动机词汇的自动分类过滤生成创意点计算方法与流程
本发明涉及一种动机词汇的自动分类过滤生成创意点计算方法。
背景技术:
随着计算机技术的快速发展和网络的日益普及,用户可获取的信息量呈现指数级增长[1],极大地丰富了用户所处的信息环境,但是,同时造成了信息过载等问题,增加了用户获取所需动机词汇的难度[2]。自动分类过滤作为最简单有效的解决方法,被认为是处理和组织大量数据的关键技术[3],而对其创意点进行计算,是对自动分类过滤方法优劣评判最有效的方法,成为了该领域亟待解决的问题,受到了广大学者的关注,也出现了很多好的好方法[4-5]。
文献[6]提出基于贝叶斯分类的动机词汇自动分类过滤方法,该方法通过贝叶斯分类进行分类,并给出核心过滤算法在动机词汇分类中的具体实现方法及过程,进而完成对动机词汇的自动分类过滤。但是存在分类时间长的问题;文献[7]提出基于信息反馈的自动分类过滤方法,该方法在现有分类算法的基础上选取了SNoW作为具体主体分类算法,并提出信息反馈和阈值过滤的策略以达到准确过滤无关词汇的目的,实现动机词汇的自动分类过滤。该方法虽然能实现动机词汇的自动分类过滤,但是存在分类过滤效果不佳的问题;文献[8]提出基于启发式规则的自动分类过滤方法,该方法通过对动机词汇进行分词、特征提取的基础上,采用NB分类器进行分类、过滤,实现对动机词汇的自动分类过滤,但是存在分类过滤精度低的问题;文献[9]提出基于潜在语义索引和支持向量机的分类过滤方法,在建立动机词汇信息过滤模型的基础上,分别听过预处理、特征降维、训练、过滤等步骤,达到动机词汇的自动分类过滤,但是存在过滤信息不完整的问题。
针对上述问题的产生,提出基于贝叶斯网络计算的动机词汇自动分类过滤方法。基于爬虫对动机词汇语料信息进行获取,通过建立向量空间模型对采集的信息进行聚类,并以此为依据,采用贝叶斯网络计算动机词汇之间的相关性,并在本体理论基础上按短语或者句子结构,对动机词汇进行分类过滤。实验结果证明,采用改进的方法进行动机词汇分类过滤,相比传统的分类过滤方法,其分类过滤精度高、效率好,具有一定的优势。
参考文献:
[1]侯风巍,郭东军,李世磊,等.基于信息反馈的文本主题分类过滤方法[J].通信学报,2009(s1):139-144.
[2]原媛,孙敏.基于CLARA的KNN文本分类过滤防火墙的设计实现[J].电脑开发与应用,2007,20(10):19-21.
[3]李健.面向智能电网的多领域海量文本过滤框架研究[J].电力信息与通信技术,2015(11):31-35.
[4]马慧媛.如何在大学英语词汇教学中激发学生的学习动机[J].时代教育,2014(3):234-234.
[5]李志义,沈之锐,义梅练.贝叶斯分类算法在社交网站信息过滤中的应用分析[J].图书情报工作,2014(13):100-106.
[6]贾宇波.大数据挖掘分类算法在垃圾邮件过滤中的应用[J].工业控制计算机,2016,29(5).23-26.
[7]高俊波,梅波.基于文本内容分析的微博广告过滤模型研究[J].计算机工程,2014,40(5):17-20.
[8]康建.用词法分析工具实现英语单词提取及分类[J].电脑编程技巧与维护,2015(19):17-17.
[9]吴玮.基于空间向量模型的垃圾文本过滤方法[J].湖南科技大学学报(自然科学版),2014(1):78-83.
