煤系含或隔水层三维可视化建模方法与流程
本发明涉及一种煤系含或隔水层三维空间展布的方法,尤其是一种煤系含或隔水层三维可视化建模方法。
背景技术:
我国煤炭的生产与消耗位居世界前列,煤炭在国内能源消费中有着举足轻重的意义。随着矿井的开采深度与强度的加大,矿井水害的发生越来越频繁。查清煤矿的水文地质条件,直观的研究含水层分布尤为重要。
在传统的煤系含或隔水层研究中,主要应用二维地质图件,运用投影几何学、画法几何学及矿体几何学的原理,将含或隔水层分布投影到平面上,对含或隔水层平面形态以及纵向分布进行描述。然而,由于复杂的煤系含或隔水层分布以及地质构造的影响,通过二维、静态的平面图件难以直观、合理的表达煤系含或隔水层的空间分布,常会出现由于三维空间分布认识不足而导致的二维图件与三维空间地质内容差异。
为了预防矿井水害,必须更加直观有效的研究煤系含或隔水层,建立三维地质模型已经成为直观研究煤系含或隔水层空间展布的有效手段。GMS是目前国内常用的煤系含或隔水层三维水文地质建模软件,其可依据钻孔地层建立三维地层实体。但GMS在实际应用中,对于构造建模以及物性建模方面较欠缺。由于构造与物性建模的欠缺导致在实际应用中不能将断层对含或隔水层的影响进行表示,也不能对含水层的富水性进行直观的表达。
中国地质科学院的博士论文《华北平原含水层非均质性研究—以石家庄栾城县为例》,吉林大学学报(地球科学版)第41卷第5期2011年09月,公开了马荣等的《熵权耦合随机理论在含水层非均质综合指数研究中的应用》,两篇论文均公开了运用含水层非均质综合指数定量化表征含水层综合非均质性,其计算流程主要包括:(1)利用云-Markov模型估计沉积样品的渗透系数;(2)通过Markov原理来模拟含水层沉积微相的分布模型;(3)在此基础上,通过相控建模原理利用改进的序贯模拟技术构建含水层的渗透系数和孔隙度分布模型。
但是,其公布的技术还有以下几点缺陷,首先,以公开方法对沉积地质特征判别的技术较简单,仅仅依据概率累计曲线进行分析,针对地质特征复杂的特点,其分析的结果不是太准确;第二,Markov原理沉积微相建模属于随机建模方法,随机模拟方法有很大的不确定性,只靠数学计算进行沉积微相建模不能真实的反应沉积微相的展布规律。第三,其使用技术方法没有使用构造建模技术,无法体现构造特征对煤系含或隔水层的控制。
技术实现要素:
本发明的目的是为克服上述现有较单一的建模方法和对构造与物性建模以及基础地质研究的欠缺,提供一种煤系含或隔水层三维可视化建模方法。
为实现上述目的,本发明采用下述技术方案:
一种煤系含或隔水层三维可视化建模方法,包括以下步骤:
1)收集相关钻孔岩性、泥岩颜色、钻孔岩心、钻孔坐标、孔口标高、数字化构造图、物性和断点数据,对相应的数据进行整理与归类;
2)利用步骤1)中的钻孔岩性数据,识别含水层与隔水层的界面,建立相应的分层数据,当不同地层的厚度比小于1/10,则忽略相对较薄地层属性;结合周边钻孔数据建立隔水层与含水层的地层格架;
3)利用步骤1)中的断点数据以及数字化构造图中的断层交面线,以插值得到的数字化构造图为约束,建立被断点数据与构造图约束的断层模型;
