基于正交与聚类修剪改进多目标遗传算法的电影推荐方法与流程
本发明属于个性化推荐技术领域。运用针对NSGA-II算法的不足进行改进的多目标遗传算法OTNSGA-II算法(具体涉及NSGA-II算法、断层多目标正交实验和自适应聚类修剪策略)来实现对电影的个性化推荐。
背景技术:
随着Internet技术的应用普及和现代电子商务的迅猛发展,充斥在互联网中的资源数量呈指数增长的态势。大量的信息同时呈现往往使得用户感觉无所适从,很难从中寻找到自己真正感兴趣的资源,从而出现了所谓的“信息爆炸”和“信息过载”现象。搜索引擎和信息检索技术就是为缓解信息过载问题而出现的。在信息化的今天,用户经常使用搜索引擎来寻找自己所需要的资源。然而传统的搜索引擎技术没有考虑用户的个性差异,将所有用户等同处理,返回给用户的资源都是一样的,同时由于反馈的信息量也非常大,使得用户很难选择到自己正在喜欢的资源。因此,如何根据每个用户的偏好特性,从互联网大量信息中寻找满足用户需求的信息,进而推荐给用户,已经成为当前一个亟待解决的研究问题。
个性化推荐系统(personlized recommender systems)就是在这种背景下应运而生的。它通过收集系统中用户的行为特征来获取用户的偏好特性,进而根据这些偏好特性从网络上的大量信息中挖掘用户潜在感兴趣的或者需要的资源,并作出相应的推荐。推荐问题实质上就是通过分析用户已选择的资源来预测用户对未选择资源(如音乐、电影、书籍、网页、饭店、旅游景点等等)的喜好程度,并将预测的结果以某种有效的形式展现给用户,比如将预测值较高的资源推荐给用户。
目前很多领域中推荐系统已得到广泛应用,日常生活中所常见的网站如:团购网、京东商城、淘宝网、唯品会、亚马逊、当当网等都是典型的推荐系统。而时下流行的去哪儿网、携程网等特色理念的网站,能否有效的寻找和拉拢客户,能否让客户依赖上该推荐系统,保持长期供给关系,能否从而提高销售业绩,也即能否选择到成熟有效的推荐系统关系到电子商务企业的生死存亡。此外,推荐系统领域一直被学术界当作热度研究课题之一,并已逐步独立成一门专业学科。
随着学术界、工程界以及商业界对推荐系统深入的研究,其他领域也广泛应用到推荐系统及其技术。现如今,推荐系统相关算法或将应用于包括图书馆的数据和网络信息检索以及数字电视收看之类的信息服务,甚至一些比较简单的推荐系统大都应用在诸如“豆瓣网”、“百度贴吧”的网络论坛中。可见经过多年的发展,推荐系统应用领域也将越来越宽泛,相关人员和学者对该领域的研究兴趣越来越大。
推荐系统性能完全取决于所选择的推荐算法。推荐的质量的好坏有很多的评价标准,比如推荐的精度,推荐的个性化程度,推荐的准确率、召回率等等。通常在某个或者某几个标准达到最优的时候,推荐质量比较好。科学研究和工程实践中许多优化问题都可归结为多目标优化问题(MOP),个性化推荐也是综合考虑多个方面的多目标优化问题。
多目标优化是近20多年来迅速发展起来的应用数学的一门新兴学科。它研究向量目标函数满足一定约束条件时在某种意义下的优化问题。由于现实世界的大量优化问题,都可归结为含有多个目标的优化问题,自70年代以来,对于多目标优化的研究,在国内和国际上都引起了人们极大的关注和重视。特别是近10多年来,理论探索不断深入,应用范围日益广泛,研究队伍迅速壮大,显示出勃勃生机。同时,随着对社会经济和工程设计中大型复杂系统研究的深入,多目标最优化的理论和方法也不断地受到严峻挑战并得到快速发展。多目标优化作为优化领域的一个重要的研究方向有其广泛的应用领域,研究求解其有效算法具有重大的科学意义和应用价值。
