混合的深度神经网络CNN和RNN的主题句识别方法与流程
本发明涉及文本挖掘领域,更具体地,涉及一种混合的深度神经网络CNN和RNN的主题句识别方法。
背景技术:
近年来,随着经济的发展,越来越多的人开始去旅游来丰富自己的精神生活。确实,旅游,不仅可以放松一下,让我更加快乐还可以拓展视野。根据国家旅游局公布的数据显示,旅游业对GDP的贡献率已经超过10%。目前,旅游已经成为日程生活中很重要的一部分。在因特网时代,许多人开始通过微博,社交网站以文本的形式分享旅游经验。
一般来说,游记中大部分在描述旅行中的所见所闻并发表自己对这些景点的看法以及对后来的游客一些建议,但是还是会参差一些无关的内容。能否识别出这些主题句子,对于成功的挖掘出旅游中的知识是非常重要的。因为这些无关的内容会对结果造成一定的噪音影响。
例如:在蚂蜂窝中的描述广州的游记中,有人写到:“感谢你的关注和支持,如果觉得本篇文章值得分享,请推荐给你的朋友或微信群,以及分享在自己的朋友圈里”。这很明显描述的不是旅游中的所见所闻,自然也就不是主题句,这些句子无疑对对文本分析相当于加入一定的噪音。再如,有人写到:“入夜的花城广场灯火通明,可眺“小蛮腰”五彩斑澜,比白天更加迷人”。这很明显就是主题句,其中描述着广州的珠江新城的夜景。正是这些主题句的内容才是关注的重点。
在进行旅行推荐的时候,游客们在广州的游记中并不会仅仅提到广州,还会提到在广州周边的城市,例如:香港,珠海,深圳等城市的所见所闻,对这些景点的描述和评论的去除对后来的知识发现有着重要的意义。因为LDA模型的缺点之一就是在于其对噪音比较敏感。也就是说,噪音对结果的影响非常大。
因此,在游记中,大部分的句子都是阐述旅行中的景点和对这些景点进行评论的句子,如何正确的识别出这些主题语句是当前的一个挑战性的课题。
技术实现要素:
本发明提供一种更好效果的混合的深度神经网络CNN和RNN的主题句识别方法。
为了达到上述技术效果,本发明的技术方案如下:
一种混合的深度神经网络CNN和RNN的主题句识别方法,包括以下步骤:
S1:利用搜狗实验室中的全网新闻数据集训练出词向量,使得每个相近词在空间上的距离相近;
S2:从百度旅游网站和蚂蜂窝旅游网站各爬取600篇的游记,对游记分割成句子,将这些句子分为训练集和测试集并且按照8:2的比例进行划分,然后对于训练集根据信息熵和互信息的计算公式计算出每个词的信息熵值和互信息值;
S3:对于训练集中每个句子根据S1计算出的词向量和S2计算出的信息熵和互信息来构建特征,作为构建的混合深度神经网络CNN_RNN的输入,获取到参数;
S4:同样的对测试集中每个句子根据S1计算出的词向量和S2计算出的信息熵和互信息来构建特征,输入到深度神经网络CNN_RNN中,利用S3得到的参数,计算出其类别,得出标准结果和预测的误差,评价其性能。
进一步地,所述步骤S1的具体过程如下:
S11:首先下载搜狗实验室中全网新闻数据集,并且对数据集进行清洗,得出每条完整的新闻;
S12:对数据集进行分词,写入到文件中,词与词之间用“\t”分开,新闻和新闻之间用”\n”分开;
S13:调用python的gensim中的word2vec工具,对词进行无监督的训练,得到其词向量表示。
进一步地,所述步骤S2的具体过程如下:
S21:对于训练集中每个句子进行分词,去除停用词,对每个句子得到一个词的集合,统计出主题句中每个词的出现频数和非主题句中每个词的出现频数;
S22:计算出每个词的信息熵值IG,公式计算如下:
其中,K是系数,n代表类别个数,pi代表每个词出现在类别i的概率,同时,设定频数阈值,对于频数小于3的词,不考虑其值;
S23:计算出每个词的在不同类别中互信息值,公式计算如下:
对于“愉悦”这个词来说,p(愉悦,主题句)表示愉悦出现在主题句中的次数,同理p(愉悦,非主题句)代表“愉悦”这个词出现在非主题句中的次数;
对每个词的PMI值计算公式如下:
PMI(愉悦)=PMI(愉悦,主题句)/PMI(愉悦,主题句)。
进一步地,所述步骤S3的具体过程如下:
S31:根据之前得出每个词的词向量200个维度,信息熵IG和互信息值PMI,因此每个词总共202个特征,对于训练集中,选择最大的那个句子中词个数作为标准,比如,这个句子中有200个词。那么就有200*202个特征表示,对于句子中词不够的,也就是说句子中的词个数不足200的,比如说是100个词,那么实际上有100*202个特征,不足的用0补充也就需要(200-100)*202个值;
S32:对于每个句子向量,得到200*202个特征,首先,先进入到卷积神经网络层,计算公式的:
其中代表第l卷积层第j个特征图,右边表示上一层的结果和第j个卷积核进行卷积,并加上偏置向量最后加入激活函数;
S33:经过上述的输入200*202向量,假设设置一个卷积核,卷积核大小为3,那么经过S32的输出是198个维度,接着,输入到卷积神经网络CNN中池化层,其计算公式是:
在这里,对上述的每个特征图是198个维度,取最大值,就变成1个维度,但是实际上,对每个句子设定n个特征图,因此,每个句子有n特征;
S34:对于上述卷积神经网络CNN的结果,对每个句子形成n个特征,把这个作为循环神经网络RNN的输入,计算隐藏节点的向量,计算公式是:
ht=f(xtU+ht-1W+bt)
其中,xt是输入,U是输入到隐藏节点的变换,ht-1代表上一层的隐藏节点,W代表隐藏层到隐藏层的变换,b是偏置向量,最后加上f激活函数;
S35:由于RNN主要处理的是时间序列模型,因此其分类在最后一步,输出的计算公式是:
ot=soft max(htV+bt)
ot代表输出,其中V是代表隐藏层到输出层的变换,最后加上softmax函数即可;
S36:在计算出结果后,将误差和真实误差进行对比,计算损失函数,然后逐步调整参数,使得损失函数最小。
进一步地,所述步骤S4的具体过程如下:
S41:对于测试集中的每个句子,进行分词,去停用词,获得每个词的词向量,信息熵,互信息值,对于句子中不足200个词的用0进行补充;
S42:对每个句子表示成200*202个形式,输入到CNN_RNN模型中,得到每个句子的类别;
S43:对模型输出的结果和标准结果进行对比,计算精确度,召回率,F检验值和准确率。
与现有技术相比,本发明技术方案的有益效果是:
本发明方法利用搜狗实验室中的全网新闻数据集训练出词向量,使得每个相近词在空间上的距离相近;并从百度旅游网站和蚂蜂窝旅游网站各爬取600篇的游记,对游记分割成句子,将这些句子分为训练集和测试集并且按照8:2的比例进行划分,然后对于训练集根据信息熵和互信息的计算公式计算出每个词的信息熵值和互信息值;然后,对于训练集中每个句子根据计算出的词向量和计算出的信息熵和互信息来构建特征,作为构建的混合深度神经网络CNN_RNN的输入,获取到参数;同时,对测试集中每个句子根据计算出的词向量和计算出的信息熵和互信息来构建特征,输入到深度神经网络CNN_RNN中,利用得到的参数,计算出其类别,得出标准结果和预测的误差,评价其性能,试验证明该方法具有良好了识别效果。
