基于全球检索的数据实时生成全球商业评级的全球联网系统的制作方法
本申请要求下述申请的优先权:(a)2015年10月15日提交的美国临时申请第62/242,075号和(b)2016年10月12日提交的美国专利申请第15/291,385号,二者的全部内容通过引用并入本文中。
技术领域
本公开内容总体上涉及下述全球联网系统,其用于实时收集来自不同时区的数据,并且使得即使在由于时区差异导致并非所有数据当前均可用的情况下,也能够按照商业信息透明度和可用性来生成世界范围内任何商业实体的全球商业评级(GBR,global business ranking)。具体地,该系统使得能够基于来自全世界多个源和/或国家的全球检索信息(例如数据)来实时生成GBR。
背景技术:
已知为给定国家的商业产生商业评级。一般地,这些商业评级无法解决全球范围的商业评级。此外,评级分数不包括基于来自不同时区中的一组全球国家的数据的组成部分,例如100或更多。由于时区不同以及在传输来自全世界各个国家的数据时的固有滞后性,所以当来自不同国家的数据由于这种时区差异而不完整或滞后时,通常会存在关于产生GBR的问题。因此,正寻求关于在例如美国、阿根廷和以色列运营的一个跨国公司的GBR的例如在日本的一方可能无法实时访问生成准确的实时和最新GBR所需的数据。技术问题在于下述事实:用户正试图实时访问基于从全世界收集的数据的GBR分数,这些数据被检索并存储在不同位置、不同时区并且以不同格式等,因而导致大量的时间延迟——直到收集并同步所有数据后才生成GBR分数。在当今的全球化世界以及对实时和即时访问信息的需求方面,期望用户等待数小时或数天以获取请求的信息已不再可行或可接受。
本公开内容提供了一种系统和方法,其不管数据是否完整都能基于一组全球国家中的活动来实时生成全球商业评级。
技术实现要素:
一种用于基于从至少多个国家检索的特定于国家的数据来实时生成全球商业评级的联网系统,该系统包括:多个国家数据收集系统,其中,特定于国家的数据是从多个国家源收集的;转换引擎,其接收所收集的数据并将其分类为选自由国家交易数据、国家财务数据和国家贬损信息构成的组中的至少之一;数据/属性储存库,其将国家交易数据、国家财务数据和/或国家贬损信息与来自全球数据库的数据、宏观分数数据和/或信号分数数据合并以形成合并数据,并且将该合并数据分类为选自由全球交易数据、全球财务数据和全球贬损信息构成的组中的至少之一;以及全球商业评级处理器,其在实时基础上检索全球交易数据、全球财务数据和/或全球贬损信息中的任何一个,并且为特定商业实体生成全球商业评级。
全球商业评级处理器包括混合模块,通过使用统计模型或商业知识来填补任何不足的信息或数据,即使在全球交易数据、全球财务数据和/或全球贬损信息中的任何一个不完整或全部都不完整的情况下,混合模块也产生全球商业评级。
优选地,全球商业评级被存储在全球商业评级储存库中。
转换引擎通过根据特定于国家的逻辑和/或规则来对所收集的数据进行转换、标准化和/或汇总来进一步处理所收集的数据。
国家数据收集系统包括对来自多个国家源的特定于国家的数据进行并行处理。
在不需要等待对所有特定于国家的数据的下载和/或处理的情况下,全球商业评级储存库向下游推送商业实体的全球商业评级和/或持续地向用户实时馈送商业实体的全球商业评级。
经由神经网络或其他人工智能技术将已经提供给用户的全球商业评级反馈至全球商业评级处理器,以改善经由全球商业评级处理器生成的全球商业评级。
附图说明
通过参照以下结合附图的说明将会理解本公开内容的其他和进一步的目的、优点和特征,在附图中,相同的附图标记表示相同的结构元素,并且:
图1是根据本公开内容的GBR系统的框图;
图2是图1中的GBR系统的宏观分数硬件的框图;
图3是图1中的GBR系统的信号分数硬件的框图;
图4是图1中的GBR系统的全球交易硬件的框图;
图5是图1中的GBR系统的全球财务硬件的框图;
图6是图1中的GBR系统的全球贬损信息硬件的框图;
图7是图1中的GBR主处理与评分系统的框图;
图8是图7中的GBR主评分模块的逻辑图;
图9是图4中的宏观分数硬件所使用的预宏观建模阶段的处理图;
图10和图11组合例示了图4中的宏观分数硬件所使用的宏观建模阶段的处理图;以及
图12是根据本公开内容的全球GBR系统的框图。
具体实施方式
