一种用于带验证分布式智能爬取网络信息的方法与流程
本发明涉及互联网技术领域,特别涉及一种用于带验证分布式智能爬取网络信息的方法。
背景技术:
现有的主要针对网页页面爬取的组件包括以下三种方式:
(1)非解析类爬虫(HTTP-Based):此类爬虫是基于网络的HTTP(s)协议(例如JAVA组件中的JSoup、HTTPClient),可以根据HTTP报文规则及连接参数构造页面请求(HTTP Request)。但这类爬虫不具备JS引擎模块,不能获取页面动态生成的内容,也不能单次接受到多连接页面。
(2)解析类爬虫(Browser-Based):此类爬虫也是基于网络的HTTP(s)协议(例如JAVA组件中的HtmlUnit),可以模拟浏览器行为,不仅可以接受多连接页面,解析动态报文,还有丰富的内带函数支持解析HTMLDom结构。但这类爬虫不具备验证信息cookie,无法对于需要登录的受保护页面信息进行爬取。此外,由于JS Core引擎和普通浏览器不同,所以有些动态数据还是无法正常显示。
(3)测试类爬虫(Test-Based):以Selenium为代表。与第一类爬虫相似功能相似,这类爬虫由于是以界面为核心的,所以部分地解决网络登录验证的问题。但这类爬虫需要依托浏览器,速度比较慢,只适合单机测试。
技术实现要素:
本发明的目的旨在至少解决所述技术缺陷之一。
为此,本发明的一个目的在于提出一种用于带验证分布式智能爬取网络信息的方法。
为了实现上述目的,本发明一方面的实施例提供一种用于带验证分布式智能爬取网络信息的方法,包括如下步骤:
步骤S1,当判断网站的目标页面数据需要登录验证后才能获取时,从数据库获取相应的登录信息,通过浏览器自动登录并提交验证信息;
步骤S2,校验登录成后,将从服务器获取的cookie进行序列化,将序列化后的cookie、登录信息和网站域名存入数据库,启动定时任务使用cookie访问其网页,并对cookie做留活处理;
步骤S3,启动网络抓包检测器,根据数据业务需求访问相应目标页面,由所述网络抓包检测器抓取HTTP数据请求和响应的HTTP报文,进行HTTP报文分析,定制爬虫脚本,确定任务爬取数据量;
步骤S4,在生成爬虫脚本并确定爬取任务后,当判断有新任务后,由主节点发出广播,通知相应的任务节点,分发爬虫脚本,所述任务节点在接收到通知后,启动并向主节点任务队列申请任务,根据申请到的任务进行数据爬取,将爬取的目标数据存入队列,进而批量存入数据库。
进一步,在所述步骤S1中,所述登录信息包括:用户名-密码键值对,采用HtmlUnit组件中的selector查找登录所需标签,并放入用户名密码键值对,提交登录申请。
进一步,在所述步骤S1时,当校验登录需要输入验证码时,首先利用光学字符识别OCR进行自动登录,包括:采用多种OCR识别模块对验证码的每个字符进行投票,取投票最高的作为识别结果,进行自动录入;
如果利用OCR无法识别验证码图片,则应用Java中的Swing和Swt的浏览器组件,进行人工登录,所述浏览器组件获取受保护的cookie验证信息,需要重新编译浏览器与操作系统交互的cookie类库,将此文件打包部署在项目中。
进一步,在所述步骤S2时,当所述登录信息符合以下条件时,判断登录成功:
(1)提交用户名密码后的URL地址的三级域名是否和登录页面相同;
(2)提交用户名密码后的URL地址是否含有redirect关键词;
(3)新页面是否含有标志性标签元素,其中,所述标志性标签元素为区别于登录页面的标签元素或者关键字,包括登录个人信息标签、设置标签、退出标签。
