用于辅助超级计算机的维护和优化的方法和系统与流程
本发明涉及超级计算机的领域。更特别地,本发明提出一种用于辅助超级计算机的维护和优化的方法和系统,以便实时检测异常从而优化超级计算机的运行。
背景技术
公司经常借助于超级计算机来解决复杂问题。他们实际上是在寻找有效地进行计算,以满足他们的需求的可能性。这需要大型的基础设施。超级计算机有时包含数千台机器,以提供更佳的计算能力。例如,超级计算机tera100具有超过3000个计算节点。另外,所有这些机器都是相互连接的,使基础设施更加复杂。由于这是在高性能计算(hpc)中特别使用的高速率网络,因此这些链接就更大了。
除了这些超级计算机处理复杂问题的事实之外,它通常涉及关键性任务。这就是为什么除了考虑超级计算机的性能之外,提高后者的可靠性也很重要。事实上,现在可以说每隔半小时,通过这种基础设施就会出现一个关键性错误。除了这些潜在故障之外,还必须不断更新作为把网络分组从一台机器发送给另一台机器的路径的路由。事实上,按照超级计算机启动的应用,会出现拥塞现象。
归因于如上所述的这种复杂性,人类分析是不可能的或者至少高度受限。事实上,在这种类型的关键系统中,发生错误后的反应时间通常太长,并且因此导致服务中断。因此,想法是提供一种工具来实时辅助网络的维护,以改善这种反应度,从而使服务中断降至最少。目的是提高超级计算机的可靠性。提高超级计算机的可靠性还意味着优化其使用,并且因此优化进行的计算的性能。
文献us2014/0358833a1公开了一种处理环境的维护方法,更准确地说,公开了一种预测所述环境在未来某个时刻的异常状态的预测方法,所述方法包括获得处理系统的一个或多个参数的一个或多个值,以对于一个或多个指标测量(measure),确定为未来的一个或多个时间点预测的一个或多个值,从而根据所述预测值来确定一个或多个时间点的变化值,并根据一个或多个变化值来判定在处理系统中是否存在异常状态。
但是,要处理的大量参数或数据可能会对异常的检测过程带来负担。另外,在us2014/0358833a1中公开的方法考虑会导致异常的错误预测或检测的一些任意参数。
技术实现要素:
因此,本发明的目的是通过提出一种辅助超级计算机的维护和优化方法和系统,来消除现有技术的一个或多个缺点。所述方法和系统提高超级计算机的可靠性。提高超级计算机的可靠性也意味着优化其使用,从而优化进行的计算的性能。
因此,一种用于辅助超级计算机的维护和优化的方法,所述方法包括:
-由至少一个传感器将代表超级计算机的至少一个计算节点的统计数据的信号发送给用于辅助维护的系统的发送步骤;
-通过由用于辅助维护的系统的处理器管理的预测算法,根据由一个或多个传感器发送并存储在用于辅助维护的系统的存储装置中的代表统计数据的信号,按规律的间隔预测所述统计数据的未来变化的预测步骤;
-通过由处理器管理的检测算法,实时检测由一个或多个传感器发送的代表统计数据的信号的变化相对于在预测步骤中预测的未来变化的异常的检测步骤;
所述方法的特征在于,对未来变化的预测步骤和对异常的检测步骤分别至少包括根据发送了实现维护和优化所述超级计算机所需的所述信号的所述一个或多个传感器,来对代表统计数据的所述信号进行的第一过滤和第二过滤。
按照另一个特征,预测步骤包括以下步骤:
-将由一个或多个传感器以代表统计数据的信号的形式发送的这些统计数据存储在存储装置中;
-通过由处理器管理的建模算法,根据统计数据来构建预测数学模型,该模型存储在存储装置中;
-通过由处理器管理的计算算法,根据所述预测数学模型来计算统计数据的未来变化以及为统计数据的未来变化定界的置信区间;
