一种搜索关键词获取的方法及装置与流程
本发明实施例涉及信息处理技术领域,尤其涉及一种搜索关键词获取的方法及装置。
背景技术:
随着互联网的快速发展,人们逐渐通过依靠互联网搜索的结果作为获取信息的入口。通过对用户搜索关键词的分析,可以获得用户的兴趣所在以及关注的热点,更可以挖掘出用户自身的偏好以及业务的潜在关联项目。
目前的搜索关键词获取的方法,大多是直接在搜索框中输入的文本中提取预设个数的关键词作为搜索关键词,如将输入的文本进行分词,将分词后获得的候选关键词排序,提取预设个数的候选关键词作为用户的搜索关键词。具体的,若用户在搜索框中键入“汽车模具”或“汽车维修”,则会将“汽车”和“模具”或“汽车”和“维修”作为搜索关键词。
然而,上述方法中,在分析用户的兴趣时,会将获得的所有关键词均作为用户的兴趣所在,如若输入的文本为“汽车模具”,会将“汽车”以及“模具”均作为用户的兴趣,然而用户的兴趣重点在于“模具”,而不是“汽车”,使得通过用户搜索关键词不能准确地确定用户的兴趣及关注的热点。
技术实现要素:
本发明提供一种搜索关键词获取的方法及装置,以实现根据用户输入的文本信息比较准确地输出与用户的某一兴趣或需求相关的关键词。
第一方面,本发明实施例提供了搜索关键词获取的方法,该方法包括:
统计目标领域的特定相关关键词和特定无关关键词;
将获取的待分析文本进行分词得到候选关键词;
将每个所述候选关键词与所述特定无关关键词进行匹配;
若每个所述候选关键词均匹配失败,则计算每个所述候选关键词的词向量与所述目标领域的每个特定相关关键词的词向量的相似度;
若所述相似度大于预设阈值,则将该目标领域的特定相关关键词作为待分析文本的关键词输出。
第二方面,本发明实施例还提供了一种搜索关键词获取的装置,该装置包括:
关键词统计模块,用于统计目标领域的特定相关关键词和特定无关关键词;
文本分词模块,用于将获取的待分析文本进行分词得到候选关键词;
关键词匹配模块,用于将每个所述候选关键词与所述特定无关关键词进行匹配;
相似度计算模块,用于若每个所述候选关键词均匹配失败,则计算每个所述候选关键词的词向量与所述目标领域的每个特定相关关键词的词向量的相似度;
关键词输出模块,用于若所述相似度大于预设阈值,则将该目标领域的特定相关关键词作为待分析文本的关键词输出。
本发明通过统计目标领域的特定相关关键词和特定无关关键词;将获取的待分析文本进行分词得到候选关键词;将每个候选关键词与特定无关关键词进行匹配;若每个候选关键词均匹配失败,则计算每个候选关键词的词向量与所述目标领域的每个特定相关关键词的词向量的相似度;若相似度大于预设阈值,则将该目标领域的特定相关关键词作为待分析文本的关键词输出,实现根据用户输入的文本信息比较准确地确定与用户的某一兴趣或需求相关的关键词,并将与候选关键词语义相似度较高的该目标领域的特定相关关键词作为待分析文本的关键词输出,丰富用户的搜索关键词。
附图说明
图1是本发明实施例一中的一种搜索关键词获取的方法的流程图;
图2是本发明实施例二中的一种搜索关键词获取的方法的流程图;
图3是本发明实施例三中的一种搜索关键词获取的装置的结构框图。
具体实施方式
下面结合附图和实施例对本发明作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释本发明,而非对本发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本发明相关的部分而非全部结构。
实施例一
