一种基于位置学习效应的最短路径问题的启发式搜索方法与流程
本发明涉及一种带有基于位置学习效应的最短路径问题的精确求解方法,属于人工智能领域,特别涉及一种机器人路径规划方法。
背景技术:
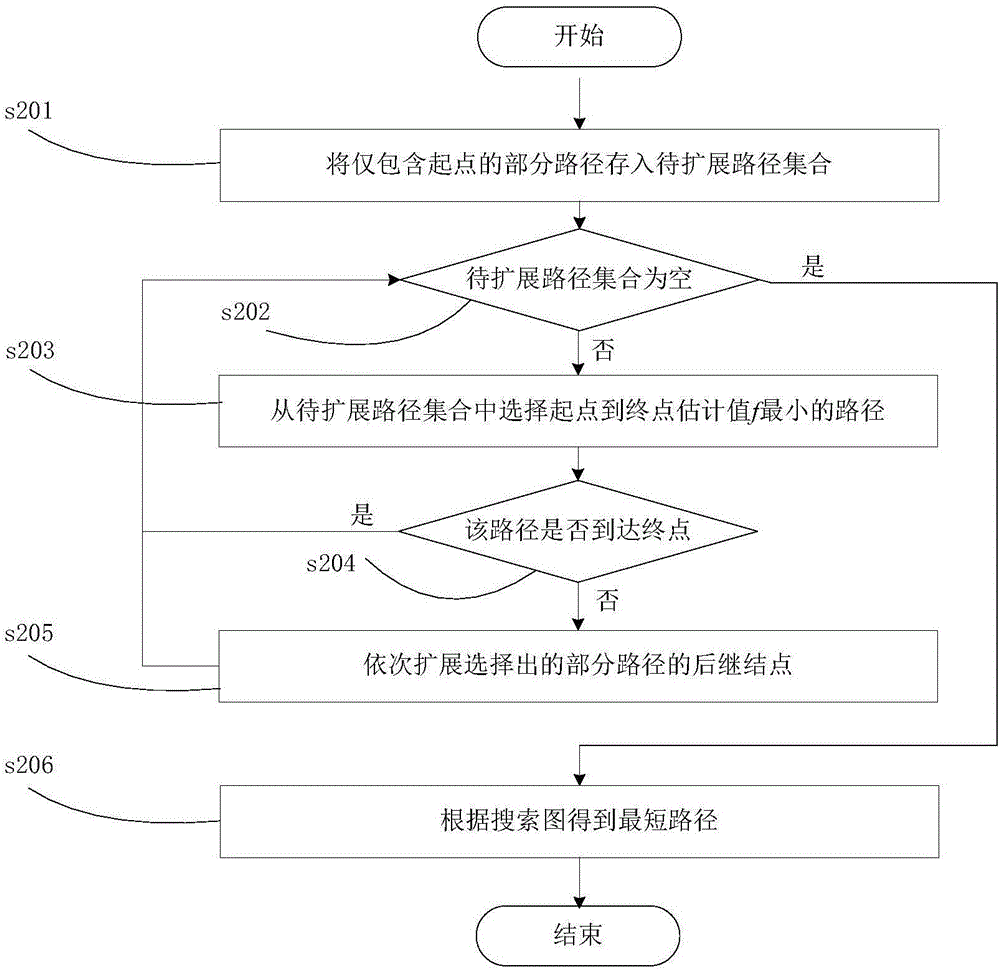
:最短路径问题在实践领域有广泛应用,比如:物流、交通运输、机器人路径规划、车辆路由等。最短路径问题就是在一个图中寻找一条从起点到终点的最短路径。通常来说,距离、时间或者每条弧的遍历开销称为代价,通常情况下,图中有很多条起点到终点的路径,最短路径就是具有最小总代价的路径。如果每条弧的代价提前已知,该问题是静态最短路径问题。如果每条弧的代价会根据一些因素(如,交通状况、学习经验)发生改变,这一类问题属于动态最短路径问题。在实践中,图中弧的代价通常会随着学习效应变化。“学习效应”由Wright首先提出,目前有很多研究都与学习效应有关。如:在机器人足球比赛、机器人空间探索和复杂环境下的机器人救援等场景中,机器人通过强化学习与环境进行交互,获取经验,而更多的经验意味着机器人可以以更小的代价通过同一条路径。因此,带有学习能力的机器人最短路径问题是一个带有学习效应的最短路径问题。通常情况下,学习效应模型有三种:基于位置、基于总处理时间和基于经验。在本方法中,考虑基于位置的学习效应,即机器人每通过一条弧,就会根据经验更新、调整各种参数,更加适应环境,从而使得某条弧的代价随着它在路径中的位置而改变。在已知求解最短路径问题的方法中,A*算法是所有算法中最常用、有效的一种启发式搜索算法,由Hart等提出,此算法由Dijkstra算法扩展而来,启发信息是A*算法时间性能的关键。对最短路径问题,A*算法通常优于其他传统精确算法。尽管有很多关于求解动态最短路径的A*算法,但这些问题大部分都是弧的代价随机变化,而在带学习效应的最短路径问题中,弧的代价是随着所在序列位置规律变化的,二者不相同。通常情况下,无学习效应图中的最短路径不同于带有学习效应图中的最短路径。因此,传统的A*算法和Dijkstra算法及A*算法的变种不适合求解带有学习效应的最短路径问题,需要寻找一个求解带有学习效应的最短路径问题的新方法。[1]A.Konar,I.G.Chakraborty,S.J.Singh,L.C.Jain,andA.K.Nagar,“Adeterministicimprovedq-learningforpathplanningofamobilerobot,”Systems,Man,andCybernetics:Systems,IEEETransactionson,vol.43,no.5,pp.1141–1153,2013.[2]P.E.Hart,N.J.Nilsson,andB.Raphael,“Aformalbasisfortheheuristicdeterminationofminimumcostpaths,”SystemsScienceandCybernetics,IEEETransactionson,vol.4,no.2,pp.100–107,1968.