[10]王文霞.基于贝叶斯文本分类算法的垃圾短信过滤系统[J].山西大同大学学报(自然科学版),2016(3):13-18.。
技术实现要素:
本发明的目的在于提供一种动机词汇的自动分类过滤生成创意点计算方法,该方法采用改进的方法进行动机词汇分类过滤,相比传统的分类过滤方法,其分类过滤精度高、效率好,具有一定的优势。
为实现上述目的,本发明的技术方案是:一种动机词汇的自动分类过滤生成创意点计算方法,包括如下步骤,
S1、采用爬虫法对动机词汇语料信息进行采集,为动机词汇语料信息聚类处理提供基础依据;
S2、根据步骤S1获取的动机词汇语料信息,采用SVD进行动机词汇信息聚类处理;
S3、在对动机词汇进行聚类处理的基础上,利用贝叶斯网络计算动机词汇之间的相关性,并以本体理论为基础,按短语或者句子结构生成创意点,对动机词汇进行分类过滤生成。
在本发明一实施例中,所述步骤S1具体实现如下,
S11、可获取信息权值的计算:
假设关键词汇集合W=(W1,W2,...,Wn),第i个关键词汇Wi有x(x≥1)个概念意义,记作从关键词汇集合转化到概念集合TW,每个关键词汇的概念可表示为:tjwi=(wi,tji),j=1,2,...,xi;则第i个动机词汇的第j个意义可表示为:
则关键动机词汇tk在动机词汇语料库di里的动机词汇权值为:
wik=tfik×log(N/nk) (2)
其中,N为语料库di中动机词汇的总数,nk为包含关键动机词汇tk的动机词汇的总数,tfik为tk在语料库di中出现的频数;则语料库di的向量可表示为:di=(wi1,wi2,...,win);
S12、基于权值的动机词汇相关语料相关度计算:
先通过权值计算动机词汇属于每个类别的概率,用向量(w1,w2,...,wn)表示;计算获取的动机词汇语料库di中动机词汇属于每一类别的概率,可用下式进行表示:
其中:|D|为动机词汇语料库di中类Bj的训练样本数,N(wm,di)为动机词汇wm在动机词汇语料库di中的词频,|V|为总动机词汇数,为类Bj中所有动机词汇的词频和;则其动机词汇相关语料相关度可用下式进行计算:
式中:训练样本数/总训练样本数,为相似含义,|C|为类的总数,N(wm,di)为wm在动机词汇语料库di中的词频,n为关键动机词汇的总数,通过相关度计算,确定所要获取的动机词汇信息;
S13、基于相关度的动机词汇相关语料信息获取:
结合相关度的计算结果,通过爬虫去采集动机词汇相关语料信息,为动机词汇语料信息聚类处理提供基础依据。
在本发明一实施例中,所述步骤S2具体实现如下,
S21、根据信息论,计算动机词汇出现的概率;定义基于带单个词汇在语料库中出现的平均信息量为:
式中:Pi(w)为单个动机词汇w在语料库中出现的概率,n为常数;W(w)的值越大,说明单个动机词汇w所表示的平均信息量越大,单个动机词汇就越普通,可以当作是噪声词省略掉;
考虑到当一个动机词汇在句子中出现的平均信息量和包含该动机词汇的句子在语料库中的平均信息量都较大时,表示该词较为普通;定义两者之和为联合嫡W'(w):
W'(w)=H(w)+H(s|w) (9)
单个动机词汇在句子中出现的平均信息量H(w):
包含此单个动机词汇w的句子在语料库中的平均信息量H(s|w):
单个动机词汇w在语料库中出现的概率Pj(w):
包含单个动机词汇w的句子在语料库中出现的概率Pl(s|w):
式中:fj(w)为单个动机词汇w在语料库中出现的频率,n为语料库中的动机词汇数,fl(s|w)为包含单个动机词汇的句子s在语料库l中出现的频率;
S22、通过计算阈值,对动机词汇特征进行选择;假设,TF是词频,表示特征tk在此语料库中出现的频率,IDF是反语料库频率,IDF=log(N/n),N表示语料库中所有的动机词汇数,n为包含特征tk的动机词汇数;IDF的的基本思想是如果包含某个特征tk的语料信息越少,IDF就越大,说明特征tk有很好的类别区分能力,则TF-IDF方法的计算公式如下所示:
为了使TF值对权重的影响进一步降低,对上式进行改进,表达式如下所示:
通过计算每个特征tk的期望交又嫡,选取预定数目的最佳特征作为结果的特征子集;计算公式如下:
式中:P(tk)为特征tk出现的概率,P(Ci|tk)为类别Ci在特征tk出现情况下的概率,P(Ci)为Ci的出现概率;
S23、在根据信息增益法计算动机词汇的信息增益,当动机词汇特征tk信息增益大于给定值时作为特征项,计算公式如下:
其中,n为特征集中的维数,pi为当前词汇特征出现的概率;当tk互信息量大于给定值时作为特征项;特征tk和类别Ci的互信息体现了特征与类别的相关程度;特征tk的互信息量为:
S24、应用SVD进行动机词汇聚类处理,k为动机词汇向量中最关键的词汇元素,动机词汇向量是由n个特征组成的n维向量,由于每个动机词汇的特征数不同,可以认为每个动机词汇向量都处于一个空间中,若想要对不同的动机词汇进行聚类处理,就需要将不同维数的动机词汇向量映射到同一个空间中进行比较,降维节后的新矩阵也将大大减少文本处理中不良信息的干扰,则矩阵A进行奇异分解降维写成矩阵Ak:
式中:ui和vi表示动机词汇特征向量和动机词汇向量的语义空间,同样的,在进行文本相似度计算的时候,需要将代表文本特征的向量映射到与Ak行向量具有相同的维数;则得到k维映射后的向量t'为:
通过k维映射后,就可以得到初始向量的相似向量,接下来就可以采用SVD进行动机词汇聚类处理,假设有一组动机词汇序列(X,s)或者(X,d),其中X表示一组样本,s和d分别表示度量样本间相似度或相异度的标准;若C={C1,C2,...,Ck}其中Ci=(i=1,2,...,k)是X的子集,如下所示:
X=C1∪C2...∪Ck (21)
对任意的i≠j,有Ci∩Cj=φ,C中的动机词汇C1,C2,...,Ck叫作簇;对于动机词汇特征相似度作为动机词汇相似度的聚类来说,让同一个聚类簇中的单个动机词汇间相似度更高,则得到聚类结果表达式如下所示:
综上所述,在获取动机词汇语料信息的基础上,可采用SVD进行动机词汇信息聚类处理,为动机词汇自动分类过滤生成创意点的计算提供基础依据。
相较于现有技术,本发明具有以下有益效果:本发明针对传统的自动分类过滤法一直存在分类过滤不准确,效率低的问题,提出基于贝叶斯网络计算的动机词汇自动分类过滤方法;该方法基于爬虫对动机词汇语料信息进行获取,通过建立向量空间模型对采集的信息进行聚类,并以此为依据,采用贝叶斯网络计算动机词汇之间的相关性,并在本体理论基础上按短语或者句子结构,对动机词汇进行分类过滤;实验结果证明,采用改进的方法进行动机词汇分类过滤,相比传统的分类过滤方法,其分类过滤精度高、效率好,具有一定的优势。
附图说明
图1为本发明采用的基于爬虫的动机词汇相关语料信息获取流程图。
图2为本发明采用的贝叶斯网络模型。
图3为不同方法下召回率对比分析。
图4为不同方法下正确率对比分析。
图5为不同方法下错误率对比分析。
具体实施方式
下面结合附图1-5,对本发明的技术方案进行具体说明。
本发明的一种动机词汇的自动分类过滤生成创意点计算方法,包括如下步骤,
S1、采用爬虫法对动机词汇语料信息进行采集,为动机词汇语料信息聚类处理提供基础依据;
S2、根据步骤S1获取的动机词汇语料信息,采用SVD进行动机词汇信息聚类处理;
S3、在对动机词汇进行聚类处理的基础上,利用贝叶斯网络计算动机词汇之间的相关性,并以本体理论为基础,按短语或者句子结构生成创意点,对动机词汇进行分类过滤生成。
以下对本发明的技术方案进行具体描述。
本发明动机词汇的自动分类过滤生成创意点计算方法,具体实现步骤如下:
1基于爬虫算法的动机词汇语料信息获取
由于动机词汇的特殊性,采用爬虫法对动机词汇语料信息进行采集,为动机词汇语料信息聚类处理提供基础依据。
1.1可获取信息权值的计算
采用改进的TF/IDF算法对动机词汇语料信息权值进行计算,通过统计一个词汇在语料库中出现的频度来评估该词汇的重要性,若一个关键词汇A比一个关键词汇B在语料库中出现的频度大,则说明关键词汇A比关键词汇B重要,以此方法来决定权重[10],而这一量度只反应了某特定文档的局部特征,不够完善。从整个语料库来看,一个词汇的频度高,针对特定查询需求区分相关语料和不相关语料重要性就不会很大,一个关键词汇的权重还应该和该词所在语料库的总数成反比关系。