多目标进化算法的研究目的主要是使求得的解集尽最大可能接近问题的Pareto理想前沿,并且分布广泛而均匀,这就决定了评价算法的性能指标是分布性和收敛性两个方面。分布性和收敛性对于解决多目标优化问题具有重要的意义,良好的分布性能够给决策者提供更多合理有效的选择方案;良好的收敛性能够更加准确的求解实际问题的答案。近年来,进化计算领域相继提出了一些多目标进化算法。其中,最具有代表性的主要有:Zitzler和Thiele提出的SPEA(Strength Pareto Evolutionary Algorithm),Kim等人在其基础上提出的SPEA2,Srinivas和Deb提出的非支配排序遗传算法NSGA(Non-dominated Sorting Genetic Algorithm),以及Deb等在其基础上提出的NSGA-II,Corne等提出的PESA(Pareto Envelope-based Selection Algorithm)和PESA-II。NSGA-II是一种应用最为广泛的多目标进化算法,该算法的特点是根据个体间的Pareto支配关系和密度信息确定个体适应值,但是这样的适应度计算方式存在着分布性和收敛性维护不当的缺陷。文诗华等根据距离度量的方式保留一些具有代表性的个体对NSGA-II进行了改进,这种方式只考虑了拥挤距离对保持种群分布性的影响,没有从同类个体集合的角度全面考虑特征相近个体和劣质个体的存在造成的收敛性和分布性缺失的问题。针对NSGA-II这两方面的缺陷,本文提出了一种改进的收敛性和分布性保持策略,算法在进化之前,采用断层非支配排序和拥挤距离评价个体的方式设置多目标正交实验初始化种群,防止种群因随机初始化而容易陷入局部收敛或收敛过慢,并且避免了初始种群个体不均匀而导致分布性缺失;算法在进化过程中,对每一代的进化结果进行聚类,在类内根据相似度的大小动态调节修剪的力度,通过自适应的去除适当数目的特征相近并且非支配排序与拥挤距离较差的类内个体以及远离前沿面的少量个体进行种群维护,加快种群收敛的同时又保持了分布性。将该改进算法应用于电影个性化推荐的具体问题上,通过与NSGA-II以及基于用户的协同过滤推荐算法和基于内容的推荐算法等传统推荐算法在相同条件下进行对比实验,验证了算法的效果。
技术实现要素:
本发明的目的是提出一种基于正交与聚类修剪的改进多目标遗传算法用于电影个性化推荐中TOP-N这一实际问题的解决,以N部电影用户行为预测评分和N部电影属性预测评分为两个目标进行优化,实现个性化推荐。
本发明的基于正交与聚类修剪的改进多目标遗传算法(OTNSGA-II),其特征在于:算法在进化之前,采用断层非支配排序和拥挤距离评价个体的方式设置多目标正交实验初始化种群,防止种群因随机初始化而容易陷入局部收敛或收敛过慢,并且避免了初始种群个体不均匀而导致分布性缺失;算法在进化过程中,对每一代的进化结果进行聚类,在类内根据相似度的大小动态调节修剪的力度,通过自适应的去除适当数目的特征相近并且非支配排序与拥挤距离较差的类内个体以及远离前沿面的少量个体进行种群维护,加快种群收敛的同时又保持了分布性。
基于正交与聚类修剪改进多目标遗传算法的电影推荐方法,包括以下步骤:
S1进行个体编码、初始化数据,并设定参数
所述个体表示N个电影的编号,其中N表示需要推荐的电影个数;用di表示第i个需要推荐的电影编号,为了应用于解决个性化推荐领域的TOP-N问题,采用N个电影编号组合,个体编码形式为:<d1,d2,di。。。dN>,采用实数编码方式,编码范围为电影编号所在的范围并且为整数形式;所述初始化数据将种群大小初始化为popszie,每次后代都产生popsize大小的种群;所述设定参数包括:设定交叉概率Pc为0.9,变异概率Pm为0.1,个体长度为N位,保持编码中电影编号有序且不重复,以作为待推荐的N部不同电影的一种组合方式。
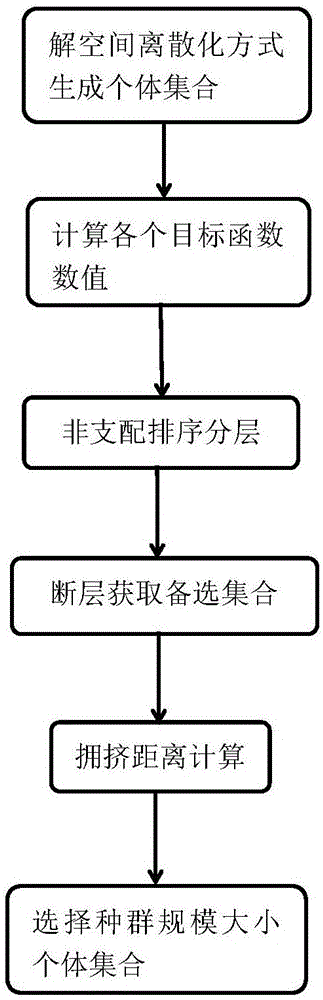
S2断层多目标正交实验方式初始化种群
S2.1采用的是按照以下解空间离散化方式生成M个N位个体,组成临时初始种群P;
S2.1.1找到满足下式的第s维;
S2.2.2若可行解空间为[l,u],l、u是两个具体数字,分别表示可行解的上界和下界,则在第S维处将可行解空间分割成S个子空间:
[l(1),u(1)],[l(2),u(2)]...[l(S),u(S)]