[3]P.E.Hart,N.J.Nilsson,andB.Raphael,“Aformalbasisfortheheuristicdeterminationofminimumcostpaths,”SystemsScienceandCybernetics,IEEETransactionson,vol.4,no.2,pp.100–107,1968.技术实现要素:发明目的:本发明提出一种带有基于位置学习效应的最短路径问题的精确求解的启发式搜索方法,以解决带有基于位置学习效应的机器人最短路径问题。技术方案;本发明所述的带有基于位置学习效应的最短路径问题的启发式搜索方法,包括如下步骤:步骤1:搜索地图信息,得到有向图G=<N,A,c>,其中,N表示图G中所有结点的集合,A表示图G中所有弧的集合,则|N|表示图中结点数,|A|表示图中弧的数目,c(n,n*)表示结点n到n*之间的弧的代价;步骤2:根据机器人路径行驶的先验知识确定学习效应函数:根据有向图G,设计无学习效应时的估计函数h(n),h(n)表示结点n到终点的路径代价的估计值;然后根据学习效应函数和估计函数h(n),得到带有学习效应时的估计函数hl(n);步骤3:使用启发式搜索算法在考虑学习效应的有向图G中寻找最短路径:步骤31:通过将仅包含起点的路径P和通过该路径到达终点的估计值f的信息存入待扩展路径集合OPEN中;并将路径P记入搜索过程中形成的搜索图SG;步骤32:从待扩展路径集合OPEN中选择起点到终点估计值f最小的部分路径作为目前最有可能扩展为最短路径的路径;步骤33:如果路径P到达终点,判断待扩展路径集合OPEN是否为空;若为空,则执行步骤37;若不为空,则执行步骤34;步骤34:依次扩展选择的部分路径的后继结点,具体为:将后继结点加入部分路径构成新的部分路径,根据带有学习效应的估计函数,计算该结点到目标结点的估计值;将带有学习效应的新部分路径的实际值与该结点到目标结点的估计值相加,作为通过该部分路径到达目标结点的估计值;将新的部分路径、其包含的弧的数量及通过对应路径到达目标结点的估计值放入待扩展路径集合OPEN;将扩展路径记入搜索图SG;步骤35:通过剪枝、过滤操作删除搜索图SG中不可能扩展为最短路径的部分路径;步骤36:判断待扩展路径集合OPEN是否为空;若为空,则执行步骤37;若不为空,则执行步骤34;步骤37:根据搜索图SG得到起点到终点的最短路径。步骤2中所述学习效应函数为L(r),其中r是某条弧在路径中的位置。步骤31中所述仅包含起点的路径P和通过该路径到达终点的估计值f具体计算如下:根据带有学习效应的估计函数,计算起点到终点的估计值hl(n0)=h(n0)×L(ρ),路径P的实际代价值为gl(n0,0)=0,则经过路径P到达终点的估计值为fl(n0,0)=gl(n0,0)+hl(n0);Gop(n0)为起点到结点n0的待扩展路径集合,Gcl(n0)为起点到结点n0的已扩展路径集合,则Gcl(n)=φ,并将向量放在带扩展路径集合OPEN中,将路径P记入搜索图SG。