图1为本发明实施例一提供的一种搜索关键词获取的方法的流程图,本实施例可适用于获取搜索关键词的情况,该方法可以由搜索关键词获取的装置来执行,具体包括如下步骤:
步骤110、统计目标领域的特定相关关键词和特定无关关键词。
其中,目标领域可为研究用户的某一兴趣或需求而确定的领域,如目标领域可为研究用户是否有购车的意愿而确定的汽车领域或为研究用户是否有旅游的意愿而确定的旅游领域等。
特定相关关键词为与用户的某一兴趣或需求相关的关键词。特定无关关键词为与用户的该兴趣或需求无关的关键词,其中,特定无关关键词通常会与某些特定相关关键词同时出现或语义相似度较高,而其往往与用户该兴趣或需求无关。
示例性的,以目标领域为研究用户是否有购车的意愿而确定的汽车领域为例,特定相关关键词可为与购车意愿相关的关键词,如“钱,买,购买,怎么样,哪个,性价比,汽车,品牌,档次,买车,二手车,实惠,车型,购车,报价,贷款,保险,提车,购买,购置税,价格,二手,汽车论坛,美容,论坛”以及“大众,起亚,丰田,奥迪,宝马,本田,福特,现代,标致,奔驰,别克,长安,雪佛兰,日产,比亚迪,马自达,铃木,路虎,保时捷,奇瑞,斯柯达,江淮,吉普,雪铁龙,五菱,帝豪,宝骏,雷克萨斯,奔腾,海马,三菱,沃尔沃,吉利,玛莎拉蒂,众泰,凯迪拉克,东风,启辰,北汽,劳斯莱斯,法拉利,捷豹,荣威,英菲尼迪,宾利,广汽”,特定无关关键词为与购车意愿无关的关键词,如“汽车站,车站,汽车旅馆,旅馆,模具,利比亚,努比亚,公司,长途,客车,相遇,靠右,传感,营业厅,现代舞,模型,汽车模型,纳米比亚,车模,收购,飞机,客运,装卸,制造,维修,前大灯,概念,概念车,时刻,时刻表,车轮,轮胎,汽车轮胎,钥匙,钥匙包,音响,汽车音响,动员,总动员,玩具,玩具车,汤姆,年票,女主播,记录,记录仪,摇号,档,单词,体,丘脑,游戏,游戏王,司机,女司机,到,座椅,总站,年检,车票,汽车票”。
其中,特定相关关键词和特定无关关键词的统计方式可为本领域技术人员根据经验进行统计。
步骤120、将获取的待分析文本进行分词得到候选关键词。
其中,待分析文本即为用户在搜索框中键入的文本。
可通过现有的分词方法,如基于词典的分词方法、基于统计的分词方法或基于语义学理解的分词方法将待分析文本进行分词,从而得到候选关键词。
优选的,通过结巴分词将待分析文本进行分词。结巴分词是基于字典树(Trie)结构实现高效的词图扫描,生成待分析文本中汉字所有可能的成词情况所构成的有向无环图(Directed Acycline graph,DAG),然后采用动态规划查找最大概率路径,找出基于词频的最大切分组合,对于字典树中没有的词,采用基于汉字成词能力的隐马尔科夫模型(hidden Markov model,HMM),使用Viterbi算法进行分词。其中,结巴分词自带词典,里面有2万多条词语,包含词语出现的次数和词性,通过将字典中2万多条的词语放到一个字典树中,可快速查找词语,由此对待分析文本,在字典树结构的基础上可快速生成有向无环图,进而实现快速分词,得到候选关键词。
步骤130、将每个候选关键词与特定无关关键词进行匹配。
得到候选关键词后,将每个候选关键词与统计的特定无关关键词进行匹配,若统计的特定无关关键词中包括任一候选关键词,则认为键入该待分析文本的用户不具有所要分析的某一兴趣或需求,滤除掉该待分析文本。
示例性的,以待分析文本为“汽车模具”为例,若将其分词后,得到“汽车”和“模具”两个候选关键词,由于特定无关关键词中包括“模具”,则认为键入该候选关键词所对应的待分析文本的用户不具有购车意愿,因此,将该候选关键词所对应的待分析文本滤除。