-将所述未来变化和置信区间存储在存储装置中。
按照另一个特定特征,预测数学模型的构建是通过由处理器管理的建模算法,根据来自于由一个或多个传感器从最后两个小时发送的代表统计数据的信号的这些统计数据而计算的。
按照另一个特定特征,按六十分钟的规律间隔来实现预测步骤。
按照另一个特定特征,检测步骤包括以下步骤:
-通过由处理器管理的检测算法,将代表统计数据的信号与最后存储在存储装置中的未来变化和置信区间进行比较;
-以异常表的形式,将由检测算法检测到的异常存储在存储装置中,异常是在代表统计数据的信号脱离置信区间和/或偏离未来变化时检测到的。
按照另一个特定特征,预测步骤还包括在设定的时间间隔期间,通过由处理器管理的聚合算法对存储在存储装置中的统计数据进行的第一聚合步骤,检测步骤还包括在相同的时间间隔期间,通过处理器对由一个或多个传感器实时发送的代表统计数据的信号进行的第二聚合步骤。
按照另一个特定特征,在预测步骤期间的、通过由所述处理器管理的过滤算法根据发送了代表统计数据的所述信号的所述一个或多个传感器来对这些统计数据进行的第一过滤步骤在构建步骤之前,在检测步骤中的、通过由所述处理器管理的过滤算法根据发送了代表统计数据的信号的所述一个或多个传感器来对这些代表性信号进行的第二过滤在比较步骤之前。
按照另一个特定特征,过滤步骤允许过滤传感器,以只保留发送预测和/或检测异常所需的信号的传感器。
按照另一个特定特征,预测步骤包括第一显示步骤,在第一显示步骤中,用于辅助维护的系统的处理器将代表未来变化的值的信号以及置信区间发送给显示装置,以由显示装置显示。
按照另一个特定特征,检测步骤包括第二显示步骤,在第二显示步骤中,当检测算法检测到异常时,用于辅助维护的系统的处理器将代表由检测算法检测到的异常的信号发送给显示装置。
按照另一个特定特征,还根据与超级计算机相关的信息来进行预测步骤,存储在超级计算机的存储区域中并且包含所述信息的数据被发送给用于辅助维护的系统。
本发明还涉及一种用于辅助超级计算机的维护和优化的系统,所述系统包括计算机基础设施,所述计算机基础设施包括至少一个处理器和代表由位于所述超级计算机的至少一个计算节点中的至少一个传感器发送的统计数据的信号的存储装置,所述存储装置还至少包含:
-预测算法,所述预测算法在所述处理器上的执行允许根据来自所述传感器的代表统计数据的信号,按规律的间隔来预测所述统计数据的未来变化,
-检测算法,所述检测算法在所述处理器上的执行允许实时检测来自所述传感器的代表统计数据的信号的变化相对于由预测算法预测的变化的异常,
所述系统的特征在于,所述系统还包括至少一个算法,所述至少一个算法在所述处理器上的执行允许根据发送了代表实现按照维护和优化方法所需的统计数据的所述信号的所述一个或多个传感器,来过滤代表这些统计数据的所述信号。
按照另一个特定特征,所述计算机基础设施还包括:
-存储在存储装置中的建模算法,所述建模算法能够根据存储在存储装置中的统计数据来构建预测数学模型,
-存储在存储装置中的计算算法,所述计算算法能够根据所述预测数学模型来计算统计数据的未来变化以及为统计数据的未来变化定界的置信区间。
按照另一个特定特征,检测算法能够将代表统计数据的信号与最后存储在存储装置中的未来变化和置信区间进行比较。
按照另一个特定特征,所述计算机基础设施包括存储在存储装置中的至少一个聚合算法,所述聚合算法能够聚合存储在存储装置中的每分钟的统计数据,以及聚合由一个或多个传感器实时发送的代表统计数据的每分钟的信号。
