一种分布式时间序列地理信息服务系统及方法与流程
本发明涉及气象科学和大数据技术应用领域,具体涉及一种分布式时间序列地理信息服务系统及方法。
背景技术:
:由于气象自动站本身基数庞大,每个自动站每分钟都在产生数据,数据日益庞大。采用专用关系型数据库来维护这种量级的数据成本颇高;也有方案利用分布式方案解决数据存储的问题,但依然需要针对数据样本投入大量的研发精力。目前在本
技术领域:
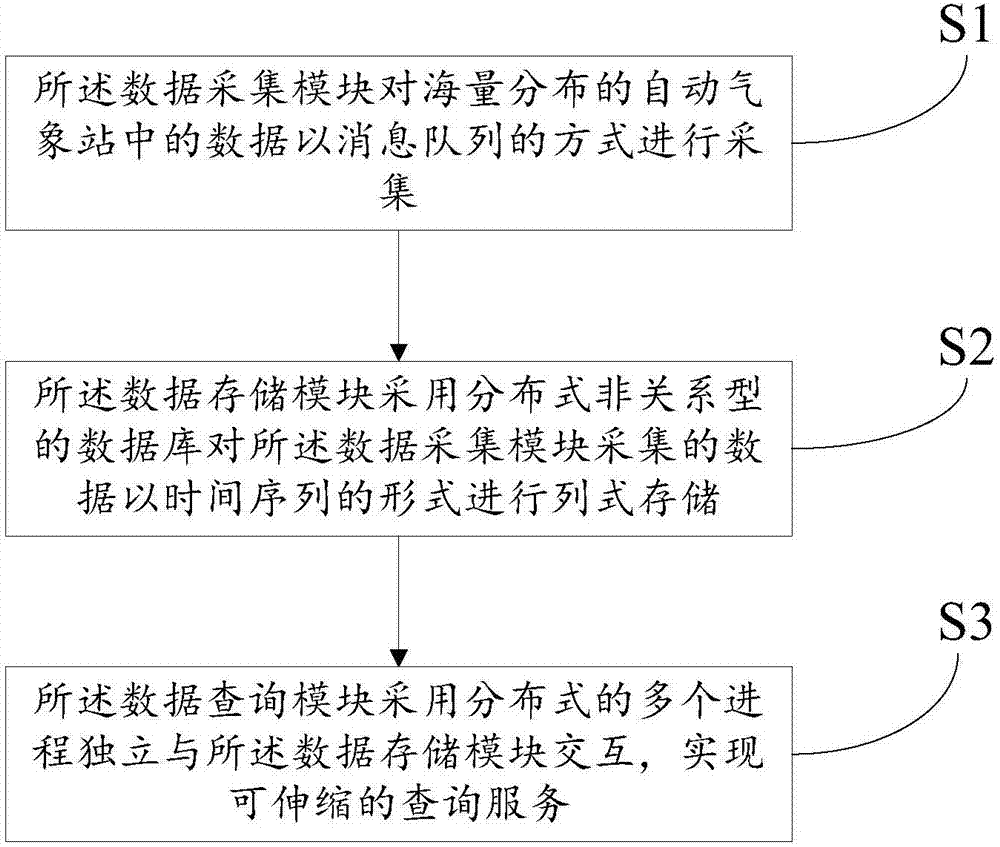
与本提案较为接近的技术方案是针对传统的数据集中存储单点查询的问题,提供了一种基于海量气象数据的存储与检索方法,利用hadoop平台,通过对分布式非关系型数据库hbase建立二级索引,并且将数据通过转换、迁移导入到云平台,实现海量数据的可靠存储与快速检索,其包括如下步骤:数据过滤;在hbase中定义对应的表格式;建立二级索引;分情况进行数据导入;分情况进行数据检索。该发明能实现数据的实时查询,也避免以往存储和维护大量数据所产生的高昂成本,在保证敏感数据安全的前提下能够更经济高效地实时查询海量气象数据。但是现有技术的方案也存在以下缺陷:1.现有技术仅描述了hbase建立二级索引理论,并没有提供针对气象数据的具体建表方案和二级索引方案。2.现有技术的二级索引理论是hbase二级索引的通用理论,并没有针对气象数据优化,浪费了存储空间。3.现有技术仅提出了存储检索方案,要最终改善气象数据使用状况还需要系统化的整体解决方案。技术实现要素:本发明所要解决的技术问题是提供一种分布式时间序列地理信息服务系统及方法,可以针对海量自动站数据的存储、检索和分析构建了专有系统,为在地理位置上广泛分布的自动站采集来的监控数据提供存储、索引和服务,并且使这些数据更容易访问。本发明解决上述技术问题的技术方案如下:一种分布式时间序列地理信息服务系统,包括数据采集模块、数据储存模块和数据查询模块,所述数据采集模块,其用于对分布的自动气象站中的数据以消息队列的方式进行采集;所述数据存储模块,其用于采用分布式非关系型的数据库对所述数据采集模块采集的数据以时间序列的形式进行列式存储;所述数据查询模块,其用于通过分布式的多个进程独立与所述数据存储模块交互,实现可伸缩的查询服务。本发明的有益效果是:本发明一种分布式时间序列地理信息服务系统通过系统封装复杂的数据采集、存储、查询的实现过程,向客户提供更适合气象数据的简单的高可用的数据服务,采用分布式非关系型的数据库可以针对海量自动站数据的存储、检索和分析构建了专有系统,为在地理位置上广泛分布的自动气象站采集来的监控数据提供存储、索引和服务,并且使这些数据更容易访问;同时,数据查询模块由多个运行在不同服务器上的无状态的服务进程组成,不同的进程独立与数据存储模块交互,独立缓存,独立提供http访问接口,当有大量客户端访问时,可以通过负载均衡服务器进行路由分摊压力到多台查询服务器,从而实现了本系统高可用、可伸缩的查询服务,通过调用数据服务接口,不仅可以直接查询获取数据,还可以在自动气象站数据服务的基础上构建应用,比如自动气象站网和自动气象站app。在上述技术方案的基础上,本发明还可以做如下改进。进一步,还包括数据分析模块,所述数据分析模块,其用于基于spark对所述数据存储模块中存储的数据直接进行分析和/或利用分析库tgisml进行分析。采用上述进一步方案的有益效果是:数据分析模块免去客户端重复造轮子的困扰,为分析海量自动气象站数据提供便利。进一步,所述分析库tgisml为,以spark计算框架和tgis数据模型为基础、依托spark的机器学习mllib库、且针对tgis库保存的地理信息数据结构而开发的一种数据分析库。