其中,Is=[c1,j]1×N,Is表示一个列向量,用于计算l(i)和u(i)的具体数值,c1,j是一个根据j的取值确定的0或1的数字j=1,2,...S,用于组成列向量Is的一个元素。
上述步骤过程中由于涉及电影编号作为编码的基因位,对各个个体中的N个基因位采用取整操作,并保持个体中不出现重复的电影编号;如果出现重复的电影编号,对该编号进行去除,并补充为不重复的其他电影编号。
S2.2对种群P中的各个个体计算在待优化问题中各个目标的数值fit,表示为第i个个体在第t个目标函数上的数值。
S2.3对种群P中的每个个体按照各个目标数值fit之间的优劣关系进行非支配排序分层的计算,并标记每个个体所在的层级Si,表示为第i个个体所在的层级。
S2.4根据层级排名从第一层开始一层一层依次获取个体放入另一个集合中,直到这个集合的个体数目大于或等于4*popszie;如果种群P的个体数目小于4*popszie取该种群个体全集,此时集合中的不同层数个数为m,这个集合即为备选集合,其中,popszie为种群个体数目。
S2.5以备选集合为全集空间,对备选集合中的每个个体计算拥挤距离di,表示为第i个个体拥挤距离的数值。
S2.6在备选集合中,以每个个体的非支配排序层级Si与拥挤距离di作为两个目标,评价个体之间的非支配关系来选择最优的前popszie个个体生成初始种群P0。
S3选择操作
以锦标赛的方式进行个体选择,即从这popszie个个体中随机选择k,k<popszie个个体,这里取k为n/2(取整),从这k个个体中选取一个最优个体。
选择标准为以非支配排序所在层数Si和拥挤距离数值di作为两个目标,按照非支配优胜关系,对各个个体进行比较,比较优胜的个体为较优个体。
S4交叉操作
交叉操作使用SBX交叉算子,假设当前代(进化过程中的第t代)待交叉的两个个体为XAt、XBt,α为交叉涉及的参数(取值范围为0~1),则XAt+1、XBt+1为下一代产生的两个个体。形式如下:
S5变异操作
对进过过程中的第gen代种群Pgen中的任一个体pi=(pi1,pi2…piN),i∈{1,2,…n},以概率Pm参与变异操作:产生一个小数r∈[0,1],和一个随机整数j∈[1,N];令pi,j=lj+r*(uj-lj),对群体Pgen进行变异产生新种群PgenNew。
S6自适应聚类局部修剪策略
S6.1设种群PgenNew中有popszie个个体,使用K-means聚类算法对该种群进行聚类,得到k个类;
S6.2对S6.1中聚类结果的k个类中的类内两两个体之间计算相似度,然后计算类内的平均相似度Pk;
S6.3根据S6.2中计算的各个类中的类内平均相似度Pk自适应的计算各个类中保留的个体数目,保留类内个体数目的百分比计算公式参考如下,其中,修剪参数δ为0.12~0.15;
1-δ*Pk
S6.4按照S6.3中计算的保留个体数目,修剪掉非支配分层排名与拥挤距离计算较差以及远离理想前沿面的少量个体;
S6.5将这些修剪后剩下的个体重新组成新的种群PgenNew,继续执行下一代的进化过程。
S7终止条件判断
若达到规定的代数或者得到满意的结果,则结束并输出结果,否则转S3步骤。
S8进入下一遗传循环
将种群PgenNew作为下一代进化的初始种群,继续进行S3步骤。
以上为基于正交与聚类修剪的改进多目标遗传算法的主要流程步骤,使用该算法流程应用于电影个性化推荐问题得到电影的推荐列表。
与现有技术相比,本发明具有如下有益效果。
基于正交与聚类修剪的改进多目标遗传算法,算法在进化之前,采用断层非支配排序和拥挤距离评价个体的方式设置多目标正交实验初始化种群,防止种群因随机初始化而容易陷入局部收敛或收敛过慢,并且避免了初始种群个体不均匀而导致分布性缺失;算法在进化过程中,对每一代的进化结果进行聚类,在类内根据相似度的大小动态调节修剪的力度,通过自适应的去除适当数目的特征相近并且非支配排序与拥挤距离较差的类内个体以及远离前沿面的少量个体进行种群维护,加快种群收敛的同时又保持了分布性。通过将该改进算法应用于电影个性化推荐的具体问题上,与NSGA-II以及基于用户的协同过滤推荐算法和基于内容的推荐算法这两种传统的推荐算法在相同条件下进行对比实验,验证了算法的实用效果。
