对于任何半结构化数据格式的高效存储器中DB查询处理的制作方法
本发明涉及管理对于半结构化数据的访问,并且更具体而言涉及在存储器中以与半结构化数据驻留在盘上的格式独立的镜像格式存储半结构化数据。
背景技术:
在关系数据库系统内,数据倾向于以高度结构化的方式被组织。具体地,数据通常存储在关系表格中,其中每行代表相关数据的集合(例如,关于特定的人的信息),并且每列对应于特定的属性(例如,姓名、地址、年龄等)。然而,使用关系表格存储和访问具有较少结构的数据不太直接。
能够存储并且高效地访问较少结构化的数据(称作“半结构化数据”)变得日益重要。诸如XML、JSON等之类的半结构化数据是支持无模式(schema-less)开发范式的主要数据模型,在无模式开发范式中用户不必指定模式以便存储数据和查询数据。
因为不提前需要模式以存储半结构化数据,用户具有在盘上存储半结构化数据的任何原始格式的自由。不幸的是,这种自由以性能为代价。由于半结构化数据的原始格式中的一些原始格式对于查询处理而言非常低效,所以对于半结构化数据的查询性能降低。例如,在盘上存储XML或者JSON的文本格式对于用户而言简单并且方便,但是由于文本解析的开销,所以对于回答针对文本存储的查询非常低效。
半结构化文档的示例在图1中例示。参考图1,所描绘的半结构化分层数据对象100是JSON文档。虽然JSON被用作半结构化数据的示例,但是本文描述的技术适用于任何形式的半结构化数据。在图1中,JSON对象可以由被大括号“{”和“}”围住的数据表示。因此,JSON对象可以是图1中描述的人和/或位置。
分层数据对象100可以包括与字段值相关联的字段名称。在图1的示例中,字段名称包括“person(人)”、“id”、“birthdate(生日)”、“friends(朋友)”、“location(位置)”、“city(城市)”和“zip(邮编)”。对于JSON对象,字段名称可以在名称-值对中在冒号之前。在图1的示例中,字段值包括‘123’、‘john’、‘1970-01-02’、‘456’、‘Mary’、‘1968-04-03’、‘789’、‘Henry’、‘1972-03-03’、‘Oakland’和‘94403’。对于JSON对象,字段值可以是在名称-值对中在冒号后的、除了字段名称或者分组符号之外的任何内容。字段值可以包括空值、布尔值、字符串值、数字值、浮点值、双精度值、日期值、时间戳值、带有时区的时间戳值、年月区间、日-秒区间、有符号二进制整数和/或任何其他数据类型。在分层数据对象100中,每个字段名称可以与一个或多个字段值相关联。例如,“person”可以与‘456’、‘Mary’和‘1968-04-03’相关联。
因为减少了在查询处理期间访问永久存储装置的需求,所以在易失性存储器中缓存半结构化数据产生一些查询性能提高。例如,如果在接收以对象100为目标的查询之前对象100的文本被加载到易失性存储器中,那么仅仅因为不需要附加的盘I/O,所以查询可以执行得更快。然而,因为预先加载到易失性存储器中的内容仍然反映半结构化数据的原始存储形式,由于在查询执行期间需要解析或者以其他方式处理半结构化数据,所以查询性能仍然受损。
解决由于半结构化数据的格式而导致的查询处理低效的一种方法是在将半结构化数据存储在数据库中之前将半结构化数据转换成另一种格式。例如,各种数据库系统供应商已经开发出专用二进制格式以用来在它们各自的数据库系统内存储半结构化数据。例如,Oracle、IBM和Microsoft SQL server已经要求用户将XML数据存储为XML类型,其在内部将XML转换成供应商特定的二进制格式,以用于针对该格式进行供应商特定的高效查询处理。类似地,MongoDB要求用户将JSON数据存储为BSON,以用于高效的JSON查询处理。
虽然将半结构化数据转换成新格式的策略对于将要被存储在数据库内并且完全由相应数据库系统控制的半结构化数据有效,但是对于存储在外部文件系统中并且作为外部表格挂载(mount)到数据库的数据,数据库特定的二进制存储格式策略行不通。具体地,在这些情况下,数据库系统不具有对存储在数据库外部的数据的控制。数据库系统不能主动地将数据转换成数据库特定的二进制存储格式,因为这将使得数据不能由需要访问数据的任何其他外部系统使用。
基于前述,显然期望具有如下技术:该技术加速由数据库系统针对其主要存储格式可能不能由数据库系统完全控制的半结构化数据的查询处理,尤其是当该主要存储格式对于查询处理不高效时。
在该部分中描述的方法是可以被追寻的方法,但是不一定是先前已经设想或者追寻的方法。因此,除非另外指示,否则不应当假设在该部分中描述的方法中的任何方法仅仅由于它们被包含在该部分中而被视为现有技术。
附图说明
在附图中:
图1描绘示例半结构化分层数据对象;
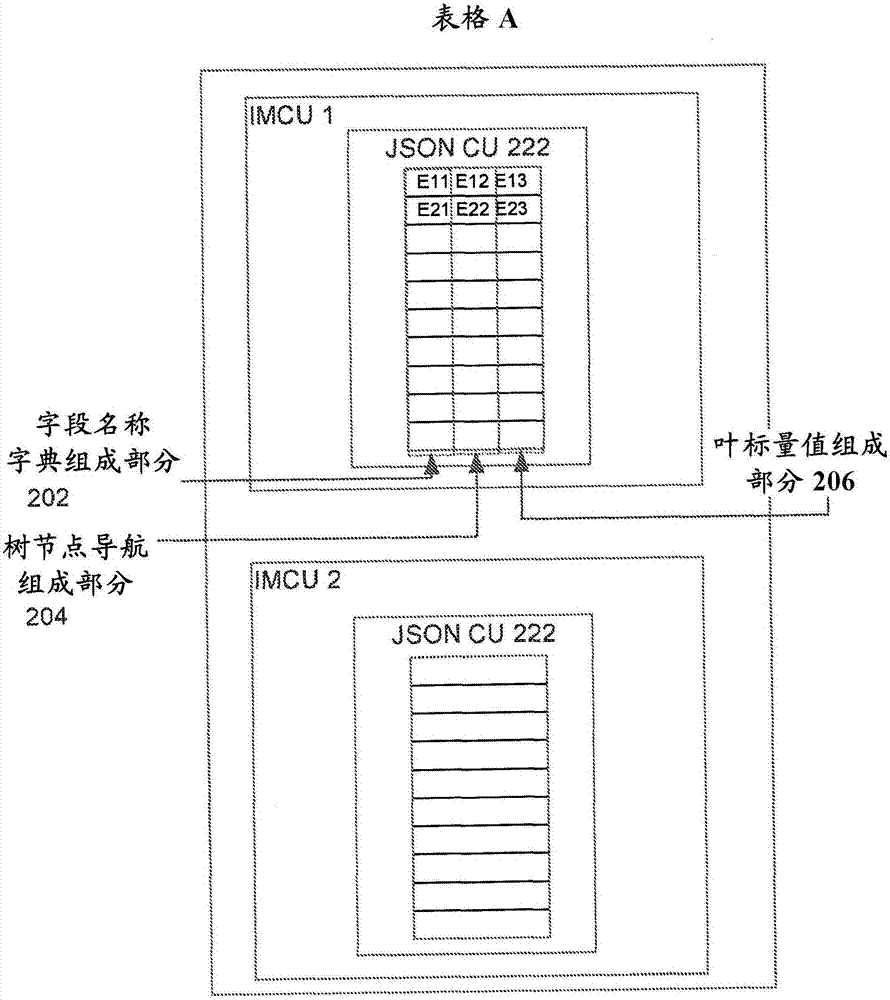
图2是根据一个实施例的、包括两个存储器中压缩单元(“IMCU”)的存储器中表格的框图,这两个IMCU中的每个IMCU存储包含半结构化文档集合的字段名称字典组成部分、树节点导航组成部分和叶标量值组成部分的单个JSON列单元;
图3是根据一个实施例的、以基于集合的镜像格式存储来自半结构化文档的数据的IMCU的框图;
图4A是示例分层对象的框图;
图4B是另一个示例分层对象的框图;
图5是根据一个实施例的、可以对于分层对象集合而生成的数据向导的框图;
图6是示例分层对象;
图7是根据一个实施例而生成的示例数据向导;
图8示出根据实施例的、可以基于数据向导而生成的视图定义;
图9是示出根据实施例的、用于响应于加载触发事件而创建MF数据的步骤的流程图;以及
图10是本文描述的技术可以利用其被执行的计算机系统的框图。
具体实施方式
在下面的描述中,为了解释的目的,阐述许多具体细节以便提供对本发明的透彻理解。然而,将明显的是可以在没有这些具体细节的情况下实践本发明。在其他实例中,以框图形式示出公知的结构和设备以便避免不必要地使本发明模糊。
总体概述
在本文中描述用于以一种格式(永久格式)在永久存储装置上并且以另一种格式(镜像格式)在易失性存储器中维护半结构化数据的技术。以永久格式存储的数据在本文中称作PF数据,而以存储器中(in-memory)格式存储的数据在本文中称作MF数据。PF数据可以存储在数据库系统自身内部或者外部。当被存储在数据库系统外部时,PF数据的格式可能在数据库系统的控制之外。经常地,永久格式是方便存储的格式,但是对于查询处理低效。例如,永久格式可以是文本格式,该文本格式每当查询需要访问半结构化对象内的单独的数据项时需要被解析。
永久格式数据的副本可以以永久格式被高速缓存在易失性存储器中。然而,虽然它在易失性存储器中的存在将通过避免磁盘访问操作而增加查询处理速度,但是被高速缓存的数据处于永久格式的事实提供与当数据以存储器中格式驻留在易失性存储器中时相比较差的查询处理性能。
因此,根据一个实施例,数据库系统将半结构化PF数据智能地加载到易失性存储器中,并且在这样做时,将半结构化PF数据转换成镜像格式(更加服从于存储器中查询处理的形式)。通过这样做,数据库系统提供对于半结构化数据演变(evolve)镜像格式的灵活性,而不必担心盘上的兼容性问题,因为镜像格式与永久格式解耦。此外,因为易失性存储器中的数据处于镜像格式,所以针对MF数据的处理查询允许避免盘I/O,同时提高查询本身的效率。例如,避免了针对PF数据的高速缓存副本运行查询可能必要的解析。
