一种job控制方法及装置与流程
本发明涉及数据分析技术领域,特别涉及一种作业job控制方法及装置。
背景技术:
随着科学的进步,时代的发展,数据量增涨呈现爆炸态势,每几年就会翻一番。大量的数据中包含着诸多有价值的信息,上至国家经济走向、发展趋势,下至每个网关传输的数据是否正常,因此,大数据处理平台应运而生。大数据处理平台中的数据是由不同的数据源产生的,针对每个数据源,运行解析作业(job)和入库job,从而对该数据源产生的数据进行解析入库操作,解析入库后的数据可供大数据处理平台中的数据分析、数据挖掘应用进行数据的分析和挖掘,从中找出用户需要的信息,为用户的决策、制定发展战略等提供支持。
然而,现有技术中如果存在接入的数据源,无论该数据源是否处于启动状态,解析job和/或入库job一直处于运行状态,造成处理资源的浪费,给用户带来了损失。
技术实现要素:
本发明提供一种job控制方法及装置,用以解决现有技术中无论数据源是否处于启动状态,对应的解析job和/或入库job一直处于运行状态,造成处理资源的浪费的问题。
为达到上述目的,本发明实施例公开了一种作业job控制方法,所述方法包括:
针对接入大数据平台的每个数据源,根据kafka消息队列中保存的每个数据源的状态信息,识别是否每个数据源都处于停止状态;
如果是,关闭解析job和/或入库job。
进一步地,所述方法还包括:
根据kafka消息队列中保存的每个数据源的状态信息,识别是否存在处于启动状态的数据源;
如果是,开启解析job和/或入库job。
进一步地,如果当前存在处于启动状态的数据源,所述方法还包括:
判断解析job和/或入库job是否针对该数据源发送的数据进行解析和/或入库操作;
如果否,控制解析job和/或入库job对该数据源发送的数据进行解析和/或入库操作。
进一步地,所述控制解析job和/或入库job对该数据源发送的数据进行解析和/或入库操作包括:
重启所述解析job和/或入库job,采用重启后的解析job和/或入库job对处于启动状态的数据源发送的数据进行解析和/或入库操作。
进一步地,所述根据kafka消息队列中保存的每个数据源的状态信息,识别是否每个数据源都处于停止状态之前,所述方法还包括:
根据用户对每个数据源启动或停止的设置指令,生成每个数据源对应的状态信息保存到所述kafka消息队列中。
本发明实施例公开了一种作业job控制装置,所述装置包括:
识别模块,用于针对接入大数据平台的每个数据源,根据kafka消息队列中保存的每个数据源的状态信息,识别是否每个数据源都处于停止状态;
关闭模块,用于如果识别模块识别到每个数据源都处于停止状态,关闭解析job和/或入库job。
进一步地,所述识别模块,还用于根据kafka消息队列中保存的每个数据源的状态信息,识别是否存在处于启动状态的数据源;
所述装置还包括:
开启模块,用于如果所述识别模块识别到当前存在处于启动状态的数据源,开启解析job和/或入库job。
进一步地,所述装置还包括:
判断模块,用于如果当前存在处于启动状态的数据源,判断解析job和/或入库job是否针对该数据源发送的数据进行解析和/或入库操作;
控制模块,用于如果判断模块的判断结果为否,控制解析job和/或入库job对该数据源发送的数据进行解析和/或入库操作。
进一步地,所述控制模块,具体用于重启所述解析job和/或入库job,采用重启后的解析job和/或入库job对处于启动状态的数据源发送的数据进行解析和/或入库操作。
进一步地,所述装置还包括:
生成模块,用于根据用户对每个数据源启动或停止的设置指令,生成每个数据源对应的状态信息保存到所述kafka消息队列中。
本发明实施例公开了一种job控制方法及装置,该方法包括:针对接入大数据平台的每个数据源,根据kafka消息队列中保存的每个数据源的状态信息,识别是否每个数据源都处于停止状态;如果是,关闭解析job和/或入库job。由于在本发明实施例中,根据kafka消息队列中保存的每个数据源的状态信息,识别是否每个数据源都处于停止状态,如果是,关闭解析job和/或入库job,节约了处理资源,减少了用户的损失。
附图说明
图1为本发明实施例提供的一种大数据处理平台对数据源的数据进行解析入库操作的过程示意图;
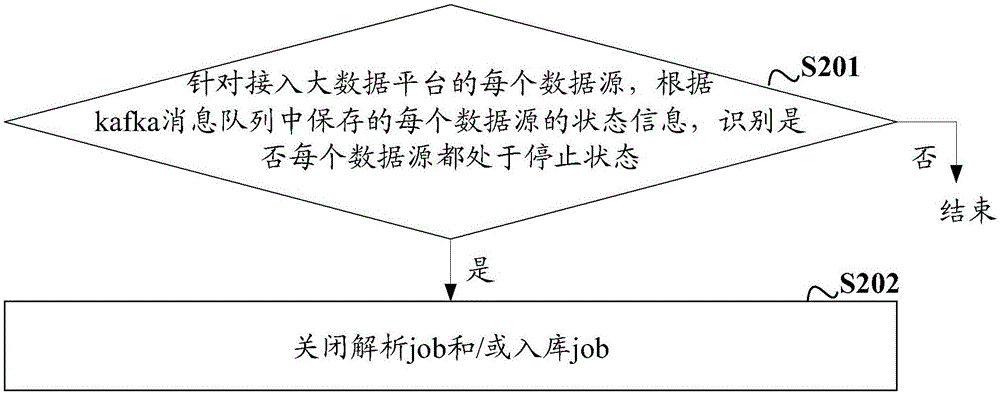
