一种基于区间的文本相似搜索方法与流程
本发明是一种相似文本搜索方法,涉及信息检索领域。所提供的方法能有效搜索文档中不定长的相同或相似的文本片段,尤其涉及信息检索、文本分类、文本挖掘、数据清洗等领域。
背景技术:
基于排序与哈希表的传统搜索技术,难以满足特定的搜索需求。与传统搜索技术相比,相似搜索技术将搜索结果扩展到与其相邻或相似的对象,在表达用户搜索需求方面更加灵活,从而在信息检索等领域广泛应用。在文本相似搜索技术领域,一般有基于文档与基于字符串两类相似搜索技术。现有基于文档的相似搜索技术虽然能够揭示文档之间语义和主题的相关性,但是衡量相似性时将整个文档作为整体,搜索粒度太大,不适用于查找主题无关的文档中相似片段或子句的情形。而侧重于文本字面上相似性的基于字符串的相似搜索技术,在缺乏如标点符号、触发词等情况下,处理文档中长度敏感的相似文本片段时,存在较大误差。
本发明提供一种跟语义无关的基于区间的文本相似搜索方法,通过逐步匹配及合并的方法,可以根据用户设置的阈值找出满足用户需求的相同或相似文本片段。本发明所提供的技术可以用于文本检索、文本分类、文本挖掘和数据清洗等过程中,对数字化历史档案文本处理、文本查重、相似基因序列查找等需求尤其适用。
中国专利200810222998号申请文件公开了“一种基于区间权值的相似性度量方法”,它是多媒体领域一种基于权值的对任意两幅图像的特征向量进行相似性度量的方法,不是文本相似搜索方法。
图书情报工作期刊2014年10月(第58卷第19期)公开了“一种基于短文本相似度计算的主观题自动阅卷方法”,它根据标准答案的得分要点与关键词与考生答案进行匹配,是两个已知短文本之间的简单匹配,本质是关键词查询与统计,其相似度衡量方法与过程皆不同于本发明的方法与过程。
技术实现要素:
本发明所要解决的技术问题是,克服目前在文档中查找文本片段比较困难的技术问题。进一步地,本发明所要解决的技术问题是,为了克服目前文本搜索方法忽视主题无关的不定长文本片段查找的技术问题。
本发明技术方案如下:一种基于区间的文本相似搜索方法,具体步骤包括:
(1)输入文档集合和查询文本,建立区间模型;
(2)遍历输入查询文本中的每一个词汇,利用步骤(1)的输入文档集合索引结构中的位置信息进行逐步匹配,利用滑动窗口技术进行合并,查找在文档集合中与输入文本相似的片段。
(3)当无法继续匹配,判断已匹配的文档集合中的区间文本(即文本片段)是否满足长度阈值要求,如果满足,则作为一个最终结果输出。
其中步骤(1):建立区间模型是对文档集合和输入查询文本的预处理。预处理有两种方案,分别对应后期不同的相似度衡量方法。一种方案是对输入的查询文本进行分词和向量化,并对文档集合进行分词、向量化和建立带有位置信息的倒排索引;另一种方案专门针对基于查询文本编辑距离的相似度衡量方法,无需分词。
其中步骤(2):相似的片段指的是在文档集合中不会有包含该片段的更长的片段满足相似度要求。对相似度的度量可以采用四种不同的方法:精确匹配、基于对称差的匹配、基于Jaccard系数的匹配和基于编辑距离的匹配。不同度量方法对应的匹配合并策略有所不同,可选择使用其中一种或多种衡量方法。滑动窗口技术指的是一个工作窗口,在其中判定当前匹配的词汇是否与之前匹配的文本进行合并。合并是指将单个词汇的匹配汇合成文本片段,并计算文本片段的长度及其与输入文本之间的相似度。
在步骤(2)中使用以下具体技术:
(1)精确匹配合并技术:将滑动窗口大小设为1,当原子匹配与已有匹配严格相邻时进行合并。
(2)基于对称差的匹配合并技术:设定对称差阈值为t,设定滑动窗口大小为t+1,根据以下规则进行合并与优化:
1)包含有相同原子匹配的匹配不进行合并。
2)如果匹配m和第i个滑动窗口中的某个匹配mi合并,设生成的合并为m′,则分两种情况进行下一步合并:①如果m′在文档集合中的起点小于m在文档集合中的起点,那么对于第i个滑动窗口之后的匹配mj,进行合并;如果mj在文档集合的终点小于m′在文档集合中的起点,则m和mj不进行合并。②如果m′在文档集合中的终点大于m在文档集合中的终点,那么对于第i个窗口之后的匹配mj,进行合并;如果mj在文档集合的终点大于m′在文档集合中的起点,那么m和mj不进行合并。
