基于数据挖掘的建模方法及装置与流程
本发明涉及数据挖掘
技术领域:
,尤其涉及一种基于数据挖掘的建模方法及装置。
背景技术:
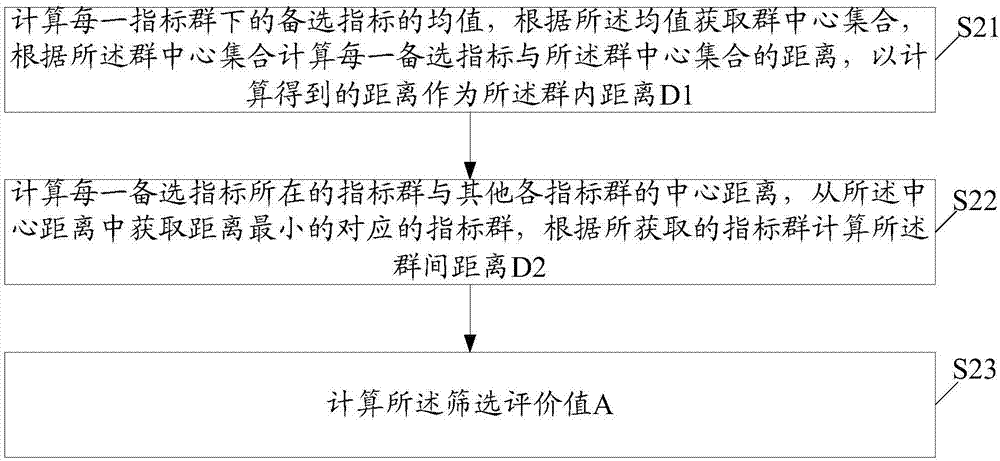
:目前,在与数据挖掘相关的建模中,通常收集到的备选建模指标数量较多,有时多达200个以上,但通常对建模有效的一般只有一部分,例如在200个备选建模指标中可能只有30个是有效的。为了从大量的备选建模指标中筛选出建模所需的有效指标,现有的方法是人工手动选出高相关度的指标进行建模,这种人工选择的方法由于带有主观性,因此不能准确地选出建模的有效指标,且建模的效率低。技术实现要素:本发明的目的在于提供一种基于数据挖掘的建模方法及装置,旨在准确地选出相关性最弱的备选指标,提高建模效率。为实现上述目的,本发明提供一种基于数据挖掘的建模方法,所述基于数据挖掘的建模方法包括:S1,在收到待筛选的备选指标后,将所述备选指标均分成K个指标群;S2,计算各指标群中每一备选指标的群内距离D1和群间距离D2,根据所述群内距离D1和群间距离D2并基于预定的计算规则计算各备选指标对应的筛选评价值A;S3,根据所述筛选评价值A选择备选指标,基于所述K值并利用所选择的备选指标建立指标模型。优选地,所述步骤S2包括:S21,计算每一指标群下的备选指标的均值,根据所述均值获取群中心集合,根据所述群中心集合计算每一备选指标与所述群中心集合的距离,以计算得到的距离作为所述群内距离D1;S22,计算每一备选指标所在的指标群与其他各指标群的中心距离,从所述中心距离中获取距离最小的对应的指标群,根据所获取的指标群计算所述群间距离D2;S23,计算所述筛选评价值A:A=(1-D1)/(1-D2)。优选地,所述步骤S3包括:S31,在每一指标群中,选出最大筛选评价值对应的至少一个备选指标和最小筛选评价值对应的至少一个备选指标;S32,若所述K值大于等于预设阈值时,则利用各指标群挑选出的备选指标建立预定的一指标模型;S33,若所述K值小于预设阈值时,则增大所述K值,重新计算筛选评价值并执行步骤S31,以利用各指标群选出的备选指标建立预定的另一指标模型。优选地,所述步骤S3之后还包括:S4,利用预定的验证数据样本对所建立的指标模型进行验证,将验证后准确率最高的指标模型作为基准模型进行应用。优选地,所述步骤S4包括:若准确率最高的指标模型的数量为1,则将该准确率最高的指标模型作为基准模型进行应用;若准确率最高的指标模型的数量大于1,则随机选择一准确率最高的指标模型作为基准模型进行应用,或者,增加验证数据样本的数量,直至准确率最高的指标模型的数量为1,并将该准确率最高的指标模型作为基准模型进行应用。为实现上述目的,本发明还提供一种基于数据挖掘的建模装置,所述基于数据挖掘的建模装置包括:均分模块,用于在收到待筛选的备选指标后,将所述备选指标均分成K个指标群;计算模块,用于计算各指标群中每一备选指标的群内距离D1和群间距离D2,根据所述群内距离D1和群间距离D2并基于预定的计算规则计算各备选指标对应的筛选评价值A;建立模块,用于根据所述筛选评价值A选择备选指标,基于所述K值并利用所选择的备选指标建立指标模型。优选地,所述计算模块包括:第一计算单元,用于计算每一指标群下的备选指标的均值,根据所述均值获取群中心集合,根据所述群中心集合计算每一备选指标与所述群中心集合的距离,以计算得到的距离作为所述群内距离D1;第二计算单元,用于计算每一备选指标所在的指标群与其他各指标群的中心距离,从所述中心距离中获取距离最小的对应的指标群,根据所获取的指标群计算所述群间距离D2;第三计算单元,用于计算所述筛选评价值A:A=(1-D1)/(1-D2)。优选地,所述建立模块包括:选择单元,用于在每一指标群中,选出最大筛选评价值对应的至少一个备选指标和最小筛选评价值对应的至少一个备选指标;第一建立单元,用于若所述K值大于等于预设阈值时,则利用各指标群挑选出的备选指标建立预定的一指标模型;第二建立单元,用于若所述K值小于预设阈值时,则增大所述K值,重新计算筛选评价值并选出的备选指标,以利用各指标群选出的备选指标建立预定的另一指标模型。