图2为本发明实施例1提供的一种job控制过程示意图;
图3为本发明实施例2提供的一种job控制过程示意图;
图4为本发明实施例3提供的一种job控制过程示意图;
图5为本发明实施例4提供的一种job控制过程示意图;
图6为本发明实施例提供的一种job控制装置结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
图1为本发明实施例提供的一种大数据处理平台对数据源的数据进行解析入库操作的过程示意图,针对每个接入的数据源(DataSource),都由大数据处理平台中的作业控制系统(job Manager)来配置每个数据源对应的解析job和入库job需要的资源,并且默认在job Manager中的解析job和入库job不启动,只有当数据源处于启动状态时,才开启解析job和入库job,并将该数据源发送的数据进过解析后,分别存入数据仓库(Hive)及弹性搜索(ElasticSearch,ES)中。
具体的,在job Manager中建立有分布式消息订阅系统(Kafka),在Kafka中针对每个数据源都对应着一个标题(topic),并建立有对数据源发送的数据进行解析和入库的解析job和入库job,其中入库job包括入ES job和入Hive job,并将解析后的数据存入对应的Hive和ES中。
例如:针对DataSource1,会将对DataSource1的开启、关闭的操作消息写入到topic中去,启动DataSource1时,topic中记录的DataSource1为启动状态,解析job和入库job针对DataSource1发送的数据进行解析和入库操作。在job Manager中默认所有的数据源公用一套资源配置,但是每个数据源接入的数据量不同,因此需要配备的资源也不同,job Manager提供对单个数据源的个性化配置功能,其中针对单个数据源的个性化配置为用户或运维人员预先创建的。当数据源存在数据操作时,job Manager会检测是否存在该数据源对应的个性化配置文件,如果存在则加载个性化配置文件,如果不存在则使用公用配置common.xml,具体的检测示例如下:
实施例1:
图2为本发明实施例提供的一种job控制过程示意图,该过程包括:
S201:针对接入大数据平台的每个数据源,根据kafka消息队列中保存的每个数据源的状态信息,识别是否每个数据源都处于停止状态,如果是,进行S202,如果否,结束。
本发明实施例中数据源包括交换机、路由器、网关等网络设备,防火墙、防毒墙等安全软件,还包括身份认证系统、邮件系统、企业资源计划系统等数据系统。
在大数据处理项目中,大数据处理平台的主要功能是将接入进来的不同数据源的数据进行解析,并将解析后的数据存入Hive及ES中,用来支持大数据处理平台中上层的数据分析、数据挖掘等业务。大数据处理平台从数据源的接入到大数据处理平台中上层的数据分析、数据挖掘等业务的进行,中间主要依靠job Manager对每个数据源的解析job和入库job进行控制,保证每个数据源的解析job和入库job正确稳定的进行。
在本发明实施例中,接入大数据处理平台的数据源包括路由器、交换机等硬件类型的数据源,也包括如邮件系统、企业资源计划系统等软件类型的数据源。
具体的,针对接入大数据处理平台的每个数据源,在kafka消息队列中保存有每个数据源的处于启动状态或者停止状态的信息,根据kafka消息队列中保存的每个数据源的状态信息,识别是否每个数据源都处于停止状态。
S202:关闭解析job和/或入库job。
job是一个由多个任务组成的并行计算的集合,常用于驱动程序日志。为了实现对每个数据源产生的数据进行解析入库操作,在本发明实施例中针对数据源,建立有解析job和入库job,通过建立的该解析job和入库job对数据源产生的数据进行解析入库操作。
因为在大数据处理平台中处理资源是一定的,并且对解析入库后的数据进行分析也依赖着大数据处理平台中的处理资源,而解析job和入库job对处理资源的占用率很高,为了防止处理资源的浪费,如果识别到每个数据源都处于停止状态,关闭解析job和/或入库job。
如果只判断解析job是否处于运行状态,并且识别到解析job处于运行状态,则关闭解析job;如果只判断入库job是否处于运行状态,并且识别到入库job处于运行状态,则关闭入库job;如果判断的是解析job和入库job,如果其中一个或者两个都处于运行状态,则关闭处于运行状态的job。