根据一个实施例,数据库系统利用存储器中数据库架构来保持PF数据与MF数据在事务上(transactionally)一致。这种存储器中数据库架构在由Jesse Kamp等人于2014年7月21日提交的美国申请号14/337,179(美国公开号2015-OO8883OA1),Mirroring,In Memory,Data From Disk To Improve Query Performance(“镜像申请”)中详细地描述,该美国申请的完整内容通过引用并入本文。镜像申请描述维护相同数据项的多个副本,其中一个副本被永久地维护在盘上,并且另一个副本被维护在易失性存储器中等等。维护在易失性存储器中的副本称作“存储器中副本”(IMC)。存储IMC的结构可以是存储器中压缩单元(IMCU)。
半结构化数据的示例
“半结构化数据”通常指分层数据对象的汇总(collection),其中分层结构跨汇总中的所有对象不一定是一致的。经常地,分层数据对象是由分层标记语言标记的数据对象。分层标记语言的示例是XML。另一个示例是JSON。
使用分层标记语言而被结构化的数据由节点构成。节点由标记节点的一组定界符界定,并且可以被加上名称标签,这些名称在本文中称作标签名称。通常,分层标记语言的语法指定标签名称被嵌入、并置或者以其他方式与划定节点界限的定界符在语法上相关联。
对于XML数据,节点由包括标签名称的起始标签和结束标签界定。例如,在下面的XML片段X中,
起始标签<ZIP CODE>和结束标签</ZIP CODE>界定具有名称ZIP CODE(邮政编码)的节点。
图4A是表示上面的XML片段X的节点树。参考图4A,它描绘分层数据对象401。非叶节点使用双线边界描绘,而叶节点使用单线边界描绘。在XML中,非叶节点对应于元素节点而叶节点对应于数据节点。节点树中的元素节点在本文中由节点的名称引用,节点的名称是由节点表示的元素的名称。为了表述方便,数据节点由数据节点表示的值引用。
对应标签之间的数据称作节点的内容。对于数据节点,内容可以是标量值(例如,整数、文本字符串、日期)。
诸如元素节点之类的非叶节点包含一个或多个其他节点。对于元素节点,内容可以是数据节点和/或一个或多个元素节点。
ZIPCODE(邮政编码)是包含子节点CODE(代码)、CITY(城市)和STATE(州)的元素节点,子节点CODE(代码)、CITY(城市)和STATE(州)也是元素节点。数据节点95125、SAN JOSE和CA分别是元素节点CODE(代码)、CITY(城市)和STATE(州)的数据节点。
由特定节点包含的节点在本文中称作该特定节点的后代节点。CODE(代码)、CITY(城市)和STATE(州)是ZIPCODE(邮政编码)的后代节点。95125是CODE(代码)和ZIPCODE(邮政编码)的后代节点,SAN JOSE是CITY(城市)和ZIPCODE(邮政编码)的后代节点,并且CA是STATE(州)和ZIPCODE(邮政编码)的后代节点。
非叶节点因此形成具有多个级别的节点的层次,非叶节点处于最高级别。每个级别处的节点链接到处于不同级别的一个或多个节点。处于最高级别以下的级别的任何给定节点是处于直接在给定节点上方的级别的父节点的子节点。具有相同父节点的节点是兄弟节点。父节点可以具有多个子节点。没有链接到它的父节点的节点是根节点。没有子节点的节点是叶节点。具有一个或多个后代节点的节点是非叶节点。
例如,在容器节点ZIP CODE(邮政编码)中,节点ZIP CODE(邮政编码)是处于最高级别的根节点。节点95125、SAN JOSE和CA是叶节点。
术语“分层数据对象”在本文中用来指一个或多个非叶节点的序列,每个非叶节点具有子节点。XML文档是分层数据对象的示例。另一个示例是JSON对象。
JSON
JSON是轻量级分层标记语言。JSON对象包括字段的汇总,这些字段中的每个字段是字段名称/值对。字段名称实际上是JSON对象中的节点的标签名称。字段的名称通过冒号与字段的值分隔。JSON值可以是:
对象,它是被包括在大括号“{}”中并且在大括号内由逗号分隔的字段的列表。
阵列,它是被包括在方括号“[]”中的逗号分隔的JSON节点和/或值的列表。
原子,它是字符串、数字、真、假或者空(null)。
下面的JSON分层数据对象J用来例示JSON。
分层数据对象J包含字段FIRSTNAME(名)、LASTNAME(姓)、BORN(出生)、CITY(城市)、STATE(州)和DATE(日期)。FIRSTNAME(名)和LASTNAME(姓)分别具有原子字符串值“JACK”和“SMITH”。BORN(出生)是包含成员字段CITY(城市)、STATE(州)和DATE(日期)的JSON对象,成员字段CITY(城市)、STATE(州)和DATE(日期)分别具有原子字符串值“SAN JOSE”、“CA”和“11/08/82”。
JSON对象中的每个字段是非叶节点并且非叶节点的名称是字段名称。每个非空阵列和非空对象是非叶节点,每个空阵列和空对象是叶节点。数据节点对应于原子值。
图4B将分层数据对象J描绘为包括如下所述的节点的分层数据对象410。参考图4B,存在三个根节点,它们是FIRSTNAME(名)、LASTNAME(姓)和BORN(出生)。FIRSTNAME(名)、LASTNAME(姓)和BORN(出生)中的每个是字段节点。BORN(出生)具有被标记为OBJECT NODE(对象节点)的后代对象节点。
OBJECT NODE(对象节点)在本文中称作包含节点,因为它表示可以包含一个或多个其他值的值。在OBJECT NODE(对象节点)的情况下,它表示JSON对象。从OBJECT NODE(对象节点)下来有三个后代字段节点,它们是CITY(城市)、STATE(州)和DATE(日期)。包含节点的另一个示例是表示JSON阵列的对象节点。
节点FIRSTNAME(名)、LASTNAME(姓)、CITY(城市)和STATE(州)分别具有表示原子字符串值“JACK”、“SMITH”、“SAN JOSE”和“CA”的子数据节点。节点DATE(日期)具有表示日期类型值“11/08/82”的后代数据节点。
路径
路径表达式是包括基于一个或多个节点的每个分层位置来识别分层数据对象中的一个或多个节点的“路径步骤”序列的表达式。“路径步骤”可以由“/”、“.”或者另一种定界符界定。每个路径步骤可以是在到分层数据对象内的节点的路径中识别节点的标签名称。XPath是指定用于路径表达式的路径语言的查询语言。另一种查询语言是由Oracle公司连同其他内容开发的SQL/JSON。
在SQL/JSON中,用于JSON的路径表达式的示例是“$.BORN.DATE”。步骤(step)“DATE(日期)”指定具有节点名称“DATE(日期)”的节点。步骤“BORN(出生)”指定节点“DATE(日期)”的父节点的节点名称。“$”指定路径表达式的上下文,其默认是路径表达式针对其被求值的分层数据对象。
路径表达式还可以指定节点应当满足的步骤的谓词或者标准。例如,下面的查询
$.BORN.DATE>TO_DATE(’1998-09-09’,‘YYYY-MM-DD’)指定节点“BORN.DATE”大于日期值‘1998-09-09’。
值路径是到表示值的节点的路径。JSON值包括JSON对象、JSON阵列和JSON原子值。因此,到对象、阵列或者数据节点的路径是值路径。分层数据对象J中的值路径包括“$.FIRSTNAME”、“$.BORN”和“$.BORN.DATE”。
在XML中,值路径是到数据节点的路径。因此,在XML片段X中,“/ZIPCODE/CODE”和“/ZIPCODE/CITY”是值路径,但是“/ZIPCODE”不是值路径。
半结构化数据的双重格式存储
半结构化数据的盘上存储通常是自包含的,其中结构和数据两者被一起存储在一个实例记录中。半结构化数据的自包含格式不必要地增加了数据的存储大小,因为所有实例之间的共同结构不可共享。另一方面,如果数据以非自包含格式被存储并且结构被分开存储,那么数据在不同数据库系统之间的导入/导出和分发变得困难,因为除了数据本身之外,运输操作还需要运输结构字典。