(3)基于Jaccard系数的匹配合并技术:设滑动窗口的大小为变量n,假定长度为len的匹配m在滑动窗口sw的第i个窗口中,Jaccard系数阈值为θ,最小长度阈值为minLen,则当匹配m满足max(minLen,len)*θ≤n-i时进行合并。该技术更适用于搜索长度不同的相似文本。
(4)基于编辑距离的匹配合并技术:该技术使用编辑距离衡量相似度,计算时,以字符为单位,而不是以词为单位(所以无需分词),且要求匹配有序。
本发明的有益效果是:无需计算文档之间的主题相关性,利用区间模型和滑动窗口技术进行逐步匹配与合并,能解决不定长文本片段的查找问题。
本发明可以用倒排索引描述文本中词的位置信息,通过在滑动窗口中逐步匹配及合并的方法找出相同或相似的文本片段,对提高文本搜索、文本清洗、文本分类、文本挖掘等任务的工作效率具有重要意义。采用本发明的技术方案,工程人员可以比较容易地实现相关软件。
附图说明
图1系统整体流程框图;
图2精确匹配实施例示意图;
图3对称差匹配实施例示意图;
图4逐步匹配与合并过程示意图;
图5结果数量与长度阈值的关系图。
具体实施方式
下面将结合附图,对本发明进一步说明:
提供一种基于区间的文本相似搜索技术,通过逐步匹配及合并的方法找出相同或相似的文本片段,包括采用下列步骤:
首先,建立区间模型,比如,对文档集合Sd进行预处理,包括分词和文本向量化,以及构建出带有位置信息的倒排索引,对输入的查询文本q进行分词操作和向量化;
其次,遍历q中的每一个词汇,利用文档集合Sd的索引结构中的位置信息进行逐步匹配,利用滑动窗口技术进行合并,查找在文档集合Sd中与q相同或相似的片段;
最后,将满足长度阈值要求的片段作为输出结果呈现给用户。
在查找过程中,可以采用精确匹配、基于对称差的匹配、基于Jaccard系数的匹配以及基于编辑距离的匹配四种不同的相似度度量方法。
为了便于详细、准确地描述基于区间的相似搜索方法及具体实施方式,下面给出相关术语的解释:
原子匹配(singleton matcher):给定文本Sd和文本Sq,假定Sd和Sq分别包含单词wi,单词wi在文本Sd和文本Sq中的位置下标分别为di和qi,称二元组<di,qi>为文本Sd和文本Sq上的一个原子匹配sm。
对于两个原子匹配sm1<d1,q1>和sm2<d2,q2>,若d1=d2或q1=q2,则sm1和sm2为冲突的原子匹配,若满足(d1-d2)×(q1-q2)<0,则sm1和sm2为交叉的原子匹配。
匹配(matcher):如果一个集合只包含两两互不冲突的原子匹配,则称之为匹配m。集合的大小即匹配m的长度。匹配之间存在属于和不属于的关系。
顺序匹配(sequential matcher):如果一个匹配中的原子匹配两两互不交叉,则称之为顺序匹配。
匹配的区间:设匹配m={sm1<d1,q1>,sm2<d2,q2>,...,sml<dl,ql>}是文本Sd和文本Sq上长度为l的匹配,则[min(dk),max(dk)],(k=1,2...l)为匹配m在文本Sd上的区间,[min(qk),max(qk)](k=1,2...l)为匹配m在Sq上的区间。
于是,可以用基于区间的形式来表示匹配,比如:{([d1,d1],[q7,q7]),...},{([d2,d2],[q8,q8]),...}。该表示方式便于表示合并之后的匹配,形如:{([d1,d2],[q7,q8]),...}。
匹配的距离:设匹配m是文本Sd和文本Sq上的一个匹配,m在Sd上的区间为[d1,d2],在Sq上的区间为[q1,q2],给定距离函数d,d(m)为匹配的距离。
匹配的距离表示两个文本对应区间的片段的相似度。当匹配的距离为0,即两个文本对应区间的片段完全相同时,可以进行精确搜索。
匹配的覆盖:设匹配m1和m2是文本Sd和文本Sq上的两个匹配,给定距离函数d,如果m2包含m1所有的原子匹配,并且d(m2)≤d(m1),则m2为m1在文本Sd和文本Sq上基于d的一个覆盖。
