一种基于非易失性存储器的频繁模式挖掘方法与流程
本发明属于存储器技术领域,具体涉及一种用于NVM的频繁模式挖掘方法。
背景技术:
中国专利文献CN106250549A于2016年12月21日公开了一种基于内存的频繁模式挖掘方法,它包括以下步骤:步骤1,构建频繁模式初始树,创建频繁模式树的根结点T,以“null”标记;再次扫描数据库,将读取的每条事务中的频繁项选出并按L中的次序排序;排序后以null为根结点构建一条频繁模式树的路径,只对路径上位于最末的结点的计数加1,路径上的其他结点的计数保持不变;依次扫描完整个数据库中所有事务后获得频繁模式初始树;步骤2,用深度优先搜索算法对频繁模式初始树依次进行遍历,遍历结点的计数器值为该结点本身的值加上其所有孩子结点的值。该专利能减少对NVM的写操作,能快速的构建频繁模式树;且能减少对靠近根结点的结点计数域大量密集的写操作,延长了NVM寿命。
但是,当待挖掘的数据集非常大,用该专利的方法构建树的效率很低,有必要探索一种快速构建频繁模式树的方法。
技术实现要素:
针对现有技术中存在的技术问题,本发明所要解决的技术问题就是提供一种基于非易失性存储器的频繁模式挖掘方法,它在挖掘大数据集时,能够快速构建频繁模式树。
本发明所要解决的技术问题是通过这样的技术方案实现的,它包括以下步骤:
步骤1、利用多核系统对频繁模式树进行并行构建
先将数据库中的多条交易记录大致均匀地分配到每个核中,利用CN106250549A记载的方法,在每一个核上构建一棵本地频繁模式树;
步骤2、对步骤1所构建的频繁模式树进行合并
将本地频繁模式树的信息搜集起来,合并成一棵大的全局频繁模式树。
由于本发明采用并行构建频繁模式树,大幅度缩短了构建的时间,提高了构建频繁模式树的效率,解决了挖掘大数据集时构建树的速度慢的问题。
附图说明
本发明的附图说明如下:
图1为本发明构建频繁模式树的示意图;
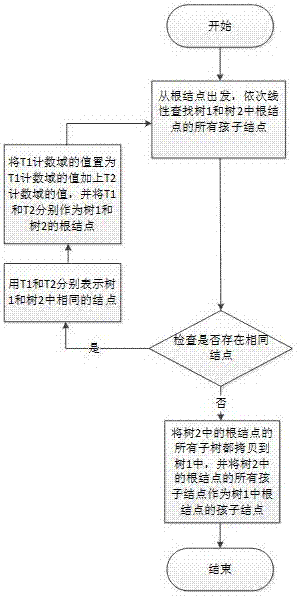
图2为brute-force合并树的流程图;
图3为本发明合并树的流程图;
图4为实验中读操作的测试效果图;
图5为实验中写操作的测试效果图;
图6为实验中构建全局树时间的测试效果图;
图7为本发明与现有并行构建树时间的对比图。
具体实施方式
下面结合附图和实施例对本发明作进一步说明:
本发明应用于多核系统中,硬件包含有CPU、存储器管理单元MMU、作为内存的NVM等,NVM直接连接在内存总线上。发明应用的上下文环境为:上层是应用层,下层具体的硬件,存储器包括NVM以及SSD等。应用层发出操作请求,对作为内存的NVM进行操作。
如图1所示,对本发明包括以下步骤:
步骤1、利用多核系统对频繁模式树进行并行构建
先将数据库中的多条交易记录大致均匀地分配到每个核中,利用CN106250549A记载的方法,在每一个核上构建一棵本地频繁模式树;例如总共十条交易记录以及3个核,大致均匀分配后每个核的交易记录条数为3、3、4;每个核根据分配到的交易记录来构建一棵树。
步骤2、对步骤1所构建的频繁模式树进行合并
将本地频繁模式树的信息搜集起来,合并成一棵大的全局频繁模式树。
Brute-force是现有的一种合并树的方法,用brute-force方法合并树1和树2的步骤,流程图如图2所示:
步骤1)、从根结点出发,依次线性查找树1和树2中根结点的所有孩子结点,检查是否存在相同结点,如存在,用T1和T2分别表示树1和树2中相同的结点,然后执行步骤2);如不存在,则执行步骤3);
步骤2)、T1计数域的值=T1计数域的值+T2计数域的值,并将T1和T2分别作为树1和树2的根结点,返回步骤1);
步骤3)、将树2中的根结点的所有子树都拷贝到树1中,并将树2中根结点的所有孩子结点作为树1中根结点的孩子结点;
步骤4)、程序结束。
采用本发明上述步骤构建频繁模式树时,如果没有优化的管理,会产生许多不必要的读写操作,带来巨大的内存开销,降低构建树的效率,且大量的读写操作会导致NVM的使用寿命减少。
针对合并过程中多次拷贝操作带来的写开销的问题,在上述步骤1中,构建本地频繁模式树时,采用左孩子右兄弟链表结构来存储结点信息。(左孩子右兄弟链表结构的参见文献:T. H. Cormen, C. Stein, R. L. Rivest, and C. E. Leiserson. Introduction to Algorithms.McGraw-Hill Higher Education, 2nd edition, 2001. ( T. H. Cormen, C. Stein, R. L. Rivest, and C. E. Leiserson. 算法导论.McGraw-Hill高等教育, 第二版, 2001.))