进一步,所述分布式非关系型的数据库具体为hbase,所述hbase中包含有数据表data,在所述数据表data中,包含有一个列族t,在所述数据表data列族t中,包含有一个行键和多个列限定符;所述数据表data列族t的行键中存储有“行政区代码+观测时间+站点类型+站点编码”,其中,所述“行政区代码”长度为3个字节,所述“观测时间”的长度为4个字节,所述“站点类型”的长度为1个字节,所述“站点编码”的长度为3个字节;所述数据表data列族t的列限定符中存储有“值类型标识+要素名”,其中,所述值类型标识的长度为1个字节,且前4位保留,后4位存储有值的类型和格式,所述要素名的长度为3个字节。采用上述进一步方案的有益效果是:所述数据表data通过行政区代码作为行键的起始符号,可以防止时间序列数据单向增长造成的少量region写入热点负担,新的行键设计包含了需要的所有信息,对比传统存储模型设计的采集数据存储表的行键减少了存储空间;同时列名长度减少后,用hbase取相同行数时明显减少了key-value中key占据的空间。进一步,所述数据表data列族t的行键中存储的“观测时间”为小时整点时间,而对于一个小时内的分钟数据则压缩在对应小时整点时间的一个单元格中存储。采用上述进一步方案的有益效果是:由于把分钟数据压入小时数据的单个列中存储,显著压缩了数据的行数。进一步,所述hbase中还包含有信息表info,所述信息表info与所述数据表data相互映射,在所述信息表info中,包含有两个列族,分别为列族id和列族name;在所述信息表info列族id中,包含有行键和列限定符,所述信息表info列族id的行键中存储有“站点类型+站点编码”,其中,所述“站点类型”的长度为1个字节,所述“站点编码”的长度为3个字节;所述信息表info列族id的列限定符中存储有“站点名称+经纬度数值+海拔高度+行政区代码”;在所述信息表info列族name中,包含有行键和列限定符,所述信息表info列族name的行键中存储有“站点名称”;所述信息表info列族name的列限定符中存储有“站点编码”。采用上述进一步方案的有益效果是:信息表info将原来每行重复存储的站点名称、经纬度数值、海拔高度、行政区代码等信息单独存储,减少了重复存储;通过编写过滤器,可以很容易实现通过输入字符串自动搜索匹配站点名称和站点编码。进一步,所述hbase中还包含有时间序列查询索引表data_ts_index,所述时间序列查询索引表data_ts_index中包含有一个行键,所述时间序列查询索引表data_ts_index的行键中存储有“站点类型+站点编码+观测时间”,所述“站点类型”的长度为1个字节,所述“站点编码”的长度为3个字节,所述“观测时间”的长度为4个字节。采用上述进一步方案的有益效果是:时间序列查询索引表data_ts_index除了“查询某个范围内、某一时刻、某一类站点的数据”这个维度的查询是常用查询之外,还有另一个维度的查询功能:“查询某个站点、某段时间的数据”,也就是查询站点的时间序列数据,扫描数据时,可以指定明确的起止位置,优化了时间序列查询时间。进一步,所述hbase中还包含有报警查询索引表data-alert-index,所述报警查询索引表data-alert-index中包含有1个行键和1个列族f;所述报警查询索引表data-alert-index行键中存储有“行政区代码+观测时间+报警要素名+站点类型+站点编码”,所述“行政区代码”的长度为3个字节,所述“观测时间”的长度为4个字节,所述“报警要素名”的长度为3个字节,所述“站点类型”的长度为1个字节,所述“站点编码”的长度为3个字节;在所述报警查询索引表data-alert-index列族f中,只有1个列限定符v,所述报警查询索引表data-alert-index列族f的列限定符v代表报警要素的报警值。采用上述进一步方案的有益效果是:报警查询索引表data-alert-index是针对“某个范围内、某一时刻、某一类站点、某个要素值”是否超出某预警值而设立的查询索引表。