附图说明
图1为本发明方法流程图;
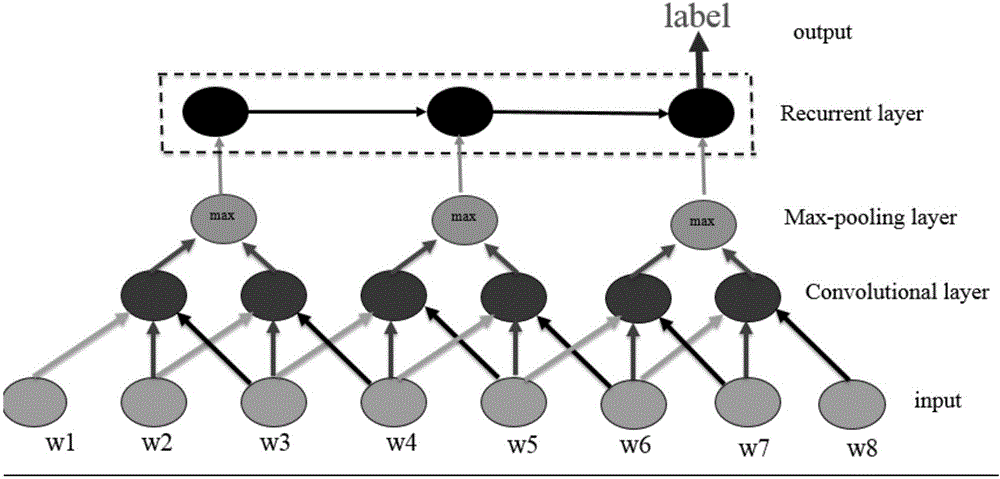
图2为本发明构建的CNN_RNN模型结构示意图;
图3为本发明中提出的信息熵特征对分类结果的影响效果直方图;
图4为本发明中提出的分类模型和传统的SVM和xgboost分类效果的对比直方图。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;
为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;
对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
下面结合附图和实施例对本发明的技术方案做进一步的说明。
实施例1
如图1所示,一种混合的深度神经网络CNN和RNN的主题句识别方法,包括以下步骤:
S1:利用搜狗实验室中的全网新闻数据集训练出词向量,使得每个相近词在空间上的距离相近;
S2:从百度旅游网站和蚂蜂窝旅游网站各爬取600篇的游记,对游记分割成句子,将这些句子分为训练集和测试集并且按照8:2的比例进行划分,然后对于训练集根据信息熵和互信息的计算公式计算出每个词的信息熵值和互信息值;
S3:对于训练集中每个句子根据S1计算出的词向量和S2计算出的信息熵和互信息来构建特征,作为构建的混合深度神经网络CNN_RNN的输入(构建的模型如图2),获取到参数;
S4:同样的对测试集中每个句子根据S1计算出的词向量和S2计算出的信息熵和互信息来构建特征,输入到深度神经网络CNN_RNN中,利用S3得到的参数,计算出其类别,得出标准结果和预测的误差,评价其性能。
进一步地,所述步骤S1的具体过程如下:
S11:首先下载搜狗实验室中全网新闻数据集,并且对数据集进行清洗,得出每条完整的新闻;
S12:对数据集进行分词,写入到文件中,词与词之间用“\t”分开,新闻和新闻之间用”\n”分开;
S13:调用python的gensim中的word2vec工具,对词进行无监督的训练,得到其词向量表示。
进一步地,所述步骤S2的具体过程如下:
S21:对于训练集中每个句子进行分词,去除停用词,对每个句子得到一个词的集合,统计出主题句中每个词的出现频数和非主题句中每个词的出现频数;
S22:计算出每个词的信息熵值IG,公式计算如下:
其中,K是系数,n代表类别个数,pi代表每个词出现在类别i的概率,同时,设定频数阈值,对于频数小于3的词,不考虑其值;
S23:计算出每个词的在不同类别中互信息值,公式计算如下:
对于“愉悦”这个词来说,p(愉悦,主题句)表示愉悦出现在主题句中的次数,同理p(愉悦,非主题句)代表“愉悦”这个词出现在非主题句中的次数;
对每个词的PMI值计算公式如下:
PMI(愉悦)=PMI(愉悦,主题句)/PMI(愉悦,主题句)。
进一步地,所述步骤S3的具体过程如下:
S31:根据之前得出每个词的词向量200个维度,信息熵IG和互信息值PMI,因此每个词总共202个特征,对于训练集中,选择最大的那个句子中词个数作为标准,比如,这个句子中有200个词。那么就有200*202个特征表示,对于句子中词不够的,也就是说句子中的词个数不足200的,比如说是100个词,那么实际上有100*202个特征,不足的用0补充也就需要(200-100)*202个值;