步骤32中待扩展路径集合OPEN中选择起点到终点估计值f最小的部分路径具体如下:从待扩展路径集合OPEN中,选择估计值fl最小的路径P,作为进行扩展的部分路径,从OPEN中删除向量其中,n表示该路径由起点到达顶点n;由起点到达顶点n的路径包含有r条弧,其实际代价为gl(n,r),ρ-r表示经过该路径到达终点γ最多还要经过ρ-r条弧;fl(n,r)=gl(n,r)+hl(n)表示经过该路径到达终点γ的估计代价;同时将向量从集合Gop(n)移到集合Gcl(n),其中r为路径P包含的弧的数量;Gop(n)表示的是起点到顶点n的所有路径中目前尚未扩展又可能成为最短路径的部分路径;Gcl(n)表示的是起点到顶点n的路径中目前已经扩展过的路径。步骤3中通过扩展的部分路径到达目标结点的估计值计算如下:根据学习效应,位于第r+1位置的弧(n,m)的代价由c(n,m)变为c(n,m,r+1)=c(n,m)×L(r+1),所以路径P'的代价为gl(m,r+1)=gl(n,r)+c(n,m)×(r+1)α;计算结点m到终点的估计值hl(m)=h(m)×L(ρ),那么,经过该路径到达终点的估计值fl(m,r+1)=gl(m,r+1)+hl(m)。所述剪枝、过滤操作具体如下:步骤351:删除Gop(m)UGcl(m)中被支配的向量,并删除SG和OPEN中对应的信息,如果Gop(m)UGcl(m)中存在支配的向量,则标记Prune为真,否则标记Prune为假;步骤352:进行过滤操作:如果fl>C,标记Filter为真,否则,标记Filter为假;如果fl<C,删除OPEN中fl<C的向量,并删除Gop(m)中对应向量,删除搜索图SG中对应的路径;步骤353:若在剪枝操作和过滤操作过程中,路径P'都没有被删除,即Prune和Filter都为假,则将向量放入OPEN中,将存入Gop(m)中,并将路径P'记入搜索图SG。有益效果本发明考虑的是具有基于位置学习能力的机器人路径规划,如何通过启发式搜索方法在有向图中找到起点到终点的精确的全局最短路径,指导具有学习能力的机器人行驶。附图说明图1为本发明方法中机器人路径规划流程图图2为本发明方法中启发式搜索方法流程图图3为本发明方法中路径扩展方法的流程图图4为案例图。图5为步骤(2)得到的搜索图。图6为步骤(3)得到的搜索图。图7为步骤(4)得到的搜索图。图8为步骤(5)得到的搜索图。图9为步骤(6)得到的搜索图。图10为案例图的最短路径。表1为案例图中各结点的启发函数值。具体实施方式下面结合附图对本发明的技术方案进行详细说明:在机器人足球比赛、机器人空间探索和复杂环境下的机器人救援等场景中,带有学习能力的机器人需要找到从某一位置最快到达目标位置的路径,也就是一条最小代价路径。本发明的一种带有基于位置学习效应的最短路径问题的精确求解的启发式搜索方法,如图1所示,包括以下步骤:步骤s101:搜集地图信息,得到有向图G=<N,A,c>,其中,N表示图G中所有结点的集合,A表示图G中所有弧的集合,则|N|表示图中结点数,|A|表示图中弧的数目,c(n,n*)表示结点n到n*之间的弧的代价;步骤s102:根据机器人路径行驶的先验知识确定学习效应函数;学习效应函数是根据先验知识事先估计得到的,是一个非递增函数;根据机器人路径行驶的先验知识确定学习效应函数L(r),其中r是某条弧在路径中的位置,r越大,L(r)的值越小。