4)在步骤3)的断层模型建立之后,构造层面模型建立以前,对整个模型的分辨率及横向与纵向的识别范围进行规定,即模型进行网格化;
5)利用步骤2)中的分层数据,以步骤3)和步骤4)结果为约束条件,采用克里金插值的方法,得到初始的构造层面模型,并根据分层数据进行构造层面的调整;
6)利用步骤1)中的钻孔岩性、泥岩颜色和钻孔岩心数据,研究煤系地层沉积地质特征,以序贯指示模拟结合沉积微相展布特征的技术建立沉积微相模型,利用随机模拟与确定性模拟相互结合的方法使得模拟结果更贴近实际;
7)在步骤5)层面模型建立的基础上,根据步骤1)中整理的物性数据,结合对应的测井曲线计算建模所用的物性数据,以相控技术与理论技术为基础,建立煤系含或隔水层的物性模型。
所述步骤3)—7)中,建立的断层模型,构造层面模型,沉积微相模型以及煤系含或隔水层物性模型都是应用Petrel软件所建立的。
Petrel是斯伦贝谢公司开发的储层地质建模软件,完善的构造建模系统是该软件的特点,依据数字化的构造图以及各分层中的断点数据,应用确定性建模的方法,可以建立三维可视化断层模型,这些断层可以有效的控制地层流体的分布。
所述步骤7)中的相控技术与理论是以沉积微相为约束条件,进一步分相模拟煤系地层的物性特征,建立相关模型;该理论的出发点就是承认不同相之间存在差异性,是研究煤系含或隔水层非均质性的基础。
所述步骤1)中钻孔岩性数据主要是根据钻孔柱状图进行分析,或者直接观察钻孔岩心,并对岩心岩性进行划分,区分出含水层岩石类型与隔水层岩石类型。
所述步骤3)中数字化构造图中会有断点数据生成的断层交面线,每个小层的断层交面线显示这条断层在该层位的上升盘与下降盘;如果出现没有断层交面线的情况,根据断点数据控制断层,将相同断层的断点在平面上组合起来,绘制出不同层位的断层交面线。
根据构造图构造线的差异判断出断层的性质;根据区域应力情况判断断层性质,在区域拉张应力条件下一般不出现逆断层,而在挤压应力条件下,则以逆冲或者逆断层为主。
所述步骤4)中的模型的网格化是指设置预建立模型的网格,根据网格的分辨率大小来设定模型的精度,模型的网格化是地质模型的基石。
所述步骤5)中,经过克里金插值得到的初始构造层面模型会由于机械运算问题而与实际地质条件不符,有些部分由于缺乏分层数据的控制使得层面模型叠合,从而使生成的构造模型出现漏洞;需要对层面模型进行平滑,使其与实际地质情况相符。
所述步骤5)中的克里金估值是一种最优无偏估值方法,这种方法用于随机模拟,以已知变量为基础,应用变差函数,对待估点的未知值作出最优无偏估计,区域化变量Z(x)在x处的随机变量Z*(x)用一个线性组合来表示:式中,Z*(x)—待估点的克里金估计值;Z(xi)—待估点周围某点xi处的观测值,i=1,2,3…,n;n为自然数;λi—xi处的加权系数,表示xi点对估值Z*(x)的影响大小。