S32:对于每个句子向量,得到200*202个特征,首先,先进入到卷积神经网络层,计算公式的:
其中代表第l卷积层第j个特征图,右边表示上一层的结果和第j个卷积核进行卷积,并加上偏置向量最后加入激活函数;
S33:经过上述的输入200*202向量,假设设置一个卷积核,卷积核大小为3,那么经过S32的输出是198个维度,接着,输入到卷积神经网络CNN中池化层,其计算公式是:
在这里,对上述的每个特征图是198个维度,取最大值,就变成1个维度,但是实际上,对每个句子设定n个特征图,因此,每个句子有n特征;
S34:对于上述卷积神经网络CNN的结果,对每个句子形成n个特征,把这个作为循环神经网络RNN的输入,计算隐藏节点的向量,计算公式是:
ht=f(xtU+ht-1W+bt)
其中,xt是输入,U是输入到隐藏节点的变换,ht-1代表上一层的隐藏节点,W代表隐藏层到隐藏层的变换,b是偏置向量,最后加上f激活函数;
S35:由于RNN主要处理的是时间序列模型,因此其分类在最后一步,输出的计算公式是:
ot=soft max(htV+bt)
ot代表输出,其中V是代表隐藏层到输出层的变换,最后加上softmax函数即可;
S36:在计算出结果后,将误差和真实误差进行对比,计算损失函数,然后逐步调整参数,使得损失函数最小。
进一步地,所述步骤S4的具体过程如下:
S41:对于测试集中的每个句子,进行分词,去停用词,获得每个词的词向量,信息熵,互信息值,对于句子中不足200个词的用0进行补充;
S42:对每个句子表示成200*202个形式,输入到CNN_RNN模型中,得到每个句子的类别;
S43:对模型输出的结果和标准结果进行对比,计算精确度,召回率,F检验值和准确率。
利用该方法进行试验:
1、实验数据集:百度旅游和蚂蜂窝上的1200篇游记;
2、实验环境:Python2.7.9和tensorflow;
3、实验工具集:Python开源工具箱;
4、实验方法:抓取的数据集包括1200篇相关的广州游记,每篇游记的长度从2000到20000字数不等,一篇游记分割成的句子从20到500至今。通过对游记进行分割,获得总共50000条的句子。这些句子总共包含100000个词,进行人工的将它们标注为主题句还是非主题句,类别数为2。
首先每个句子中的每个词根据训练好的word2vec模型获取其对应的200维词向量,对于句子中没有出现的词,随机产生。为训练集中的每个词计算一个点互信息值PMI和信息熵值,在对每个句子我们产生一个202句子词的个数的向量。我们对每个句子以35作为标准,不足35的用0来补充。这些预处理在模型中,我们已经详细描述,我们不在重复。
首先对我们的模型的结合和单个模型卷积神经网络CNN或者循环神经网络RNN进行对比,并对信息熵和互信息特征提取方式的加入分别进行效果的对比。图3主要展示的是不同的模型对效果的评价,为了比较方便,RNN都是两层的LSTM单元。
5、评价标准:精确率,召回率,F值,准确率
6、实验结果:如图4所示,为了比较模型和传统的分类器的性能,我们采用SVM算法和xgbosot算法来进行对比。在传统分类器中,SVM和xgboost是被分别公认为是最好的单分类器和集成分类器。
可以发现我们的模型可以获得非常好的效果相对于别的模型来说。
相同或相似的标号对应相同或相似的部件;
附图中描述位置关系的用于仅用于示例性说明,不能理解为对本专利的限制;
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!