一种基于深度学习的非结构化数据处理方法与流程
本发明涉及非结构化数据处理方法,尤其是一种基于深度学习的非结构化数据处理方法,属于大数据处理技术领域。
背景技术:
随着大数据时代的到来,越来越多的非结构化数据受到人们的重视,尤其是符合大数据4V特性(数据容量大、数据类型繁多、商业价值高和处理速度快)的非结构化数据,如大量的视频数据、图片数据等。
以交通行业为例,如今道路上的视频监控设备和电子警察设备积累了大量的视频监控数据以及抓拍图像数据,这些非结构化数据中,包含人员、车辆、路网、环境等多种影响交通状况的信息,如何利用好这些数据来解决由于机动化和城市化进程加快带来的交通拥堵、交通事故频发等问题,成为了一个热门方向。
当今的非结构化数据的处理方式主要是模板匹配法,将现有的非结构化数据与已经完成处理的模板进行对比,从而找到最相似的模板,从中提取出相应有用的信息,但这种方法在处理大量非结构化数据时耗时长,并且没有那么大的模板库与之相应匹配。
技术实现要素:
针对上述现有技术存在的缺陷,本发明提供一种基于深度学习的非结构化数据处理方法,包含图像、视频等符合大数据4V特性(数据容量大、数据类型繁多、商业价值高和处理速度快)的非结构化数据,该方法包括以下步骤:1)非结构化数据的存储,基于Hadoop的大数据框架,可以很好解决非结构化数据的存储、管理、访问;2)非结构化数据的预处理,利用大数据平台的ETL能力,完成数据预处理(清洗、转换、挖掘、搜索等);3)非结构化数据的结构化处理,对非结构化数据内容按照语义关系,采用时空分割、特征提取、对象识别等处理手段,实现非结构化数据向信息、情报的转化;4)非结构化数据的处理能力提升,利用深度学习算法来替代手工获取特征分析,提升非结构化数据处理的准确性和合理性。
本发明的具体技术方案如下:
步骤1,非结构化数据的存储
本发明利用大数据平台来对非结构化数据进行存储,主要是基于Hadoop的大数据框架,解决视频数据的存储、管理、访问,具体方式如下:
步骤1.1,根据数据连通度选择共享交换方式将非结构化数据上传汇聚到大数据对象存储或通过在线存储服务访问方式配置非结构化数据采集任务;
步骤1.2,将需要采集的非结构化数据,基于Hadoop的大数据框架,完成大规模非结构化数据的分布式存储;
步骤1.3,利用图形化的配置界面对大规模非结构化数据进行统一管理。
步骤2,非结构化数据的预处理
本发明利用大数据平台的ETL能力,完成数据的清洗、转换、挖掘、搜索等基本处理,具体方式如下:
步骤2.1,从不同的数据库系统、网络系统、操作系统、数据格式中抽取数据;
步骤2.2,将抽取的数据根据规则进行计算、合并、拆分、编码转换等操作,清除重复数据、错误数据,清空稀疏的数据集;
步骤2.3,将已经处理后的数据加载到目标数据库,以供下一步骤的分析使用。
步骤3,非结构化数据的结构化处理
本发明对非结构化数据内容按照数据间的语义关系,采用时空分割、特征提取、对象识别等处理手段,实现非结构化数据向信息、情报的转化,具体做法如下:
步骤3.1,将非结构化数据根据数据线性序列的横向关系以及相同结构、相同位置之间的纵向结构,建立好非结构化数据的语义关系;
步骤3.2,将建立好语义关系的非结构化数据,根据非结构数据的时间和空间的差异,进行数据分割;
步骤3.3,将分割后的非结构化数据,通过影像分析和变换,将数据按照一定的规律生成不同的子集,形成一个个特征参数;
步骤3.4,根据特征提取的结果,利用定量描绘子提取的方式,提取出具体的结构化数据,定量描绘子包括长度、纹理和面积等。
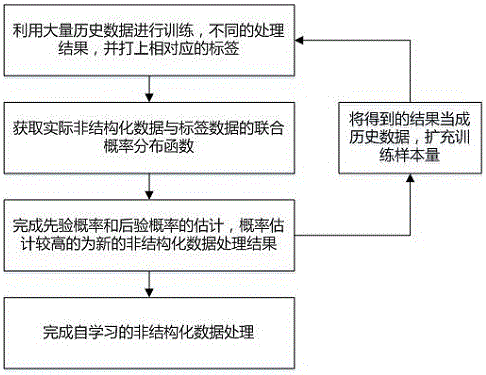
步骤4,非结构化数据的处理能力提升
本发明利用深度学习算法,对不同非结构化数据的结构化处理结果进行不断学习调整,提升非结构化数据处理的准确性和合理性,具体做法如下:
步骤4.1,利用大量历史数据进行训练,即将大量非结构化数据带入步骤3,得到多种不同的处理结果,并打上相对应的标签;