按照另一个特定特征,所述计算机基础设施还包括存储在存储装置中的过滤算法,所述过滤算法能够根据发送了代表统计数据的信号的一个或多个传感器,来过滤存储在存储装置中的统计数据和代表这些统计数据的信号。
按照另一个特定特征,所述计算机基础设施包括允许为各个传感器选择预测和/或检测异常所需的信号的类型,并在所有传感器中选择用于过滤预测和/或检测异常所需的所述数据或所述信号的一定数目的传感器的接口。
按照另一个特定特征,所述系统还包括能够至少显示未来变化的值以及置信区间的显示装置。
附图说明
通过阅读参考附图进行的以下详细说明,本发明的其他特定特征和优点将变得清楚,附图中:
-图1示意性图解说明按照实施例的辅助超级计算机的维护和优化的系统;
-图2图解说明按照方法的实施例的流程图;
-图3示意性图解说明用于辅助维护和优化的系统的架构的例子;
-图4示意性图解说明方法的概述流程图。
具体实施方式
下面参考上述附图说明本发明。
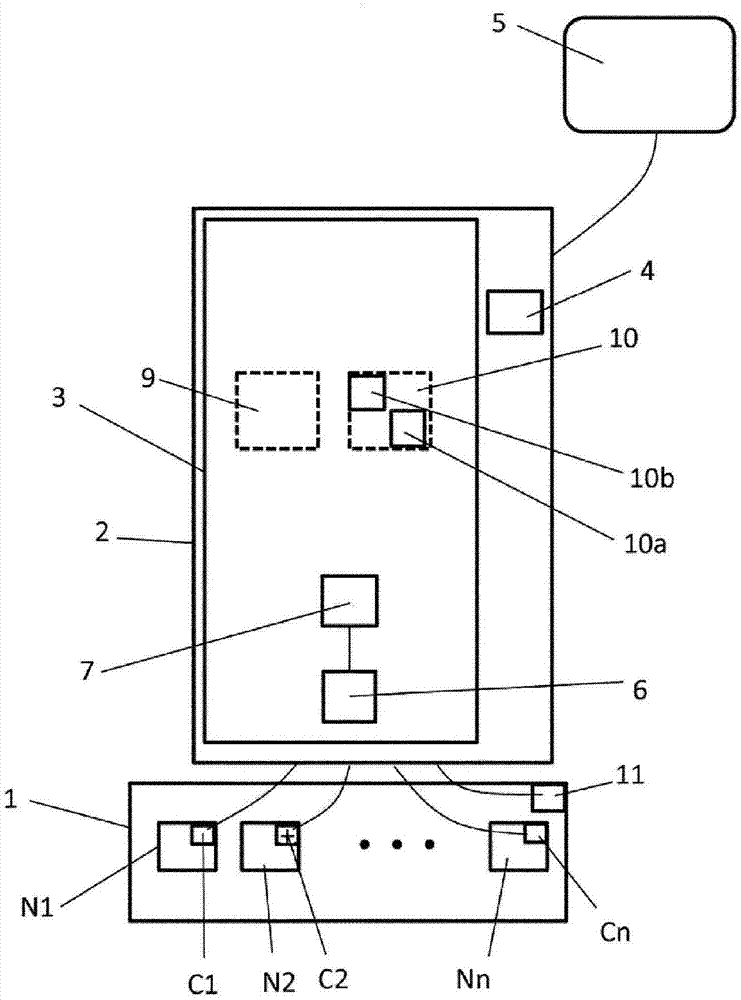
本发明涉及一种辅助超级计算机(1)的维护和优化的方法和系统。
所述方法和系统基于例如存在于超级计算机(1)的各个节点(n1,n2,...,nn)的网卡上的一组物理传感器(c1,c2,...,cn)。这些传感器(c1,c2,...,cn)可生成代表一些统计数据的信号(s)。
统计数据例如可以是由计算节点(n1,n2,...,nn)发送的分组的数目、计算节点(n1,n2,...,nn)接收的分组的数目、或者计算节点(n1,n2,...,nn)丢失的分组的数目。统计数据也可以是在计算节点(n1,n2,...,nn)中发现的错误代码,或者计算节点(n1,n2,...,nn)的拥塞指示。
所述方法和系统还基于已存在于超级计算机(1)中的特定数据库。所述数据库可包含与超级计算机(1)相关的统计信息。例如,所述数据库包含各个节点(n1,n2,...,nn)及其链接的物理和逻辑信息。所述数据库和信息被存储在例如超级计算机的存储区域中。
用于辅助超级计算机(1)的维护和优化的系统包括容纳(host)所述系统的业务逻辑的虚拟或真实计算机基础设施(2)。
计算机结构包含至少一个处理器(4)和存储装置(3)。
存储装置(3)存储用于根据由传感器(c1,c2,...,cn)发送并存储在存储装置(3)中的代表统计数据的信号,按规律的间隔预测统计数据的未来变化的至少一个预测算法(10)。
存储装置(3)还包含用于实时检测由传感器(c1,c2,...,cn)发送的代表统计数据的信号的变化相对于利用预测算法(10)预测的未来变化的异常的检测算法(9)。
按照实施例,检测算法(9)可把代表统计数据的信号与最后存储在存储装置(3)中的未来变化和置信区间相比较。非限制性地,置信区间可被固定为5%。
计算机基础设施(2)还可包括存储在存储装置(3)中的建模算法(10a)。建模算法(10a)根据存储在存储装置(3)中的统计数据,构建预测数学模型。
按照实施例,建模算法(10a)构建模型,所述模型允许根据在先值确定时间序列的各个值。例如,所述模型是自回归积分滑动平均(arima)模型。该模型被存储在存储装置中。
计算机基础设施(2)还可包括存储在存储装置(3)中的计算算法(10b)。计算算法(10b)根据由建模算法(10a)构建的预测数学模型,计算统计数据的未来变化,以及为统计数据的未来变化定界的置信区间。
计算机基础设施(2)还可包括存储在存储装置(3)中的至少一种聚合算法(7),所述聚合算法(7)聚合存储在存储装置(3)中的每分钟的统计数据。聚合算法(7)还允许聚合传感器(c1,c2,...,cn)实时发送的代表统计数据的每分钟的信号。