通过使用本文中描述的技术,当半结构化文档集合被加载到易失性存储器中时,文档从永久格式转换成独立于永久格式的镜像格式。因为镜像格式独立于永久格式,所以这两种格式可以被选择以实现不同的目标。例如,在永久格式中,半结构化文档集合可以处于自包含格式以提高导入/导出和分发操作的性能。另一方面,镜像格式可以是被定制以提高存储器中查询性能的格式。
在下文描述的镜像格式仅仅是示例性的,并且本文中描述的技术可以与其他镜像格式一起使用。为了例示的目的,基于行的镜像格式、基于集合的镜像格式以及主-明细(master-detail)镜像格式将各自在下文被详细描述。
基于行的镜像格式
如上所述,为了提高对于半结构化数据的查询处理,半结构化数据在数据被加载到易失性存储器中时被转换成镜像格式。然后针对数据的镜像格式版本处理查询。根据一个实施例,半结构化数据转换成的镜像格式是基于行的镜像格式。
将半结构化数据转换成基于行的镜像格式涉及将半结构化数据(例如,XML文档、JSON文档等)逻辑地划分成三个组成部分:字段id名称字段名称字典组成部分,树节点导航组成部分以及叶标量值组成部分。用于将半结构化文档划分成这样三个组成部分的一种技术在OSON申请中详细地描述,OSON申请的内容通过引用并入本文。
通常,为JSON文档创建的字段名称字典组成部分包括由JSON文档使用的所有字段的名称。为了使得字段名称字典组成部分更加紧凑,即使相同的字段在JSON文档本身内可能被重复任何次数,字段名称在字典中也仅出现一次。例如,字段名称“name”、“person”、“birthdate”在图1中示出的JSON文档内多次出现。每个不同的字段名称被编码有id。例如,“name”、“person”、“birthdate”可以分别被指派id“1”、“2”和“3”。
树节点导航组成部分表示对应JSON文档的树结构。在树节点导航组成部分内,字段名称由它们的id表示,而不是引用驻留在树结构本身中的每个节点处的字段名称。如上所述,由这些id中的每个id表示的字段名称可以基于字段名称字典组成部分中包含的信息而确定。
叶标量值组成部分存储与在字段名称字典组成部分中识别的字段相关联的值。例如,在图1中示出的JSON文档中,“name”字段的第一实例具有值“john”。因此,字段名称字典组成部分将字段“name”与某个id相关联。字段名称字典组成部分将指示与该id相关联的第一节点具有位于叶标量值组成部分中的特定位置的值。最后,叶标量值组成部分将在指定位置处具有值“john”。根据一个实施例,三个组成部分中的每个组成部分中包含的具体信息条目的细节在OSON申请中给出。
在半结构化数据被划分成组成部分之后,组成部分被加载到易失性存储器中。根据一个实施例,在基于行的镜像格式中,每个半结构化文档由存储器中表格中的行表示,并且对于任何给定的文档,组成部分中的每个组成部分被存储在该行的不同列中。因此,在存储器中表格内,对应于给定JSON文档的行包括(a)JSON文档的字段名称字典组成部分、(b)JSON文档的树导航组成部分、以及(c)JSON文档的叶标量值组成部分。在一个实施例中,所有三个组成部分在易失性存储器中被存储在单个列单元中。可替代地,每个组成部分可以具有它自己的列。因为对于给定JSON文档所需要的所有信息都在与该文档对应的行中,所以每行相对于该行表示的JSON文档是“自包含的”。
示例的IMCU中的基于行的镜像格式
图2示出来自表格A的数据项以基于行的镜像格式被存储在IMCU中的实施例。参考图2,字段名称字典组成部分、树节点导航组成部分和叶标量值组成部分被存储在单个列单元(CU 222)中。CU222存储单个JSON列,该单个JSON列的数据可以在逻辑上被看作被细分成在单个CU 222内的三个组成部分。该信息在IMC内被组织的具体方式可以依据实施方式而变化,并且本文中描述的技术不限制于在IMC内组织信息的任何特定方式。
CU 222包括三个逻辑组成部分:字段名称字典组成部分102、树节点导航组成部分102和叶标量值组成部分106。这三个组成部分分别存储上述的字段id名称字典信息、树节点导航信息和叶标量值信息。更具体地,如在OSON申请中解释的,字段名称字典组成部分102存储散列代码映射、字段名称映射和字段名称汇总。字段名称字典组成部分102中的这些映射在本文中被统称为对象字典映射。
如在OSON申请中详细描述的,节点树导航组成部分104包含分层节点树,每个分层节点树用于特定的分层数据对象。如上文所描述的,叶标量值组成部分106包含字段值汇总,每个汇总用于特定的分层数据对象。
列向量
根据可替代的实施例,在CU 222中示出的组成部分中的每个组成部分代替地按照以列为主的格式被存储在它自己的单独列中。即,不是在单个CU中连续地存储行的组成部分,而是每个组成部分的元素被连续地存储。用来存储给定列的相邻值的结构在本文中称作列单元(CU),并且被存储在任何给定CU中的值被统称为列向量。
再次参考图2中示出的实施例,存储器中表格A存储半结构化文档的镜像格式版本。根据一个实施例,在以永久格式驻留在盘上的半结构化数据以基于行的镜像格式被预先加载到易失性存储器中时,在易失性存储器中创建表格A。参考表格A,每行表示不同的分层数据对象。例如,每行可以存储与不同的JSON文档对应的信息。
在每行对应于不同的半结构化文档的实施例中,各个列向量元素表示对应的半结构化文档。换言之,由表格A的第n行表示的半结构化文档的信息将作为第n个元素被存储在CU 222中。例如,元素E11、E12和E13用于同一半结构化文档的字段名称字典组成部分、树节点导航组成部分和叶标量值组成部分。类似地,元素E21、E22和E23是另一个半结构化文档的字段名称字典组成部分、树节点导航组成部分和叶标量值组成部分。
如在镜像申请中描述的,可以使用各种压缩技术来压缩列向量。因为列内的值倾向于具有比行内的值更高的冗余度,并且压缩针对列向量执行而不是针对行执行,所以通常实现比对于以行为主的格式或者文本半结构化格式将可能实现的更高的压缩。
基于集合的镜像格式
在基于行的镜像格式中,给定列内的许多值可能是重复的。特别地,加载到IMCU中的半结构化文档可能大部分具有相同的字段名称。当是这种情况时,使用基于行的镜像格式的IMCU的字段名称字典组成部分中的元素可能是高度冗余的。即,E11可能是与E21几乎相同的信息,因为由表格A中的第一行代表的JSON文档所使用的字段名称可能与由表格A中的第二行代表的JSON文档所使用的字段名称相同。
基于集合的镜像格式是被设计为消除这种冗余的格式。具体地,基于集合的镜像格式通过提取出存储器中表格的所有行的所有冗余部分并且使用共享的字典来表示它们而创建。具体地,在基于集合的镜像格式中,文档集合之间的共同结构作为一个字典一起加载到存储器中以节省存储器中的空间消耗。
基于集合的镜像格式的共享字典
参考图3,它示出根据一个实施例的、半结构化数据以基于集合的镜像格式存储在其中的IMCU 300。IMCU 300包括存储两个共享字典304和308的报头302。字段名称共享字典304包括由IMCU 300表示的所有文档中的所有字段名称的列表,其中每个不同的字段名称仅被包括一次,而不管该字段名称多么频繁地出现在任何文档中并且不管多少文档具有拥有该字段名称的字段。因此,字段名称“name”将在共享字典304中将仅具有一个条目,即使IMCU 300对100个文档的数据进行镜像,并且这100个文档中的每个文档具有10至20个“name”实例。
在图3中示出的示例中,字段名称共享字典304将字段名称“name”、“address”、“birthdate”和“age”分别映射到标识符0、1、2和3。该示例仅仅是说明性的。在实践中,作为在IMCU 300中被镜像的半结构化文档中的任何半结构化文档中出现的所有字段名称的超集的字段名称的数量可以多得多。