步骤140、若每个候选关键词均匹配失败,则计算每个候选关键词的词向量与目标领域的每个特定相关关键词的词向量的相似度。
如果特定无关关键词中不包括候选关键词,则计算每个候选关键词的词向量与目标领域的每个特定相关关键词的词向量的相似度。其中,词向量是一种把词处理成向量的技术,并且保证向量间的相似度和语义相似度是相关的,如果两个词的词向量间的相似度越大,则说明两个词间的语义相似度越大。
优选的,两个词的词向量间的相似度计算公式为:其中,Xi表示任一候选关键词的词向量,i=0,1,…,n,表示任一特定相关关键词的词向量,i=0,1,…,n。
步骤150、若相似度大于预设阈值,则将该目标领域的特定相关键词作为待分析文本的关键词输出。
若候选关键词的词向量与某一特定相关关键词的词向量的相似度大于预设阈值,则说明该特定相关关键词与候选关键词的语义相似度较大,因此,将该特定相关关键词作为关键词输出,丰富搜索关键词。
示例性的,待分析文本为“大众性价比”,若经过分词,得到“大众”和“性价比”两个候选关键词,在“大众”和“性价比”与特定无关关键词均匹配失败后,计算每个候选关键词的词向量与每个特定相关关键词的词向量的相似度,若候选关键词“大众”的词向量与特定相关关键词中“大众”和“丰田”的词向量,以及候选关键词“性价比”的词向量与特定相关关键词中“性价比”和“怎么样”的词向量的相似度均超过预设阈值,则将“大众”和“丰田”以及“性价比”和“怎么样”均作为待分析文本的关键词输出,进而可根据输出的关键词确定键入该待分析文本的用户是否有购车意愿,如若输出的关键词中包括任一特定相关关键词,便将该用户视为具有购车意愿的用户,或输出的关键词中包括预设的特定相关关键词,如既包括特定相关关键词“钱,买,购买,怎么样,哪个,性价比,汽车,品牌,档次,买车,二手车,实惠,车型,购车,报价,贷款,保险,提车,购买,购置税,价格,二手,汽车论坛,美容,论坛”中的至少一个,又包括特定相关关键词“大众,起亚,丰田,奥迪,宝马,本田,福特,现代,标致,奔驰,别克,长安,雪佛兰,日产,比亚迪,马自达,铃木,路虎,保时捷,奇瑞,斯柯达,江淮,吉普,雪铁龙,五菱,帝豪,宝骏,雷克萨斯,奔腾,海马,三菱,沃尔沃,吉利,玛莎拉蒂,众泰,凯迪拉克,东风,启辰,北汽,劳斯莱斯,法拉利,捷豹,荣威,英菲尼迪,宾利,广汽”中的至少一个,则确定该用户为具有购车意愿的用户。
示例性的,预设阈值可为0.7、0.8或0.9。
本发明通过统计目标领域的特定相关关键词和特定无关关键词;将获取的待分析文本进行分词得到候选关键词;将每个候选关键词与特定无关关键词进行匹配;若每个候选关键词均匹配失败,则计算每个候选关键词的词向量与所述目标领域的每个特定相关关键词的词向量的相似度;若相似度大于预设阈值,则将该目标领域的特定相关关键词作为待分析文本的关键词输出,实现根据用户输入的文本信息比较准确地确定与用户的某一兴趣或需求相关的关键词,并将与候选关键词语义相似度较高的该目标领域的特定相关关键词作为待分析文本的关键词输出,丰富用户的搜索关键词。
实施例二
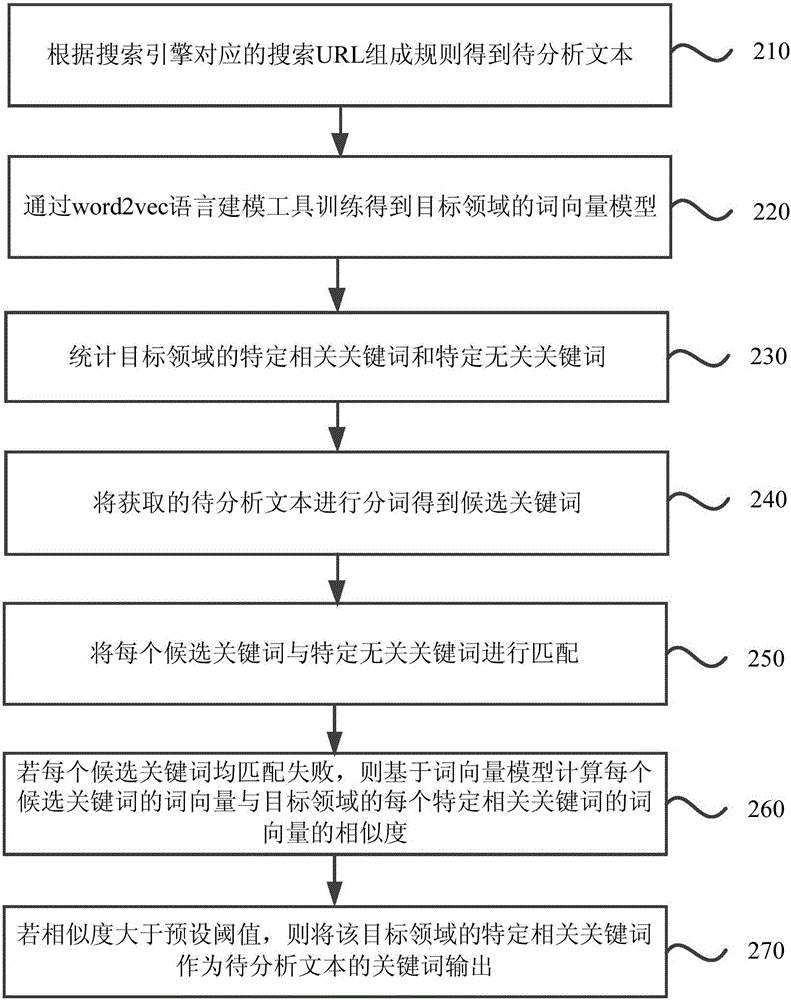
图2为本发明实施例二提供的一种搜索关键词获取的方法的流程图,本发明实施例为在实施例一的基础上进行进一步优化。参见图2,本实施例提供的方法具体包括如下步骤:
步骤210、根据搜索引擎对应的搜索URL组成规则得到待分析文本。
用户在搜索引擎中键入的待分析文本会包含在统一资源定位符(Uniform Resource Locator,URL)中,则对搜索引擎的搜索URL进行分析,得到搜索引擎对应的搜索URL组成规则,即可得到待分析文本。