聚合算法(7)例如是确定一组值的平均值或中值的函数。可以使用适合于待研究的统计数据的其他聚合函数。
这样,通过每分钟确定存储在存储装置(3)中的统计数据的平均值或中值,聚合算法(7)能够聚合每分钟的统计数据。通过每分钟确定由传感器(c1,c2,...,cn)实时发送的代表统计数据的信号的平均值或中值,聚合算法(7)还能够实时聚合代表统计数据的每分钟的信号。
计算机基础设施(2)还可包括存储在存储装置(3)中的过滤算法(6),过滤算法(6)根据发送了代表统计数据的信号的传感器(c1,c2,...,cn)来过滤存储在存储装置(3)中的这些统计数据和代表的这些统计数据的信号。
系统还包括显示置信区间以及未来变化的值的显示装置(5)。代表置信区间和未来变化的值的信号由计算机基础设施(2)的处理器(4)发送,使得显示装置(5)显示这些值。
处理器(4)还可例如以异常表(102e)的形式发送代表异常的信号。
处理器(4)还可把代表统计数据的信号实时发送给显示装置(5),使得这些显示装置(5)显示统计数据的这些值。
由用于辅助超级计算机(1)的维护和优化的系统实现的方法至少包括由至少一个传感器(c1,c2,...,cn)向辅助维护的系统的处理器发送代表超级计算机(1)的至少一个计算节点(n1,n2,...,nn)的统计数据的信号的步骤(100)。非限制性地,发送的统计数据可按150go/h的速度发送。
按照实施例,发送步骤(100)可包括通过超级计算机的数据库,把与超级计算机相关的信息发送给辅助维护的系统的处理器的步骤(100a),和/或辅助维护的系统的处理器查询超级计算机的数据库以便取回与超级计算机相关的信息的步骤(100a)。
所述方法还包括根据由传感器(c1,c2,...,cn)发送并存储在辅助维护的系统的存储装置(3)中的代表统计数据的信号,来按规律的间隔预测统计数据的未来变化的预测步骤(102)。所述预测步骤(102)是利用由辅助维护的系统的处理器(4)管理的预测算法(10)实现的。
按照实施例,按60分钟的规律间隔实现预测步骤(102)。
所述方法还包括实时检测由传感器(c1,c2,...,cn)发送的代表统计数据的信号的变化相对于在预测步骤中预测的未来变化的异常的检测步骤(101)。该预测步骤是利用由处理器(4)管理的检测算法(9)实现的。
按照实施例,检测步骤还可包括使由传感器发送和/或处理器查询的代表统计数据的信号与存储在超级计算机的存储区域中的信息关联的步骤。
预测步骤(102)可包括把由传感器(c1,c2,...,cn)发送的统计数据存储在存储装置(3)中的存储步骤(102a)。所述统计数据由传感器(c1,c2,...,cn)以代表这些统计数据的信号的形式发送。
预测步骤(102)还可包括通过由处理器(4)管理的建模算法,根据存储在存储装置(3)中的统计数据,来构建预测数学模型的构建步骤(102b)。
按照实施例,通过建模算法(10a),根据来自传感器(c1,c2,...,cn)从最后两个小时发送的代表这些统计数据的信号的统计数据,计算预测数学模型的构建(102b)。
预测步骤(102)还可包括通过由处理器(4)管理的计算算法,根据所述预测数学模型来计算统计数据的未来变化,以及为统计数据的未来变化定界的置信区间的计算步骤(102c)。
预测步骤(102)还可包括把在计算步骤中计算的未来变化和置信区间存储在存储装置(3)中的存储步骤(102d)。