如所示出的,共享字典304将每个字段名称映射到标识符,并且与半结构化文档对应的IMCU行使用标识符代替字段名称。例如,列单元306中的第一行具有标识符0、1和3以指示与该行对应的半结构化文档具有字段名称“name”、“address”和“age”。类似地,列单元306中的第二行具有标识符0、1、2以指示与第二行对应的半结构化文档具有字段名称“name”、“address”和“birthdate”。
根据一个实施例,包含在共享字典304中的字段名称到标识符的映射是隐式的。具体地,每个字段名称出现在共享字典304内的特定位置。该位置可以被表示为距共享字典304的开始的偏移量,可以被用作对应字段名称映射到的标识符。例如,如果字段名称“name”处于相对于共享字典304的开始的偏移量10184处,那么在列单元305的行内,字段名称“name”可以由10184表示。
值共享字典308包括在IMCU 300中被镜像的每个半结构化文档的所有叶节点值的列表。正如字段名称共享字典304列出字段名称仅一次而不管字段名称的出现次数,值共享字典308列出叶节点值仅一次,而不管叶节点值的出现次数。例如,值“john”可能在IMCU 300中被镜像的任何数量的文档中出现任何次数,但是在值共享字典308中将仅出现一次。在图3中示出的实施例中,值共享字典308包括分别映射到标识符4和5的叶节点值“fred”和“john”。
同样与字段名称类似地,叶节点值到标识符的映射可以是隐式的。例如,在列单元306内,每个叶节点值可以由距值共享字典308的开始的偏移量表示,其中偏移量指示该叶节点值在值共享字典308内的位置。
因此,与基于行的镜像格式类似地,基于集合的镜像格式将半结构化文档(例如,XML文档、JSON文档等)在逻辑上分解成3个组成部分:字段id名称字段名称字典组成部分、树节点导航组成部分、叶标量值组成部分。然而,不像基于行的镜像格式那样,在基于集合的镜像格式中,被加载到IMCU 300中的所有半结构化文档的字段名称字段名称字典组成部分和叶标量值组成部分被组合成共享字典304和308并且被加载到存储器中。仍然在每个文档一行的基础上维护的树导航组成部分被存储在列单元306中。如上所述,在一个实施例中,在列单元306内,字段名称和叶标量值两者都被表示为到共享字典304中的偏移量。
基于集合的镜像格式变体
如上面说明的,基于集合的镜像格式通过生成字段名称和/或字段值信息的集合级别的整合而消除重复的字段名称和/或字段值。这些冗余的消除减少数据存储需求并且降低输入/输出成本。例如,集合级别的压缩可以引发多个分层数据对象的快速扫描,并且所得到的空间节省可以使得适合于单个指令、多个数据(SIMD)操作的存储器中表示成为可能。
在IMCU 300中被镜像的分层数据对象集合中的每个分层数据对象可以具有它自己的分层节点树(被存储在列单元306中)。然而,分层数据对象集合可以共享共同的散列代码映射、共同的字段名称映射和/或共同的字段名称汇总。例如,共同的散列代码映射可以通过整合分层数据对象集合中的每个分层数据对象的各自散列代码映射而获得,由此实现集合级别的散列代码的压缩。附加地或者可替代地,分层数据对象集合可以共享共同的字段值汇总。
然而,在实施例中,分层数据对象集合还可以共享共同的分层节点树。在这种实施例中,分层数据对象集合中的每个分层数据对象可以被指派实例标识符,诸如序数。分层数据对象集合中的每个分层数据对象的各自的分层节点树可以被合并成超级分层节点树。超级分层节点树中的每个节点可以存储压缩后的位图。特定节点的压缩后的位图可以存储共享该特定节点的每个分层数据对象的各自的实例标识符。
超级分层节点树中的叶节点可以包括压缩后的位图的阵列。阵列中的压缩后的位图中的每一个可以对应于不同的字段值标识符并且可以存储共享与不同字段值标识符对应的特定字段值的每个分层数据对象的各自的实例标识符。因此,可以对于分层数据对象集合中的每个分层数据对象并发地执行分层数据对象集合的导航。
对于在线事务处理(OLTP)应用,将已编码的分层数据对象存储到BLOB字段中可以提供最佳性能,并且维护基于集合的表示可能在计算上是昂贵的。因此,原始存储格式可以是单个已编码的分层数据对象。可以对于分层数据对象的镜像格式版本保留集合级别的编码。
索引共享字典
根据一个实施例,可以构建索引字典304的结构的存储器中位图,使得当针对压缩单元300处理谓词操作符(诸如JSON_EXISTS(jcol,‘$.a.b’)或者JSON_VALUE(jcol,‘$a.c?(d==4)’))时,索引结构的存储器中位图可以被用作过滤器以识别压缩单元300内的什么文档满足谓词。
根据一个实施例,对结构进行索引的存储器中位图包括存储在相应IMCU中的所有文档的不同路径的集合。因为IMCU中的每个文档由IMCU序数槽号(ordinal slot number)识别,因此,对于每个不同的路径,可以构造指示哪个文档包含该路径的序数槽号的位图,使得JSON_EXISTS(jcol,‘$.a.b’)可以通过查找用于路径‘$.a.b’的位图而被高效地处理。此外,对于其叶子是标量值的每个不同路径,这些标量值可以按照与在IMCU中对普通关系标量列进行编码相同的方式进行列编码。JSON_EXISTS(jcol,‘$a.c?(d==4)’))可以通过对于路径‘$.a.c.d’针对值4执行标量数值的列扫描而被高效地处理。
当在基于集合的镜像格式中时,用于后置过滤的逐实例导航完全可行。即,当以基于集合的镜像格式表示时,存储器中半结构化数据由实例级别和集合级别的查询操作两者高效地访问。
主-明细镜像格式
主-明细镜像格式通过将半结构化文档的内容“撕碎”成仅在易失性存储器中具体化(materialize)的关系表格而创建。然而,在半结构化文档的内容可以被撕碎(提取并且指派给列)之前,必须确定将要使用所提取的项目填充的关系表格的结构。对于结构化数据,确定包含表格的结构相对直接。具体地,通常在模式中指定结构,并且模式中的每个字段映射到表格的相应列。然而,对于半结构化数据,文档的结构较不统一。
根据一个实施例,当半结构化数据将要被撕碎到存储器中表格中时,数据库系统首先生成用于半结构化数据的“数据向导”。可以使用各种技术生成用于半结构化数据的数据向导。用于生成用于半结构化数据的数据向导的一些技术在于2015年4月29日提交的美国专利申请号14/699,685(“数据向导申请”)中详细地描述,该美国专利申请的完整内容通过引用并入本文。
一旦已经针对将要预先加载到易失性存储器中的半结构化文档的集合生成了数据向导,则存储器中关系视图基于数据向导被创建,并且然后使用来自半结构化文档的数据被填充。根据一个实施例,存储器中关系视图按照以列为主的格式存储在IMCU内。然后在查询处理期间以在镜像申请中描述的方式来访问IMCU。
生成用于半结构化文档集合的数据向导
如上面说明的,当主-明细格式是将要用来将半结构化文档的特定汇总预先加载到易失性存储器中的镜像格式时,必须首先生成用于半结构化文档的汇总的数据向导。可以转换成主-明细格式的分层数据对象的示例包括但不限于(a)符合XML(可扩展标记语言)的文档、以及(b)符合JSON(JavaScript对象表示法)的数据对象。可以在分层数据对象被添加到汇总时创建和/或更新数据向导。
数据向导实际上定义汇总中的分层数据对象的模式。然而,根据在本文中描述的方法,分层数据对象的汇总可以被认为是无模式的,因为分层数据对象不必符合模式以被添加到汇总中。此外,与要求分层数据对象在被添加到汇总之前符合模式的基于模式的方法不同,模式响应于将分层数据对象添加到汇总而生成。