优选地,所述基于数据挖掘的建模装置还包括:验证模块,用于利用预定的验证数据样本对所建立的指标模型进行验证,将验证后准确率最高的指标模型作为基准模型进行应用。优选地,所述验证模块具体用于若准确率最高的指标模型的数量为1,则将该准确率最高的指标模型作为基准模型进行应用;若准确率最高的指标模型的数量大于1,则随机选择一准确率最高的指标模型作为基准模型进行应用,或者,增加验证数据样本的数量,直至准确率最高的指标模型的数量为1,并将该准确率最高的指标模型作为基准模型进行应用。本发明的有益效果是:本发明在将备选指标均分为若干个指标群后,首先计算各指标群中每一备选指标的群内距离D1和群间距离D2,根据群内距离D1和群间距离D2计算得到筛选评价值A,由于筛选评价值A综合考虑备选指标的群内距离D1和群间距离D2,因此,根据筛选评价值A可以选出相关性最小的备选指标,即选出的备选指标为最具有代表性或者最有效的指标,不需人工手动选取,选取的准确性高,且建模效率高。附图说明图1为本发明基于数据挖掘的建模方法第一实施例的流程示意图;图2为图1所示步骤S2的细化流程示意图;图3为图1所示步骤S3的细化流程示意图;图4为本发明基于数据挖掘的建模方法第二实施例的流程示意图;图5为本发明基于数据挖掘的建模装置一实施例的结构示意图;图6为图5所示计算模块的结构示意图;图7为图5所示建立模块的结构示意图。具体实施方式以下结合附图对本发明的原理和特征进行描述,所举实例只用于解释本发明,并非用于限定本发明的范围。如图1所示,图1为本发明基于数据挖掘的建模方法一实施例的流程示意图,该基于数据挖掘的建模方法包括以下步骤:步骤S1,在收到待筛选的备选指标后,将所述备选指标均分成K个指标群;本实施例可应用在一基于数据挖掘的建模装置中,该装置在接收到待筛选的备选指标后,将备选指标随机均分成K个指标群,以对备选指标进行聚类分析。其中,K为大于1的自然数,例如,共有150个备选指标,若K为10,则随机均分成10个指标群,每个指标群中有15个备选指标。其中,在接收到150个备选指标之前,例如初始备选指标有200个,可以通过逐步回归向前向后的方法,设置合适的参数来初步选出150个备选指标。其中,以建立客户是否发生理赔的模型为例,备选指标包括人口统计特征、生命阶段特征、客户价值信息、产品持有情况、投保行为习惯、历史理赔相关信息等等。步骤S2,计算各指标群中每一备选指标的群内距离D1和群间距离D2,根据所述群内距离D1和群间距离D2并基于预定的计算规则计算各备选指标对应的筛选评价值A;本实施例中,群内距离D1指的是备选指标变量与群中心集合的相关系数,该群内距离D1越大,则说明该备选指标与群中心集合的相关性越大。群中心集合由各指标群中的备选指标的均值决定。群间距离D2指的是备选指标变量与离群最近的群的中心的相关系数,该群间距离D2越小,则说明该备选指标与离群最近的群的中心的相关性越大。根据各备选指标的群内距离D1和群间距离D2计算筛选评价值A时,同时考虑各备选指标的群内距离D1和群间距离D2,所计算得出的筛选评价值A具备综合性及目的性。步骤S3,根据所述筛选评价值A选择备选指标,基于所述K值并利用所选择的备选指标建立指标模型。本实施例中的筛选评价值A,在根据筛选评价值A选择备选指标时,可选择出相关性最小的备选指标,例如选择筛选评价值A最大的对应的备选指标及选择筛选评价值A最小的对应的备选指标,选择筛选评价值A最大的对应的10个备选指标及筛选评价值A最小的对应的10个备选指标。另外,所建立的模型例如可以是逻辑回归模型、决策树模型或神经网络模型等。根据指标群的数量K建立模型,例如,在K值较小时可以建立某种模型或某几种,当K值大于某个阈值时可以建立另一种模型或另几种模型,即主要根据指标群的数量来确定所建立的模型。