参照图1和图12,本公开内容中的GBR系统100包括GBR主硬件系统700,其接收来自下述多个源的输入,即主机全球数据库110、宏观分数硬件200、信号分数硬件300、GBR全球交易硬件400、全球财务硬件500和全球贬损硬件600。GBR主硬件系统700处理接收到的输入以向GBR分数存储装置800提供GBR评级分数。
GBR全球交易硬件400、全球财务硬件500和全球贬损硬件600各自接收来自交易数据库组150和160的输入。交易数据库组150包括来自本地国家(诸如美国(US))的一个或更多个交易数据库的一个或更多个交易数据库。交易数据库组160包括全球国家集合中的一个或更多个交易数据库,例如英国(UK)的本地数据库162、巴西的本地数据库164以及全世界许多其他国家。
本公开内容提供了一种技术解决方案,其允许对全球数据的唯一收集以及基于全球收集的数据进行实时处理并生成GBR分数。参照图12可以最好地理解该技术解决方案。
图12描绘了GBR系统100的框图,其包括特定于各个国家的数据的集合,例如国家A数据162、国家B数据163、国家C数据165和国家Z数据164。对于每个国家A至国家Z,数据是从各种源收集的,例如,国家A数据162从至少源1A(交易)、源2A(财务)、源3A(贬损信息)至源nA(其他数据)并行地上传数据。类似地,国家B数据、国家C数据至国家Z数据从其各自的源并行检索其各自的源数据。此后,来自162、163、165至164的各个国家数据被并行处理,使得当从它们各自的源获取到数据时,将数据发送至转换引擎161,在转换引擎处根据存储在元数据储存库166中的规则和格式对数据进行转换、标准化、分类和/或汇总。特定于国家的逻辑/规则在步骤168中被建立并被存储在元数据储存库166中。
此后,一旦转换引擎161已经处理了从162、163、165至164接收到的各个国家数据,这些数据就被发送到GBR数据/属性储存库169,在GBR数据/属性储存库169处将这些数据与来自全球数据库110的数据、宏观分数200和信号分数300合并。数据/属性储存库169将合并的数据分类为全球交易数据400、全球财务数据500和全球贬损信息600。通过对储存库169中的数据进行预先分类,GBR处理器700可以在实时基础上检索这样的交易400、财务500或贬损信息600中的任何一个,条件是全球交易数据400、全球财务数据500和全球贬损信息600中的至少一个具有完整的信息,从而避免需要等待每个其他数据/属性储存库数据变得完整和最新。这对于用户依赖于将经由转换引擎161处理并被分配到独立且不同的数据/属性储存库的来自多个源和国家的数据(例如,全球交易数据400、全球财务数据500和全球贬损信息600)的情况尤其有用。GBR处理器700利用混合模块在持续馈送基础上从全球交易数据400、全球财务数据500和全球贬损信息600(即商业知识)中提取不完整的数据以满足用户的即期要求,由此利用统计资料来填补有缺陷信息并仍然产生准确的GBR分数,该GBR分数被存储在储存库800中。
由于创建以混合模块、并行处理和连续馈送为基础的系统,本公开内容使得GBR系统100能够在不需要等待对来自每个国家A至国家Z及其各自的数据源的所有数据的下载和处理的情况下,实时地向下游推送GBR分数181或检索用户所请求的数据183。此外,可以利用神经网络或其他人工智能技术经由推送到下游系统的信息181的递归反馈回路185来不断地改善由GBR处理器700生成的GBR分数。
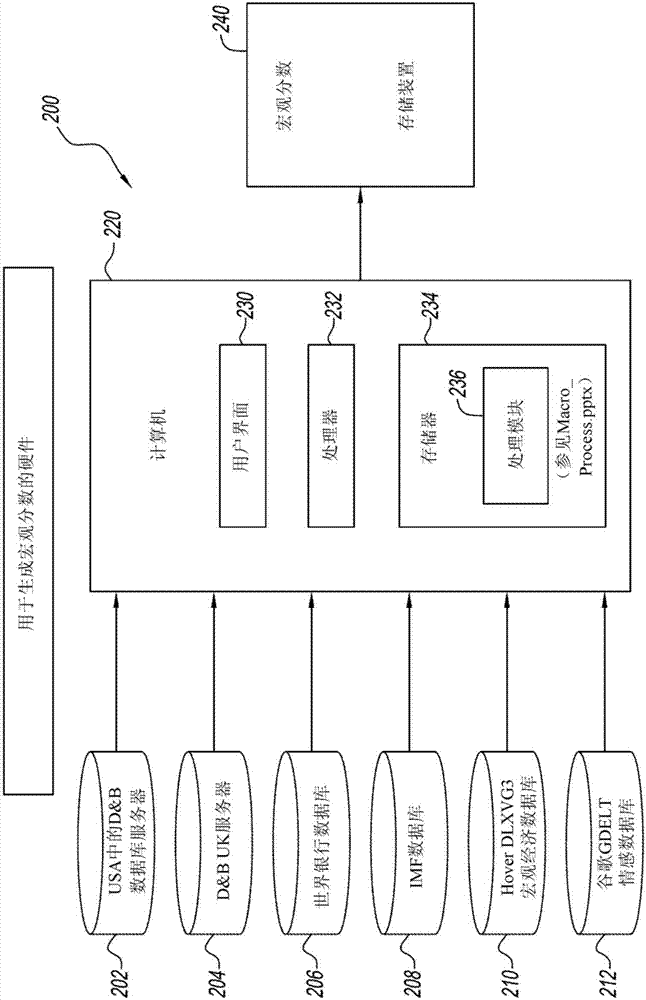
参照图2,宏观分数硬件200包括具有用户界面230、处理器232和存储器234的计算机220。存储器234中存储有处理模块236。计算机220接收来自USA数据库服务器202、UK服务器204、世界银行数据库206、IMF(国际货币基金组织)数据库208、宏观经济数据库210和谷歌GDELT(全球事件、语言和语调数据库)情感数据库212的输入。处理器220操作处理模块236来处理这些输入并提供存储在240中的宏观分数。
参照图3,信号分数硬件300包括计算机310、(一个或多个)全球数据库350、商业档案变更数据库352、匹配审计数据库354和跨境咨询数据库356。计算机310包括用户界面312、处理器314和存储器316。存储器316包括处理模块318,其处理从(一个或多个)全球数据库350、商业档案变更数据库352、匹配审计数据库354和跨境咨询数据库356获得的信息以进行处理以产生存储在330中的信号分数。
