一种基于深度运动图‑尺度不变特征变换的手势识别方法与流程
本发明属于手势识别、体感技术、虚拟现实、自然人机交互技术领域,涉及一种基于深度运动图-尺度不变特征变换的手势识别方法。
背景技术:
近年来,随着模式识别、人工智能及计算机视觉等领域的高速发展,基于体感的手势识别成为了新的研究热点。人们每天都在重复着大量的复合型活动,如与人交流时除自然语言对话之外,经常涉及到手势。如果机器和计算机也能像正常人类一样理解人类手势的含义并根据相应的手势来完成各种指令,实现与人的实时交互,一个崭新的世界在向我们挥手。这些研究已经在大量的应用中显示出优势。例如,手势用于聋哑人群与正常人群的无障碍交流、机器人机械手的抓取、互动游戏平台、控制智能轮椅或实现虚拟环境的交互。
手势识别是通过计算机设备对人的手势进行精准解释,已成为一种基于体感的自然人机交互的有效手段。动态手势既包括空间信息又涉及时间信息,常见的特征为运动历史图、时空形状、时空体、运动速度、运动方向、梯度方向直方图、加速稳健特征等。
目前,虽然基于手势识别的人机交互具有良多的好处及优势,但是现实并不是一帆风顺,手势识别方法很容易受到外界条件的影响,在很多方面都具有改进的必要。在特征提取方面,常见特征提取过程复杂且易受到遮挡、光照、距离和摄像头移动等因素的限制;在分类方面,由于人体手势特征量及手势样本数量较多而导致运算量过大,时间复杂度较高进而影响人机交互的实时性。因此,急需提出一种能够适应不同光照环境、高准确率同时兼顾实时性的手势识别方法。
技术实现要素:
有鉴于此,本发明的目的在于提供一种基于深度运动图-尺度不变特征变换的手势识别方法,该方法针对传统的彩色视频中手势识别算法成本高,且二维信息不足导致动作识别效果不佳实时性差的问题,能够高效处理高维非线性流行特征量,具有较少的模型参数,降维后的数据特征具有易于解释的可视化特性,对手势序列进行实时高效识别。
为达到上述目的,本发明提供如下技术方案:
一种基于深度运动图-尺度不变特征变换的手势识别方法,该方法包括以下步骤:
S1:采用基于Kinect体感技术获取手势运动信息,通过基于Kinect体感技术获取原始深度图像序列;与常规的手势动作输入信息不同,采用基于Kinect体感技术获取的原始深度图像序列,既能消除光照、肤色等影响又能保证输入数据的高精准度。
S2:采用基于深度运动图-尺度不变特征变换的描述符进行手势运动特征提取,可以有效表征手势运动过程,然后采用有监督局部线性嵌入的降维方法处理高维的深度运动图-尺度不变特征变换描述符,以减小计算量;
S3:手势模型分类识别:采用基于统计方法的分类器,支持向量机,对深度图像序列提取的特征集合进行建模,可有效利用训练得到的模型,识别未知标签的动态手势。
进一步,在步骤S2中,特征提取和特征降维主要包括:
S21:采集数据,即Kinect体感技术获取的原始深度视频序列;
S22:预处理,对原始深度图像进行去噪操作,采用双边滤波方法;
S23:深度投影图,将原始深度图投影到三个笛卡尔正交平面,得到手势的三个深度投影图,分别为DPMfDPMsDPMt;
S24:动态手势深度运动图DMMv,通过计算深度投影图连续帧差得到运动能量,累计整个动态手势深度序列的能量产生深度运动图;
S25:DMM-SIFT描述符,在动态手势深度运动图DMMv上提取SIFT特征,并级联三个投影面上的DMM-SIFT作为动态手势深度序列的表达,记为DMM-SIFT描述符;
S26:降维处理,运用有监督局部线性嵌入算法对DMM-SIFT描述符集合进行降维。
进一步,在步骤S23中,将深度图投影到各个平面后,利用形态学操作(膨胀和腐蚀)移除每个投影图中内部空隙和噪声,得到每帧图像的三个深度投影图。
进一步,在步骤S24中,所述的动态手势深度运动图DMMv,对一个动态手势过程,通过在前视图、侧视图、俯视图三个正交平面上分别计算连续帧间差异,得到运动能量,积累整个动态手势深度序列的运动能量产生动态手势深度运动图DMMv。