附图说明
图1为基于正交与聚类修剪的改进多目标遗传算法的流程图。
图2为断层多目标正交实验设计初始化种群主要流程图。
图3为自适应聚类修剪策略主要流程图。
图4为本发明总体实施方法流程图。
图5为基于用户的协同过滤推荐算法主要流程图。
图6为基于内容的推荐算法主要流程图。
具体实施方式
下面结合附图和具体实施例对本发明做进一步说明。
本发明选用Movielens作为电影推荐的数据集,该数据集涉及100,000条电影评分,943个用户以及1682部电影。将基于用户的协同过滤算法(UserCF)、基于内容的推荐算法(CB)、NSGA-II以及OTNSGA-II四个算法进行对比实验。
在NSGA-II和OTNSGA-II两种多目标优化算法中,编号方式为N部电影的电影序号(这里N取值为5,10,15,20),编号限制为有序不重复,两者的运行代数gen为100,种群规模popsize为50,设定交叉概率Pc为0.9,变异概率Pm为0.1,以使用用户相似度矩阵中最相近的K个用户计算N部电影编号对应的预测评分之和以及使用电影属性相似度矩阵计算相似电影得到的N个电影编号对应的预测评分之和作为两个优化目标函数。对于已经使用上述两种方式计算出来的单部电影预测评分记录下来,下次计算同样的电影编号对应的电影评分则不需要计算,直接读取该评分数值求和即可。以常用的推荐评价标准准确率、召回率和覆盖率以及推荐方案的丰富程度作为指标来验证算法的效果。其中,准确率、召回率和覆盖率的计算方法如下:
假设在测试集I上对n个用户进行推荐测试,令用户i喜欢的物品集合为L(i),令R(i)表示对用户i推荐的物品的集合。
准确率指标则是相对应推荐系统而言的,准确率指标可以用以下数学公式进行表示:
上式中,|R(i)|表示的是推荐列表中物品的个数。由上式可见,准确率描述的是推荐列表中用户喜欢的物品的个数占整个推荐列表的比例。通常商家希望给用户推荐的物品尽可能都是用户喜欢的物品,所以通常认为准确率越高越好。
召回率则可以用以下数学公式进行表示:
上式中,|R(i)∩L(i)|表示推荐列表和用户i喜欢列表中重叠的部分的物品的个数,从上述召回率公式可以看出召回率是针对用户而言的,召回率计算的是推荐列表中用户喜欢的物品个数占用户整个喜欢列表的比例。
覆盖率描述的是推荐列表占据总物品的比例,覆盖率可以用以下数学公式进行表示:
本发明提出的基于正交与聚类修剪的改进多目标遗传算法的主要流程如图1所示,整个流程运用断层多目标正交实验设计初始化种群以及自适应聚类修剪策略维护种群的分布性和收敛性。主要分为断层多目标正交实验设计初始化种群、选择操作、交叉操作、变异操作、自适应聚类修剪策略五个部分,其中,断层多目标正交实验设计初始化种群主要流程如图2所示,自适应聚类修剪策略主要流程如图3所示。选择、交叉、变异三个操作流程与NSGA-II算法的操作流程一致。
结合图4对本发明的实施过程作详细的说明。本发明的实施例是在以本发明技术方案为前提进行实施的,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述实施例。
实施例选用电影个性化推荐问题对本文中提出的多目标改进算法OTNSGA-II和基于用户的协同过滤算法(UserCF)、基于内容的推荐算法(CB)以及NSGA-II进行测试和比较。通过比较可以看出在同一实验条件下不同算法在处理相同问题的性能状态。
其中,基于用户的协同过滤算法(UserCF)根据用户所看电影的评分数值,计算两两用户之间的相似度,并选出与待推荐用户的相似度从大到小排序前K个用户,以这些相似度数值为权重,利用这些用户已看过并评分的电影对待推荐的用户未看过的电影进行预测评分。主要流程如图5所示。