通过将全球数据库350和商业档案变更数据库352进行耦合(例如CEO变更),还获得了给定商业的变更频率。全球数据库350提供诸如CEO变更的信息,并且商业档案变更数据库352提供给定商业的信息,例如变更频率。匹配审计数据库354包含指示信号数据有多活跃(即,在商业活动的临期程度和频繁程度方面的活跃度)的信息(例如,诸如关于该商业的匹配和审计的次数以及信号活动覆盖的时间长度),并且信号数据通常涉及针对特定商业的商业咨询(例如负面媒体报道,CEO变更等)。匹配和审计的次数越多和/或信号的时段越长表明商业越活跃或越繁荣。跨境咨询数据库356对该商业进行跨境咨询。来自较高数量的不同国家的咨询和经历较长时段的咨询是较好的商业的指标。
处理模块318汇集所有上述信号数据项,即将数据信号(例如商业咨询、负面媒体报道以及CEO变更)放在一起。回归模型对这些数据应用不同的权重并将加权值相加成为单个信号分数。该信号分数仅基于可用的信号信息示出商业的风险水平。
参照图4,GBR全球交易硬件400包括计算机410,其包括用户界面420、处理器单元422、存储器430和交易存储装置440。计算机系统412包括向用户界面420提供输入的全球国家的本地计算机414和中央FTP(文件传输协议)服务器416。本地计算机414在其各自的国家中使用交易数据库150和160来向计算机410提供输入。
存储器430包括处理模块432,用于交易数据选择、转换和派生变量创建。然后,处理模块432的结果被存储在财务存储装置440中。
参照图5,GBR全球财务硬件500包括计算机510,其包括用户界面520、处理器单元522、存储器530和交易存储装置540。计算机系统512包括向用户界面520提供输入的全球国家的本地计算机514和中央FTP服务器516。本地计算机514在其各自的国家中使用交易数据库150和160向计算机510提供输入。
存储器530包括处理模块532,用于交易数据选择、转换和派生变量模块。然后,处理模块532的结果被存储在财务存储装置540中。
参照图6,GBR全球贬损硬件600包括计算机610,其包括用户界面620、处理器单元622、存储器530和贬损数据存储装置640。计算机系统612包括向用户界面620提供输入的全球国家的本地计算机614和中央FTP服务器616。本地计算机614在其各自的国家中使用交易数据库150和160来向计算机610提供输入。
存储器630包括处理模块632,用于交易数据选择、转换和派生变量创建。然后,处理模块632的结果被存储在贬损数据存储装置640中。
参照图7,GBR主处理与评分硬件系统700包括计算机702和计算机750。还参照图1,计算机702接收来自主机全球数据库110、宏观分数硬件200、信号分数硬件300、GBR全球交易信息400、GBR全球财务信息500和GBR全球贬损信息600的输入。计算机702包括用户界面704、处理器单元706、存储器708和主数据库存储装置740。计算机702和附加计算机750使该系统能够同时进行两个连续的步骤。计算机702中的GRB主处理模块710将所有宏观数据、信号数据、交易数据、财务数据和贬损数据(图2至图6)放在一起。附加计算机750中的GBR主评分模块758将GBR模型应用于从主数据库存储装置740取回的最终的大数据文件以生成GBR分数并将其存储在存储装置790中。
GBR主处理模块710被设置在存储器708内。处理器单元706使用GBR主处理模块710来处理来自主机全球数据库110、宏观分数硬件200、信号分数硬件300、GBR全球交易信息400、GBR全球财务信息500和GBR全球贬损信息600的输入,以将所有输入文件拉到一起并生成主数据集以供750使用。然后,处理器单元706将此结果存储在主数据库存储装置740中。
计算机750包括用户界面752、处理器单元754、存储器756和存储装置790。处理器单元754使用来自计算机702的输入来生成最终GBR分数以存储在存储装置790中并存储在GBR分数存储装置800(图1)中。
关于图2,当由处理器232执行时,处理模块236执行预建模阶段和建模阶段。预建模阶段创建了宏观调整因子,其确保从经济角度来看按照不好的定义对国家评级是有意义的。建模阶段中的数据准备步骤(1005至1050)包括与数据充足国家相对数据不充足国家对应的两条独立路径。1055使用这两种类型的国家的数据,并为所有国家生成宏观分数。