优选的,步骤210包括以下步骤:
步骤211、利用搜索引擎对应的正则表达式得到目标搜索URL中包含待分析文本的字符串。
示例性的,如在百度和谷歌中键入“复兴之路,”则网关数据中记录的相应的搜索URL为:https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=0&rsv_idx=1&tn=57095150_1_oem_dg&wd=%E5%A4%8D%E5%85%B4%E4%B9%8B%E8%B7%A F&rsv_pq=c95b4ea9000071e2&rsv_t=a6008ZBdM3sQoy8JmIsARIXdNElSHgiE1E AhQBSeXbJkfIY0LOETYymxf9X%2Bjn6fXup3om%2Byzys&rqlang=cn&rsv_ente r=1&rsv_sug3=2&rsv_sug1=1&rsv_sug7=100与http://google.qwsdq.com/#q=%E5%A4%8D%E5%85%B4%E4%B9%8B%E8%B7%AF&btnK=Google+%E6%90%9C%E7%B4%A2,经分析,两个搜索引擎对应的搜索URL中字符串“%E5%A4%8D%E5%85%B4%E4%B9%8B%E8%B7%AF”与用户所键入的待分析文本相对应。
则对于需要获取关键词的目标搜索URL,使用正则表达式,将符号“=”和“&”之间的字符切割出来,即可得到待分析文本对应的字符串。
步骤212、将字符串进行转码得到待分析文本。
将获得的待分析文本对应的字符串进行转码即可得到待分析文本,从而实现通过网关数据中的搜索URL,获得用户在搜索引擎中键入的待分析文本。
其中,网关数据为客户端与服务器通信过程中网关产生的日志记录,网关数据中会记录源互联网协议(Internet Protocol,IP)地址、URL、目标互联网协议(Internet Protocol,IP)地址、操作系统及版本、设备信息、用户代理(User Agent,UA)和请求时间等信息。
步骤213、将待分析文本中除中文之外的文本和\或中文符号滤除。
优选的,在得到待分析文本后,将待分析文本中除中文之外的文本和\或中文符号滤除,以将待分析文本进行预处理,提高确定搜索关键词的效率。
步骤220、通过word2vec语言建模工具训练得到目标领域的词向量模型。
Word2vec是一款将词表征为实数值向量的高效工具,其利用深度学习的思想,可以通过训练,把对文本内容的处理简化为K维向量空间中的向量运算,其中,向量空间上的相似度可以用来表示文本语义上的相似度。
示例性的,以确定用户是否具有购车意愿为例,可通过网络爬虫获取大量与汽车相关网站的搜索URL,如汽车之家、易车网和\或太平洋汽车网等网站,通过搜索URL获得用户键入的文本,将文本进行分词,利用分词后的文本训练word2vec词向量模型,进而得到目标领域的词向量模型。
步骤230、统计目标领域的特定相关关键词和特定无关关键词。
步骤240、将获取的待分析文本进行分词得到候选关键词。
步骤250、将每个候选关键词与特定无关关键词进行匹配。
步骤260、若每个候选关键词均匹配失败,则基于词向量模型计算每个候选关键词的词向量与目标领域的每个特定相关关键词的词向量的相似度。
将每个候选关键词与每个特定相关关键词代入训练后的词向量模型即可得到每个候选关键词的词向量与每个特定相关关键词的词向量,进而可计算每个候选关键词与目标领域的每个特定相关关键词的词向量的相似度。