与现有技术相比,本实施例在将备选指标均分为若干个指标群后,首先计算各指标群中每一备选指标的群内距离D1和群间距离D2,根据群内距离D1和群间距离D2计算得到筛选评价值A,由于筛选评价值A综合考虑备选指标的群内距离D1和群间距离D2,因此,根据筛选评价值A可以选出相关性最小的备选指标,即选出的备选指标为最具有代表性或者最有效的指标,不需人工手动选取,选取的准确性高,且建模效率高。在一优选的实施例中,如图2所示,在上述图1的实施例的基础上,步骤S2包括:S21,计算每一指标群下的备选指标的均值,根据所述均值获取群中心集合,根据所述群中心集合计算每一备选指标与所述群中心集合的距离,以计算得到的距离作为所述群内距离D1;S22,计算每一备选指标所在的指标群与其他各指标群的中心距离,从所述中心距离中获取距离最小的对应的指标群,根据所获取的指标群计算所述群间距离D2;S23,计算所述所述筛选评价值A:A=(1-D1)/(1-D2)。本实施例中,假设有5个备选指标变量X1、X2、X3、X4、X5,其中Xi=(Xi1,Xi2,...,Xin),n=10,如下表1所示:X1X2X3X4X5-0.02106-0.02075-0.00183-0.25420.517368-0.02106-0.02075-0.001830.3055050.367093-1.54935-1.54959-1.49993-1.00909-0.51768-0.02106-0.020750.3165220.305505-0.03013-1.54935-1.54959-1.49993-1.00909-0.03013-1.54935-1.54959-1.49993-0.25420.556034-1.54935-1.54959-1.49993-0.2542-0.82450.9364790.9370070.9090811.0206550.556034-1.54935-1.54959-1.49993-0.25420.367093-0.50968-0.50945-0.47902-0.2542-0.51768表1其中,这五个备选指标变量组合的群中心是5个备选指标变量的各分量的均值:M=(m1,m2,...,mn),其中其中,m1=(-0.02106-0.02075-0.00183-0.2542+0.517368)/5=0.043906;m2=(-0.02106-0.02075-0.00183+0.305505+0.367093)/5=0.125792;此时可以计算出这五个备选指标变量的中心(即群中心集合)为:M=(0.043906,0.125792,-1.22513,0.110018,-1.12762,-0.85941,-1.13551,0.871851,-0.8972,-0.45401)。由上可以得到,备选指标变量X1与群中心的距离:设是备选指标变量X1的均值,就是群中心集合M的均值,n是样本的个数(指标群的数量),可以计算出X1的均值为-0.73831,M的均值为-0.45473。该距离D1即为备选指标变量X1的群内距离D1。以此类推,可以计算得到各备选指标变量的群内距离D1。在计算群间距离时,首先计算备选指标变量所在的指标群中心与其他指标群中心的距离:这里mpi是各指标群的中心MP的各个分量,mqi是其他指标群的中心MQ的各个分量。从上述距离d中找出备选指标变量与离群最近的指标群的中心,然后根据备选指标变量与群中心的距离公式计算出备选指标变量的群间距离:最后,计算筛选评价值A:A=(1-D1)/(1-D2),另外,筛选评价值A也可以用这种方法计算得到:A=(1-D2)/(1-D1)。在一优选的实施例中,如图3所示,在上述图1的实施例的基础上,上述步骤S3包括:S31,在每一指标群中,选出最大筛选评价值对应的至少一个备选指标和最小筛选评价值对应的至少一个备选指标;S32,若所述K值大于等于预设阈值时,则利用各指标群挑选出的备选指标建立预定的一指标模型;S33,若所述K值小于预设阈值时,则增大所述K值,重新计算筛选评价值并执行步骤S31,以利用各指标群选出的备选指标建立预定的另一指标模型。