根据有向图G,设计无学习效应时的估计函数h(n),表示结点n到终点的路径代价的估计值,然后根据学习效应函数和估计函数h(n),得到带有学习效应时的估计函数hl(n)=h(n)×L(ρ),其中,ρ=min{|N|-1,|A|},表示最短路径的最大可能长度;步骤s103:启发式搜索算法初始化,待扩展路径集合OPEN初始化为空,目前已找到的最短路径代价C初始化为无穷大;步骤s104:使用启发式搜索算法在有向图G中寻找考虑学习效应的最短路径;步骤s105:指导机器人按照寻找到的最短路径行驶。寻找最短路径的启发式搜索算法如图2所示,包含以下步骤:步骤s201:通过将仅包含起点的路径P和通过该路径到达终点的估计值f的信息存入待扩展路径集合OPEN中;并将路径P记入搜索过程中形成的搜索图SG;步骤s202:如果待扩展路径集合OPEN为空,执行步骤s206;步骤s203:从OPEN中选择起点到终点估计值f最小的部分路径P,作为目前最有可能扩展为最短路径的路径;步骤s204:如果路径P到达终点,执行步骤s202;步骤s205:依次扩展选择出的部分路径的后继结点,并通过剪枝、过滤操作删除不可能扩展为最短路径的部分路径,将扩展路径记入搜索图SG,执行步骤s202;步骤s206:如果已经搜索到了终点,那么根据搜索过程形成的搜索图SG,得到起点到终点的最短路径,C就是最短路径的代价;否则,说明不存在起点到终点的路径。图2中的扩展起点n0过程:对于仅含有起点n0的路径P,根据带有学习效应的估计函数,计算起点到终点的估计值hl(n0)=h(n0)×L(ρ),路径P的实际代价值为gl(n0,0)=0,包含路径和路径含有弧数量的信息存入向量则经过路径P到达终点的估计值为fl(n0,0)=gl(n0,0)+hl(n0),Gop(n0)为起点到结点n0的待扩展路径集合,Gcl(n0)为起点到结点n0的已扩展路径集合,则Gcl(n)=φ,并将向量放在OPEN中,将P记入搜索图SG。图2中的选择路径过程:从待扩展路径集合OPEN中,选择估计值fl最小的路径P,作为进行扩展的部分路径,从OPEN中删除向量其中,n表示该路径由起点到达顶点n;由起点到达顶点n的路径包含有r条弧,其实际代价为gl(n,r),ρ-r表示经过该路径到达终点γ最多还要经过ρ-r条弧;fl(n,r)=gl(n,r)+hl(n)表示经过该路径到达终点γ的估计代价。同时将向量从集合Gop(n)移到集合Gcl(n),其中r为路径P包含的弧的数量;Gop(n)表示的是起点到顶点n的所有路径中目前尚未扩展又可能成为最短路径的部分路径;Gcl(n)表示的是起点到顶点n的路径中目前已经扩展过的路径。图2中的扩展路径过程:如图3所示,依次扩展选择出的部分路径的后继结点。将后继结点加入部分路径构成新的部分路径P,根据带有学习效应的估计函数,计算该结点到目标结点的估计值。将新部分路径P的实际值g与该结点到目标结点的估计值hl相加,作为通过该部分路径到达目标结点的估计值f。