参照图9,当由处理器232运行以进行预建模阶段时,处理模块236执行多个步骤以实现等级调整的因变量。在步骤905中,在商业失败的时间序列和各种宏观经济变量之间执行相关/协整测试。在步骤910中,选择表示国家内的商业失败的三个最稳健的宏观经济变量。在步骤915中,使用主成分分析和回归分析的组合来创建等级调整因子。在步骤920中,将等级调整因子应用于国家层面的因变量以实现有经济意义的评级。在步骤925中,等级调整的变量已准备好用于建模阶段。
参照图10和图11,在由处理器232运行以进行建模阶段时,处理模块236执行多个步骤以实现用于并入GBR分数的宏观分数组成部分。首先参照图10,在步骤1005中,按国家收集GDP增长的5年历史数据。在步骤1010中,按国家创建GDP增长的5年历史GDP标准差。在步骤1015中,确定GDP增长的跨国平均标准差。在步骤1020中,基于国家GDP增长标准差与跨国平均标准差的比值来创建相对波动率预测指标。在步骤1025中,确定国家数据是否充足。如果是,则在步骤1030中考虑其他输入变量。其他输入变量非限制性地包括通货膨胀、经常账户、余额、汇率、进口补偿、失业率中的一个或更多个。
还参照图11,如果在步骤1025中为否,则在步骤1035中还要考虑不同的输入变量组。该输入变量组非限制性地包括互联网用户比例、政治稳定性和媒体报道中新闻事件的平均基调中的一个或更多个。
对于1030和1035中包括的每个变量,提取其过去10年的历史时间序列面板数据(1040)。对于1030和1035中的每一个都有对应的输出数据集。
1045检查所述两个输出数据集并标记那些缺失一个或更多个预测指标的国家。
如果国家被标记,那么其缺失的数据将用基于主权国家联盟、地理位置、类似的经济概况或外推法而估算的值来替代(1050)。
数据充足的国家和数据匮乏的国家在组合时涵盖了所有国家。
任何给定国家的宏观分数是从1到100的数值,例如,宏观分数为95的国家在商业环境和商业实体方面风险较低,而宏观分数为20的国家则表示整体商业风险高的国家。
参照图1和图7,处理器单元706操作GBR主处理模块710以从主机全球数据库110、宏观分数硬件200、信号分数硬件300、GBR全球交易硬件400、全球财务硬件500和全球贬损硬件600获得数据输入,用于存储在主数据库存储装置740中。
对于来自英国(UK)的客户(公司)的跨国投资组合的示例,这些输入包括:
1)关于主机全球数据库110(图1)的客户信息,
2)创建并提取的UK宏观经济分数(图2),
3)来自信号分数硬件300的信号分数(CEO变更、咨询等)
4-6)在图1的UK本地数据库(F001)中搜索财务信息、交易信息和贬损信息。
这6组信息通过GBR主处理模块的操作来取得并被存储在GBR数据库存储装置740中。
参照图7,处理器单元754操作GBR主评分模块758以使用上述6个输入中的一个或更多个来产生GBR分数以存储在GBR存储装置790中。
图8提供了根据本申请的关于GBR分数生成的逻辑图。
以下是说明为特定实体生成全球商业评级(GBR)的过程的示例,其中无论所关注的该特定实体的正式地址属国为何,GBR分数都保持一致。
例如,一家美国(US)公司拥有其供应商的跨国投资组合。其中一个供应商是名为ABC的英国(UK)公司。在与ABC开展业务之前,这家美国公司试图确定ABC的GBR分数,其通过下述步骤来计算。
从全球数据库110中检索ABC的企业统计特征(firmographic)数据,例如年龄(40年)、员工数(200名员工)、标准行业代码等。
通过200创建并检索特定于国家的宏观分值。提取的生成UK宏观分数所需的UK信息如下:
●来自202的国家不良率、年平均通货膨胀率和进口补偿率;来自204的政治稳定指数;来自206的失业率和因特网使用情况;将来自服务器202至212的数据耦合而得到的GDP增长和经常账户占GDP的百分比;来自Google GDELT情感数据库212的媒体事件的平均基调。
●图2中的处理模块236如下进行工作。从数据库202至212拉取包括UK在内的所有国家的GDP增长。基于按国家的GDP增长,生成GDP增长的标准差和GDP增长的跨国平均标准差。GDP增长的标准差是统计学上的波动率度量。UK的相对波动率预测指标是UK GDP增长标准差与所有国家GDP增长标准差的比。相对波动率预测指标示出一个国家的相对于全球平均水平的商业风险水平。一个国家的相对波动率预测指标大于1表示该国的商业风险高于全球平均水平。