进一步,所述hbase中还包含有地理位置查询索引表data-geo-index,所述地理位置查询索引表data-geo-index中包含有行键,所述地理位置查询索引表data-geo-index行键中存储有利用空间索引geohash算法对每个自动气象站的经、纬度进行计算得出的相应的geohash编码。采用上述进一步方案的有益效果是:地理位置查询索引表data-geo-index可以按地理位置划分进行查询,拓宽了查询手段。基于上述一种分布式时间序列地理信息服务系统,本发明还提供一种分布式时间序列地理信息服务方法。一种分布式时间序列地理信息服务方法,包括以下步骤,s1,所述数据采集模块对分布的自动气象站中的数据以消息队列的方式进行采集;s2,所述数据存储模块采用分布式非关系型的数据库对所述数据采集模块采集的数据以时间序列的形式进行列式存储;s3,所述数据查询模块通过分布式的多个进程独立与所述数据存储模块交互,实现可伸缩的查询服务。本发明的有益效果是:本发明一种分布式时间序列地理信息服务方法通过系统封装复杂的数据采集、存储、查询的实现过程,向客户提供更适合气象数据的简单的高可用的数据服务,采用分布式非关系型的数据库可以针对海量自动站数据的存储、检索和分析构建了专有系统,为在地理位置上广泛分布的自动气象站采集来的监控数据提供存储、索引和服务,并且使这些数据更容易访问;同时,数据查询模块由多个运行在不同服务器上的无状态的服务进程组成,不同的进程独立与数据存储模块交互,独立缓存,独立提供http访问接口,当有大量客户端访问时,可以通过负载均衡服务器进行路由分摊压力到多台查询服务器,从而实现了本系统高可用、可伸缩的查询服务,通过调用数据服务接口,不仅可以直接查询获取数据,还可以在自动气象站数据服务的基础上构建应用,比如自动气象站网和自动气象站app。附图说明图1为本发明一种分布式时间序列地理信息服务系统的结构框图;图2为本发明一种分布式时间序列地理信息服务方法的流程图。具体实施方式以下结合附图对本发明的原理和特征进行描述,所举实例只用于解释本发明,并非用于限定本发明的范围。如图1所示,一种分布式时间序列地理信息服务系统,包括数据采集模块、数据储存模块和数据查询模块,所述数据采集模块,其用于对分布的自动气象站中的数据以消息队列的方式进行采集;所述数据存储模块,其用于采用分布式非关系型的数据库对所述数据采集模块采集的数据以时间序列的形式进行列式存储;所述数据查询模块,其用于通过分布式的多个进程独立与所述数据存储模块交互,实现可伸缩的查询服务。本发明的系统还包括数据分析模块,所述数据分析模块,其用于基于spark对所述数据存储模块中存储的数据直接进行分析和/或利用分析库tgisml进行分析。所述分析库tgisml为,以spark计算框架和tgis数据模型为基础、依托spark的机器学习mllib库、且针对tgis库保存的地理信息数据结构而开发的一种数据分析库,封装了进行机器学习算法之前额外的数据提取转换操作,为常用数据分析工作提供简明分析接口。数据分析模块免去客户端重复造轮子的困扰,为分析海量自动气象站数据提供便利。本发明一种分布式时间序列地理信息服务系统(也称tgis)通过系统封装复杂的数据采集、存储、查询的实现过程,向客户提供更适合气象数据的简单的高可用的数据服务,采用分布式非关系型的数据库可以针对海量自动站数据的存储、检索和分析构建了专有系统,为在地理位置上广泛分布的自动气象站采集来的监控数据提供存储、索引和服务,并且使这些数据更容易访问;同时,数据查询模块由多个运行在不同服务器上的无状态的服务进程(即tgis进程)组成,不同的进程独立与数据存储模块交互,独立缓存,独立提供http访问接口,当有大量客户端访问时,可以通过负载均衡服务器进行路由分摊压力到多台查询服务器,从而实现了本系统高可用、可伸缩的查询服务,通过调用数据服务接口,不仅可以直接查询获取数据,还可以在自动气象站数据服务的基础上构建应用,比如自动气象站网和自动气象站app。