由于模式的可用性,可以使用RDBMS的强大查询能力来查询分层数据对象的存储器中副本。根据本发明的实施例,使用数据向导生成分层数据对象的汇总的存储器中关系视图。
例示性数据向导
图5表示根据本发明的实施例的例示性数据向导。数据向导描述诸如JSON分层数据对象之类的分层数据对象的汇总的结构。数据向导还可以包括关于结构的统计数据,诸如在汇总内的特定值路径处发现的最大值。如将更详细解释的,当分层数据对象被添加到分层数据对象的汇总时,更新数据向导。根据实施例,数据向导包括数据向导条目,每个数据向导条目包含在分层数据对象的汇总中发现的值路径,并且包含描述在值路径处发现的值的数据特性或性质的数据;描述一个或多个数据特性的这种数据在本文中称作值描述符。
参考图5,它描绘数据向导501。如在图5中所描绘的,数据向导501反映在将分层数据对象J和分层数据对象K作为第一分层数据对象添加到分层数据对象的汇总之后,分层数据对象汇总的结构。
根据实施例,数据向导501是以行和列的形式的具有条目的表格,每行定义在分层数据对象的汇总中发现的值路径。数据向导501的列包括PID、PATH(路径)、DATATYPE(数据类型)、MIN(最小值)和MAX(最大值)。
对于数据向导501中的给定行,列PATH(路径)包含表示在分层数据对象的汇总中发现的值路径的路径表达式。PID保持被指派给特定值路径的路径标识符。数据向导501中的其他列保持一起构成在特定值路径处发现的值的值描述符的值。诸如保持描述数据特性的值的这些列之类的字段在本文中称作值描述符属性。
数据向导501中的路径值属性包括DATATYPE(数据类型)、MAX(最大值)和MIN(最小值)。DATATYPE(数据类型)包含数据类型标识符,数据类型标识符识别在分层数据对象的汇总内的值路径处发现的值的数据类型。列MAX(最大值)和MIN(最小值)随后描述。
参考图5,数据向导501中的行1在列PID中保持路径标识符1。数据向导501中的行在本文中由被保持在该行的PID列中的路径标识符引用。行1在列PATH(路径)中包括路径表达式FIRSTNAME(名)并且在列DATATYPE(数据类型)中包括值STRING(字符串),由此指定在该值路径处发现的值的数据类型为STRING(字符串)数据类型。注意,上下文步骤“$”不在路径表达式中,但是可以看作被隐式地指定为路径表达式中的第一步骤。行3在列PATH(路径)中包括路径表达式BORN(出生)并且在列DATATYPE(数据类型)中包括值{},由此指定在该值路径处发现的值的数据类型属于JSON对象数据类型。行6在列PATH(路径)中包括路径表达式BORN.DATE并且在列DATATYPE(数据类型)中包括值DATE(日期),由此指定在该值路径处发现的值的数据类型属于JSON日期数据类型。
列MIN(最小值)和MAX(最大值)保持例示可以存储在数据向导内的值描述符属性的统计数据。对于给定行,列MIN(最小值)包含关于在分层数据对象的各自汇总的各自值路径处发现的值的特定性质的最小值。在数据向导501中,特定性质取决于在列DATATYPE(数据类型)中指定的数据类型。例如,在行1中在列MIN(最小值)中,值4代表任何字符串值的最小长度。在行6中,列MIN(最小值)反映值路径处的最早日期值,在该情况下是11/08/82。
类似地对于列MAX(最大值),列MAX(最大值)包含关于在汇总内的各自值路径处发现的值的特定性质的最大值。在数据向导501中,特定性质取决于数据类型。例如,在行1中在列MAX(最大值)中,值7代表值路径FIRSTNAME(名)处的任何字符串值的最大长度。在行6中,列MAX(最大值)反映值路径处的最晚日期值,在该情况下是09/10/95。
数据向导可以用来描述分层数据对象(诸如存储在数据库表格中的分层数据对象)的汇总的许多形式。根据实施例,分层数据对象的汇总包括存储在列数据类型为XML或者JSON的列中的分层数据对象。
视图的自动生成
如上所述,一旦已经对于半结构化文档的给定填充生成了数据向导,则数据向导可以用来将半结构化文档转换成主-明细存储器格式。具体地,主-明细存储器中格式涉及基于数据向导撕碎来自半结构化文档的数据以及基于数据来填充存储器中视图。
在没有数据向导的情况下,定义这种视图可能需要手动写出具有复杂路径表达式和关系构造的DDL语句以指定在分层数据对象中什么值将在关系视图中存在,这是可能容易出错的手动任务。然而,根据一个实施例,给定半结构化文档集合的数据向导中的信息被用来自动地生成分层数据对象的汇总的存储器中视图,由此避免了需要手动写出复杂的DDL语句。
根据本发明的实施例,提供自动地生成可以被提交到DBMS以生成半结构化文档集合的存储器中视图的DDL语句的实用程序。实用程序的变元可以被用来指定视图的名称以及哪些值路径将在关系视图中存在。实用程序在本文中称作JSON_RelationViewGenerator,并且在数据向导申请中被详细描述。
为了例示关系视图的自动生成,例示性JSON对象和数据向导在图6和图7中提供。图6描绘对象V。对象V包括阵列LineItems。
图7描绘数据向导701。图8描绘可以使用JSON_RelationViewGenerator生成的关系视图。
参考图7,数据向导701是用于表格jtab中的列jcol的数据向导(参见图7中的DDL语句)。在图7中描绘的值路径值从对象V中生成。数据向导701还可以包括没有在图7中描绘的值描述符属性。
关系视图在图8中由可以用来定义视图的DDL语句表示。这种DDL语句由JSON_RelationViewGenerator生成。
参考图8,视图SCALAR-VIEW(标量视图)是没有嵌入阵列结构内的标量值的视图。根据实施例,JSON_RelationViewGenerator采取若干变元(argument),这些变元包括表示视图名称“scalar-view”的第一变元(“视图名称变元”),以及表示“*”、指定对于没有嵌套在阵列内的标量值返回所有字段的第二变元(“路径id变元”)。
JSON_RelationViewGenerator可以采取一个或多个附加变元来识别存储针对其生成视图的汇总的表格和JSON列,以及识别数据向导。
JSON_RelationViewGenerator被配置为生成视图,该视图具有拥有与JSON分层数据对象中的相应字段相同的名称的列名称。以这种方式生成视图通过JSON_TABLE表格函数的使用完成,JSON_TABLE表格函数返回来自JSON分层数据对象的值作为关系列值。JSON_TABLE函数的实施例在数据库,SQL Language Reference(SQL语言参考),12c发布1(12.1),E41329-12,145-165页中描述,其内容通过引用并入本文。
JSON_TABLE表格函数声明视图包括用于指定要返回的列的列子句的变元,以及用于每个列的列名称、列数据类型和解析为要返回的JSON值的路径表达式。例如,在视图SCALAR-VIEW(标量视图)中,列子句变元Id varchar(40)path‘$._id’指定列名称id、数据类型varchar(40)和路径表达式‘$._id’;列子句变元StoreNo number path‘$.StoreTransaction.StoreNo’指定列名称StoreNo、数据类型number(数字)和路径表达式‘$.StoreTransaction.StoreNo’。
当JSON_RelationViewGenerator被调用时,实用程序检查数据向导以确定哪些行表示没有嵌套在阵列内的标量值的字段。JSON_RelationViewGenerator使用数据向导中的信息来生成定义关系视图的DDL语句。例如,JSON_RelationViewGenerator使用列PATH(路径)中的值路径和列DATATYPE(数据类型)中的数据类型来确定如何定义视图SCALAR-VIEW(标量视图)的列子句中的列。