本实施例中,可以为每一指标群选出筛选评价值最大的至少一个备选指标和筛选评价值最小的至少一个备选指标,以使得所选出的备选指标之间的相关性最弱。如果所选出的备选指标之间的相关性最弱,则所选出的备选指标为最具有代表性或者最有效的指标。本实施例中,如果K值大于等于预设阈值(例如预设阈值为15)时,则利用各指标群挑选出的备选指标建立预定的一指标模型;若K小于预设阈值,则将K增加1,并重新将备选指标均分成(K+1)个指标群,然后计算对应的群内距离D1、群间距离D2及筛选评价值A,根据筛选评价值A选择备选指标,以建立另一个预先确定的模型。在一优选的实施例中,如图4所示,在上述图1的实施例的基础上,在上述步骤S3之后还包括:S4,利用预定的验证数据样本对所建立的指标模型进行验证,将验证后准确率最高的指标模型作为基准模型进行应用。本实施例中,在建立模型之后,可以对模型的准确性进行验证。例如可以利用预先确定的验证数据样本对建立的各个模型进行验证,以确定各个模型对应的准确率,然后将准确率最高的模型作为基准模型进行应用。优选地,如果准确率最高的指标模型的数量为1,则将该准确率最高的指标模型作为基准模型进行应用;若准确率最高的指标模型的数量大于1,则随机选择一准确率最高的指标模型作为基准模型进行应用,或者,增加验证数据样本的数量,直至准确率最高的指标模型的数量为1,并将该准确率最高的指标模型作为基准模型进行应用。如图5所示,图5为本发明基于数据挖掘的建模装置一实施例的结构示意图,该基于数据挖掘的建模装置包括:均分模块101,用于在收到待筛选的备选指标后,将所述备选指标均分成K个指标群;本实施例在接收到待筛选的备选指标后,将备选指标随机均分成K个指标群,以对备选指标进行聚类分析。其中,K为大于1的自然数,例如,共有150个备选指标,若K为10,则随机均分成10个指标群,每个指标群中有15个备选指标。其中,在接收到150个备选指标之前,例如初始备选指标有200个,可以通过逐步回归向前向后的方法,设置合适的参数来初步选出150个备选指标。其中,以建立客户是否发生理赔的模型为例,备选指标包括人口统计特征、生命阶段特征、客户价值信息、产品持有情况、投保行为习惯、历史理赔相关信息等等。计算模块102,用于计算各指标群中每一备选指标的群内距离D1和群间距离D2,根据所述群内距离D1和群间距离D2并基于预定的计算规则计算各备选指标对应的筛选评价值A;本实施例中,群内距离D1指的是备选指标变量与群中心集合的相关系数,该群内距离D1越大,则说明该备选指标与群中心集合的相关性越大。群中心集合由各指标群中的备选指标的均值决定。群间距离D2指的是备选指标变量与离群最近的群的中心的相关系数,该群间距离D2越小,则说明该备选指标与离群最近的群的中心的相关性越大。根据各备选指标的群内距离D1和群间距离D2计算筛选评价值A时,同时考虑各备选指标的群内距离D1和群间距离D2,所计算得出的筛选评价值A具备综合性及目的性。建立模块103,用于根据所述筛选评价值A选择备选指标,基于所述K值并利用所选择的备选指标建立指标模型。本实施例中的筛选评价值A,在根据筛选评价值A选择备选指标时,可选择出相关性最小的备选指标,例如选择筛选评价值A最大的对应的备选指标及选择筛选评价值A最小的对应的备选指标,选择筛选评价值A最大的对应的10个备选指标及筛选评价值A最小的对应的10个备选指标。另外,所建立的模型例如可以是逻辑回归模型、决策树模型或神经网络模型等。根据指标群的数量K建立模型,例如,在K值较小时可以建立某种模型或某几种,当K值大于某个阈值时可以建立另一种模型或另几种模型,即主要根据指标群的数量来确定所建立的模型。在一优选的实施例中,如图6所示,在上述图5的实施例的基础上,上述计算模块102包括:第一计算单元1021,用于计算每一指标群下的备选指标的均值,根据所述均值获取群中心集合,根据所述群中心集合计算每一备选指标与所述群中心集合的距离,以计算得到的距离作为所述群内距离D1;第二计算单元1022,用于计算每一备选指标所在的指标群与其他各指标群的中心距离,从所述中心距离中获取距离最小的对应的指标群,根据所获取的指标群计算所述群间距离D2;第三计算单元1023,用于计算所述筛选评价值A:A=(1-D1)/(1-D2)。