所述步骤6)中,煤系沉积地质特征主要包含对煤系地层的沉积环境、沉积物源及沉积微相进行研究;通过岩石颜色指数分析、古生物、古水深还原方法判断研究区域的沉积环境,岩石颜色较深判断为还原环境,说明水深较深,古生物化石多出现适合深水生物化石,而颜色较浅判断出富氧的环境,说明水深较浅,古生物化石多出现潜水生物化石;分析重矿物的组合类型和含量指示物源区母岩性质,石榴石等重矿物含量高的区域指示近物源区,各类重矿物含量低值区域为远物源区;结合区域沉积相背景和其他测录井资料,对目标区域的砂体厚度进行划分;在相分布研究上,充分利用录井岩性剖面和砂体展布图,识别相标志,对沉积微相进行了判别,同时划分出沉积微相的平面的展布特点;沉积微相的平面展布按照相序递变规律,不应有跳相现象;在沉积微相平面展布的基础上,通过沉积微相来约束含或隔水层的平面展布形态。
所述步骤6)中的序贯指示模拟是序贯模拟的指示化方法,这种方法相对于常规序贯模拟能够更好的处理多种分布方式的原始样本,有利于离散性的沉积微相和含水层砂体分布数据为基础建立相应的模型;
序贯指示模拟的具体步骤如下:
首先,是将原始数据变换为指示变量;沉积微相数据属于离散性分布数据,该类数据的门槛值为所有离散性数据;矿区煤系上覆地层为辫状河道沉积环境,这种亚相里面包含三种沉积微相,分别是心滩沉积、辫状河道滞留沉积、河道漫溢沉积,相数据为1、2、3,所有的相数据均是这三个值中的一个,那么门槛值就是这三个数;相应的指示函数就是Z(u,1);Z(u,2);Z(u,3);
其次,把指示化的原始相数据采用序贯模拟方法进行随机模拟;序贯模拟方法的具体步骤如下:
矿区网格化为N个网格结点,其中N个随机变量Zi(i=1,2,…,n)的条件联合概率模型:
FN[Z1,Z2,…,Zn/(n)]=Prob{Zi≤zi,i=1,2,…,N/(n)}
由上式可知其条件累积分布函数:
Z1-Prob{Z1≤z1/(n)};
Z2-Prob{Z2≤z2/(n+1)}
…
ZN-Prob{ZN≤zN/(n+N-1)};
其中,i=1,2,…,n,n为自然数,N为正整数;
根据各类网格变量的条件概率累积分布函数,则序贯模拟算法的实现步骤如下:
(1)在已知n个原始数据的条件下变量的条件累积分布函数中抽取一个样本,得到第一个样本设为z1;
(2)将z1加入到原始数据集中,目前的原始数据变为(n+1)=(n)∪{Z1=z1},在新的条件下的条件累积分布函数中抽取一个样本,得到第二个样本设为z2;
(3)重复步骤(2),得到样本z3,…,zN,这一组样本就是一个模拟结果;
(4)重复步骤(1)—步骤(3),重复n次,得到n个这样的模拟结果。
最后,心滩沉积、辫状河道滞留沉积、河道漫溢沉积分别选用不同指示化的变差函数类型,心滩沉积应用标准球型变差函数模型:
其中,a为变程,表示变量的影响大小。变程小于原始数据表示其连续性好,随机性小;大于原始数据,则随机性大。
辫状河道滞留沉积应用指数变差含数模型:
其中,C0是块金常数表示空间变异性大小,a为变程表示变量的影响大小,C为拱高,表示变量差异大小。主物源方向设置C0趋于0,变程a小于原始数据;次物源方向设置C0大于主物源方向,变程a大于原始数据;
河道漫溢沉积选用间断型变差函数块金效应模型:
C0是块金常数表示空间变异性大小;C是拱高,表示变量差异大小,拱高越大表示差异越大。C+C0称为基台值,表征了变量在空间上的总体变异性大小。
经过不同沉积微相的变差函数模拟,达到确定性与随机性模拟相结合的目标,使得模拟结果更加接近实际。