具体的:所述分布式非关系型的数据库具体为hbase,所述hbase中包含有数据表data、信息表info、时间序列查询索引表data_ts_inde、报警查询索引表data-alert-index和地理位置查询索引表data-geo-index索,在介绍这些表之前,首先介绍一下hbase的几个关键概念:行键和列族;行键(rowkey)是hbase建立索引的唯一方式,行根据行键按照rowkey的字节序(byteorder)排序存储,对表的访问要通过行键(get:单个rowkey访问;scan:rowkey范围访问,或全表扫描);列族(columnfamily)必须在表定义时给出,每个列族可以有一个或多个列限定符(columnqualifier),列限定符不需要在表定义时给出可以动态加入,数据按列族分开存储。下面具体介绍一下hbase中的表设计:在所述数据表data中,包含有一个列族t(只有一个列族t,可以防止原有设计的跨列族查询造成的不必要io),在所述数据表data列族t中,包含有一个行键和多个列限定符;所述数据表data列族t的行键中存储有“行政区代码+观测时间+站点类型+站点编码”,其中,所述“行政区代码”长度为3个字节,所述“观测时间”的长度为4个字节,所述“站点类型”的长度为1个字节,所述“站点编码”的长度为3个字节;所述数据表data列族t的行键具体设计如下:(11字节,十六进制)06690f582bcbb05100e018在数据表data列族t的行键中,第1至3字节中存储有完整的“行政区代码”,例如,存储的十六进制\x06\x69\x0f换算成10进制是420111,代表湖北省武汉市洪山区,存储汉字“湖北省武汉市洪山区”需要18个字节(gbk编码),以“行政区代码”数值存储只需要3个字节;第4至7字节中存储有“观测时间”,使用linux时间戳数值表示,十六进制582bcbb0换算成十进制为1479265200,代表“wed,16nov201603:00:00gmt”,北京时间“2016年11月16日11:00:00”,比起原来使用时间字符串“2016-11-1611:00:00”(22字节),或反转时间“16110000201611”(14字节)节约了存储空间;特别的是,这里存储的时间为小时整点时间,对于一个小时内的分钟数据压缩在一个单元格中表示,由于把分钟数据压入小时数据的单个列中存储,显著压缩了数据的行数;第8个字节中存储有自动气象站的“站点类型”,比如这里\x51代表字符q,表示区域自动气象站(国家站为空格符号\x20),第9至11字节中存储有自动气象站的5位数的“站点编码”,比如这里的\x00\xe0\x18换算为十进制为57368,代表“站点编码”57368。所述数据表data列族t的列限定符中存储有“值类型标识+要素名”,其中,所述值类型标识的长度为1个字节(8位),且前4位保留,后4位存储有值的类型和格式,以后4位为起点,第1位是一个flag,表明值是整型还是浮点型,0表示整型,1表示浮点型,后3位表明数据的长度(即:所述要素名的长度为3个字节),按1偏移,000表示1个字节;001表示2个字节。长度一定是1,2,4,8中的一个,不然说明有错误;所述要素名的长度为3个字节,要素名压缩到3个字节,减少重复存储长列限定符造成的空间浪费。所述数据表data通过行政区代码作为行键的起始符号,可以防止时间序列数据单向增长造成的少量region写入热点负担,新的行键设计包含了需要的所有信息,对比传统存储模型设计的数据表data的行键减少了存储空间;同时列名长度减少后,用hbase取相同行数时明显减少了key-value中key占据的空间。所述hbase中还包含有信息表info,所述信息表info与所述数据表data相互映射(具体的映射关系为信息表info中存储的站点信息与数据表data的行键中存储的“站点编码”相互映射),在所述信息表info中,包含有两个列族,分别为列族id和列族name;列族id和列族name在查询时并不相关,由于是“站点编码”与站点信息的相互映射,两个列族将拥有数量相等的行,不会因为一个列族行数的过分增长而影响到另一个列族。