基于内容的推荐算法(CB)根据电影类型的所属关系计算各个电影之间的相似度大小,并对待推荐的用户已经看过的电影评分比较高的电影,按照与之相似度大小对未看过的电影进行预测评分。主要流程如图6所示。
在这一实施例中,对于NSGA-II和OTNSGA-II而言,以使用用户相似度矩阵中最相近的K个用户计算N部电影编号对应的预测评分之和以及使用电影属性相似度矩阵计算相似电影得到的N个电影编号对应的预测评分之和作为两个优化目标函数。对于已经使用上述两种方式计算出来的单部电影预测评分记录下来,下次计算同样的电影编号对应的电影评分则不需要计算,直接读取该评分数值求和即可。目的在于求解N个不同电影的编号组合,即每个个体的基因位为一部电影的编号,用di表示i部待推荐电影的编号,个体编码形式为:<d1,d2,di。。。dN>,采用实数编码方式,编码范围为电影编号所在的范围并且为整数形式,保持编码中电影编号有序且不重复,以作为待推荐的N部不同电影的一种组合方式。
下面详细给出该发明技术方案中所涉及的各个细节问题的说明:
S1进行个体编码、初始化数据,并设定参数
所述个体表示N个电影的编号,其中N表示需要推荐的电影个数;用di表示第i个需要推荐的电影编号,为了应用于解决个性化推荐领域的TOP-N问题,采用N个电影编号组合,个体编码形式为:<d1,d2,di。。。dN>,采用实数编码方式,编码范围为电影编号所在的范围并且为整数形式;所述初始化数据将种群大小初始化为popszie,每次后代都产生popsize大小的种群;所述设定参数包括:设定交叉概率Pc为0.9,变异概率Pm为0.1,个体长度为N位,保持编码中电影编号有序且不重复,以作为待推荐的N部不同电影的一种组合方式。
S2断层多目标正交实验方式初始化种群
S2.1采用的是按照以下解空间离散化方式生成M个N位个体,组成临时初始种群P;
S2.1.1找到满足下式的第s维;
S2.2.2若可行解空间为[l,u](l、u是两个具体数字,分别表示可行解的上界和下界),则在第s维处将可行解空间分割成S个子空间:
[l(1),u(1)],[l(2),u(2)]...[l(S),u(S)]
其中,Is=[c1,j]1×N,Is表示一个列向量,用于计算l(i)和u(i)的具体数值,c1,j是一个根据j的取值确定的0或1的数字(j=1,2,...S),用于组成列向量Is的一个元素。
上述步骤过程中由于涉及电影编号作为编码的基因位,对各个个体中的N个基因位采用取整操作,并保持个体中不出现重复的电影编号(如果出现重复的电影编号,对该编号进行去除,并补充为不重复的其他电影编号)。
S2.2对种群P中的各个个体计算在待优化问题中各个目标的数值fit,表示为第i个个体在第t个目标函数上的数值。
S2.3对种群P中的每个个体按照各个目标数值fit之间的优劣关系进行非支配排序分层的计算,并标记每个个体所在的层级Si,表示为第i个个体所在的层级。
S2.4根据层级排名从第一层开始一层一层依次获取个体放入另一个集合中,直到这个集合的个体数目大于或等于4*popszie(如果种群P的个体数目小于4*popszie取该种群个体全集),此时集合中的不同层数个数为m,这个集合即为备选集合,其中,popszie为种群个体数目。
S2.5以备选集合为全集空间,对备选集合中的每个个体计算拥挤距离di,表示为第i个个体拥挤距离的数值。
S2.6在备选集合中,以每个个体的非支配排序层级Si与拥挤距离di作为两个目标,评价个体之间的非支配关系来选择最优的前popszie个个体生成初始种群P0。
S3选择操作
以锦标赛的方式进行个体选择,即从这popszie个个体中随机选择k(k<popszie)个个体,这里取k为n/2(取整),从这k个个体中选取一个最优个体。
选择标准为以非支配排序所在层数Si和拥挤距离数值di作为两个目标,按照非支配优胜关系,对各个个体进行比较,比较优胜的个体为较优个体。