进一步,在所述步骤S2中,对cookie进行序列化,包括:将cookie列表转为Json字符串。
进一步,在所述步骤S3中,所述网络抓包检测器利用XPath的方式查找所需数据,并对其中的相似数据通过自定义报文推断引擎生成规则脚本。
进一步,在所述步骤S3中,对于不能直接获取的数据,应用自定义智能报文推断引擎,匹配爬虫HTTP报文生成特殊申请,其中,所述自定义智能报文推断引擎,根据所述网络抓包检测器为输入,以HTTP协议报文和HTML标签为关键词,进行规制匹配生成脚本。
进一步,在所述步骤S4中,在生成爬虫脚本并确定爬取任务后,采用Java的quartz调度框架开启定时任务。
进一步,在所述步骤S4中,爬虫脚本采用消息机制来进行分发,
所述任务节点收到通知后,根据通知内存储任务ID和版本查找相应的实现类,如果本地找不到,则所述任务节点向主节点申请,其中,所述实现类通过流的方式写到所述任务节点,所述任务节点通过ClassLoaderExpand中的findClass实例化此实现类,再通过Java反射来调用页面爬取方法来实现数据收集。
根据本发明实施例的用于带验证分布式智能爬取网络信息的方法,具有以下有益效果:通过自动和人工辅助的方式登录,获取并存储网站验证信息,提供有效机制确保验证信息在服务器长期留存有效;自定义智能报文推断引擎,主从分布式结构,进行爬取任务分配和任务实施,实现了一种可自动登录,访问受保护页面,自动生成挖掘脚本的,快速的可扩展的分布式网页爬虫综合框架。本发明可以帮助开发者将可爬取页面扩展到可解析、受保护页面限制,突破了原有的限制;应用模式匹配生成爬取脚本,节省大量的开发时间;在爬取机制上采取主从分布式,平衡各个节点负载的同时,提升了网络I/O的效率。
本发明附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:
图1为根据本发明实施例的用于带验证分布式智能爬取网络信息的方法的流程图;
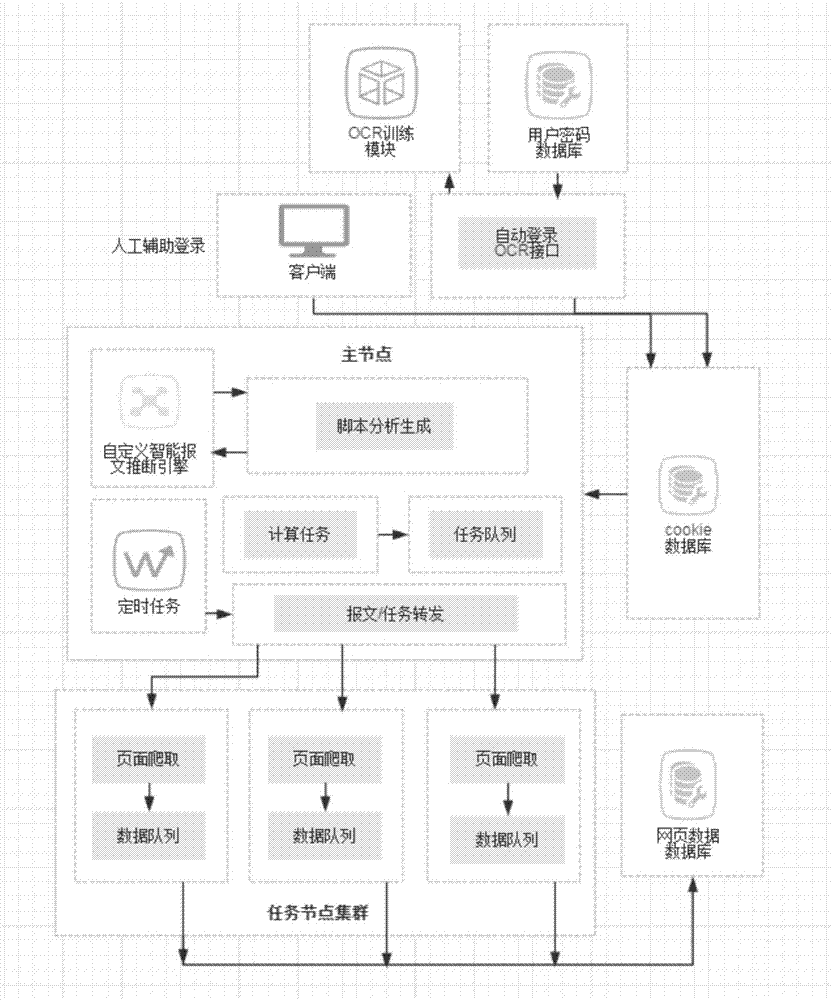
图2为根据本发明实施例的用于带验证分布式智能爬取网络信息的方法的架构图。
具体实施方式
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。
本发明提出一种用于带验证分布式智能爬取网络信息的方法,可以实现自动登录,访问受保护页面,自动生成挖掘脚本,进行数据爬取。
如图1和图2所示,本发明实施例的用于带验证分布式智能爬取网络信息的方法,包括如下步骤:
步骤S1,当判断网站的目标页面数据需要登录验证后才能获取时,从数据库获取相应的登录信息,通过浏览器自动登录并提交验证信息。
在本发明的一个实施例中,登录信息包括:用户名-密码键值对,采用HtmlUnit组件中的选择器selector查找登录所需标签,并输入用户名密码键值对,提交登录申请。
当校验登录需要输入验证码(例如显示数字、字母、中文的验证码图片)时,利用光学字符识别OCR进行自动登录,包括:采用多种OCR识别模块对验证码的每个字符进行投票,取投票最高的作为识别结果,进行自动录入。其中,光学字符识别OCR多个开源OCR对验证码进行识别,包括Tesseract、OCRopus、Cuneiform、GOCR和自定义识别验证码程序。这些识别项目被整合统一接口部署在一台验证服务器上。
当HtmlUnit加载页面时,将验证码图片以文件的形式持久化在服务器某一目录下,然后启动验证码识别接口。各个OCR识别模块对识别结果做出校验后,确定字符结果(字符串)和权重,然后对每个字符进行投票,取投票最高的作为识别结果。