视图SELECT-SCALAR-VIEW(选择标量视图)投射由路径id变元指定的具体值路径的列,变元值为‘1,3’。这个值列出识别数据向导1001中的值路径的行的路径标识符。因此,视图SELECT-SCALAR-VIEW(选择标量视图)包括用于值路径‘$._id’和‘$.StoreTransaction.StoreNo’的列。
类似地,视图ARRAY-VIEW(阵列视图)投射由路径id变元指定的值路径的列。视图ARRAY-VIEW(阵列视图)投射由路径id变元指定的具体值路径的列,变元值为‘1,9-11’。这个值列出识别数据向导1001中的值路径的行的路径标识符。这些值路径之间是用于阵列的元素的字段的值路径。为了投射阵列元素,ARRAY-VIEW(阵列视图)包括两个JSON_TABLE表格函数之间的联结(join)。JSON_TABLE函数J返回三个列Code、Amount和Cancelledamount。
视图的存储器中具体化
如上面说明的,数据向导可以对于半结构化文档的汇总被自动地生成,并且视图定义可以基于数据向导被自动地生成。根据一个实施例,然后使用这种自动生成的视图定义来仅在易失性存储器内具体化半结构化数据的视图。这种存储器中视图以主-明细镜像格式呈现半结构化文档。
根据一个实施例,对于半结构化文档的给定汇总,所有三个步骤(自动生成数据向导,自动生成视图定义,以及在易失性存储器内自动具体化视图)在半结构化文档要被预先加载到易失性存储器中时执行。在可替代的实施例中,数据向导可以在预先加载半结构化数据的时间之前生成并且不断地维持最新。因此,在预先加载时,仅视图生成和存储器中视图具体化发生。在另一种可替代的实施例中,数据向导生成和视图定义生成两者都在将要预先加载半结构化数据之前发生。因此,在预先加载时,仅执行存储器中视图具体化。
针对半结构化文档而创建的存储器中视图可以以多种方式被存储在易失性存储器中。例如,视图可以简单地按照与这种视图如果在盘上被具体化则将具有的相同格式被存储在易失性存储器中。典型地,这种视图的数据将处于以行为主的格式。另一方面,存储器中视图可以按照以列为主的格式存储在IMCU内。以这种格式,对于每列,列的值连续地存储在列单元中。此外,各种压缩技术可以应用于每个列以减少由每个列单元消耗的易失性存储器的量。
存储器中文本表示
除了以镜像格式在易失性存储器中存储半结构化数据之外,数据库服务器还可以在易失性存储器中存储半结构化文档的文本版本。半结构化文档的存储器中文本版本可以在各种情况下被访问。例如,镜像格式数据可能被压缩。当被压缩时,镜像格式数据可以被视为只读的以避免必须对于每个数据操纵语言(DML)操作来解压缩、改变和重新压缩镜像格式数据。因为镜像格式数据被视为只读的,所以数据可以响应于DML操作而被标记为无效(而不是被改变)。如果用于文档的镜像格式数据已经无效并且改变还没有被日志记录,那么使用用于该文档的镜像格式数据来回答查询是不可能的。因此,可以访问存储器中文本版本,而不是引发访问文档的盘上版本所需的盘I/O。
作为另一个示例,用于文档的镜像格式信息可以被用来确定文档是否满足查询,但是由查询返回的值可以从文档的存储器中文本版本中提取。然而,除了镜像格式信息之外还维护文本存储器中版本消耗更多的存储器资源,并且从存储器中文本版本中提取数据通常涉及解析操作。
预先加载镜像数据
在MF数据可以用来满足查询之前,PF数据必须被加载到易失性存储器中并且被转换成镜像格式。永久地存储分层数据对象的永久格式可以是基于文本的或者基于压缩的,诸如字典编码的分层数据对象。因为MF数据处于不同于PF数据的格式,所以通过(a)从永久存储装置中读取PF数据以及(b)将这样获得的PF数据转换成镜像格式来初始地填充易失性存储器。
关于何时创建MF数据的决策可以基于各种因素。例如,如果在系统启动时充足的时间和存储器可用,则已经选择用于镜像的所有PF数据可以在启动时被预先加载到易失性存储器中。因此,在一个实施例中,半结构化数据在数据库系统启动时被预先加载到易失性存储器中。预先加载可以例如由后台过程在任何数据库操作针对包含将由MF数据镜像的数据项目的存储器启用的数据结构执行之前执行。
另一方面,为了减少启动时间,已经选择用于进行镜像的PF数据的一些或者全部可以根据需要被加载。即,即使已经选择半结构化文档集合用于镜像,文档也都没有实际地被镜像,直到数据库命令实际地尝试访问文档中的一个文档为止。响应于尝试访问文档中的一个文档,可以预先加载集合中的所有文档。
如上面说明的,加载MF数据涉及从永久存储装置中读取相应PF数据并且然后将该PF数据转换成镜像格式。触发加载/转换操作的事件在本文中称作“加载触发事件”。如上所述,加载触发事件可以包括但不限于系统启动以及访问相应PF数据的请求。
在一个实施例中,用户可以设置配置选项以指示预先加载哪些MF数据,以及按需加载哪些MF数据。在可替代的实施例中,数据库服务器自动地确定预先加载MF数据的哪些部分以及按需加载哪些部分。通常,数据项目使用得越频繁,数据库服务器将越可能将该数据项目自动地加载到MF数据中,使得甚至需要该数据项目的第一个数据库操作也具有从MF数据中获得数据的选项。
重要地,从其中创建MF数据的PF数据可以按照多种格式被永久地存储并且可以来自多个源。即,可以存在PF数据的多个源,这些源中的每个源可以采用不同的永久格式。例如,PF数据可以按照JSON对象的形式被存储在HADOOP系统中。PF数据可以通过外部表格检索,如在由Daniel McClary等人于2015年4月14日提交的美国申请号14/685,840,Accessing an External Table in Parallel to Execute A Query中描述的,该美国申请的全部内容通过引用并入本文。检索的数据被转换成镜像格式。
IMCU方法的重要优点在于分层对象可以以任何格式永久地存储在数据库中(或者数据库外部)。分层数据对象不必在添加到数据库时被转换成不同的格式。分层数据对象可以以文本形式永久地存储是期望的。分层数据对象在被预先加载到易失性存储器中时被转换成镜像格式。
MF数据可以一次创建一个IMCU。在多实例环境中,可以使用持久存储的元数据来确定哪些MF数据被预先加载到数据库服务器实例中的每个数据库服务器实例中。这种元数据可以包括例如数据到IMCU的映射以及IMCU到实例的映射。
预先加载处理
参考图9,在步骤900,加载触发事件在数据库系统内发生。为了说明的目的,将假设预先加载操作中涉及的PF数据是JSON文档的集合,并且加载触发事件是由数据库系统接收到以集合中的一个或多个JSON文档为目标的查询。
在步骤902,数据库系统确定要将JSON文档集合转换成的镜像格式。数据库系统可以基于各种因素自动地选择格式,这些因素诸如可用的存储器的量、跨对象集合的字段名称和叶标量值共同性等。可替代地,数据库系统可以简单地读取由用户先前指定的格式偏好。这种偏好可以例如在逐数据库对象的基础上指定。例如,用户可以指定表格X将以基于行的存储器中格式被镜像,而表格Y将以基于集合的存储器中格式被镜像。
响应于确定用于JSON文档集合的镜像格式将是基于行的镜像格式,针对JSON文档生成组成部分(步骤904),并且所有组成部分在每文档一行的基础上被存储在IMCU内的单个列单元中(步骤906)。
另一方面,如果数据库系统确定用于JSON文档集合的镜像格式将是基于集合的镜像格式,那么与步骤904类似,在步骤908,来自JSON文档的数据被划分成组成部分。然而,不是在列单元中存储每个组成部分,而是对于字段名称创建共享字典(步骤910)以及对于值创建共享字典(步骤912)。树节点信息被存储在列单元914中。在该列单元内,字段名称可以由它们在字段名称字典中的偏移量代表,并且值可以由它们在值字典中的偏移量代表。