在所述信息表info列族id中,包含有行键和列限定符,所述信息表info列族id的行键中存储有“站点类型+站点编码”,其中,所述“站点类型”的长度为1个字节,所述“站点编码”的长度为3个字节;所述信息表info列族id的列限定符中存储有“站点名称+经纬度数值+海拔高度+行政区代码”;所述信息表info列族id的行键具体设计如下:(4字节,十六进制)5100e018在所述信息表info列族id的行键中,第1字节存储有自动气象站的“站点类型”,比如这里\x51代表字符q,表示区域自动气象站(国家站为空格符号\x20),第2至4字节存储有自动气象站的5位数的“站点编码”,比如这里的\x00\xe0\x18换算为十进制为57368,代表“站点编码”57368。在所述信息表info列族name中,包含有行键和一个列限定符,所述信息表info列族name的行键中存储有“站点名称”;所述信息表info列族name的列限定符中存储有“站点编码”。信息表info将原来每行重复存储的站点名称、经纬度数值、海拔高度、行政区代码等信息单独存储,减少了重复存储;通过编写过滤器,可以很容易实现通过输入字符串自动搜索匹配站名和站点编码。除了“查询某个范围内、某一时刻、某一类站点的数据”这个维度的查询是常用查询之外,还有另一个维度的查询也很重要,那就是“查询某个站点、某段时间的数据”,也就是查询站点的时间序列数据。由于hbase的行键是索引的唯一方式,所以建立索引的唯一方式就是建立一个行键描述维度不同的新表,即需要建立时间序列查询索引表data_ts_index,可以通过自定义协处理器在hbase添加行时,将行内的数据转储到新表,当然维护新表内容也可以通过客户端分别向两张表插入数据,但是使用协处理器的方法可以减少客户端与服务器端之间的io。所述时间序列查询索引表data_ts_index中包含有一个行键,所述时间序列查询索引表data_ts_index的行键中存储有“站点类型+站点编码+观测时间”,所述“站点类型”的长度为1个字节,所述“站点编码”的长度为3个字节,所述“观测时间”的长度为4个字节。时间序列查询索引表data_ts_index的行键具体设计如下:(8字节,十六进制)5100e018582bcbb0在所述时间序列查询索引表data_ts_index的行键中,第1字节中存储有自动气象站的“站点类型”,比如这里十六进制51代表字符q,表示区域气象站(国家站为空格符号,十六进制20),第2至4字节中存储有自动气象站的5位数的“站点编码”,比如这里的十六进制00e018换算为十进制为57368,代表“站点编码”57368,第5至8字节中存储有“观测时间”,且所“述观测时间”使用linux时间戳数值表示,比如这里的十六进制582bcbb0换算成十进制为1479265200,代表“wed,16nov201603:00:00gmt”,北京时间“2016年11月16日11:00:00”。因为hbase是按行键排序的,这样做的好处是同类型,同一个站点的记录自动落到了连续的存储位置。扫描数据时,可以指定明确的起止位置,优化了时间序列查询时间。同时,因为数据是连续的,对站点某段时间内的要素值进行统计的分组求和速度提升的需求也得到了满足(通过定义协处理器替换regionscanner为带有分组求和的scanner,结果在客户端合并)。时间序列查询索引表data_ts_index除了“查询某个范围内、某一时刻、某一类站点的数据”这个维度的查询是常用查询之外,还有另一个维度的查询功能:“查询某个站点、某段时间的数据”,也就是查询站点的时间序列数据,扫描数据时,可以指定明确的起止位置,优化了时间序列查询时间。