假设关键词汇集合W=(W1,W2,...,Wn),第i个关键词汇Wi有x(x≥1)个概念意义,记作从关键词汇集合转化到概念集合TW,每个关键词汇的概念可表示为:tjwi=(wi,tji),j=1,2,...,xi;则第i个动机词汇的第j个意义可表示为:
则关键动机词汇tk在动机词汇语料库di里的动机词汇权值为:
wik=tfik×log(N/nk) (2)
其中,N为语料库di中动机词汇的总数,nk为包含关键动机词汇tk的动机词汇的总数,tfik为tk在语料库di中出现的频数;则语料库di的向量可表示为:di=(wi1,wi2,...,win);
其中,N为动机词汇语料库中动机词汇的总数,nk为包含关键动机词汇tk的动机词汇的总数,tfik为tk在动机词汇语料库di中出现的频数。则动机词汇语料库di的向量可表示为:di=(wi1,wi2,...,win)。需要注意的是:如果动机词汇训练样本集的语料信息都属于同一类,其中重要动机词汇几乎在每个语料库中都会出现,就会导致IDF的值极小,影响权值。当语料信息全部属于同一个类别时,动机词汇的重要性应该与语料信息在语料库中出现的频率成正比。或者说某一个关键词汇在一个类中出现的次数很大,在别的类中出现的次数都很小,显然此关键词汇具有很好的表征此类文档的能力,所以传统的权值计算方法具有缺陷,并不是对所有的情况都表现优秀需要对其进行改进。
假设总的动机词汇语料库中的动机词汇数为N,tfik为tk在动机词汇语料库di中出现的频数,某一类Bi中出现此关键词汇的个数为nbi,nki表示除类Bi以外的类中包含关键词汇tki的动机词汇语料信息数,则权值计算公式可以表示为:
其中:
设函数:令x1>x2>0,则有:
很显然当x增大,IDF的值随着增大。所以说如果关键词汇tk在类别Bi里出现的次数多,在其他类别中的出现次数少,则关键词汇tk就能很好的代表Bi类的特征,具有很好的区别能力。假如在其他类中出现的次数多,则在此类中的IDF值就会变小,所以此方法获取的权值为最优值。
1.2基于权值的动机词汇相关语料相关度计算
动机词汇语料相关度评价是采用爬虫获取动机词汇相关语料非常重要的一个环节。通过相关度计算可以预测目标动机词汇语料的相关度,引导搜索方向另外对采集的动机词汇语料进行相关度计算,与预先设定的语料权值相比较,大于权值的动机词汇语料保留,小于权值的动机词汇语料直接抛弃。这样既提高所采集语料与动机词汇语料的相关度,又减少了本地的存储空间。所以引入上文权值方法来计算动机词汇语料的相关度。相关度计算常用的方法主要有内容分析法、链接结构分析法。贝叶斯方法其实是一种概率统计的方法,通过计算动机词汇属于某个类别的概率的大小进行匹配。先通过权值计算动机词汇属于每个类别的概率,用向量(w1,w2,...,wn)表示;计算获取的动机词汇语料库di属于每一类别的概率,可用下式进行表示:
其中:|D|为动机词汇语料库di中类Bj的训练样本数,N(wm,di)为动机词汇wm在动机词汇语料库di中的词频,|V|为总动机词汇数,为类Bj中所有动机词汇的词频和;则其动机词汇相关语料相关度可用下式进行计算:
式中:训练样本数/总训练样本数,为相似含义,|C|为类的总数,N(wm,di)为wm在动机词汇语料库di中的词频,n为关键动机词汇的总数,通过相关度计算,确定所要获取的动机词汇信息;
1.3基于相关度的动机词汇相关语料信息获取
结合相关度的计算结果,可通过爬虫去采集动机词汇相关语料信息,详细的获取步骤如下所示:
Input:等待其他节点传来的一个动机词汇,或者它所管辖的抓取进程返回的一个URL及相应的动机词汇;
Oitput:把动机词汇下载或传往其它节点。
(1)若得到其他节点传来的一个动机词汇,看动机词汇是都出现在语料库中;
(2)若得到抓取进程返回的动机词汇,则从动机词汇对应的语料库中解析出超链接LINK。从语料库中分给该抓取进程一个新的动机词汇,并将返回动机词汇放到词汇存储器中;如果爬虫用于普通的爬行则转到A,如果用于词汇爬行转到B;