如果数据库系统确定用于JSON文档集合的镜像格式将是主-明细镜像格式,那么在步骤916对于JSON文档集合生成数据向导,如果数据向导还没有存在的话。在步骤918,基于数据向导生成视图定义,如果这种视图定义还没有存在。最后,在步骤920,基于视图定义实例化仅存储器(memory-only)视图。在仅存储器实例化内,用于视图的每个列的值可以被存储在单独压缩的列单元中。
维护MF数据与PF数据之间的一致性
存储器中MF数据被维护得与PF数据在事务上一致。MF数据在事务上一致在于从MF数据提供到事务的任何数据项目将是如果数据项目从PF数据提供的话将提供的相同版本。此外,该版本反映在事务的快照时间之前已经提交的所有改变,并且不反映在事务的快照时间之后提交的改变。因此,当对在MF数据中被镜像的数据项目做出改变的事务被提交时,该改变相对于PF数据和MF数据两者是可见的。另一方面,如果做出改变的事务被中止或者回滚,那么该改变相对于PF数据和MF数据两者都被回滚。
在一个实施例中,确保PF数据的读取和写入之间的一致性的同一事务管理器还被用来确保MF数据的读取和写入之间的一致性。因为MF数据以事务上一致的方式保持最新,所以如果存储器中MF数据包括由数据库操作所需要的数据,那么可以从存储器中MF数据或者从PF数据满足数据库操作。
MF数据对在PF数据中已经存在的数据进行镜像。然而,虽然MF数据中的所有项目都是PF数据中的对应项目的镜像版本(尽管以不同的格式组织),但是并不是PF数据中的所有项目都需要在MF数据中被镜像。因此,MF数据可以是PF数据的子集。
因为不是所有PF数据都一定在MF数据中被镜像,所以在一些情况下,查询可能需要仅可以由PF数据满足的数据。例如,如果表格具有列A、B和C,并且仅列A在MF数据中被镜像,那么需要来自列B的值的查询必须从PF数据中获得这些值。
然而,甚至在这些情况下,MF数据仍然可以用来(a)满足查询的一部分,和/或(b)加速从PF数据中检索所需的数据。例如,MF数据可以用来识别必须从PF数据中检索的具体行。
根据一个实施例,为了减少开销,不维护MF数据的盘上(on-disk)副本。在可替代的实施例中,可以存储MF的副本,但是不尝试保持MF数据的盘上副本与正在对PF数据执行的更新同步。因此,在失败之后,必须基于PF数据的永久副本来重新构造存储器中MF数据。
根据一个实施例,使用在镜像申请中描述的技术来维护半结构化文档的镜像格式版本(不管是基于行的镜像格式、基于集合的镜像格式还是主-明细镜像格式)与半结构化数据的永久格式版本在事务上一致。例如,一旦被构造,则包含半结构化数据的IMCU可以被当作只读的。因此,当对JSON文档做出更新时,IMCU中的相应行失效而不是被更新。为了记录更新,改变可以存储在存储器中日志中。当IMCU内的阈值百分比的行已经失效时,可以重新构建IMCU。重新构建反映半结构化文档的IMCU涉及读取这些文档的永久格式版本,将数据转换成镜像格式中的一种,以及将转换后的数据存储在新的IMCU中。
处理访问被镜像的半结构化数据的查询
在实施例中,MF数据镜像反映(mirror)以永久格式存在的数据。然而,虽然MF数据中的所有项目都是PF数据中的相应项目的镜像版本(尽管以不同的格式组织),但是并不是PF数据中的所有项目都需要在MF数据中被镜像。因此,MF数据可以是PF数据的子集。
此外,即使由查询针对的所有半结构化文档都在易失性存储器中被镜像,被镜像的数据中的一些可能无效。例如,文档中的一些文档可能已经更新,其中更新对PF数据进行但是没有对MF数据进行。与已更新文档对应的MF数据可以仅仅被标记为无效,而不是更新MF数据。
因为不是所有PF数据都一定在MF数据中被镜像并且有效,所以在一些情况下,查询可能需要仅可以由PF数据满足的一些数据。例如,图2中以IMCU形式被镜像的表格A可以仅包含以PF形式存储的盘上表格A中存储的分层数据对象中的一些分层数据对象。例如,IMCU 1和IMCU 2各自仅具有10行。因此,存储器中表格A存储用于二十个半结构化文档的MF数据。然而,表格A的盘上副本可以以永久格式存储数百个半结构化文档。
因此,查询可能需要访问表格A中的没有在表格A的存储器中版本中的JSON对象。在这些情况下,执行查询的DBMS必须被配置为从IMCU和PF源二者获得JSON对象。例如,在执行访问表格A中的JSON分层数据对象的查询的DBMS中,查询由DBMS重写成SQL查询以并入用于访问JSON对象的基于路径的操作符。操作符的实现可以被配置为访问在表格A中以文本形式或者以IMCU格式永久地存储的JSON对象。
用于访问诸如JSON之类的分层数据对象的基于路径的操作符在由Zhen Hua Liu等人于2014年7月21日提交的、标题为Generic SQL Enhancement To Query Any Semi-Structured Data And Techniques To Efficiently Support Such Enhancements的美国专利申请号14/337,189(美国专利公开号2015-0039587A1)中描述,该美国专利申请的全部内容通过引用并入本文。
IMCU形式的益处
根据一个实施例,IMCU格式完全独立于永久格式。然而,MF数据基于永久存储的PF数据,而不是基于任何永久的IMCU结构在存储器中被初始地构造。因为不需要永久结构,所以现有数据库的用户不需要将他们的现有数据库中的数据或者结构迁移为另一种格式。用户可以保留文本形式的分层对象而不必将对象转换成PF。事实上,分层数据对象的PF可以是异构的,例如,文本、编码的或者关系型。
以IMCU形式存储分层数据对象使得IMCU形式固有的强大能力可用于访问分层数据对象。例如,在IMCU中被镜像的列中的一个或多个列的最小值和最大值可以存储在存储器中。可以使用最小值和最大值来快速地确定在IMCU中被镜像的列是否具有可以满足引用该列的查询谓词的任何值。例如,如果IMCU存储用于列“age(年龄)”的值,并且最小值/最大值分别为10和20,那么数据库服务器可以立即确定谓词“age>30”将不会由IMCU中的任何数据满足。此外,IMCU可以包含共同字段值字典中的字段值或者对象集合字典中的字段名称的位图索引,或者与共同字段值字典中的字段值或者对象集合字典中的字段名称的位图索引相关联。位图索引指示IMCU中的哪些行包括字段名称或者字段值。
透明地启用半结构化数据存储器中选项
数据库系统通常已经预先定义用于存储半结构化数据的数据类型。例如,数据类型XMLtype可以用来在关系表格的列中存储XML文档。类似地,数据类型JSONtype可以用来在关系表格的列中存储JSON文档。
根据一个实施例,当创建半结构化数据类型的列时,或者当列具有检查约束以强制规定(enforce)特定半结构化数据类型的数据时,数据库服务器在内部增加计算半结构化数据的存储器中格式的隐藏列。根据一个实施例,通过将半结构化数据转换成适当的镜像格式来填充该隐藏列。数据库服务器然后响应于加载触发事件而将隐藏列的内容加载到易失性存储器中。
透明地重写针对半结构化数据的查询以利用MF数据
根据一个实施例,当查询半结构化数据以利用半结构化数据可以以镜像格式在易失性存储器中可用的事实时,用户查询绝不需要由用户修改。为了避免需要用户修改查询以利用数据的镜像格式版本,在查询编译时,当优化器决定使用存储器中执行计划来运行查询时,对于任何半结构化SQL操作符(例如,json_exists()、xmlexists(),json_query()、xmlquery()、json_value()、xmlcast()),数据库服务器重写查询以访问MF数据。