所述步骤1)中的物性数据主要包括含水层的孔隙度数据,该物性数据通过岩心样品测试得到;依据步骤7)中所述根据对应的测井数据结合岩心样品测试进行孔隙度校正,得到回归公式,结合对应的测井曲线计算建模所用的物性数据;步骤7)中建模所用的物性数据主要是指根据回归公式计算出的孔隙度值。
本发明使用Petrel软件应用了多种先进技术:如构造建模技术、三维网络化技术、确定性建模与随机性建模相互结合的技术。尤其针对较强非均质性的地层,随机性建模可以很好的弥补确定性建模的劣势。利用Petrel软件建立基于相控技术与理论和随机-确定性建模理论的三维可视化地质模型能够直观的反应含或隔水层的三维空间分布与含水层富水性,为矿井水害危险性研究提供三维可视化的依据。
本发明的有益效果是:
本发明相对于背景技术中的论文,有以下技术效果:
第一、本发明针对煤系含或隔水层沉积地质特征较复杂的特点,将沉积环境判别技术、物源分析技术、沉积微相展布刻画技术分别分析沉积地质特征,更加准确地描述了煤系含或隔水层空间展布趋势。
第二、本发明应用随机建模与确定性建模相结合的技术方法,即序贯指示模拟与沉积微相展布特征相结合的技术,使得模型更加符合实际。
第三、本发明强调结合数字化构造图、断点数据在构造模型的基础上建立其他模型,充分体现了构造特征对煤系含或隔水层的控制。
本发明将石油地质建模中的构造建模等技术,应用到了煤系含水层建模中。煤系含水层由于沉积构造复杂,沉积环境多样,导致煤系上覆地层中岩性变化频繁;由于煤层与上覆地层的沉积环境差异,造成地层的非均质性很强;煤系地层的基础资料相对于石油储层要少。因此,煤系含水层三维地质建模难度明显大于石油储层三维地质建模。
本发明与现有理论和其他现有技术相比,将相控技术与理论引入了煤系含或隔水层的研究;应用Petrel软件,突出了其构造断层建模的优势,而断层是控制含水层的重要因素;应用了随机建模与确定性建模相结合的手段,即序贯指示模拟结合沉积微相的展布特征建立了沉积微相模型,以相控技术与理论为基础,根据相应物性资料建立含水层的物性模型,使模型更加的贴近实际,更加符合煤系含或隔水层的非均质性特征。
本发明所采用的建模手段是点、线、面、体环环相扣,循序渐进的建模手段。以Petrel软件强大的构造建模能力基础,根据数字化构造图与断点数据控制断层的走向与倾向;以克里金估值建立地层的层面模型;以序贯指示模拟结合沉积微相的展布特征建立沉积微相模型;以沉积微相控制储层物性以及砂体的展布,建立相应的模型,更加准确的描述了煤系含或隔水层空间展布趋势,使模型可信度更高。
附图说明
图1是本发明煤系含或隔水层三维可视化建模方法的流程图;
图2是本发明一个实施例中建立的H矿区断层三维图;
图3是本发明一个实施例中建立的H矿区网格系统图;
图4是本发明一个实施例中建立的H矿区构造层面模型;
图5是本发明一个实施例中建立的H矿区沉积微相平面图;
图6是本发明一个实施例中建立的沉积微相模型随机模拟结果;
图7是本发明一个实施例中建立的H矿区沉积微相模型;
图8是本发明一个实施例中建立的H矿区物性模型;
图9是本发明一个实施例中建立的H矿区岩石孔隙度与声波时差回归图。
具体实施方式
下面结合附图和实施例对本发明进一步说明。
