一种面向数据库加密字段模糊检索的密文索引方法与流程
本发明涉及一种面向数据库加密字段模糊检索的密文索引方法,属于信息安全以及数据库加密
技术领域:
。
背景技术:
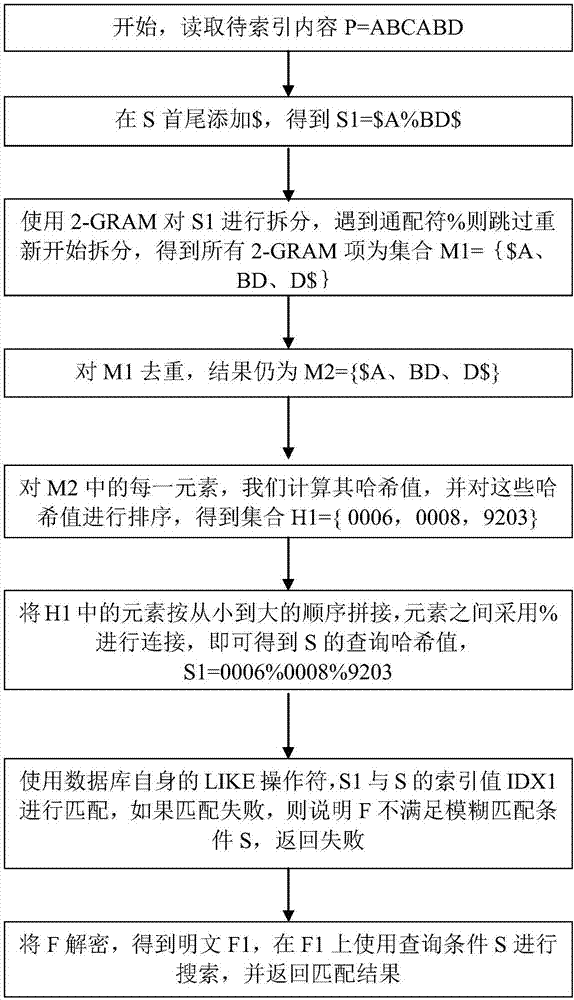
:数据库安全日益重要,对数据库中的敏感字段进行加密是有效的安全手段。对字符型字段进行加密后,如果需要对内容使用LIKE操作符进行模糊检索,就必须将原内容解密后再进行匹配,这样效率会非常低,从而影响到数据库的可用性。目前还未见对字符型加密字段的模糊检索索引的研究成果。本发明的目的是致力于解决上述字符型字段进行加密后使用LIKE操作符进行模糊检索效率太低的问题,提出一种面向数据库加密字段模糊检索的密文索引方法。技术实现要素:本发明的目的是针对现有数据库加密索引技术存在的对字符型加密字段进行模糊检索运行效率低的技术缺陷,提出一种面向数据库加密字段模糊检索的密文索引方法。本发明的原理是使用被加密字段明文的K-GRAM片段计算哈希值,并重组作为密文索引,该索引保存了原文的部分字符特征,但是不能从索引推断回原文。可以通过该索引过滤掉大量的不匹配记录,从而大大降低需要解密进行模糊匹配的记录数,从而提升了对加密字段进行模糊查询的性能。本发明的目的是通过以下技术方案实现的:一种面向数据库加密字段模糊检索的密文索引方法,包括以下内容:首先对待加密的字段C,增加模糊检索索引字段IC。然后对C所在的表T的每个记录,生成字段C的索引字段IC的内容:(一)、记待索引字段内容为字符串P,索引建立过程具体步骤如下:(1)在P的首尾添加标记符,标记出数据的开始和结束,记添加标记后的字符串为P1;(2)以长度为K对P1进行子串拆分,得到K-GRAM集合M1,M1包含P1的长度为K的所有子串;(3)对集合M1中的重复串进行合并,得到子串集合M2;(4)对M2中的每个子串计算哈希值,并进行排序,得到哈希值集合H1;(5)对H1中的所有哈希值按顺序拼接,得到一个新的字符串IDX,此IDX即为P的索引值;(6)返回索引值IDX。(二)、记进行模糊检索的查询条件为S,该字符串可能包含任意关键字以及通配符,记被检索的当前记录的加密字段的内容为C,C的密文索引值为IDX1,匹配过程具体步骤如下:(1)在S的首尾添加标记符,标记出数据的开始和结束,记添加标记后的字符串为S1;(2)以长度为K对S1进行子串拆分,得到K-GRAM集合M1,M1包含S1的长度为K的所有子串,拆分时遇到通配符则跳过重新开始拆分;(3)对集合M1中的重复串进行合并,得到子串集合M2;(4)对M2中的每个子串计算哈希值,得到哈希值集合H1;(5)对H1中的所有哈希值进行排序并按顺序拼接得到一个新的字符串S1;(6)将S1与待匹配的字符串C的索引值IDX1进行匹配,如果匹配成功,则转到(7),如果匹配失败,则说明C不满足模糊匹配条件S,返回失败;(7)将C解密,得到明文C1,在C1上使用查询条件S进行精确匹配,并返回匹配结果。作为优选,所述步骤(6)将S1与待匹配的字符串C的索引值IDX1进行匹配的过程如下:(1)计算S1的子串个数M。M=S1的长度/L,L为所采用的每个K-GRAM的哈希值的长度;(2)设置匹配次数n=0;(3)设置IDX1的当前子串为第一个子串,设置S1的当前子串为第一个子串;(4)如果IDX1和S1的当前子串相等,n加1,IDX1和S1都将当前子串设置为后一个字串;否则,如果IDX1的当前子串大于S1的当前子串,则S1的当前子串置为下一个子串;反之,则IDX1的当前子串置为下一个子串;(5)重复(4),直到IDX1或者S1结束;(6)如果n等于M,即发生了M次匹配,则返回匹配成功,否则返回匹配失败。