A:对每一个新得到的动机词汇语料信息计算其权值,公式如下式(8),在节点由每个节点上面维护的一个映射表中得到具体的节点号;
node_num=hash(new_url.host)%node_sum_num (8)
B:对每一个新得到的动机词汇语料信息计算其权值,公式如下式(9),在节点由每个上面维护的一个映射表中得到具体的节点号;
(3)对每一个超链接LINK及其对数的整数,如果本节点标号为整数重新进行分配;反之,将LINK发给节点;
(4)计算相关度,结合相关度判断动机词汇类型是否为所需的动机词汇,如果不是则跳过,如果是则继续进行分析;
(5)读取所需动机词汇采用正则表达式匹配方法,寻找动机词汇语料信息,并进行记录下来;
(6)将记录下来的动机词汇按照预定的形式进行存储,实现动机词汇相关语料信息的获取,表达式如下式(10)所示,流程如下图1所示:
式中:Simcos为动机词汇语料特征,Simmed为动机词汇语料信息量。
2采集动机词汇语料信息的聚类处理
在获取动机词汇语料信息的基础上,采用SVD进行动机词汇信息聚类处理。
第一、根据信息论,计算动机词汇出现的概率;定义基于带单个词汇在语料库中出现的平均信息量为:
式中:Pi(w)为单个动机词汇w在语料库中出现的概率,n为常数;W(w)的值越大,说明单个动机词汇w所表示的平均信息量越大,单个动机词汇就越普通,可以当作是噪声词省略掉;
考虑到当一个动机词汇在句子中出现的平均信息量和包含该动机词汇的句子在语料库中的平均信息量都较大时,表示该词较为普通;定义两者之和为联合嫡W'(w):
W'(w)=H(w)+H(s|w) (12)
单个动机词汇在句子中出现的平均信息量H(w):
包含此单个动机词汇w的句子在语料库中的平均信息量H(s|w):
单个动机词汇w在语料库中出现的概率Pj(w):
包含单个动机词汇w的句子在语料库中出现的概率Pl(s|w):
式中:fj(w)为单个动机词汇w在语料库中出现的频率,n为语料库中的动机词汇数,fl(s|w)为包含单个动机词汇的句子s在语料库l中出现的频率;
第二、通过计算阈值,对动机词汇特征进行选择;假设,TF是词频,表示特征tk在此语料库中出现的频率,IDF是反语料库频率,IDF=log(N/n),N表示语料库中所有的动机词汇数,n为包含特征tk的动机词汇数;IDF的的基本思想是如果包含某个特征tk的语料信息越少,IDF就越大,说明特征tk有很好的类别区分能力,则TF-IDF方法的计算公式如下所示:
为了使TF值对权重的影响进一步降低,对上式进行改进,表达式如下所示:
通过计算每个特征tk的期望交又嫡,选取预定数目的最佳特征作为结果的特征子集;计算公式如下:
式中:P(tk)为特征tk出现的概率,P(Ci|tk)为类别Ci在特征tk出现情况下的概率,P(Ci)为Ci的出现概率;
第三、在根据信息增益法计算动机词汇的信息增益,当动机词汇特征tk信息增益大于给定值时作为特征项,计算公式如下:
其中,n为特征集中的维数,pi为当前词汇特征出现的概率。当tk互信息量大于给定值时作为特征项;特征tk和类别Ci的互信息体现了特征与类别的相关程度。特征tk的互信息量为:
第四、应用SVD进行动机词汇聚类处理,k为动机词汇向量中最关键的词汇元素,动机词汇向量是由n个特征组成的n维向量,由于每个动机词汇的特征数不同,可以认为每个动机词汇向量都处于一个空间中,若想要对不同的动机词汇进行聚类处理,就需要将不同维数的动机词汇向量映射到同一个空间中进行比较,降维节后的新矩阵也将大大减少文本处理中不良信息的干扰,则矩阵A进行奇异分解降维写成矩阵Ak:
式中:ui和vi表示动机词汇特征向量和动机词汇向量的语义空间,同样的,在进行文本相似度计算的时候,需要将代表文本特征的向量映射到与Ak行向量具有相同的维数;则得到k维映射后的向量t'为:
通过k维映射后,就可以得到初始向量的相似向量,接下来就可以采用SVD进行动机词汇聚类处理,假设有一组动机词汇序列(X,s)或者(X,d),其中X表示一组样本,s和d分别表示度量样本间相似度或相异度的标准;若C={C1,C2,...,Ck}其中Ci=(i=1,2,...,k)是X的子集,如下所示:
X=C1∪C2...∪Ck (24)
对任意的i≠j,有Ci∩Cj=φ,C中的动机词汇C1,C2,...,Ck叫作簇;对于动机词汇特征相似度作为动机词汇相似度的聚类来说,让同一个聚类簇中的单个动机词汇间相似度更高,则得到聚类结果表达式如下所示:
综上所述,在获取动机词汇语料信息的基础上,可采用SVD进行动机词汇信息聚类处理,为动机词汇自动分类过滤生成创意点的计算提供基础依据。
3动机词汇自动分类过滤生成创意点的计算
在对动机词汇进行聚类处理的基础上,利用贝叶斯网络计算动机词汇之间的相关性,并以本体理论为基础,按短语或者句子结构生成创意点。
采用贝叶斯网络计算动机词汇间的相关性,主要是由于其通过总体动机词汇信息和先验信息来估计其后验信息。在对动机词汇间的相关性进行计算时,除了考虑动机词汇A产生的概率,还需要考虑在已知的动机词汇B获取的情况下,动机词汇A获取的概率,这就需要计算其条件概率,记为P(A|B),计算公式如下所示:
式中:P(A|B)表示动机词汇A和B同时被采集的概率,P(B)为动机词汇B被采集的概率。
假设(Ω,F,P)为一概率空间。Ai∩Aj=φ(i≠j)且则对任意动机词汇B∈F且P(B)>0,有:
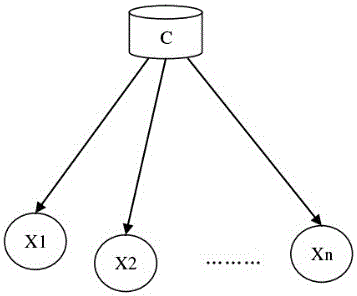
式中:P(Ai)为先验概率,P(B|Ai)为条件概率,为全概率公式,且P(Ai)>0。如果用C表示动机词汇类别结点,用X1,X2,...,Xn表示n个属性结点,则贝叶斯网络模型可用下图2进行表示。
将贝叶斯网络运用到动机词汇自动分类的动机词汇间相关性的计算,其具体计算流程如下所示:
1)把将要计算的动机词汇X用一个n维特征向量X=(t1,t2,...,tn)表示,其中t1,t2,...,tn分别动机词汇向量空间的n个特征项;
2)设有m个动机词汇类别C1,C2,...,Cm,给定一个待计算词汇X,采用贝叶斯网络法将待计算的词汇X分别具有最高后验概率的类别,即在给定词汇X下,贝叶斯网络法将待计算词汇分配给类别Ci,当且仅当
P(Ci|X)>P(Cj|X),i≠j (28)
3)根据贝叶斯定理有
由于P(X)对于所有类别都为常数,所以只需要P(X|Ci)P(Ci)最大即可,P(X|Ci)P(Ci)中类的先验概率P(Ci)可以由训练文本集估计得到,既可以用进行估计,其中si是类别Ci中的训练动机词汇的总数,s是全部训练动机词汇的总数,此时只需要对条件概率P(X|Ci)进行最大化处理;
4)根据朴素贝叶斯网络的类条件独立性假设,即动机词汇集中一个特征项对给定类的影响独立于其它特征项,则
式中:概率p(t1|Ci),p(t2|Ci),...,p(tn|Ci)的值同样可以由训练样本估计出来,主要表示类别Ci中出现tk的概率,具体为:
式中:count(tk|Ci)表示词汇特征tk在训练样本的类Ci中出现的次数,表示类Ci中出现的所有动机词汇特征的总次数。由于动机词汇向量空间的稀疏性,导致一些特征项在某些语料库中没有出现,这样不管别的特征项的条件概率有多高,都会导致为零,为了避免这种情况的出现,需要用Laplace平滑修正,表达式改为:
式中:n为动机词汇特征项的总个数,即特征向量空间的维数,δ为任意的非零实数通常设置为1;
5)根据贝叶斯网络分类器的判别规则,把待计算动机词汇X判给类C,当且仅当
通过以上几个步骤,采用贝叶斯网络法计算动机词汇间关联度,表达式为:
式中:pi和pj分别为动机词汇S1、S2的显著特征,D为横向关联影响深度,d(pi,pj)为动机词汇特征pi在语料库pj中出现的次数。则动机词汇间的相关性,可用其相关度表示,表达式为:
在此基础上,基于本体理论基上,按短语或者句子结构生成创意点,计算公式为:
式中:X≠φ,|X|表示动机词汇集合X的基数。当αR(X)=1时,其创意点为最优;当αR(X)=0时,其创意点为最差。
4实验结果分析
4.1实验参数设置