本说明书所附图式所绘示的结构、比例、大小等,均仅用以配合说明书所揭示的内容,以供熟悉此技术的人士了解与阅读,并非用以限定本发明可实施的限定条件,故不具技术上的实质意义,任何结构的修饰、比例关系的改变或大小的调整,在不影响本发明所能产生的功效及所能达成的目的下,均应仍落在本发明所揭示的技术内容得能涵盖的范围内。同时,本说明书中所引用的如“上”、“下”、“左”、“右”、“中间”及“一”等的用语,亦仅为便于叙述的明了,而非用以限定本发明可实施的范围,其相对关系的改变或调整,在无实质变更技术内容下,当亦视为本发明可实施的范畴。
为了改进现有含水层建模中不能充分反应出构造和物性建模以及煤系含水(隔)层的空间展布形态的问题。
为此,本发明提供了一种基于相控技术与理论,应用Petrel软件的煤系含或隔水层建模方法,如图1所示,包括以下步骤:
1)收集相关钻孔岩性、钻孔坐标、孔口标高、数字化构造图、物性和断点等数据。
钻孔岩性数据主要是根据钻孔柱状图进行分析,也可以直接观察钻孔岩心。并对岩心岩性进行合理划分,区分出含水层岩石类型与隔水层岩石类型。
表1是钻孔坐标与孔口标高。钻孔坐标是指钻孔的大地坐标,X坐标和Y坐标;孔口标高指孔口的海拔高度;数字化构造图指插值得到的煤系地层等高线,构造图中包含断层交面线等信息;表2是断点数据。断点数据是指断层在每一小层的断点深度。
2)根据钻孔的岩石性质将地层性质划分为隔水层与含水层,识别含水层与隔水层的界面,建立相应的分层数据,并根据单层厚度以及周边钻孔岩性对地层性质进行调整。
在含水层与隔水层划分中,钻孔的岩石性质是划分的主要依据,如大套隔水性质岩石中夹杂薄层含水性质岩石,则认为该含水性质岩石影响不大。可统分为隔水层。
岩性突变面、不整合面、粒度变换面可以作为含或隔水层界面识别的标志。当含水性质岩石厚度/隔水性质岩石厚度小于1/10时,则认为该含水性质岩石对于地层性质影响不大。
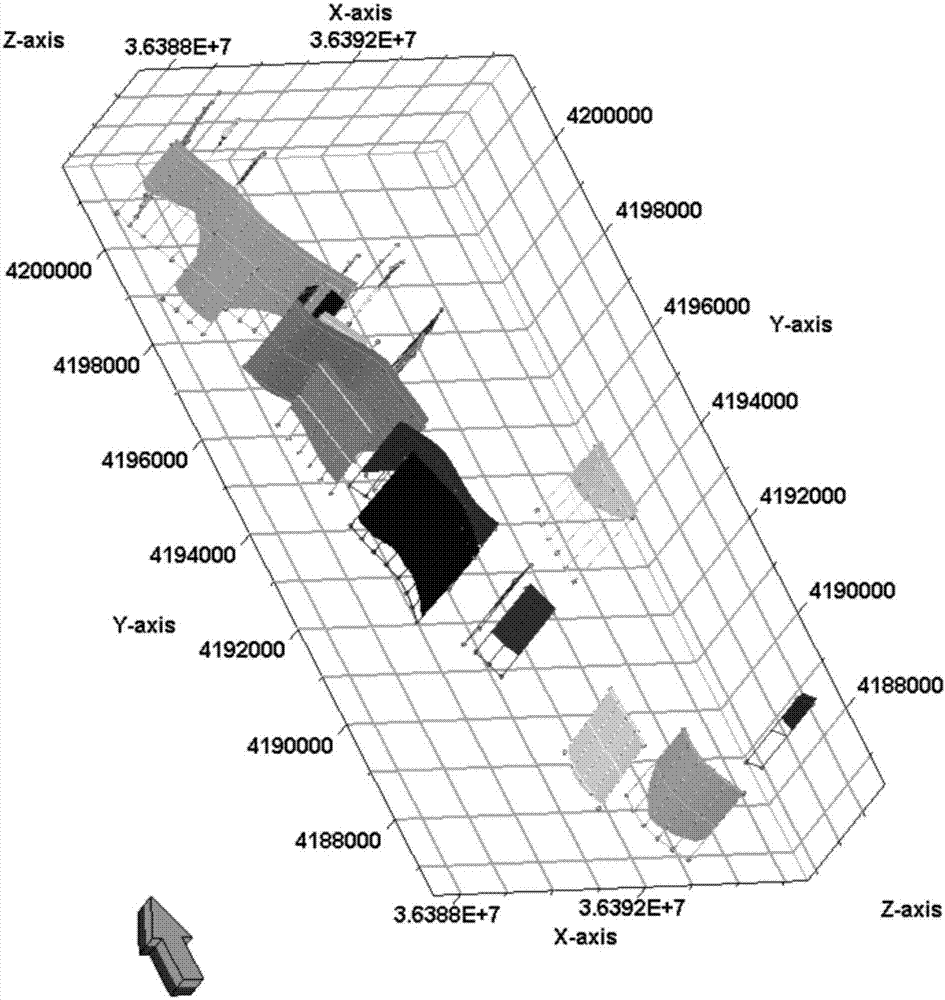
3)图(2)是利用步骤1)中的断点数据以及插值得到的数字化构造图建立的断层模型。
数字化构造图中会有断点数据生成的断层交面线,每个小层的断层交面线显示这条断层在该层位的上升盘与下降盘。如果出现没有断层交面线的情况,可以根据断点数据控制断层,将相同断层的断点在平面上组合起来,绘制出不同层位的断层交面线。
根据构造图构造线的差异判断出断层的性质;根据区域应力情况判断断层性质,在区域拉张应力条件下一般不出现逆断层,而在挤压应力条件下,则以逆冲或者逆断层为主。
4)在断层模型建立后,构造层面模型建立以前,需要对整个模型的分辨率及横向与纵向的识别范围进行规定,即模型进行网格化。网格分辨率的高低决定了生成模型的精度。
模型的网格化即是地质模型的基石,网格的分辨率直接影响着模型生成的精度。图(3)考虑了H矿区的地质特征及断层分布外加计算机的运算能力,建立了H矿区的网格系统。
5)图(4)是利用步骤1)、2)中的分层数据、钻孔岩性数据,以步骤3)步骤(4)结果为约束条件,采用克里金插值,得到初始的构造层面模型,并根据分层数据进行构造层面的调整。
经过克里金插值得到的初始构造层面模型会由于机械运算问题而与实际地质条件不符,有些部分由于缺乏分层数据的控制使得层面模型叠合,从而使生成的构造模型出现漏洞。需要对层面模型进行平滑,使其与实际地质情况相符。