最大匹配:设匹配m是文本Sd和文本Sq上的一个匹配,给定距离函数d,如果在文本Sd和文本Sq上基于d不存在m的覆盖,则称m为文本Sd和文本Sq上基于d的一个最大匹配。
给定样本Sq,备查询文本Sd,距离函数d,距离阈值maxDis,匹配m的长度len(m),以及最小长度阈值minLen,基于区间的文本搜索表现为返回所有满足以下条件的最大匹配:
d(m)≤maxDis∧len(m)≥minLen
实施的方式:
第一步,对文档集合进行分词并建立带位置信息的倒排索引。具体方法是利用分词技术分词后,记录词所属文本编号及频数,并一一记录词在文本中的位置信息,以便利用这些位置信息来判断一组词的距离是否在一定范围之内,其形式为{(文本编号,词序号),(文本编号,词序号),…,(文本编号,词序号)}。
例如,对于文本0:“……略询关于拔还南极周边地区气象台修理费主管当局是否核准请查明见复由法国驻华大使馆致我外交部节略法国大使馆兹向外交部致意并声述关于请求拔还南极周边地区气象台修理费事曾准外交部三月十八日……”和文本1:“……关于南极周边地区气象台修理费用事法国驻华大使馆致我外交部节略法国大使馆兹向外交部致意并声述关于南极周边地区气象台修理费用事接准外交部欧洲司十一月二十四日……”,其倒排索引(部分)如下:
略->{(0,0)}
询->{(0,1)}
关于->{(0,2),(0,35),(1,0),(1,23)}
拔->{(0,3),(0,37)}
还->{(0,4),(0,38)}
南极->{(0,5),(0,39),(1,1),(1,24)}
周边->{(0,6),(0,40),(1,2),(1,25)}
地区->{(0,7),(0,41),(1,3),(1,26)}
第二步,进行精确搜索,设置滑动窗口大小为1。
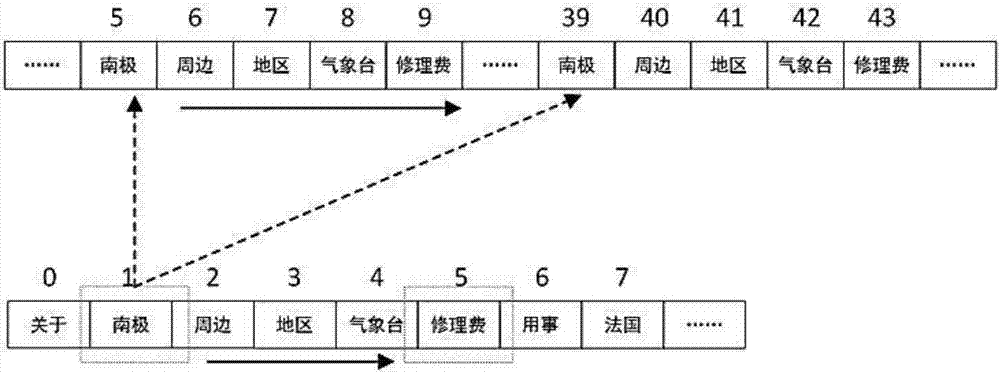
如图2所示,查询“南极”,生成一组原子匹配:([1,1],[5,5])和([1,1],[39,39])。将该组原子匹配压入滑动窗口尾部,则滑动窗口的状态为:
sw[0]={([1,1],[5,5]),([1,1],[39,39])}
接下来查询“周边”:我们得到另一组原子匹配{([2,2],[6,6]),([2,2],[40,40])},将其压入滑动窗口尾部,此时滑动窗口状态为:
sw[0]={([1,1],[5,5]),([1,1],[39,39])}
sw[1]={([2,2],[6,6]),([2,2],[40,40])}
滑动窗口大小大于1,取出窗口首部的一组原子匹配得到:
pop={([1,1],[5,5]),([1,1],[39,39])}
将取出的原子匹配集pop与滑动窗口中的原子匹配集进行合并,其中([1,1],[5,5])与([2,2],[6,6])相邻,合并之后得到匹配([1,2],[5,6]),([1,1],[39,39])与([2,2],[40,40])相邻,合并之后得到匹配([1,2],[39,40]),替换到滑动窗口中。
接下来按上述步骤依次查询“地区”、“气象台”、“修理费”得到滑动窗口的状态为:
sw[0]={([1,5],[5,9]),([1,5],[39,43])}
查询到“用事”时,返回的位置信息为空,因此无法继续合并。然后验证已合并的匹配,假定设置最小长度阈值minLen为5,则两个匹配都满足要求,输出到结果集当中。
第三步,进行相似搜索。和精确搜索不同,相似搜索允许匹配之间存在距离,所以,只要在一定距离范围之内,两个匹配不相邻也可以合并。具体匹配合并过程因相似度衡量方法不同而不同。
以基于对称差的匹配和合并为例:根据两个集合r与s的对称差(symmetric difference)距离公式:diss(r,s)=|r∪s|-|r∩s|可知,假设对称差距离阈值设定为t,最小匹配长度为minLen,那么滑动窗口sw大小需要设为t+1。这是因为,如果两个匹配在文本中的位置间隔相差大于t,那么基于这两个匹配合并的匹配对称差也大于t。因此如果两个匹配在滑动窗口中的距离相差大于t,那么这两个匹配是无法直接合并的。