●基于为上述数据项(包括相对波动率预测指标)分配权重的回归方程来生成UK宏观分数,并将权重值相加成该宏观分数。
宏观分数存储装置240存储该UK宏观分数。
与其他国家相比(如宏观分数为1250的巴西),UK国家整体的商业风险较小,因此宏观分数较高,为1285。这可以依照以上指定的参与UK宏观分数计算的信息项进行说明。
UK宏观分数对于巴西宏观分数的此差异有助于使得可以基于相同标准比较UK与巴西之间的GBR分数。最终的GBR分数有以下六个组成部分:
1.财务
2.交易
3.贬损
4.信号分数
5.宏观分数
6.企业统计特征
如果UK公司和巴西公司针对以上组成部分1、2、3和4中的数据项目相同,则在包括宏观分数和企业统计特征之前它们将具有相同的风险分数。
关于组成部分5,即宏观分数,由于UK的宏观分数高于巴西,所以该UK公司的GBR分数(1285)将高于巴西公司的分数(1250)。
进一步假设这两家公司具有相同的企业统计特征(诸如年龄、员工规模、SIC等)。GBR组成部分6(企业统计特征)用不同的公式来基于企业统计特征计算不同国家的风险。这两家公司即使具有相同的企业统计特征,也会由于计算公式/模型不同,因而将从组成部分6具有不同的风险分数。
也就是说,最终的GBR分数考虑了上述所有6个组成部分,包括宏观分数和企业统计特征分数。因此,所述UK和巴西两家公司将基于一致的度量基准获得两个不同的最终GBR分数,并且可以对该分数基于相同标准进行比较。
检索信号分数值300。
对于UK公司ABC,在耦合全球数据库350和商业档案变更数据库352之后获得了ABC的商业档案变更类型(例如,CEO变更)以及变更频率。匹配审计数据库354提供下述信息,其指示信号数据对于ABC而言有多活跃,诸如关于ABC的匹配和审计的数量以及信号活动覆盖的时间长度等信息。更高的匹配和审计次数和/或信号的更长时段表明ABC在商业中更加活跃和/或具有更多的商业关系。跨境咨询数据库356对该商业进行跨境咨询。较多的咨询对于此商业可能是好指示或坏指示,但如果在相当长的时段内不存在关于ABC的咨询则表明与ABC做生意的风险。
处理模块318将所有上述信号数据项汇集在一起。回归模型向其应用不同的权重并将加权值相加成为单个信号分数。
以下仅用于说明目的,因为在GBR过程中可以使用其他计算。关于信号数据的此示例也可以用于GBR的所有其他部分,例如根据人口统计特征、财务和交易信息等的分数。
在过去3个月中,ABC公司共接受了10次跨境咨询,这些咨询来自7个国家。在去年,ABC的CEO辞职并且存在关于ABC的3个负面媒体报道。
首先,基于证据权重(Weight of Evidence)表,将上述4个原始数据值中的每一个转换为预测指标值。根据模型样本,在建模创建过程中为所有预测指标创建证据权重表。以下是跨境咨询次数的预测指标的一个证据权重表。
1.将10次(咨询)转换为1.46(证据权重)
2.将7个(国家)转换为1.52(证据权重)
3.将CEO变更转换为-1.12(证据权重)
4.将3个(负面媒体报道)转换为-0.74(证据权重)
将以上证据权重值应用于GBR信号模型:
Log_odds=-0.4207
-0.7005*咨询(1.46)
-0.2125*国家(1.52)
-0.3281*CEO变更(-1.12)
-0.2788*负面媒体(-0.74)
=-1.1926
分数=1130-40/Ln(2)*Log_odds
=1061
公司ABC的信号分数为1061。
该信号分数的范围从1001至1500,其中1001为最大风险并且1500作为最小风险。该信号分数仅基于可用的信号信息来显示商业的风险水平。
假设ABC的信号分数为1439,这是一个相对好的分数,因为有很多匹配和审计以及可用于ABC的跨境咨询,并且没有诸如CEO变更等的商业档案变更。
从国家数据库组160以及交易数据库组150中的US交易数据库151和US商业数据库152检索GBR全球交易信息400。
交易信息使得需要商业实体如何偿还债务。对于作为一般的商业风险模型的GBR模型,使用了下述信息项:
1.过去12个月的交易数量
2.及时支付的付款
3.逾期30天内支付的付款