检测步骤(101)可包括通过由处理器(4)管理的检测算法(9),将代表统计数据的信号与最后存储在存储装置(3)中的未来变化及置信区间相比较的比较步骤(101a)。
检测步骤(101)还可包括以异常表(102e)的形式,将由检测算法(9)检测到的那些异常存储在存储装置(3)中的存储步骤(101b)。异常是在代表统计数据的信号脱离置信区间和/或离开未来变化时检测到的。
为了提高预测数学模型的构建步骤(102b)的性能并限制由传感器(c1,c2,...,cn)发送的信号的变化,例如正弦变化,预测步骤(102)还包括在设定的时间间隔内,借助由处理器(4)管理的聚合算法(7)进行的对存储在存储装置(3)中的统计数据的第一聚合步骤(106a)。类似地,检测步骤还包括在相同的时间间隔期间,由处理器(4)进行的对由传感器(c1,c2,...,cn)实时发送的代表统计数据的信号的第二聚合步骤(105a)。
非限制性地,所述时间间隔等于1分钟。
第二聚合步骤(105a)可将代表实时发送的统计数据的信号的真实值与在预测步骤期间在第一聚合步骤(106a)处的聚合预测值相比较。
所述方法可包括过滤步骤(105b、106b)。这些过滤步骤(105b、106b)只保留预测和/或检测由传感器(c1,c2,...,cn)发送的异常所需的那些信号。例如,对于一个传感器,过滤步骤按照由对预测和/或检测来说所需的信号代表的(一个或多个)数据,过滤由传感器(c1,c2,...,cn)发送的不同信号。再例如,对于一些传感器(c1,c2,...,cn),过滤步骤过滤传感器(c1,c2,...,cn),以便只保留发送对异常的预测和/或检测来说所需的信号的传感器(c1,c2,...,cn)。
计算机基础设施(2)因此可包括为各个传感器(c1,c2,...,cn),选择预测和/或检测异常所需的信号类型,并在所有传感器(c1,c2,...,cn)中选择将用于过滤预测和/或检测异常所需的所述数据或所述信号的一定数目的传感器(c1,c2,...,cn)的接口(未图示)。
这样,预测步骤(102)还包括通过由处理器(4)管理的过滤算法(6),根据发送了代表统计数据的信号的传感器(c1,c2,...,cn)来对这些统计数据进行的第一过滤步骤(106b)。第一过滤步骤(106b)在构建步骤(102a)之前。
检测步骤(101)包括通过由处理器(4)管理的过滤算法(6),根据发送了代表统计数据的信号的传感器(c1,c2,...,cn),来对这些代表性信号进行的第二(105b)过滤步骤。第二过滤步骤(105b)在比较步骤(101a)之前。
在第一显示步骤(103)中,在用于计算预测步骤(102)的步骤(102c)期间计算的未来变化的值(103a)以及置信区间,由处理器(4)以代表这些值的信号的形式发送给显示装置(5),以便显示在显示装置(5)上。
第一过滤步骤(106b)在第一聚合步骤(106a)之前。第二过滤步骤(105b)在第二聚合步骤(105a)之前。
检测步骤包含第二显示步骤(104),在第二显示步骤(104)中,当检测算法(9)检测到异常时,用于辅助维护的系统的处理器(4)把代表由检测算法(9)检测到的异常的至少一个信号发送给显示装置(5)。
处理器(4)可以异常表的形式,把代表异常的信号发送给显示装置(5)。例如,发送的异常表是在检测步骤(102)期间,存储在存储装置(3)中的那些检测到的异常的异常表(102e)。
用于辅助维护和优化的系统的用户(0)可注视显示装置,以根据显示在显示装置上的信息,决定为优化超级计算机的运行而要采取的行动。