6)步骤5)中的克里金估值是一种最优无偏估值方法,这种方法可以用于随机模拟,以已知变量为基础,应用变差函数,对待估点的未知值作出最优无偏估计。区域化变量Z(x)在x处的随机变量Z*(x)可以用一个线性组合来表示:式中Z*(x)—待估点的克里金估计值;Z(xi)—待估点周围某点xi处的观测值,i=1,2,3…,n;λi—xi处的加权系数,表示xi点对估值Z*(x)的影响大小。
7)图(5)是利用步骤1)中的岩性、泥岩颜色、钻孔岩心等数据,研究H矿区煤系地层主要含水层的沉积地质特征,图(6)是以序贯指示模拟结合沉积微相的展布特征建立的H矿区煤系地层主要含水层的沉积微相模型。利用随机模拟与确定性模拟相互结合的方法使得模拟结果更贴近实际。
煤系沉积地质特征主要包含对煤系地层的沉积环境、沉积物源及沉积微相进行研究。通过岩石颜色指数分析、古生物、古水深还原等方法判断研究区域的沉积环境。物源方向的判断是下一步的砂体及微相的展布的基础,分析重矿物的组合类型和含量可以直接指示物源区母岩性质,根据其含量的变化也可以判断物源方向,为下一步的沉积微相的展布奠定基础。结合区域沉积相背景和其他测录井资料,对目标区域的砂体厚度进行划分。在沉积微相分布模式的基础上,充分利用H矿区录井岩性剖面和砂体展布图,识别相标志,对H矿区沉积微相进行了判别,同时划分出沉积微相的平面的展布特点。沉积微相的平面展布按照相序递变规律,不应有跳相现象。通过H矿区的沉积微相来约束H矿区煤系含或隔水层的平面展布形态。
图(5)将H矿区主要含水层的辫状河道沉积环境划分为三种沉积微相:心滩沉积、辫状河道滞留沉积、河道漫溢沉积。将三种类型的相数据分别表示为1,2,3。图(6)的沉积微相模型将不同类型的相数据进行序贯指示模拟后的结果,图(7)中该含水层的沉积微相模型以步骤7)中沉积微相平面展布的结果进行约束,达到应用序贯指示模拟方法结合沉积地质研究的效果。
8)步骤7)中的序贯指示模拟是序贯模拟的指示化方法,这种方法相对于常规序贯模拟能够更好的处理多种分布方式的原始样本,有利于离散性的沉积微相和含水层砂体分布数据为基础建立相应的模型。
序贯指示模拟的具体步骤如下:
首先,是将原始数据变换为指示变量。沉积微相数据属于离散性分布数据,该类数据的门槛值可以为所有离散性数据。H矿区煤系上覆地层为辫状河道沉积环境,这种亚相里面包含三种沉积微相,分别是心滩沉积、辫状河道滞留沉积、河道漫溢沉积,相数据为1、2、3,所有的相数据均是这三个值中的一个,那么门槛值就是这三个数。相应的指示函数就是Z(u,1);Z(u,2);Z(u,3)。
最后把指示化的原始相数据采用序贯模拟方法进行随机模拟。序贯模拟方法的具体步骤如下:
H矿区网格化为362987个网格结点,其中362987个随机变量Zi(i=1,2,…,362987)的条件联合概率模型:
F362987[Z1,Z2,…,Z362987/(362987)]=Prob{Zi≤zi,i-1,2,…,362987/(362987)}
由上式可知其条件累积分布函数:
Z1-Prob{Z1≤z1/(362987)};