如何重写查询以利用MF数据可以依据实施方式而不同。例如,在MF数据被当作表格的隐藏列的实施例中,数据库服务器可以通过将隐藏列作为操作符的最后变元添加到用户的查询而在内部重写查询。因此,在运行时,当存储器中压缩单元被扫描时,隐藏列值被设置为指向存储器中压缩单元内部的值,使得半结构化SQL操作符可以使用MF数据进行查询评估。
变体
已经描述了实施例,在这些实施例中对于半结构化文档的给定集合,来自文档的数据以一种格式(PF格式)被存储在永久存储装置中,并且以另一种格式(MF格式)被存储在易失性存储器中。然而,在可替代的实施例中,这两种格式可以都存储在永久存储装置中,或者这两种格式可以都存储在易失性存储器中。在永久存储装置上存储两种格式具有减少系统所需要的相对昂贵的易失性存储器的量的益处。另一方面,在易失性存储器中存储两种格式具有甚至在由查询所需要的数据已经在MF格式中失效并且因此必须从PF格式数据中检索的情况下,也能增加查询处理速度的益处。
硬件概述
根据一个实施例,本文中描述的技术由一个或多个专用计算设备实现。专用计算设备可以是硬连线的以执行技术,或者可以包括被永久地编程以执行技术的数字电子设备(诸如一个或多个专用集成电路(ASIC)或者现场可编程门阵列(FPGA)),或者可以包括被编程以按照固件、存储器、其他存储装置或者组合中的程序指令来执行技术的一个或多个通用硬件处理器。这种专用计算设备还可以组合具有定制编程以实现技术的定制的硬连线逻辑、ASIC或者FPGA。专用计算设备可以是桌面计算机系统、便携式计算机系统、手持设备、联网设备或者结合硬连线和/或程序逻辑以实现技术的任何其他设备。
例如,图10是示出可以在其上实现本发明的实施例的计算机系统1000的框图。计算机系统1000包括用于传送信息的总线1002或者其他通信机制、以及与总线1002耦接以用于处理信息的硬件处理器1004。硬件处理器1004可以是例如通用微处理器。
计算机系统1000还包括耦接到总线1002以用于存储信息以及将由处理器1004执行的指令的主存储器1006,诸如随机存取存储器(RAM)或者其他动态存储设备。主存储器1006还可以用于在将由处理器1004执行的指令的执行期间存储临时变量或者其他中间信息。当被存储在处理器1004可访问的非暂态存储介质中时,这些指令使得计算机系统1000成为被定制以执行在指令中指定的操作的专用机器。
计算机系统1000还包括耦接到总线1002以用于为处理器1004存储静态信息和指令的只读存储器(ROM)1008或者其他静态存储设备。诸如磁盘、光盘或者固态驱动器之类的存储设备1010被提供并且被耦接到总线1002以用于存储信息和指令。
计算机系统1000可以经由总线1002耦接到显示器1012(诸如阴极射线管(CRT)),以用于将信息显示给计算机用户。包括字母数字键和其他键的输入设备1014耦接到总线1002,以用于将信息和命令选择传送至处理器1004。另一种类型的用户输入设备是光标控制器1016,诸如鼠标、轨迹球或者光标方向键,以用于将方向信息和命令选择传送至处理器1004以及用于控制显示器1012上的光标移动。该输入设备典型地具有允许设备指定平面中的位置的在两个轴(第一轴(例如x)和第二轴(例如y))上的两个自由度。
计算机系统1000可以使用与计算机系统组合使得计算机系统1000成为专用机器或者将计算机系统1000编程为专用机器的定制的硬连线逻辑、一个或多个ASIC或者FPGA、固件和/或程序逻辑来实现本文中描述的技术。根据一个实施例,本文中的技术由计算机系统1000响应于处理器1004执行包含在主存储器1006中的一个或多个指令的一个或多个序列而执行。这些指令可以从另一个存储介质(诸如存储设备1010)被读入主存储器1006中。包含在主存储器1006中的指令序列的执行使得处理器1004执行本文中描述的处理步骤。在可替代的实施例中,可以使用硬连线电路系统代替软件指令或者与软件指令组合。
如本文中使用的术语“存储介质”指存储使得机器以具体方式操作的数据和/或指令的任何非暂态介质。这种存储介质可以包括非易失性介质和/或易失性介质。非易失性介质包括例如光盘、磁盘或者固态驱动器,诸如存储设备1010。易失性介质包括动态存储器,诸如主存储器1006。存储介质的常见形式包括例如软盘、柔性盘、硬盘、固态驱动器、磁带或者任何其他磁性数据存储介质、CD-ROM、任何其他光学数据存储介质、具有孔的图案的任何物理介质、RAM、PROM和EPROM、FLASH-EPROM、NVRAM、任何其他存储器芯片或者盒式磁带。
存储介质与传输介质不同,但是可以连同传输介质一起使用。传输介质参与在存储介质之间传送信息。例如,传输介质包括同轴线缆、铜线和光纤,传输介质包含包括总线1002的线。传输介质还可以采取声波或光波的形式,诸如在无线电波数据通信和红外数据通信期间生成的声波或光波。
将一个或多个指令的一个或多个序列承载至处理器1004以供执行可以涉及各种形式的介质。例如,指令可以初始地在远程计算机的磁盘或者固态驱动器上承载。远程计算机可以将指令加载到它的动态存储器中并且使用调制解调器在电话线路上发送指令。计算机系统1000本地的调制解调器可以接收电话线路上的数据并且使用红外发射器将数据转换成红外信号。红外检测器可以接收在红外信号中承载的数据并且适当的电路系统可以将数据放置在总线1002上。总线1002将数据承载到主存储器1006,处理器1004从主存储器1006中检索指令并且执行指令。由主存储器1006接收的指令可以可选地在由处理器1004执行之前或者之后被存储在存储设备1010上。
计算机系统1000还包括耦接到总线1002的通信接口1018。通信接口1018提供耦接到连接到本地网络1022的网络链路1020的双向数据通信。例如,通信接口1018可以是综合业务数字网络(ISDN)卡、线缆调制解调器、卫星调制解调器,或者提供到相应类型的电话线路的数据通信连接的调制解调器。作为另一个示例,通信接口1018可以是局域网(LAN)卡以提供到兼容的LAN的数据通信连接。无线链路还可以被实现。在任何这种实施方式中,通信接口1018发送和接收承载代表各种类型的信息的数字数据流的电信号、电磁信号或者光学信号。
网络链路1020典型地通过一个或多个网络提供到其他数据设备的数据通信。例如,网络链路1020可以通过本地网络1022提供到主机计算机1024的连接或者到由因特网服务提供商(ISP)1026运营的数据装备的连接。ISP 1026又通过现在通常称作“因特网”1028的全球分组数据通信网络提供数据通信服务。本地网络1022和因特网1028都使用承载数字数据流的电信号、电磁信号或者光学信号。承载到计算机系统1000的数字数据以及来自计算机系统1000的数字数据的通过各种网络的信号以及在网络链路1020上并且通过通信接口1018的信号是传输介质的示例形式。
计算机系统1000可以通过(一个或多个)网络、网络链路1020和通信接口1018发送消息和接收包括程序代码的数据。在因特网示例中,服务器1030可以通过因特网1028、ISP 1026、本地网络1022和通信接口1018传输对于应用程序的请求代码。
接收的代码可以在它被接收时由处理器1004执行,和/或被存储在存储设备1010或者其他非易失性存储装置中以用于随后执行。
在前述说明书中,已经参考可以依据实施方式而不同的许多具体细节描述了本发明的实施例。因此,说明书和附图要被视为例示性的而不是限制性的。本发明的范围的唯一且排他的指示以及申请人打算作为本发明范围的是以权利要求书发布的具体形式从本申请中发布的这种权利要求的集合的字面和等价范围,包括任何随后的补正。
- 还没有人留言评论。精彩留言会获得点赞!