以下为本发明中合并树1和树2的步骤,流程图如图3所示:
步骤(1)、从根结点出发,将树1的根结点的最末孩子结点的兄弟指针指向树2的根结点的第一个孩子结点;
步骤(2)、利用所建立的哈希表查找树1和树2根结点的孩子结点中是否存在相同结点,如存在,用T1和T2分别表示树1和树2中相同的结点,然后执行步骤(3);如不存在,则执行步骤(5);
步骤(3)、T1计数域的值=T1计数域的值+T2计数域的值,并将T2结点从该链表中删除;
步骤(4)、将T1和T2分别作为树1和树2的根结点,返回步骤(1);
步骤(5)、结束程序。
上述步骤(1)-(5)直接将相同父结点的所有孩子结点结点链接起来,如果在这些孩子结点中有重复的结点,则将这些孩子结点的计数域的值相加并存储到其中一个结点中,再将其他重复的孩子结点从孩子结点链中删除。通过链接结点的方式避免了在内存空间中拷贝已经存储过的结点,能够有效减少合并本地频繁模式树的过程中大量的不必要的内存写操作,减少写开销,提高性能,降低能耗。
针对合并过程中对指定结点查找效率低的问题以及避免多次查找指定结点操作带来的读开销问题,在上述步骤1中,在构建频繁模式初始树过程中创建新节点时,为根结点T以下的孩子结点建立了哈希表(建立哈希表参见文献:T. H. Cormen, C. Stein, R. L. Rivest, and C. E. Leiserson. Introduction to Algorithms.McGraw-Hill Higher Education, 2nd edition, 2001. ( T. H. Cormen, C. Stein, R. L. Rivest, and C. E. Leiserson. 算法导论.McGraw-Hill高等教育, 第二版, 2001.))。在建立哈希表时仅存储孩子结点的项目名称以节省空间,用该结点的孩子结点数目作为关键字,采用直接取余法建立哈希表,并利用链表法解决哈希冲突。
由于为结点建立了哈希表,在合并频繁模式树时能够快速定位到指定结点,能避免线性查找法对子结点进行挨个查找。当某些结点的孩子结点较多时,可有效减少对结点的读操作,提高查找效率,加快树的合并。
试验测试
选取不同类型的数据集进行试验,统计各个数据集的读写操作总量和总的构建树的时间。这些数据集的名称分别为T10I4D100K、T40I10D100K、retail、chess、mushroom、pumsb*、connect、pumsb、accidents、C73D10、C20D10、T20I6D100。
测试时,本发明与单核采用背景技术方法构建的树以及多核采用brute-force方法合并的树相对比,其中以单核构建方法作为基准对结果进行归一化处理,实验结果参见图4至图7。
图4中,纵坐标代表读的总量,横坐标代表各个数据集,从图4看出,本发明减少了大量的读操作;
图5中,纵坐标代表写的总量,横坐标代表各个数据集,从图5看出,本发明减少了大量的写操作;
图6中,纵坐标代表总的构建树的时间,横坐标代表各个数据集,从图6看出,本发明减少了构建树的时间,本发明最少可减少的建树时间为15.45%(发生在数据集C73D10),最大可减少58.09%(发生在数据集T10I4D100K),极大地增加了构建树的效率。
图7中,纵坐标代表总的构建树的时间,横坐标代表不同的核数,从图7看出,随着核数的增多,本发明减少了构建树的时间,且减少得比brute-force算法多。
- 还没有人留言评论。精彩留言会获得点赞!