进一步,在步骤S3中,所述支持向量机模型包含三个部分:
部分一:输入观测序列X,为手势运动原始深度序列样本即每个手势的运动特征;
部分二:支持向量机隐含层,采用Sigmoid函数作为核函数,隐含层节点数目及节点对输入节点的权值由训练过程中自动确定;
部分三:输出动作类别Y,为通过支持向量机模型预测出的手势动作类别。
进一步,所述支持向量机识别算法分为两个过程:训练过程和识别过程,其中,训练过程即为对大量手势动作特征描述符进行分类的过程;识别过程即在训练模型基础上对一个未知的测试集中的观察序列X进行预测,推理出对应的手势识别标签的过程。
本发明的有益效果在于:本发明提供的方法不仅能够适应不同光照环境、鲁棒性较强,还能够对手势序列进行实时高效识别,适用于人机交互中的实时手势识别领域。
附图说明
为了使本发明的目的、技术方案和有益效果更加清楚,本发明提供如下附图进行说明:
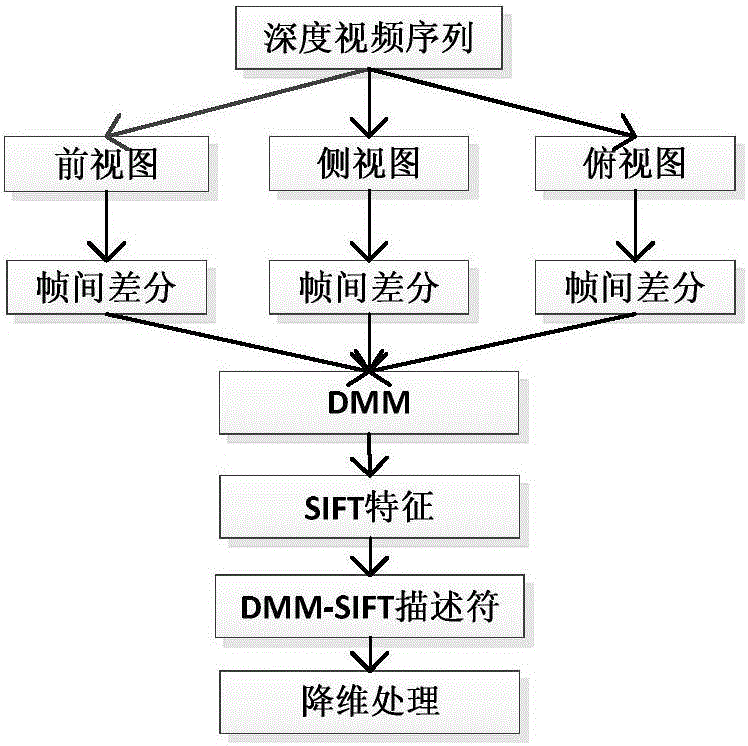
图1为本发明的基于深度运动图-尺度不变特征的手势识别方法示意图;
图2为本发明所述DMM-SIFT描述符具体示意图。
具体实施方式
下面将结合附图,对本发明的优选实施例进行详细的描述。
图1为本发明的基于深度运动图-尺度不变特征的手势识别方法示意图,如图1所示,基于深度运动图和尺度不变特征变换的手势识别示意图,包括:数据采集、提取人体手势运动特征、手势动作识别。其中,人体手势数据采集采用的是基于Kinect体感技术,与传统的彩色图像相比,深度图像能够提供第三维的深度数据,对光照不敏感,能够有效的消除肤色、遮挡及背景对手势识别的影响。常见的基于三维骨骼节点的识别方法,由于Kinect是通过分析深度图像重构出的人体骨骼节点,不能保证骨骼点的坐标估算准确,故本发明采用的是一种基于原始深度图像的手势识别方法,对采集到原始深度图像序列进行预处理,即对原始深度图像进行去噪操作,为避免滤波器平滑图像去噪时导致边缘模糊化,采用是改进的高斯滤波,即双边滤波。
在本实施例中,所述手势识别方法中深度信息由体感设备Kinect采集提供,并把原始的深度图像作为特征提取的输入,由于原始的深度图像不仅能够提供人体的形状信息,还能提供不同视角下手势动作之间的差别,故采用原始的深度视频序列作为手势动作特征数据。
在所述手势识别方法中特征提取方面,本发明提出一个全新的描述符——深度运动图(DMM)-尺度不变特征变换。首先,深度序列的每一帧都被投影到三个正交的笛卡尔平面上,深度序列的每一帧都得到三个深度投影图,对每个投影图计算并累计其运动能量产生动态手势深度运动图。其次,为了更好的表征动态手势深度运动图的局部外观和形状,在动态手势深度运动图上提取SIFT特征,最后,由于在手势深度运动图上提取尺度不变特征的运算空间复杂度和时间复杂度较大,故对图模型采用局部线性嵌入算法降维处理。
在手势模型分类识别方面,支持向量机作为一种基于统计方法的分类器,由于其优良和稳定的分类能力,对比其他分类算法不容易出现过拟合,并且支持向量机在解决小样本,非线性及高维模式识别中具有很大的优势,故在视频或者图像分类领域支持向量机已经成为最常见的分类器。本发明所述的识别方法设计非线性高维模式识别,故采用支持向量机分类器。
进一步地,所述通过体感设备Kinect获取深度信息,即Kinect红外发射器向外发射镭射光,通过红外发射器镜头前的光栅,均匀地投射到测量空间,测量空间的粗糙物体反射,形成随机的散斑,再通过红外摄像机记录空间中形成的散斑,得到原始数据,然后使用特殊的芯片计算图像的深度。
进一步地,所述手势识别特征提取分为两个部分:DMM-SIFT描述符和有监督局部线性嵌入算法。首先,在Kinect传感器所获取的深度视频序列上,深度序列每一帧被投影到三个笛卡尔正交平面得到三个深度投影图DPMv,其中v∈{f,s,t}(即前视投影图、侧视投影图、俯视投影图)。对每个投影图,通过计算连续帧投影图的差异来得到其运动能量,积累整个动态手势深度序列的运动能量,即通过整个深度序列累计的全局活动产生动态手势深度运动图DMMv。由于动态手势深度序列生成的深度运动图表征了累计的运动分布和强度,考虑到SIFT特征可以表征深度运动图的局部外观和形状,从DMMv计算得到SIFTv,并级联[SIFTtT]作为动态手势深度序列的特征表达,记为DMM-SIFT描述符。