将路径P和路径P包含的弧的数量、路径P对应的估计值f放入待扩展路径集合OPEN,并通过剪枝和过滤操作删除不可能成为最短路径的部分路径,具体步骤如下:步骤s301:假设选择出待扩展的路径为从起点到结点n的路径P,P包含r条弧,将图G中结点n的所有后继结点放在集合S中;步骤s302:如果集合S为空,结束,如果不为空,执行步骤s303;步骤s303:取出S中的一个结点m,加入路径P,形成新的路径P';步骤s304:因为学习效应,位于第r+1位置的弧(n,m)的代价由c(n,m)变为c(n,m,r+1)=c(n,m)×L(r+1),所以,路径P'的代价为gl(m,r+1)=gl(n,r)+c(n,m)×(r+1)α;计算结点m到终点的估计值hl(m)=h(m)×L(ρ),计算实际代价时,学习效应函数值会随着后面的弧会随着所在位置的增加而变下,但是,因为无法预先知道m到终点的弧的数量,所以无法用精确估计,此处用最坏的情况作为估计值;向量那么,经过该路径到达终点的估计值fl(m,r+1)=gl(m,r+1)+hl(m);步骤s305:如果结点m是终点,并且gl(m,r+1)<C执行步骤s306,否则执行步骤s307;步骤s306:更新目前找到的最短路径代价C=gl;步骤s307:进行剪枝操作:删除Gop(m)UGcl(m)中被支配的向量,并删除SG和OPEN中对应的信息,如果Gop(m)UGcl(m)中存在支配的向量,则标记Prune为真,否则标记Prune为假;步骤s308:进行过滤操作:如果fl>C,标记Filter为真,否则,标记Filter为假;如果fl<C,删除OPEN中fl<C的向量,并删除Gop(m)中对应向量,删除搜索图SG中对应的路径;步骤s309:如果在剪枝操作和过滤操作过程中,路径P'都没有被删除,即Prune和Filter都为假,则将向量放入OPEN中,将存入Gop(m)中,并将路径P'记入搜索图SG;下面我们用图例详细解释该方法,图4是有向标记图,其中,n0是起点,γ是唯一的目标结点。假设学习效应函数为L(r)=rα,其中r表示弧所在路径上的位置。图中包括8个顶点和14条弧,因为从起点n0到γ的路径没有环,因此ρ=min{8-1,14}=7,学习效应因子α取值-0.2。C初始化为+∞,当图G中存在弧(n,γ)时,则c(n,γ)是弧(n,γ)的代价,否则取值为+∞。在带学习效应的图G中,我们用启发函数hl(n)=ρα×h(n)(在本例中,hl(n)=7-0.2×h(n))来估算顶点n到终点γ的值是实际值;hl(n)是的估计值。每个顶点的h和hl值在表1中给出。nn0n1n2n3n4n5n6γh(n)35245350hl(n)2.0333.3381.3552.7103.3882.0333.3880表1(1)将n0初始化为根结点,并且是搜索图SG中仅有的结点。因此,gl(n0,0)=0,ρ=7,Gop(n0)←{(0,7)},Gcl(n0)=φ,fl=gl(n0,0)+hl(n0)=0+2.033=2.033。OPEN←{(n0,(0,7),2.033)}。(2)选择OPEN表中唯一的路径,其四个扩展点n1、n2、n3和n4加入到搜索图SG中和OPEN表中。相应的四条弧位于各自产生的搜索路径中的第一个位置。学习效应对它们的代价没有影响。因此gl(n1,1)=6,从结点n1到目标结点γ至多只有6条弧,则fl(n1,1)=gl(n1,1)+hl(n1)=6+3.338=9.338,Gop(n1)←{(6,6)},同时元组(n1,(6,6),9.338)加入到OPEN表中。对其他的扩展进行类似的处理,得到的搜索图SG如图5所示。