广告统计结果文件。
具体地,在所述网络爬虫广告计算模块30中,依据此URL列表开始爬取每个网站首页的html源码,根据广告的特征计算出html源码会成广告的数量和种类,并将计算结果写入文本保存。接着将爬虫技术爬取的广告信息与URL列表文件合并,并按照访问量进行排序,这样就获得了长尾网站广告统计列表。
所述网站广告价值评分标准建模40将所述广告统计结果文件与URL列表文件合并,依据访问量进行排序,获得RTB竞价中高价值网站网站的广告统计列表,对网站广告价值评分标准建模,并对Hadoop筛选结果和爬虫结果进行量化分析。
需要说明的是,在本实施例中,所述RTB竞价广告位价值分析方法及系统具有如下特点:
1.将“长尾”的思想与网站广告价值分析相结合。利用长尾的思想“小”和“大”,小指份额很少的市场,在以前这是不被重视的市场或没有条件重视的市场;大指的是这些市场虽然很小,但是数量众多。很多数量的微小市场占据着市场中可观的份额。“长尾网站广告价值分析”是“长尾营销”的一种具体实现形式,具有巨大的研究和商业价值。以某电信省级运营商管道数据为例,一天的有效访问流量大概在100亿条左右,每天的访问网站大概在700万个,而大概170主流网站如百度、腾讯、淘宝、京东等约占比67%左右,这部分网站的广告位价格一般极高,而33%的流量集中在剩余700万个网站中,而从700万个中网站中找到适合的广告高价值网站意义极大。
2.将“大数据分析”引入到网站广告价值分析中。随着技术的进步、互联网速度不断提升、以及移动互联网的更新换代,都更使得我们不断加深了大数据分析的需求不断的加深。而面对成几何级数增长的海量网络数据,很多行业都开始设法将其变“数”为宝,并从中分析挖掘出更具有商业价值的数据信息价值的信息显得尤为重要。将大数据分析应用到长尾网站的广告分析上,将更能体现出长尾网站的个体优势及潜在商业价值。
3.针对网站广告属性分析的“网络爬虫”技术。传统网络爬虫从一个或若干初始网页的URL开始,编写网络爬虫去爬取每个网站的html源码,主要爬取网站的基本属性和自有业务内容,而本专利利用网络爬虫技术,主要爬取目标为网站广告位,通过自定义算法得出网站中各广告位的各种属性,满足长尾网站广告位的定制化需求分析。
相较于现有技术,本发明提供的技术方案具有如下有益效果:
1、将网络爬虫与网站广告的特征相结合,通过自定义算法得出网站中各广告位的各种属性,使得网站广告价值分析更具针对性,也能够满足网站广告的定制化需求分析,所有被爬虫抓取的广告属性特征将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的分析和利用;
2、利用Hadoop集群的大数据处理,来分析RTB竞价高价值网站的广告价值,从而可以有效地处理海量网路数据,并从所述海量网络数据中高效的地提取并分析RTB竞价高价值网站的广告价值。
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
- 还没有人留言评论。精彩留言会获得点赞!