4.逾期31至60天的付款
5.逾期61至90天的付款
6.逾期91至120天的付款
7.逾期121至150天的付款
8.逾期151至180天的付款
9.逾期181天以上的付款
图4中的全球合作伙伴414通过文件传输协议(FTP)的方法将来自遍布全球的其本地计算机/服务器/数据库的交易数据提供给集中式FTP站点/服务器416。交易数据选择、转换、派生变量创建模块432将所有本地数据组合成一个最终交易数据库并将上述交易数据存储在存储装置440中。
数据库150和160除了其他的以外还包含针对US(即US交易数据库151和US商业数据库152)以及其他国家(即各个本地国家162至164的本地数据库)的下述交易信息。针对US和其他国家的此信息包括但不限于:
●在过去12个月内有报告的详细交易的月数
●Paydex分数
●过去12个月的总未付金额
●过去12个月中的付款经历的总#
●过去12个月中及时付款的次数
●过去12个月中满意的付款(0至30dpd)的次数
●过去12个月中30至60dpd的付款的次数
●过去12个月中60至90dpd的付款的次数
●过去12个月中90至120dpd的付款的次数
●过去12个月中120以上dpd的付款的次数
*dpd:逾期天数。
通过图4中的本地国家计算机414和中央FTP站点/服务器416,上述数据项被汇集在一起。
存储器432将所有货币转换为美元,并且基于原始数据项来创建下述模型预测指标,诸如满意的经历(0至30dpd)中及时支付(0dpd)所占的百分比以及30以上dpd经历中60以上dpd所占的百分比等的预测指标。
交易数据存储装置440存储预测指标,并且这些预测指标将由计算机702中的GBR主处理模块用于在GBR主评分模块计算机750中的GBR分数创建。计算机702和750允许两个连续的步骤。GBR主处理模块710将(来自图2至图6的)所有的宏观数据、信号数据、交易数据、财务数据和贬损数据放在一起。GBR主评分模块758将GBR模型应用于存储在主数据库存储装置740中的信息,从而生成GBR分数并将其存储在存储装置790中。
图5从国家数据库组160以及来自交易数据库组150的US交易数据库151和US商业数据库152检索GBR财务信息500。
数据库150和160除其他之外还包含针对US(数据库151和152)以及其他国家(数据库162至164)的下述财务信息:
●过去3年中最新的财务报表的日期
●最新的财务报表中的总资产
●最新的财务报表中的净值
●净收入
●现金以及现金等值金额
通过图5中的本地计算机514和服务器516,上述数据项被汇集在一起。
财务数据选择、转换、派生变量创建模块532将所有货币转换为美元,并且基于上述原始数据项来创建诸如资产回报率(ROA)和最近的财务报表的新近度等的预测指标。
财务数据存储装置540存储所述预测指标,并且这些预测指标将由GBR主处理计算机702使用以由GBR主评分计算机750创建GBR分数。
图6演示了如何从国家数据库组160以及来自交易数据库组150的US交易数据库151和US商业数据库152中检索GBR全球贬损信息600。
数据库150和160除其他之外还包含针对US(数据库151和152)和其他国家(数据库162至164)的下述贬损信息:
●过去7年的收款额(年数视市场而异)
●过去7年中由法院诉讼引起的金额(年数视市场而异)
●过去7年中董事决断的金额(年数视市场而异)
●过去7年中董事失败计数(年数视市场而异)
●自上次贬损事件以来的月数
通过图6中的本地计算机614和服务器616,上述数据项被汇集在一起。
贬损数据选择、转换、派生变量创建模块632将所有货币转换为美元,并生成标志/虚拟预测指标,诸如具有债务追收(1/0),具有董事失败(1/0)等。贬损数据存储装置640存储预测指标,并且那些预测指标稍后将由GBR主处理计算机702调用以用于GBR主评分计算机750中的GBR分数创建。
通过对关于UK公司ABC的图2至图6中的步骤的上述说明以及来自全球数据库110的ABC的企业统计特征信息,图7中的GBR主处理模块710匹配和/或合并这样的企业统计特征信息、来自存储装置240的宏观分数、来自存储装置330的信号分数、来自交易数据存储装置440的交易数据、来自财务数据存储装置540的全球财务数据以及来自公司层面的贬损数据存储装置640的全球贬损数据。换句话说,主处理模块710创建主数据文件,其中每个商业具有一个且仅一个记录。对于ABC的情况,主处理模块710将以上说明的企业统计特征数据字段(例如年龄、雇员规模、SIC等)、交易数据字段、财务数据字段和贬损预测指标数据字段及其信号分数和UK宏观分数并排组装成数据文件。