(3)由于结点n3在OPEN表中具有最小的估计代价值,因此被选作用来扩展。结点n1是结点n3唯一的后继子结点。弧(n3,n1)位于新路径的第2个位置。由于学习效应的影响,弧的代价c(n3,n1,2)为2×2-0.2=1.741。通过剪枝操作PRUNE,弧(n1,n0)从SG中移除,元组(n1,(6,6),9.338)从OPEN表中删除,从Gop(n1)删除,相似地,对弧(n1,n3)进行类似的处理,最终,结点n3的扩展过程如图6所示。(4)由于结点n1在OPEN表中具有最小的估计代价值,因此被选作用来扩展。结点n1有两个直接后继,n4和n6。由于弧(n1,n4)位于路径中的第3个位置,所以代价c(n1,n4,3)为3×3-0.2=2.408。因此,gl(n4,3)=gl(n1,2)+c(n1,n4,3)=5.149,目前有两条路径到达结点n4,两条子路径都加入到SG中,即弧(n4,n1)加入到图SG中,元组(n4,(5.149,4),8.537)插入到OPEN表中,向量加入到Gop(n4),对于结点n6进行类似的操作,计算得到:fl(n6,3)=gl(n6,3)+hl(n6)=7.557+3.388=10.945。最终,结点n1的扩展过程如图7所示。(5)由于在OPEN表中,结点n4的fl的值最小,因此,扩展结点n6和γ。到目标结点γ的新路径的代价为9.353,小于C值,因此C值更新为9.353.因为fl(n2,1)=gl(n2,1)+hl(n2)=8+1.355=9.355>C,则到结点n2的路径被操作FILTER过滤。由于fl(n6,3)=10.945>C,因此也被过滤。从γ到n4的路径加入到SG中,元组(γ,(9.353,5),9.353)插入到OPEN表中。向量加入到Gop(γ)。至于结点n6,弧(n4,n6)的代价现在已经是c(n4,n6,2)=4×2-0.2=3.482.gl(n6,2)=8.482.fl(n6,2)=gl(n6,2)+hl(n6)=12.860。因此,由于fl(n6,2)>C,通过FILTER操作,到结点n6的路径被移除。最终,结点n1的扩展过程如图8所示。(6)接下来,选择到结点n4的第2条路径,因为在OPEN表中,它有最小的fl值。n4的两个直接后继n6和γ被再次检查。弧(n4,γ)位于新产生路径的第4个位置,因此代价c(n4,γ,4)=5×4-0.2=3.789.因此,fl(γ,4)=gl(γ,4)=gl(n4,3)+c(n4,γ,4)=8.938.其值小于C=9.353.因此C值更新为8.938.产生到γ的扩展。弧(n4,n6)的代价变为c(n4,n6,4)=4×4-0.2=3.031.gl(n6,4)=8.180.fl(n6,4)=gl(n6,4)+hl(n6)=11.568。因此到结点n6的子路径被过滤。最终的SG图如图9所示。(7)目前,OPEN表中还剩下可选择的元组(γ,(8.938,3),8.938),因此选择该元组并将其移除OPEN表。因此,OPEN表已空,算法从γ回溯已获得的SG,得到代价为8.938的路径。如图10所示。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1