基于对称差的匹配与合并过程中,匹配不一定连续,所以,需要记录原子匹配在文档中的所有位置,来判断原子匹配之间是否存在冲突。同时,为了避免数据冗余,还需要在合并时验证匹配是否有覆盖,并删除被覆盖的匹配。如([5,6],[24,25])就是([6,6],[25,25])的覆盖。
需要注意,有时两组不同的匹配的合并可能是相同的。如([0,1],[0,1])和([0,2],[0,2]),([0,1],[0,1])和([2,2],[2,2])合并产生的匹配是相同的即([0,2],[0,2])。
为了减少匹配合并的次数,在保证正确性的前提下对匹配之间的合并提出2个条件:
1)包含有相同原子匹配的匹配不进行合并。
2)如果匹配m和第i个滑动窗口中的某个匹配mi合并,设生成的合并为m′,则分两种情况进行下一步合并:①如果m′在文档集合中的起点小于m在文档集合中的起点,那么对于第i个滑动窗口之后的匹配mj,进行合并;如果mj在文档集合的终点小于m′在文档集合中的起点,则m和mj不进行合并。②如果m′在文档集合中的终点大于m在文档集合中的终点,那么对于第i个窗口之后的匹配mj,进行合并;如果mj在文档集合的终点大于m′在文档集合中的起点,那么m和mj不进行合并。
针对上面的情况,已有([0,1],[0,1])和([2,2],[2,2])可以合并成([0,2],[0,2]),则条件1规定了匹配([0,1],[0,1])和匹配([0,2],[0,2])不能合并。条件2的情况2使匹配([0,0],[0,0])和匹配([2,2],[2,2])不能匹配生成([0,2],[0,2]),从而避免了不必要的匹配合并。
如图3所示,设minLen为6,maxDis为3。
“略”和“询”都不在文档S1中出现,因此滑动窗口的状态为空。
查询“关于”生成匹配([2,2],[0,0])和([2,2],[23,23]),压入滑动窗口,滑动窗口状态为:
sw[0]={}
sw[1]={}
sw[2]={([2,2],[0,0]),([2,2],[23,23])}
“拔”,“还”均不在文档S1中,压入空集,并取出首部空集。查询“南极”生成匹配([5],[1])和([5],[24]),压入滑动窗口,并取出窗口首部空集。查询“周边”生成匹配([6],[2])和([6],[25]),压入滑动窗口,并取出窗口首部匹配集,则:
pop=([2,2],[0,0]),([2,2],[23,23])
滑动窗口状态为:
sw[0]={}
sw[1]={}
sw[2]={([5,5],[1,1]),([5,5],[24,24])}
sw[3]={([6,6],[2,2]),([6,6],[25,25])}
从窗口中寻找能够与移除的匹配相合并的匹配进行合并。不难看出,([2,2],[0,0]和([5,5],[1,1])能够合并,([2,2],[23,23]和([5,5],[24,24])能够合并。合并后的匹配分别为([2,5],[0,1])和([2,5],[23,24]),将合并得到的匹配加入被合并匹配所在的窗口后,得到滑动窗口状态为:
sw[0]={}
sw[1]={}
sw[2]={([5,5],[1,1]),([5,5],[24,24]),([2,5],[0,1]),([2,5],[23,24])}
sw[3]={([6,6],[2,2]),([6,6],[25,25])}
依次查询“地区”、“气象台”、滑动窗口的状态为:
sw[0]={([5,5],[1,1]),([5,5],[24,24]),([2,5],[0,1]),([2,5],[23,24])}
sw[1]={([6,6],[2,2]),([6,6],[25,25])}
sw[2]={([7,7],[3,3]),([7,7],[26,26])}
sw[3]={([8,8],[4,4]),([8,8],[27,27])}
接着查询“修理费”,得到匹配([9,9],[5,5])和([9,9],[28,28]),压入滑动窗口,并取出滑动窗口首部匹配集:
pop=([5,5],[1,1]),([5,5],[24,24]),([2,5],[0,1]),([2,5],[23,24]))
将pop中的匹配与窗口中其它匹配进行合并,得到滑动窗口状态为:
sw[0]={([5,6],[1,2]),([5,6],[24,25]),([2,6],[0,2]),([2,6],[23,25])}
sw[1]={([5,7],[1,3]),([5,7],[24,26]),([7,7],[3,3]),([7,7],[26,26])}
sw[2]={([8,8],[4,4]),([8,8],[27,27])}
sw[3]={([9,9],[5,5]),([9,9],[28,28])}
这里要注意的是,sw[0]中删除了原来的([6,6],[2,2])和([6,6],[25,25]),而在sw[1]中却保留了原来窗口中的([7,7],[3,3])和([7,7],[26,26]),在窗口sw[0]的([5,6],[1,2])和([5,6],[24,25])分别是([6,6],[2,2])和([6,6],[25,25])的覆盖。
按上述步骤依次查询完毕,总共可得到两个个满足要求的匹配分别为:
([2,9],[0,5]),([2,9],[23,28])。
使用对称差衡量片段的相似性,距离阈值与匹配的长度无关,窗口距离大于距离阈值的两个匹配是无法直接合并的,因此,直接取出窗口首部的匹配集,它所包含的匹配就是需要尝试合并的匹配。这对于不同长度的匹配可能存在“不公平”。直观的想法是,随着匹配的长度的增长,所允许的距离也应该相应增长,即匹配所允许的距离与匹配的长度成正比。对于这种要求,可以使用Jaccard系数来衡量片段的相似性。
根据两个集合r与s的Jaccard距离公式:可知,如果使用在匹配与合并过程中,滑动窗口的大小不固定,当有新的匹配压入窗口尾部时,需要合并的匹配不一定只在窗口首部中,并且窗口首部也可能包含暂时不需要合并的匹配。具体匹配、合并过程为:
设滑动窗口的大小为变量n,假定长度为len的匹配m在滑动窗口sw的第i个窗口中,Jaccard系数阈值为θ,最小长度阈值为minLen,则当匹配m满足max(minLen,len)*θ≤n-i时进行合并。该技术更适用于搜索长度不同的相似文本。
中文文本的分析通常需要一个中文分词步骤,然而在缺乏自然语言技术对文本进行预处理时,或者因为数据源本身的因素(如缺乏标点符号)导致自然语言处理存在较大误差时,相似搜索技术也会受到相应的影响。本发明所提供的技术具体实施时,可以不进行分词,此时,需采用基于编辑距离的相似度衡量方法。
基于编辑距离获取的匹配是该匹配在输入的查询文本q和文档集合文本Sd在某个区间上的一个最长公共子串。基于编辑距离与基于对称差衡量相似性方法的不同点在于:
1)编辑距离计算以字符为单位,对称差计算以词为单位;
2)基于编辑距离衡量相似性要求匹配有序,基于对称差衡量相似性不要求匹配有序。
因此,处理中文时,建立索引和查询都不必进行分词,将每个中文字符作为一个词来处理;在处理英文等外文时,仍然以单词为基本单位进行索引和查询。处理英文没有严格按照编辑距离的定义以字符为单位的原因是,如果对每个字符进行索引,索引的长度会非常长,而且英文总共仅有26个字母,查询每个字母获取的原子匹配的数量会非常大。
对于第二个不同,在执行匹配合并时首先需要验证匹配是否有序。由于合并的匹配是有序的,所以,不需要记录匹配在文本中的具体位置,只需要像精确匹配中那样记录匹配在文本中的起点和终点,但是仅根据这些信息无法计算出匹配的长度和距离,因此为了验证匹配的距离和长度,还要额外地记录匹配的距离和长度信息。对于顺序匹配,对称差计算的距离相当于只能使用删除和插入的方式进行编辑的编辑距离。
以上对所公开的涉及基于区间的文本相似搜索方法进行了具体描述,本领域技术人员将能理解和实施,在不偏离本发明范围情况下,可以对搜索方法进行形式和细节的种种修改,因此以上所建议的但不限定的修改都在本发明的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!