步骤4.2,新的非结构化数据中,将新的非结构化数据和步骤4.1训练的标签数据进行概率匹配,获取新的数据与标签数据的联合概率分布函数f(p);
步骤4.3,利用步骤4.2获取的联合概率分布,完成先验概率和后验概率的估计,概率估计较高的为新的非结构化数据处理结果;
步骤4.4,在今后的其他非结构化数据处理中,将步骤4.3得到的结果当成历史数据,扩大步骤4.1中的样本量,并重复上述操作,完成自学习的非结构化数据处理。
本发明的有益效果是:基于深度学习的非结构化数据处理方法,利用大数据平台,基于Hadoop的大数据框架,采用深度学习算法,完成符合大数据4V特性的图像、视频等非结构化数据的存储、预处理以及最终的结构化处理。该方法可以实现海量非结构化数据的存储,支持非结构化数据的批量实时处理,增强非结构化数据处理的效率,提高处理结果的准确性和合理性。
附图说明
图1 为本发明基于深度学习的非结构化数据处理方法总流程图。
图2 为本发明基于深度学习的非结构化数据处理能力提升流程图。
具体实施方式
以下结合附图对本发明的特征及其它相关特征作进一步详细说明。
如图1所示,提供一种基于深度学习的非结构化数据处理方法,包含图像、视频等符合大数据4V特性(数据容量大、数据类型繁多、商业价值高和处理速度快)的非结构化数据,该方法包括以下步骤:1)非结构化数据的存储,基于Hadoop的大数据框架,可以很好解决非结构化数据的存储、管理、访问;2)非结构化数据的预处理,利用大数据平台的ETL能力,完成数据预处理(清洗、转换、挖掘、搜索等);3)非结构化数据的结构化处理,对非结构化数据内容按照语义关系,采用时空分割、特征提取、对象识别等处理手段,实现非结构化数据向信息、情报的转化;4)非结构化数据的处理能力提升,利用深度学习算法来替代手工获取特征分析,提升非结构化数据处理的准确性和合理性。
结合道路上高清摄像头记录的视频数据为例,详细说明基于深度学习的非结构化数据处理方法的步骤:
步骤1,非结构化数据的存储
步骤1.1,将视频数据通过在线存储服务访问方式配置非结构化数据采集任务;
步骤1.2,将需要采集到的视频数据,基于Hadoop的大数据框架,完成视频数据在大数据平台上的分布式存储;
步骤1.3,利用图形化的配置界面对视频数据进行统一管理。
步骤2,非结构化数据的预处理
步骤2.1,从不同的数据库系统、网络系统、操作系统、数据格式中抽取出视频数据;
步骤2.2,将抽取的视频数据根据规则进行计算、合并、拆分、编码转换等操作,清除重复数据、错误数据,清空稀疏的数据集;
步骤2.3,将已经处理后的视频数据加载到目标数据库,以供下一步骤的分析使用。
步骤3,非结构化数据的结构化处理
步骤3.1,将视频数据根据数据线性序列的横向关系以及相同结构、相同位置之间的纵向结构,建立好非结构化数据的语义关系;
步骤3.2,将建立好语义关系的视频数据,根据视频数据的记录的时间和空间的不同,进行视频数据时空分割;
步骤3.3,将分割后的视频数据,通过影像分析和变换,将数据按照一定的规律生成不同的子集,形成一个个特征参数;
步骤3.4,根据特征提取的结果,利用定量描绘子提取的方式,提取出具体的结构化数据,定量描绘子包括车辆长度、纹理和面积等。
步骤4,非结构化数据的处理能力提升,如图2所示,具体流程如下:
步骤4.1,利用大量历史数据进行训练,即将大量视频数据带入步骤3,得到多种不同的处理结果,并打上相对应的标签;
步骤4.2,新的视频数据中,将新的视频数据和步骤4.1训练的标签数据进行概率匹配,获取新的数据与标签数据的联合概率分布函数f(p);
步骤4.3,利用步骤4.2获取的联合概率分布,完成先验概率和后验概率的估计,概率估计较高的为新的视频数据处理结果;
步骤4.4,在今后的其他视频数据处理中,将步骤4.3得到的结果当成历史数据,扩大步骤4.1中的样本量,并重复上述操作,完成自学习的视频数据处理。
- 还没有人留言评论。精彩留言会获得点赞!