所述的DMM-SIFT描述符是高维的具有大量性,故需对其进行降维处理。为使降维后的数据能够保持原有的拓扑结构,采用有监督局部线性嵌入算法,既能保证特征的多样性又能保证识别的高效性。
进一步地,所述支持向量机的识别方法,在模型训练方面,选用降维后的DMM-SIFT描述符作为支持向量机分类器的输入,输出为已知对应手势类别标签。经过大量样本数据的训练,得到相应的样本训练模型。在模型预测方面,输入同为降维处理后的DMM-SIFT描述符,输出为模型预测标签,对应着相应的手势类别。
所述识别方法,对采集到的深度序列数据集上进行留一测试,即对于具有N个对象的数据集,使用N-1个对象的数据进行训练,对剩余一个对象的数据进行测试,并进行重复实验,获得平均识别准确率。
人体手势运动特征提取过程分为特征提取和特征降维两个部分,所述方法的基本流程为:
1)深度投影图,根据图2所述的流程,将手势深度序列的每一帧投影到三个笛卡尔正交平面上,并利用形态学操作(膨胀和腐蚀)移除每个投影图中的内部空隙和噪声,得到手势的三个方向深度投影图,前视投影图、侧视投影图和俯视投影图,分别记为DPMfDPMsDPMt。
2)动态手势深度运动图DMMv,累计每个平面上连续帧深度投影图的差异,获得动态手势运动能量,通过积累整个动态手势深度序列的运动能量产生动态手势深度运动图DMMv。
3)DMM-SIFT描述符,由于动态手势深度运动图携带的形状和结构信息是局部的且SIFT特征能够很好的表征深度运动图的局部外观和形状,故在动态手势深度运动图DMMv上提取SIFT特征。提取尺度不变特征过程包括构建尺度空间、检测尺度空间极值点、除去不好的特征点、赋值方向参数和生成关键点描述子等五个部分。其中,构建尺度空间主要涉及图像金字塔的建立;检测尺度空间极值点即找到图像中的兴趣点;除去不好的特征点本质上是去掉尺度空间中局部曲率非常不对称的点;生成关键点描述子,对一个关键点产生128个数据即最终形成128维的SIFT特征向量。然后,通过级联三个投影面的DMM-SIFT作为动态手势深度序列的表达,记为DMM-SIFT描述符。
4)降维处理,对DMM-SIFT样本集合,首先以欧式距离为度量寻找样本的k个近邻点;其次,在高维空间中,由每个样本的近邻点计算该样本的局部重建权值矩阵;最后,由该样本点的局部重建权值矩阵和其近邻点计算该样本点的输出值。
手势动作识别过程主要包括构造支持向量机分类器、将特征向量样本添加到支持向量机、训练支持向量机以得到模型、对未知序列进行识别等步骤。支持向量机算法包括以下三个方面的内容:
1)输入观察序列X,为手势运动深度序列样本即每帧降维处理后的手势运动特征值。
2)SVM隐含层核函数K,采用Sigmoid函数作为核函数,隐含层节点数目及节点对输入节点的权值由训练过程中自动确定。
3)输出动作类别Y,为通过支持向量机模型预测出的手势动作类别。
所述手势识别过程可以看作是给每个手势动作序列的观察值预测一个类别标签的过程。结合图1可知,所述支持向量机模型以DMM-SIFTd描述符(即经过局部线性嵌入算法降维后的DMM-SIFT特征量)作为训练样本输入。训练过程即为对大量手势动作特征描述符进行分类的过程;然后,在训练模型基础上对一个未知的测试集中的观察序列X进行预测,推理出对应的手势识别标签的过程。
最后说明的是,以上优选实施例仅用以说明本发明的技术方案而非限制,尽管通过上述优选实施例已经对本发明进行了详细的描述,但本领域技术人员应当理解,可以在形式上和细节上对其作出各种各样的改变,而不偏离本发明权利要求书所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!