主数据库存储装置740通常以矩阵的格式将上述信息存储到大型数据库中,其中每行对应于公司并且每列对应于数据字段。在ABC的情况下,存储装置740是具有许多列预测指标值的单条记录数据文件。每个公司使用单条记录的汇总信息而不是使用ABC公司的多个交易记录,将节省生成最终GBR分数的计算机处理步骤和时间。
如图8所示,从存储装置740开始,在所有必要的信息准备好进行评分的情况下,图7中的主评分模块758通过图8中的下述步骤生成GBR分数。
首先,检查对于ABC而言交易或财务数据是否可用
1.如果不存在对于ABC可用的交易信息和财务信息,则检查企业统计特征或信号分数是否可用,
●如果对于ABC没有企业统计特征或信号分数,则应用宏观_模型(Macro_Model)、生成GBR分数并且将GBR分数保存在存储装置790中。
●如果ABC有企业统计特征或信号分数,则应用企业统计特征_信号_模块(firmographics_signal_module)生成GBR分数,并将GBR分数保存在存储装置790中。
2.如果对于ABC存在交易数据项或财务数据项,则检查其财务数据是否可用
●如果没有财务数据可用,则应用交易_贬损_企业统计特征_信号_宏观_模型(trade_derogatory_firmographics_signal_macro_model)来生成GBR分数,并将GBR分数保存在存储装置790中。
●如果存在财务数据,则检查交易数据是否可用
°如果交易数据不可用,则应用财务_贬损_企业统计特征_信号_宏观_模型(financial_derogatory_firmographics_signal_macro_model)来生成GBR分数,并将该分数保存在存储装置790中。
°如果交易数据可用,则应用财务_交易_贬损_企业统计特征_信号_宏观_模型(financial_trade_derogatory_firmographics_signal_macro_model),并将分数保存在存储装置790中。
假设在上述步骤之后,ABC被发现具有交易信息和财务信息并且没有任何贬损数据字段被填充。在交易数据字段中,所有交易都得到及时支付,并且拖欠债务数据字段全部填充0。在财务数据项中,ABC提交了其截至上一财政年度末的最新财务报表,且商业在资产回报方面表现良好。
使用财务_交易_贬损_企业统计特征_信号_宏观_模型(Financial_Trade_Derogatory_Firmographics_Signal_Macro_model)来生成GBR分数,并且发现GBR原始分数为1520。
GBR最终输出包括预测组成部分和描述组成部分。预测组成部分来源于GBR原始分数,其基于预定的截止点将原始分数分级为15个分段,其中“15”为风险最高。描述性组成部分表示数据深度或数据可用性,其中“A”最强并且“G”最弱。GBR利用数据深度度量提供对可用于公司的可靠性评估的预测性数据的可视性。数据深度组成部分用作置信系数,其提供了洞察用于评估商业的未来状态的预测性数据的级别。
基于GBR原始分数1520和交易与财务信息的数据可用性,GBR主评分模块758向ABC分配GBR最终输出“4A”。
关于UK的账户的分数4意味着无论数据的潜在深度如何,其在风险倾向方面与巴西相同。
最后,将分数“4A”保存在图1中的GBR分数存储装置800中。
以下详细说明图9至图11。
图9公开了如何创建国家调整因子来调整模型样本中的商业失败率信息。这是在创建GBR模型时如何克服数据的弱点的一个示例。
图10和图11说明了如何创建宏观模型的过程。
图2提供了如何产生宏观分数的过程,这已在上文中进行了说明。
对于图9,在GBR模型创建阶段期间,步骤905在来自服务器202和204以及数据库206、208、210和212的商业失败的时间序列与各种宏观经济时间序列变量之间运行相关性测试。