作为优选,所述步骤(二)、(5)对H1中的所有哈希值进行排序并按顺序拼接,拼接时在各哈希值之间添加通配符“%”;所述步骤(二)、(6)对将S1与待匹配的字符串C的索引值IDX1进行匹配为使用数据库的LIKE操作符将S1与IDX1进行匹配。由于采用了HASH算法,HASH算法本身具有冲突性质,也就是多个不同的原文可能生成一个相同的哈希值,并且本专利对哈希值进行了去重、排序、合并等操作,才得到索引值,所以从索引值并不能逆向的还原出原文,保证了算法的安全。而在匹配过程中,通过哈希值过滤掉了绝大多数的候选记录,仅对索引值匹配成功的记录解密,进行精确匹配,从而保证了很高的性能。有益效果一种面向数据库加密字段模糊检索的密文索引方法,具有如下增益效果:(1)能够对字符型字段建立针对模糊检索的索引,加速对加密字段的检索性能;(2)基于哈希函数生成密文索引,由于哈希函数具有冲突性质,所以从索引值并不能逆向的还原出原文,保证了算法的安全。附图说明图1是本发明一种面向数据库加密字段模糊检索的密文索引方法建立索引阶段流程示意图;图2是本发明一种面向数据库加密字段模糊检索的密文索引方法检索阶段流程示意图;图3是本发明一种面向数据库加密字段模糊检索的密文索引方法索引匹配过程示意图。具体实施方式下面结合附图和实施例对本发明做进一步说明和详细描述。实施例1本实施例详细阐述了应用本发明一种面向数据库加密字段模糊检索的密文索引建立过程的一个具体实例。设待索引字段内容为字符串P=ABCABD,如图1所示,索引建立过程具体步骤如下:(1)在P的首尾添加标记符,本例中使用符号$作为标记符,表示数据的开始和结束,得到P1=$ABCABD$;当然,本领域技术人员亦可使用其它的标记符进行标记;(2)设置K=2,使用2-GRAM对P1进行拆分,得到对应的所有2-GRAM项集合为M1={$A、AB、BC、CA、AB、BD、D$};(3)对M1中的元素去重,得到集合M2={$A、AB、BC、CA、BD、D$};(4)对M2中的每一元素,我们计算其哈希值。以AB为例,其哈希值为(ASCII(A)*ASCII(B))MODM||(ASCII(A)+ASCII(B))MODN。其中,ASCII(X)为取字符X的ASCII码值,MOD为取模运算,||代表字符串拼接符号,M、N为参数。在此实施例中,我们将M取为100,N取为10。经过计算,我们得到所有元素的哈希值,并对这些哈希值进行排序,得到集合H1={9203、0605、0202、0306、0008、0006};(5)将H1中的元素按从小到大的顺序拼接,即可得到数据P的索引值IDX=000600080202030606059203;(6)返回IDX。正如本领域技术人员公知的,此处的哈希函数可以替换为任何其他的哈希函数,以生成哈希值。实施例2本实施例详细阐述了本发明一种面向数据库加密字段模糊检索的密文索引匹配过程的一个具体实例。设进行模糊检索的查询条件为S=A%BD,设被检索的密文为F,F的密文索引值为IDX1,如图2所示,匹配过程具体步骤如下:(1)在S首尾添加标记符,本例中就使用$,表示数据的开始和结束,得到S1=$A%BD$;(2)使用2-GRAM对S1进行拆分,遇到通配符%则跳过重新开始拆分,得到所有2-GRAM项为集合M1={$A、BD、D$};(3)对集合M1进行去重,本例中去重后结果仍为M2={$A、BD、D$};(4)对M2中的每一项2-GRAM,我们计算其哈希值。