步骤270、若相似度大于预设阈值,则将该目标领域的特定相关关键词作为待分析文本的关键词输出。
若候选关键词与目标领域的特定相关关键词的词向量的相似度大于预设阈值,则该目标领域的特定相关关键词与候选关键词的语义相似度较大,将该目标领域的特定相关关键词作为待分析文本的关键词输出,丰富搜索关键词。
优选的,还可获取目标搜索URL对应的源IP地址,则在输出关键词后可定位到对应的源IP地址,从而可以较为比较准确地确定具有某一兴趣或需求的人群,如若确定输出的关键词中有预设的特定相关关键词,则可确定该用户具有购车意愿,则可向目标搜索URL对应的源IP地址推送与汽车相关的信息,进而实现有针对性地推送,可提高推送的效率。
本发明实施例通过根据搜索引擎对应的搜索URL组成规则得到待分析文本,实现根据网关数据中记录的搜索URL获得用户在搜索引擎中键入的待分析文本;通过word2vec语言建模工具训练得到目标领域的词向量模型,实现如果每个候选关键词均与特定无关关键词匹配失败,则基于词向量模型计算每个候选关键词的词向量与目标领域的每个特定相关关键词的词向量的相似度,从而可获得与候选关键词语义相似度较大的特定相关关键词,将其作为待分析文本的关键词,丰富用户的搜索关键词。
实施例三
图3文本发明实施例三提供的一种搜索关键词获取的装置的结构框图,该装置可由软件和\或硬件组成。参见图3,该装置包括:关键词统计模块310、文本分词模块320、关键词匹配模块330、相似度计算模块340和关键词输出模块350,其中,
关键词统计模块310,用于统计目标领域的特定相关关键词和特定无关关键词;
文本分词模块320,用于将获取的待分析文本进行分词得到候选关键词;
关键词匹配模块330,用于将每个所述候选关键词与所述特定无关关键词进行匹配;
相似度计算模块340,用于若每个所述候选关键词均匹配失败,则计算每个所述候选关键词的词向量与所述目标领域的每个特定相关关键词的词向量的相似度;
关键词输出模块350,用于若所述相似度大于预设阈值,则将该目标领域的特定相关关键词作为待分析文本的关键词输出。
上述方案中,可选的是,还包括:
模型训练模块,用于通过word2vec语言建模工具训练得到目标领域的词向量模型;
所述相似度计算模块,具体用于:
基于所述词向量模型计算每个所述候选关键词的词向量与所述目标领域的每个特定相关关键词的词向量的相似度。
上述方案中,可选的是,还包括:
文本获取模块,用于根据搜索引擎对应的搜索URL组成规则得到待分析文本。
上述方案中,可选的是,所述文本获取模块,包括:
字符串获取单元,用于利用搜索引擎对应的正则表达式得到目标搜索URL中包含待分析文本的字符串;
文本获取单元,用于将所述字符串进行转码得到待分析文本。
上述方案中,可选的是,所述文本获取模块,还包括:
滤除单元,用于将所述待分析文本中除中文之外的文本和\或中文符号滤除。
上述装置可执行本发明实施例一和实施例二所提供的方法,具备执行上述方法相应的功能模块和有益效果。未在本实施例中详尽描述的技术细节,可参见本发明实施例一和实施例二所提供的方法。
注意,上述仅为本发明的较佳实施例及所运用技术原理。本领域技术人员会理解,本发明不限于这里所述的特定实施例,对本领域技术人员来说能够进行各种明显的变化、重新调整和替代而不会脱离本发明的保护范围。因此,虽然通过以上实施例对本发明进行了较为详细的说明,但是本发明不仅仅限于以上实施例,在不脱离本发明构思的情况下,还可以包括更多其他等效实施例,而本发明的范围由所附的权利要求范围决定。
- 还没有人留言评论。精彩留言会获得点赞!