步骤915首先利用基于来自服务器202和204以及数据库206、208、210和212的所有宏观经济变量的主成分分析和回归分析的组合,来创建等级调整因子,以生成商业失败率的预测值。然后生成等级调整因子,即预测的商业失败率与观测到的商业失败率的比值。使用这种投射的商业失败而不是在可用数据中观测到的国家商业失败率的原因是为了消除数据覆盖偏差。不同国家对商业失败信息的收集情况差异很大。例如,巴西的观测到的失败率低于/优于UK,这是由于在巴西没有很好地收集失败信息。
步骤925存储投射的商业失败率以及等级调整因子以调整模型样本中的观测到的失败率。此调整后的商业失败率被用于创建GBR模型。
图10和图11中的宏观分数1060适于所有国家。该步骤对应于图1中的宏观分数200。图7中的GBR主处理与评分710结合了宏观分数以及信号信息、交易信息、财务信息、贬损信息。图9中的步骤925创建了等级调整的因变量。在步骤1060中,使用步骤925中的结果以及其他宏观信息(诸如GDP增长等)来生成宏观分数。如果国家在图10的步骤1025中宏观数据薄弱,主要在发展中国家之间,则其交易、财务、贬损和信号数据通常也较不充足,因为数据收集的信息结构不够高级。由于可用信息较少,因此对最终GBR分数的准确性产生不利影响,因为这些国家的预测指标有许多缺失值。
1055中的模型使用所需的变量并产生UK国家宏观分数(例如UK宏观分数=1539,低风险分数)。如上文通过详细数学公式和计算对信号分数所说明的,此UK宏观分数遵循与之相同的方法,除了宏观分数使用与信号分数不同的公式和计算。通常1000至1200是高风险分数并且1500+是低风险分数。
图3中的数据库350至356汇集所有可用的信号数据项并且处理模块318(即,回归方程)生成ABC的信号分数(例如ABC信号分数=1435,中等风险分数)。
图1示出了在UK本地数据库162中密集交易数据可用。在本地数据库162中,如果公司有3个以上的交易信息,则认为其有密集的交易。当既没有贬损(说明风险较低)也没有财务数据可用时,密集的交易对于分数的准确性是有利的,因为可以获得密集的数据。图1中的GBR全球交易信息400从UK本地数据库162提取ABC公司的交易信息。
图7中的GBR主处理模块710将ABC的企业统计特征、宏观分数、信号分数和交易信息汇集在一起。主数据库存储装置740对结果进行保存。
图7中的GBR主评分模块758例如根据图8中所阐述的逻辑流程图来产生ABC的GBR分数。
从“开始758”开始,系统确定交易信息或财务信息801是否可用。如果其中任何一个可用,则系统进行检查以查看财务信息是否可用803。如果没有财务信息可用,则系统移动到“记分卡:交易/贬损/企业统计特征/信号/宏观模型”805,并使用740中的所有可用数据,并为ABC创建GBR分数(GBR=“4C”),其中“4”表示低风险并且“C”表示数据可用性和分数置信度良好。分数“4C”被保存在GBR分数存储装置800中。
如果财务信息可用,则系统检查以确定交易信息是否可用807。如果没有交易信息可用,则系统移动到“记分卡:财务/贬损/企业统计特征/信号/宏观模型”809并使用740中的所有可用数据,并为ABC创建GBR分数(GBR=“4C”),其中”4“表示低风险并且“C”表示数据可用性和分数置信度良好。分数“4C”被保存在GBR分数存储装置800中。
如果财务和交易信息均可用,则系统移动到“记分卡:财务/交易/贬损/企业统计特征/信号/宏观模型”811并使用740中的所有可用数据,并为ABC创建GBR分数(GBR=“4C”),其中“4”表示低风险并且“C”表示数据可用性和分数置信度良好。分数“4C”被保存在GBR分数存储装置800中。
如果财务和交易信息均不可用801,则系统检查以确定是否有企业统计特征或信号数据可用813。如果有,则系统移动到“记分卡:企业统计特征/信号/模型”815并使用740中的所有可用数据,并为ABC创建GBR分数(GBR=“4C”),其中“4”表示低风险并且“C”表示数据可用性和分数置信度良好。分数“4C”被保存在GBR分数存储装置800中。
如果企业统计特征和信号数据均不可用,则系统移动到“记分卡:宏观”817并使用740中的所有可用数据,并为ABC创建GBR分数(GBR=“4C”),其中“4”表示低风险并且“C”表示数据可用性和分数置信度良好。分数“4C”被保存在GBR分数存储装置800中。
已经如此具体参考其优选形式描述了本公开内容,明显的是,在不脱离所附权利要求书限定的本公开内容的精神和范围的情况下可以进行各种改变和修改。
- 还没有人留言评论。精彩留言会获得点赞!