Z2-Prob{Z2≤z2/(362987+1)}
…
Z362987-Prob{Z362987≤z362987/(362987+362987-1)}
根据各类网格变量的条件概率累积分布函数,则序贯模拟算法的实现步骤如下:
(1)在已知362987个原始数据的条件下变量的条件累积分布函数中抽取一个样本,得到第一个样本设为z1;
(2)将z1加入到原始数据集中,目前的原始数据变为(362987+1)=(362987)∪{Z1=z1},在新的条件下的条件累积分布函数中抽取一个样本,得到第二个样本设为z2;
(3)重复步骤(2),得到样本z3,…,z362987,这一组样本就是一个模拟结果;
(4)重复步骤(1)—步骤(3),重复362987次,得到362987个这样的模拟结果。
最后,心滩沉积、辫状河道滞留沉积、河道漫溢沉积分别选用不同的变差函数类型,心滩沉积应用标准球型变差函数模型:
其中,变程a取2,小于原始数据,体现出连续性好。
辫状河道滞留沉积应用指数变差含数模型:
其中,主物源方向设置C0趋于0,变程a小于3;次物源方向设置C0大于主物源方向,变程a大于3;
河道漫溢沉积选用间断型变差函数块金效应模型:
C0块金常数取0.21;C拱高取0.94;得到C+C0基台值为1.15。
经过不同沉积微相的变差函数模拟,达到确定性与随机性模拟相结合的目标,使得模拟结果更加接近实际。
9)图(8)是在步骤5)层面模型建立的基础上,根据步骤1)中整理的钻孔物性数据,以相控技术与理论为基础,结合克里金插值方法,建立煤系含或隔水层的物性模型。
含水层岩性主要是中粗粒砂岩,也包含大部分的细砂岩和少量的粉砂岩,由于地层岩性的不同导致物性的非均质程度较强。采用随机模拟的方法有助于人们认识含水层的复杂性,较好的反映储层性质的离散性,对非均质性表征有较大优势。
物性数据主要包括含水层的孔隙度与渗透率数据。物性数据可以通过岩心样品测试得到,再根据测井数据结合室内实验进行孔隙度校正,根据测井数据得到相应的物性数据。平面上砂体的展布边界是物性建模的边界。
为了更好的研究煤系含水层的物性,本发明搜集钻孔岩心的物性实验数据,图(9)根据物性数据与声波时差测井曲线对比的方法,建立相关关系,得到回归公式:
y=1.3222x-1.2577,其中相关系数(R2)为0.7601,相关系数较强。以声波时差测井数据为基础,建立研究区所有钻孔控制的物性分布特征。根据物性平面分布特征,以平面上沉积微相展布进行约束,最终得到含水层的物性模型。
本发明与现有理论和技术相比,将相控技术与理论引入了煤系含或隔水层的研究;应用Petrel软件,突出了其构造断层建模的优势,而断层是控制含水层的重要因素;应用了随机建模与确定性建模相结合的手段建立了层面模型,以相控技术与理论为基础,根据相应物性资料建立含水层的物性模型,使模型更加的贴近实际,更加符合煤系含或隔水层的非均质性特征。
上述虽然结合附图对本发明的具体实施方式进行了描述,但并非对本发明保护范围的限制,所属领域技术人员应该明白,在本发明的技术方案的基础上,本领域技术人员不需要付出创造性劳动即可做出的各种修改或变形仍在本发明的保护范围以内。
- 还没有人留言评论。精彩留言会获得点赞!