各个OCR识别模块可以利用正则表达式对每个返回的字符进行校验(例如中文正则为[\u4e00-\u9fa5]),如果不在这个范围则将这个结果权重降到最低;确定字符结果和权重后,对每个字符进行投票,取投票最高的作为识别结果。
如果多次OCR识别仍验证失败,即验证图片结果有不属于正则范围的字符出现,则重复加载HtmlUnit获取验证码图片,重复如上过程。如失败结果次数超过所设阈值(例如,4次),进行人工干预,储存失败验证图片会被存储用作训练集,实现识别程序自增长,提升识别率。
下面对人工干预的过程进行说明。
如果利用OCR无法识别验证码图片,则应用Java中的Swing和Swt的浏览器组件,进行人工登录。例如,可以使用基于chromiun的swing组件,也可使用JavaFX的方式(不支持网页Flash组件)。
登录成功后,根据网络传输协议安全标准,登录cookie属于受保护信息,带有HTTPOnly字段,所以正常浏览器无法通过JavaScript显示的取得这些值。可以通过改写Browser组件中的cookiemanager获取cookie的方法来拿到这些得到验证信息。此过程需要重新编译浏览器(Browser)与OS系统交互的类库重新编译浏览器与操作系统交互的cookie类库,将此文件打包部署在项目中,浏览器组件才能获取受保护的cookie验证信息。
其中,cookie类库分为以下方式:window系统下为dll文件,Linux系统下为so文件。
步骤S2,校验登录成后,将从服务器获取的cookie进行序列化,将序列化后的cookie、登录信息和网站域名存入数据库,启动定时任务使用cookie访问其网页,并对cookie做留活处理,以便使得cookie长期留存,不会超时过期。
在本步骤中,由于各个网站的cookie不同,当登录信息符合以下条件时,判断登录成功:
(1)提交用户名密码后的URL地址的三级域名是否和登录页面相同;
(2)提交用户名密码后的URL地址是否含有redirect关键词;
(3)新页面是否含有标志性标签元素,其中,标志性标签元素为区别于登录页面的标签元素或者关键字。例如:登录个人信息标签、设置标签、退出标签。
需要说明的是,标志性标签元素不限于上述举例,还可以为其他类型标签,只要满足区别于登录页面的条件,在此不再赘述。
校验登录成功后,对cookie进行序列化,包括:将cookie列表转为Json字符串。将序列化后的cookie、登录信息和网站域名存入数据库。
根据网络安全协议标准,服务器保留验证session(在服务端每个登录cookie对应一个session)留活(keep alive)的最大时长是900秒。cookie存入数据库之后,启动Java的quartz定时计划项目,每隔800秒使用该cookie访问网站(小于900秒的时长都可以,但为避免CPU过载和网络拥塞,此值不宜太小),以确保登录取得的cookie在服务器可以长期有效。
步骤S3,启动网络抓包检测器,根据数据业务需求访问相应目标页面,由网络抓包检测器抓取HTTP数据请求和响应的HTTP报文,进行HTTP报文分析,定制爬虫脚本,确定任务爬取数据量。
根据数据业务需求,需要定制不同的页面爬取脚本,脚本生成采用机器加人工的方式。具体地,启动网络抓包检测器,以调试模式开启步骤S1中的浏览器,访问业务所需数据页面,网络抓包检测器抓取HTTP数据请求和响应的HTTP报文(HTTP Request/Response),用XPath的方式找到所需数据,并对其中的相似数据(如分页数据)通过自定义报文推断引擎生成规则脚本。