S4交叉操作
交叉操作使用SBX交叉算子,假设当前代(进化过程中的第t代)待交叉的两个个体为XAt、XBt,α为交叉涉及的参数(取值范围为0~1),则XAt+1、XBt+1为下一代产生的两个个体。形式如下:
S5变异操作
对进过过程中的第gen代种群Pgen中的任一个体pi=(pi1,pi2…piN),i∈{1,2,…n},以概率Pm参与变异操作:产生一个小数r∈[0,1],和一个随机整数j∈[1,N];令pi,j=lj+r*(uj-lj),对群体Pgen进行变异产生新种群PgenNew。
S6自适应聚类局部修剪策略
S6.1设种群PgenNew中有popszie个个体,使用K-means聚类算法对该种群进行聚类,得到k个类;
S6.2对S6.1中聚类结果的k个类中的类内两两个体之间计算相似度,然后计算类内的平均相似度Pk;
S6.3根据S6.2中计算的各个类中的类内平均相似度Pk自适应的计算各个类中保留的个体数目,保留类内个体数目的百分比计算公式参考如下,其中,修剪参数δ为0.12~0.15;
1-δ*Pk
S6.4按照S6.3中计算的保留个体数目,修剪掉非支配分层排名与拥挤距离计算较差以及远离理想前沿面的少量个体;
S6.5将这些修剪后剩下的个体重新组成新的种群PgenNew,继续执行下一代的进化过程。
S7终止条件判断
若达到规定的代数或者得到满意的结果,则结束并输出结果,否则转S3步骤。
S8进入下一遗传循环
将种群PgenNew作为下一代进化的初始种群,继续进行S3步骤。
以上为基于正交与聚类修剪的改进多目标遗传算法的主要流程步骤,使用该算法流程应用于电影个性化推荐问题得到电影的推荐列表。
下面详述说明本发明的实验结果:
为了证明本发明所述方法在电影个性化推荐问题中的有效性,分别采用OTNSGA-II(本发明中的方法)和UserCF、CB以及NSGA-II对电影个性化推荐中的TOP-N问题进行优化,其中,N为一个组合中推荐电影的个数(这里分别取值为5、10、15、20)。实验结果如表1所示(其中加粗字体为表现较好的实验数据)。
表1 OTNSGA-II与UserCF、CB以及NSGA-II的准确率、召回率和覆盖率对比
由表1可知,采用OTNSGA-II(本发明中的方法)在N=5、10、15、20的条件下都可以有效的提高推荐的准确率、召回率和覆盖率,而NSGA-II在这两方面则表现较差,UserCF和CB这两种传统的推荐方法相比OTNSGA-II则更差。这充分说明针对NSGA-II改进的本发明方法OTNSGA-II得到的推荐结果比NSGAII方法在提高准确率、召回率和覆盖率方面有所提高,也明显优于UserCF、CB两种传统的推荐方法。因此,与现有技术相比,本发明可以得到更为优良的推荐结果,提高了推荐的准确率、召回率和覆盖率,有利于充分挖掘用户的兴趣点提供更为可靠的推荐服务。
对于推荐的组合方案而言,使用OTNSGA-II(本发明中的方法)和UserCF、CB以及NSGA-II算法得到的组合方式实验结果如表2所示(其中加粗字体为表现较好的实验数据)。
表2 OTNSGA-II与UserCF、CB以及NSGA-II的推荐方案丰富程度对比
由表2可知,使用OTNSGA-II(本发明中的方法)比NSGAII可以得到更为多样的解决方案,并且综合考了用户历史行为与电影属性本身的特点进行推荐,使得推荐更加全面和个性化;而UserCF和CB这两种传统的推荐方法只能得到一种解决方案,这种推荐方式不仅单调而且忽略用户的个性化喜好,并且这种推荐方式更多的依赖于同一种推荐方式的计算结果,容易造成一致性的错误偏差。对于OTNSGA-II得到的这些解决方案而言,从多目标优化的角度来看都是非劣的,即相互之间是等同的优劣关系,商家可以根据不同的解决方案提供更为多样的电影推荐组合,用户可以根据不同的解决方案选择更适合自己当前兴趣的电影组合进行观看,使得推荐结果更加准确和实用。
- 还没有人留言评论。精彩留言会获得点赞!