以$A为例,其哈希值为(ASCII($)*ASCII(A))MODM||(ASCII($)+ASCII(A))MODN。其中,ASCII(X)为取字符X的ASCII码值,MOD为取模运算,“||”代表字符串拼接符号,M、N为参数。在此实施例中,我们将M取为100,N取为10。经过计算,我们得到所有去重后的2-GRAM项的哈希值,并将所有哈希值进行排序并去重,得到一个新的哈希值集合,即H1={0006,0008,9203};(5)对H1的元素按从小到大的顺序拼接,元素之间采用%进行连接,即可得到S的查询哈希值,S1=0006%0008%9203;(6)使用数据库自身的LIKE操作符,S1与IDX1进行匹配,如果匹配成功,则到(7),如果匹配失败,则说明F不满足模糊匹配条件S,返回失败;(7)将F解密,得到明文F1,在F1上使用查询条件S进行搜索,并返回匹配结果。实施例3本实施例详细阐述了本发明一种面向数据库加密字段模糊检索的密文索引在ORACLE数据库上的一个具体实例。如表1所示是本实施例中原有加密前的数据表T1。其中包括两个字段C1和C2,并且已有一些记录。字段ROWID为ORACLE系统提供的伪列,其值表示每个记录的物理位置,也是被加密记录的唯一性标识。C1为字符型字段,为敏感字段,需要对其进行加密。表1:T1ROWIDC1C21ABCABD1首先,针对于上述表T1,将字段C1重命名为EC1,EC1中保存原C1明文加密后的密文,在T1中增加密文索引字段IDX_C1,用于保存C1的密文索引值,如表2所示:表2:加密后的表T1ROWIDEC1IDX_C1C21E(ABCABD)0006000802020306060592031然后,根据实施例1生成字段C1的索引值,并填充IDX_C1字段。设进行模糊检索的查询条件为S=A%BD根据实施例2计算S的索引哈希值为S1=0006%0008%9203,则原先在未加密表上的模糊条件查询:SELECTC1,C2FROMT1WHEREC1LIKE‘A%BD’;可以通过改写SQL请求,使用如下模糊条件查询替换上述语句:SELECTDEC(EC1)ASC1,C2FROMT1WHEREIDX_C1LIKE‘0006%0008%9203’ANDDEC(EC1)LIKE‘A%BD’;数据库执行如上语句时,数据库系统首先使用将查询索引值‘0006%0008%9203’与密文索引字段IDX_C1进行匹配,如果匹配成功,再将EC1解密结果与真实查询条件‘A%BD’进行匹配。在本实施例中,记录1将会被匹配成功且被返回。当数据表中的记录很多时,可以通过条件“IDX_C1LIKE‘0006%0008%9203’”过滤掉很多不匹配的记录,从而大大减少性能损耗。实施例4本实施例详细阐述了本发明一种面向数据库加密字段模糊检索的密文索引在ORACLE数据库上的另一种具体实施方案。本实施方案是通过使用Oracle的扩展索引机制实现的。如表3所示是本实施例中原有加密前的数据表T1。其中包括两个字段C1和C2,并且已有一些记录。字段ROWID为ORACLE系统提供的伪列,其值表示每个记录的物理位置,也是被加密记录的唯一性标识。C1为字符型字段,为敏感字段,需要对其进行加密。