所述hbase中还包含有报警查询索引表data-alert-index,所述报警查询索引表data-alert-index中包含有1个行键和1个列族f;所述报警查询索引表data-alert-index行键中存储有“行政区代码+观测时间+报警要素名+站点类型+站点编码”,所述“行政区代码”的长度为3个字节,所述“观测时间”的长度为4个字节,所述“报警要素名”的长度为3个字节,所述“站点类型”的长度为1个字节,所述“站点编码”的长度为3个字节;所述报警查询索引表data-alert-index的行键具体设计如下(14个字节,十六进制):06690f582bcbb0p105100e018在所述报警查询索引表data-alert-index的行键中,第1至3字节中存储有完整的“行政区代码“,即为其中的“06690f”;第4至7字节中存储有“观测时间“,即为其中的“582bcbb0”;第8至10字节中存储有“报警要素名“,即为其中的“p10”;第11字节中存储有自动气象站的“站点类型“,及为其中的“51”;第12至14以3字节中存储有自动气象站的5位数的“站点编码“,及为其中的“00e018”。在所述报警查询索引表data-alert-index列族f中,只有1个列限定符v,所述报警查询索引表data-alert-index列族f的列限定符v代表报警要素的报警值。报警查询索引表data-alert-index是针对“某个范围内、某一时刻、某一类站点、某个要素值”是否超出某预警值而设立的查询索引表。这样仅对行键过滤即可得到某个范围内、某一时刻、某一类站点、某个要素值超出某预警值的所有站点,以及超出报警的值。在某些情况下并不需要按行政区对站点进行分类,行政区划分在行政机关等单位比较有用,但是在对大众的互联网应用,更多时候是按地理位置进行划分。在做某些位置相关的分析的时候,比如knn邻近查询时,更需要能够表示站点在地理位置上的关系。于是可以引入空间索引geohash算法对每个站点的经纬度计算相应的geohash编码,将geohash编码保存在行键中代替行政区编码实现空间索引,即通过建立地理位置查询索引表data-geo-index可实现上述的地理位置查询工作。所述地理位置查询索引表data-geo-index中包含有行键,所述地理位置查询索引表data-geo-index行键中存储有利用空间索引geohash算法对每个自动气象站的经、纬度进行计算得出的相应的geohash编码。所述地理位置查询索引表data-geo-index可以按地理位置划分进行查询,拓宽了查询手段。基于上述一种分布式时间序列地理信息服务系统,本发明还提供一种分布式时间序列地理信息服务方法。如图2所示,一种分布式时间序列地理信息服务方法,包括以下步骤,s1,所述数据采集模块对分布的自动气象站中的数据以消息队列的方式进行采集;s2,所述数据存储模块采用分布式非关系型的数据库对所述数据采集模块采集的数据以时间序列的形式进行列式存储;s3,所述数据查询模块通过分布式的多个进程独立与所述数据存储模块交互,实现可伸缩的查询服务。本发明一种分布式时间序列地理信息服务方法通过系统封装复杂的数据采集、存储、查询的实现过程,向客户提供更适合气象数据的简单的高可用的数据服务,采用分布式非关系型的数据库可以针对海量自动站数据的存储、检索和分析构建了专有系统,为在地理位置上广泛分布的自动气象站采集来的监控数据提供存储、索引和服务,并且使这些数据更容易访问;同时,数据查询模块由多个运行在不同服务器上的无状态的服务进程组成,不同的进程独立与数据存储模块交互,独立缓存,独立提供http访问接口,当有大量客户端访问时,可以通过负载均衡服务器进行路由分摊压力到多台查询服务器,从而实现了本系统高可用、可伸缩的查询服务,通过调用数据服务接口,不仅可以直接查询获取数据,还可以在自动气象站数据服务的基础上构建应用,比如自动气象站网和自动气象站app。以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1