对于不能直接获取的数据,即如果数据不是直接的显示页面,而是通过AJAX独立加载的和HTML合成的,可以根据截取的遍历报文,应用自定义智能报文推断引擎,匹配爬虫HTTP报文生成特殊申请,其中,自定义智能报文推断引擎,根据网络抓包检测器为输入,以HTTP协议报文和HTML标签为关键词,进行规制匹配生成脚本。
具体地,由自定义智能报文推断引擎来判断是哪一个数据请求发起的数据,进而将此报文请求生成XmlHttpRequest请求脚本。如果有利用页面数据和JavaScript中的函数计算数值再提交报文,特别是解析类爬虫不能解析的页面,则可利用原有JavaScript和自定义智能报文推断引擎来生成新的新的JS脚本,挂载在解析类爬虫上,使其正常发送报文。
步骤S4,在生成爬虫脚本并确定爬取任务后,当判断有新任务后,由主节点发出广播,通知相应的任务节点,分发爬虫脚本,任务节点在接收到通知后,启动并向主节点任务队列申请任务,根据申请到的任务进行数据爬取,将爬取的目标数据存入队列,进而批量存入数据库。
在生成爬虫脚本并确定爬取任务后,需要开启定时任务。在本发明的一个实施例中,采用Java的quartz调度框架开启定时任务。
对于任务可以设置为单数据任务或多数据任务:单数据任务可以直接插入消息队列,多数据任务需要在主节点来计算任务量(如分页数据)后再分块插入消息队列。此处消息队列使用的是Kafka。分块的意义在于避免某一个节点任务过多,网络爬取时间过长。
当判断有新任务后,由主节点发出广播,通知相应的任务节点,分发爬虫脚本。在本发明的一个实施例中,爬虫脚本使用过消息机制来进行分发。
任务节点收到主节点的通知后,根据通知内存储任务ID和版本查找相应的实现类(Java中的class)。如果本地找不到,则任务节点向主节点申请。其中,实现类通过流的方式写到任务节点,任务节点通过ClassLoaderExpand中的findClass实例化此实现类,再通过Java反射来调用页面爬取方法来实现数据收集,避免了频繁的项目部署。此处如果是需要受保护页面,任务节点还需向步骤S2中的校验信息数据库请求cookie信息。为避免大量申请,cookie信息缓存在任务节点本地。
任务节点爬取成功后,数据会先缓存在本地队列,当数据达到阈值时,一次批量插入数据库,避免频繁插入和数据库socket长连接。例如,此处阈值设:消息队列长度为1000。
根据本发明实施例的用于带验证分布式智能爬取网络信息的方法,具有以下有益效果:通过自动和人工辅助的方式登录,获取并存储网站验证信息,提供有效机制确保验证信息在服务器长期留存有效;自定义智能报文推断引擎,主从分布式结构,进行爬取任务分配和任务实施,实现了一种可自动登录,访问受保护页面,自动生成挖掘脚本的,快速的可扩展的分布式网页爬虫综合框架。本发明可以帮助开发者将可爬取页面扩展到可解析、受保护页面限制,突破了原有的限制;应用模式匹配生成爬取脚本,节省大量的开发时间;在爬取机制上采取主从分布式,平衡各个节点负载的同时,提升了网络I/O的效率。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在不脱离本发明的原理和宗旨的情况下在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。本发明的范围由所附权利要求及其等同限定。
- 还没有人留言评论。精彩留言会获得点赞!