表3:T1ROWIDC1C21ABCABD1首先,针对于上述表T1,将字段C1重命名为EC1,EC1中保存原C1明文加密后的密文,在T1中增加密文索引字段IDX_C1,用于保存C1的密文索引值,如表4所示:表4:加密后的表T1ROWIDEC1IDX_C1C21E(ABCABD)0006000802020306060592031然后,根据实施例1生成字段C1的索引值,并填充IDX_C1字段。然后,正如本领域技术人员公知的,为T1的加密列EC1创建扩展索引,并使用CREATEOPERATOR语句创建MY_LIKE()函数,并将其与扩展索引类型进行绑定。当在SQL语句中调用MYLIKE()函数时,系统将按照用户自定义索引来执行数据的查找操作。添加上述扩展索引后,数据查询操作的执行过程如下:(1)当用户调用模糊条件查询语句:SELECTC1,C2FROMT1WHEREC1LIKE‘A%BD’;从表T1中查询数据时,扩展索引使用实施例2计算查询条件S=A%BD的索引哈希值为S1=0006%0008%9203;(2)扩展索引内部使用语句:SELECTROWIDFROMT1WHEREIDX_C1LIKE‘0006%0008%9203’ANDDEC(EC1)LIKE‘A%BD’;数据库执行如上语句时,数据库系统首先使用将查询索引值‘0006%0008%9203’与密文索引字段IDX_C1进行匹配,如果匹配成功,再将EC1解密结果与真实查询条件‘A%BD’进行匹配。在本实施例中,记录1将会被匹配成功且被返回。当数据表中的记录很多时,可以通过条件“IDX_C1LIKE‘0006%0008%9203’”过滤掉很多不匹配的记录,从而大大减少性能损耗。实施例5本实施例详细阐述了本发明一种面向数据库加密字段模糊检索索引方法的另一种密文索引匹配过程的具体实例:设数据索引值为IDX1,本例设其具体值为:000600080202030606059203。设查询条件为S=‘A%BD’。根据实施例2计算S的密文索引查询条件。在实施例2步骤(5)中,对H1的元素按从小到大的顺序拼接。正如本领域技术人员公知的,元素之间不采用%而直接进行连接,即可得到S的查询哈希值,S1=000600089203;设所采用的每个K-GRAM的哈希值的长度L为4,则匹配过程如图3所示,具体如下:(1)计算S1的子串个数,记为M,M=S1的长度/4=12/4=3;(2)设置匹配成功次数n=0;(3)设置IDX1的当前子串为第一个子串“0006”,设置S1的当前子串为第一个子串“0006”;(4)IDX1和S1的当前子串相等,n加1等于1,IDX1和S1都指向下一个子串;(5)IDX1和S1的当前子串相等,都为“0008”,n加1等于2,IDX1和S1都指向下一个子串;(5)IDX1当前字串为“0202”,小于S1的当前子串为“9203”,IDX1的当前子串置为下一个子串,重复(5)直到IDX2的当前子串为“9203”;(6)IDX1和S1的当前子串相等,都为“9203”,n加1等于3,IDX1和S1都指向结束;(7)此时n等于3,也即等于S1的子串个数M,本次匹配成功。以上所述为本发明的较佳实施例而已,本发明不应该局限于该实施例和附图所公开的内容。凡是不脱离本发明所公开的思想下完成的等效或修改,都落入本发明保护的范围。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1