由于在本发明实施例中,根据kafka消息队列中保存的每个数据源的状态信息,识别是否每个数据源都处于停止状态,如果是,关闭解析job和/或入库job,节约了处理资源,减少了用户的损失。
实施例2:
在本发明实施例中,关闭解析job和/或入库job后,为了保证对处于启动状态的数据源发送的数据正常的进行解析入库,在上述实施例的基础上,所述方法还包括:
根据kafka消息队列中保存的每个数据源的状态信息,识别是否存在处于启动状态的数据源;
如果是,开启解析job和/或入库job。
具体的,如果识别到kafka消息队列中存在处于启动状态的数据源,则说明需要对该数据源发送的数据进行解析、入库操作,开启解析job和/或入库job。
图3为本发明实施例提供的一种job控制过程示意图,该过程包括:
S301:根据kafka消息队列中保存的每个数据源的状态信息,识别是否存在处于启动状态的数据源,如果是,进行S302,如果否,进行S303。
S302:开启解析job和/或入库job。
S303:保持解析job和/或入库job关闭。
如果之前关闭了解析job,则识别到kafka消息队列中存在处于启动状态的数据源时,开启解析job,如果关闭了入库job,则识别到kafka消息队列中存在处于启动状态的数据源时,开启入库job;如果关闭了解析job和入库job,则识别到kafka消息队列中存在处于启动状态的数据源时,开启解析job和入库job。
实施例3:
为了保证对处于启动状态的数据源发送的数据解析入库的正常进行,在上述各实施例的基础上,在本发明实施例中,如果当前存在处于启动状态的数据源,所述方法还包括:
判断解析job和/或入库job是否针对该数据源发送的数据进行解析和/或入库操作;
如果否,控制解析job和/或入库job对该数据源发送的数据进行解析和/或入库操作。
具体的,针对每个处于启动状态的数据源,判断解析job和/或入库job是否针对该数据源发送的数据进行解析和/或入库操作;如果否,则说明解析job和/或入库job针对该数据源进行解析和/或入库操作的过程意外终止,控制解析job和/或入库job对该数据源发送的数据进行解析和/或入库操作,从而保证对处于启动状态的数据源的解析入库的正常进行,提高用户的体验。
对解析job和/或入库job是否针对每个处于启动状态的数据源发送的数据进行解析和/或入库操作进行判断,可以是按照设定的时间间隔,定时对解析job和/或入库job是否针对每个处于启动状态的数据源发送的数据进行解析和/或入库操作进行判断,保证对处于启动状态的数据源发送的数据进行正常的解析入库。
为了提高用户体验,保证对处于启动状态的数据源发送的数据解析入库的正常进行,所述控制解析job和/或入库job对该数据源发送的数据进行解析和/或入库操作包括:
重启所述解析job和/或入库job,采用重启后的解析job和/或入库job对处于启动状态的数据源发送的数据进行解析和/或入库操作。
具体的,如果解析job和/或入库job未对处于启动状态的数据源发送的数据进行解析入库操作,重新启动该解析job和/或入库job,控制该解析解析job和/或入库job对处于启动状态的数据源发送的数据进行解析入库操作。
在本发明实施例中,对解析job和入库job对正在进行数据解析和入库操作的识别,及控制解析job和入库job对处于开启状态的数据源发送的数据进行解析和入库操作是现有技术,不再进行赘述。
图4为本发明实施例提供的一种job控制过程示意图,对于启动状态的数据源(Dataresource start),解析job和/或入库job对该数据源进行解析和/或入库操作的进程,如果对该数据源的解析入库的进程中停止(Process Exists stop),重启(restart)解析job和/或入库job,控制解析job和/或入库job对启动状态的数据源发送的数据进行解析入库操作。
实施例4:
为了保证对每个处于启动状态的数据源发送的数据解析入库操作的正常进行,在上述各实施例的基础上,在本发明实施例中,所述根据kafka消息队列中保存的每个数据源的状态信息,识别是否每个数据源都处于停止状态之前,所述方法还包括:
根据用户对每个数据源启动或停止的设置指令,生成每个数据源对应的状态信息保存到所述kafka消息队列中。