实验采用Reuters-21578语料库,该语料库一共包含22个文件,21578个动机词汇。为了把该语料库分为训练集和测试集,分为训练集9603个动机词汇,测试集3299个动机词汇,另有8676为未使用的动机词汇。将Reuters-21578的动机词汇分为135个类别,每个动机词汇最多可以属于14个类别,最少属于1个类别,在训练集中动机词汇数目最多的10个类别如表1所示:
表1在训练集中动机词汇数目最多的10个类别
对于一个类别和一个动机词汇来说,就是判断该动机词汇是否属于此类别。分别以召回率、准确率、错误率为指标进行分析,公式分别如下所示:
召回率:
准确率:
错误率:
式中:a为正确计算的动机词汇分类过滤创意点数目,b为错误计算的动机词汇分类过滤创意点数目,d正确计算该原本正确的动机词汇创意点数目,c错误计算该原本正确的动机词汇创意点数目。
4.2实验结果分析
为了验证改进方法的有效性及可行性,先采用改进方法与信息反馈法、启发式规则法为对比进行分析。则Reuters-21578训练集中10个动机词汇数目最大的类别,采用改进方法进行召回率和准确率的计算,结果如下表2所示:
表2 Reuters-21578训练集中10个动机词汇的召回率与准确率对比
由表1可知,Reuters-21578训练集中10个动机词汇,采用改进方法时平均召回率约为87.6%,平均准确率约为83.1%;其中acquisitions的召回率最高为97%,corn的召回率最低为63%;earnings的准确率最高为93%,corn的准确率最低70%;由此发现,在动机词汇训练数目和测试数目不同的情况下,会随着动机词汇的增加,召回率和准确率均会提高。
为了验证改进方法的有效性及可行性,先采用改进方法与信息反馈法、启发式规则法为对比进行分析。在数量一定的情况下,其召回率、准确率、错误率对比结果分别如下图3、图4、图5所示:
由图3可知,采用信息反馈法时,其召回率约为0.12,且随着动机词汇量的增加而降低;采用启发式规则法时,其召回率约为0.10,且对着动机词汇的增加在多处出现波动,不适合大面积范围使用;采用改进方法时,其召回率约为0.08,且随着动机词汇量的增加而降低,相比信息反馈法和启发式规则法,其召回率分别降低了0.04和0.02,具有一定的优势。
由图4可以看出,采用信息反馈法时,其准确率约为76.2%,且随着动机词汇量的增加,其准确度在200-400及600-800处出现了波动,稳定性较差;采用启发式规则法时,其准确率约为58.4%,且随着动机词汇量的增加,准确率为无大变化,相比信息反馈法,其准确率下降了17.8%;采用改进方法时,其准确率约为94.3%,虽然随着动机词汇量的增加,其准确率出现了多处波动,但其整体相比信息反馈法和启发式规则法提高了分别提高了约18.1%、35.9%,具有一定的优势。
由图5可以看出,采用信息反馈法时,其错误率约为32.2%,且随着动机词汇量的极速下降,其错误率在200-1000处出现了波动,稳定性较差;采用启发式规则法时,其错误率约为48.4%,且随着动机词汇量的增加,错误率无太大变化,相比信息反馈法,其错误率提高了16.2%;采用改进方法时,其错误率约为18.3%,虽然随着动机词汇量的增加,其错误率处于稳定状态,相比信息反馈法和启发式规则法分别降低了降低了约30.1%、13.9%,具有一定的优势。
5结论
针对传统的自动分类过滤法一直存在分类过滤不准确,效率低的问题,提出基于贝叶斯网络计算的动机词汇自动分类过滤方法。基于爬虫对动机词汇语料信息进行获取,通过建立向量空间模型对采集的信息进行聚类,并以此为依据,采用贝叶斯网络计算动机词汇之间的相关性,并在本体理论基础上按短语或者句子结构,对动机词汇进行分类过滤。实验结果证明,采用改进的方法进行动机词汇分类过滤,相比传统的分类过滤方法,其分类过滤精度高、效率好,具有一定的优势。
以上是本发明的较佳实施例,凡依本发明技术方案所作的改变,所产生的功能作用未超出本发明技术方案的范围时,均属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!