本实施例中,假设有5个备选指标变量X1、X2、X3、X4、X5,其中Xi=(Xi1,Xi2,…,Xin),n=10,如上表1所示。其中,这五个备选指标变量组合的群中心是5个备选指标变量的各分量的均值:M=(m1,m2,…,mn),其中其中,m1=(-0.02106-0.02075-0.00183-0.2542+0.517368)/5=0.043906;m2=(-0.02106-0.02075-0.00183+0.305505+0.367093)/5=0.125792;此时可以计算出这五个备选指标变量的中心(即群中心集合)为:M=(0.043906,0.125792,-1.22513,0.110018,-1.12762,-0.85941,-1.13551,0.871851,-0.8972,-0.45401)。由上可以得到,备选指标变量X1与群中心的距离:设是备选指标变量X1的均值,就是群中心集合M的均值,n是样本的个数(指标群的数量),可以计算出X1的均值为-0.73831,M的均值为-0.45473。该距离D1即为备选指标变量X1的群内距离D1。以此类推,可以计算得到各备选指标变量的群内距离D1。在计算群间距离时,首先计算备选指标变量所在的指标群中心与其他指标群中心的距离:这里mpi是各指标群的中心MP的各个分量,mqi是其他指标群的中心MQ的各个分量。从上述距离d中找出备选指标变量与离群最近的指标群的中心,然后根据备选指标变量与群中心的距离公式计算出备选指标变量的群间距离:最后,计算筛选评价值A:A=(1-D1)/(1-D2),另外,筛选评价值A也可以用这种方法计算得到:A=(1-D2)/(1-D1)。在一优选的实施例中,如图7所示,在上述图5的实施例的基础上,建立模块103选择单元1031,用于在每一指标群中,选出最大筛选评价值对应的至少一个备选指标和最小筛选评价值对应的至少一个备选指标;第一建立单元1032,用于若所述K值大于等于预设阈值时,则利用各指标群挑选出的备选指标建立预定的一指标模型;第二建立单元1033,用于若所述K值小于预设阈值时,则增大所述K值,重新计算筛选评价值并选出的备选指标,以利用各指标群选出的备选指标建立预定的另一指标模型。本实施例中,可以为每一指标群选出筛选评价值最大的至少一个备选指标和筛选评价值最小的至少一个备选指标,以使得所选出的备选指标之间的相关性最弱。如果所选出的备选指标之间的相关性最弱,则所选出的备选指标为最具有代表性或者最有效的指标。本实施例中,如果K值大于等于预设阈值(例如预设阈值为15)时,则利用各指标群挑选出的备选指标建立预定的一指标模型;若K小于预设阈值,则将K增加1,并重新将备选指标均分成(K+1)个指标群,然后计算对应的群内距离D1、群间距离D2及筛选评价值A,根据筛选评价值A选择备选指标,以建立另一个预先确定的模型。在一优选的实施例中,在上述图5的实施例的基础上,所述基于数据挖掘的建模装置还包括:验证模块,用于利用预定的验证数据样本对所建立的指标模型进行验证,将验证后准确率最高的指标模型作为基准模型进行应用。本实施例中,在建立模型之后,可以对模型的准确性进行验证。例如可以利用预先确定的验证数据样本对建立的各个模型进行验证,以确定各个模型对应的准确率,然后将准确率最高的模型作为基准模型进行应用。优选地,验证模块具体用于若准确率最高的指标模型的数量为1,则将该准确率最高的指标模型作为基准模型进行应用;若准确率最高的指标模型的数量大于1,则随机选择一准确率最高的指标模型作为基准模型进行应用,或者,增加验证数据样本的数量,直至准确率最高的指标模型的数量为1,并将该准确率最高的指标模型作为基准模型进行应用。以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1