针对接入大数据处理平台的数据源,job Manager对应着一套job控制,保证对每个数据源发送的数据解析、入库的正确进行,针对每个数据源设置了启动(start)状态、停止(stop)状态、更新(update)状态、删除(delete)状态四个状态。其中,当用户需要大数据处理平台对该数据源发送的数据进行解析、入库操作时,将该数据源对应状态设置为start状态,当用户不需要大数据处理平台对该数据源发送的数据进行解析、入库操作时,将该数据源对应状态设置为stop状态。当该数据源的配置数据发生改变时,对该数据源进行更新时,对该数据源设置为update状态,当对该数据源对应的配置数据进行删除时,对该数据源设置为update)状态。根据每个数据源对应的状态,在kafka消息队列中保存有每个数据源对应的状态信息。
如果所有的数据源的状态都为stop状态,所有数据源的stop状态合为一条stop状态消息,job Manager根据合为一条的该stop消息,关闭解析job和/或入库job,从而节约处理资源。如果存在数据源的状态为start状态,所有的数据源的状态消息产出(produce)合为一条start状态消息,job Manager根据合为一条的该start状态消息开启解析job和/或入库job。
用户可以根据自身的需求,对每个数据源的状态进行设置,例如:存在数据源路由器、网关和交换机,用户根据自身的需求,如果用户只需要对交换机发送的数据进行解析和入库操作,将交换机的状态设置为启动状态,将网关和交换机的状态设置为停止状态。实现只对用户需求的数据源的数据进行解析入库,提高用户的体验。
具体的,根据用户每个数据源启动或停止的设置指令,生成每个数据源对应的状态信息保存到所述kafka消息队列中。
图5为本发明实施例提供的一种job控制过程示意图,针对每个目标数据源DataSource在Kafka中有根据数据源建立的topic、标题文件(topic_tmp),job Manager根据该目标数据源对应的topic、topic_tmp,控制解析job和入库job的开启及关闭,及控制解析job和入库job对该目标数据源发送的数据进行解析入库操作。
实施例5:
图6为本发明实施例提供的一种job控制装置结构示意图,该装置包括:
识别模块61,用于针对接入大数据平台的每个数据源,根据kafka消息队列中保存的每个数据源的状态信息,识别是否每个数据源都处于停止状态;
关闭模块62,用于如果识别模块识别到每个数据源都处于停止状态,关闭解析job和/或入库job。
所述识别模块61,还用于根据kafka消息队列中保存的每个数据源的状态信息,识别是否存在处于启动状态的数据源;
所述装置还包括:
开启模块63,用于如果所述识别模块识别到当前存在处于启动状态的数据源,开启解析job和/或入库job。
所述装置还包括:
判断模块64,用于如果当前存在处于启动状态的数据源,判断解析job和/或入库job是否针对该数据源发送的数据进行解析和/或入库操作;
控制模块65,用于如果判断模块的判断结果为否,控制解析job和/或入库job对该数据源发送的数据进行解析和/或入库操作。
所述控制模块65,具体用于重启所述解析job和/或入库job,采用重启后的解析job和/或入库job对处于启动状态的数据源发送的数据进行解析和/或入库操作。
所述装置还包括:
生成模块66,用于根据用户对每个数据源启动或停止的设置指令,生成每个数据源对应的状态信息保存到所述kafka消息队列中。
本发明实施例公开了一种job控制方法及装置,该方法包括:针对接入大数据平台的每个数据源,根据kafka消息队列中保存的每个数据源的状态信息,识别是否每个数据源都处于停止状态;如果是,关闭解析job和/或入库job。由于在本发明实施例中,根据kafka消息队列中保存的每个数据源的状态信息,识别是否每个数据源都处于停止状态,如果是,关闭解析job和/或入库job,节约了处理资源,减少了用户的损失。
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例作出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
- 还没有人留言评论。精彩留言会获得点赞!