下面说明用于辅助维护和优化的系统的可能架构(图3)。这是被分成数层以同时进行预测步骤和检测步骤的软件架构。
至于由传感器(c1,c2,...,cn)进行的代表统计数据的信号的发送步骤,在数据获取层(200)中,利用工具来收集、分析和存储日志或日志文件,比如充当不同的日志发布协议的连接器的“logstash”(201)。
“日志”或“日志文件”意味着按时间先后列出已执行的事件的文本文件。日志是可用于了解错误或异常的出处的文件。
“logstash”(201)工具向负责管理数据的面向消息的工具(比如“kafka”(202)之类)发送数据。就其本质而言,“kafka”(202)工具是整合用于扩展和吸收大量数据的队列的消息代理(broker)。
“logstash”(201)工具还可对于输入数据实现过滤步骤。
一旦通过“logstash”(201)工具进行了用于收集和/或过滤数据的步骤,所述数据就可用于在称为“批次”(batch)的重(heavy)处理层(300)中实现预测步骤。使用用于收集、聚合和传送大量日志的工具,诸如例如“flume”(301)之类。“flume”(301)工具是数据管理工具“kafka”(202)和其中存储数据的分布式文件系统(比如“hdfs”(302)之类)之间的连接器。一旦数据被存储,就可借助分布式处理用平台,(比如“spark”(303)之类),实现构建步骤和计算步骤。
“分布式系统”、“分布式平台”或者一般分布式架构意味着资源不在相同地方或者不在相同机器上的架构,所述资源通过通信装置互连。例如,计算集群或超级计算机是分布式架构或系统。事实上,按照定义,超级计算机具有中央机器和称为节点的自主次级站或机器,中央机器和节点由通信网络连接。
“spark”(303)工具利用包含帮助数据分析(这种情况下,统计数学模型的建构以及预测值和置信区间的计算)的大量统计工具的r语言。
“spark”工具例如实现聚合步骤(105a、106a)。
至于检测步骤,在实时的处理层(400)中,还使用分布式处理平台,不过实时进行处理。可以使用“spark”(303)工具的实时版本,比如“sparkstreaming”(401)之类。
在用于预测步骤的重处理层(300)和用于检测步骤的实时处理层(400)中获得的结果由分布式搜索引擎(比如“elasticsearch”(500)之类)索引。
对于显示步骤,例如可以使用诸如“kibana”(600)之类的web接口。“kibana”(600)接口负责通过在搜索引擎“elasticsearch”(500)上提出请求的结果的图形显示。
本说明参考附图和/或技术特征,详细描述了各个实施例和配置。本领域的技术人员将明白各种方式或配置的各种技术特征可以组合在一起,除非明确地另有说明,或者这些技术特征不相容。类似地,实施例或配置的技术特征可以独立于与该实施例的其他技术特征,除非明确地另有说明。在本说明中,作为例示而不是对本发明的限制,提供了许多具体细节,以便准确地详细描述本发明。然而,本领域的技术人员将明白在缺少这些具体细节中的一个或多个细节的情况下,或者利用具体细节的变型,也可实现本发明。在其他情况下,一些方面未被详细描述以避免使说明复杂和负担过重,并且本领域的技术人员会明白可以使用各种不同的变化手段,并且本发明不限于说明的唯一例子。
对本领域的技术人员来说清楚的是,本发明允许许多其他具体形式的实施例,而不脱离要求保护的本发明的应用领域。从而,实施例应被视为举例说明,在附加权利要求书的范围限定的领域中,可对实施例进行修改,并且本发明不限于上面给出的细节。
- 还没有人留言评论。精彩留言会获得点赞!