一种面向大数据中稀有类数据的快速查询技术的制作方法
本发明属于数据挖掘领域,尤其涉及一种面向大数据中稀有类数据的快速查询技术。
背景技术:
在现实世界里,大数据中经常包含一些数据样本较少但却具有重要价值的稀有类。例如在商业活动过程中,虽然绝大多数的交易行为都是合法的,但是其中仍然包括一些虚假信息的交易数据;在大量的网络访问的过程中,虽然绝大多数的网络请求都是合理的,但是不排除一些利用系统漏洞进行网络攻击的行为。在实际应用中,这些稀有类数据样本常常被偶然发现或者是通过一些稀有类检测技术所侦察到,当发现了少量的稀有类样本后,随之产生的问题是如何利用这些少量的稀有类数据样本对数据集中的稀有类数据进行快速查询。
对于稀有类的查询,虽然有稀有类分类和稀有类聚类等相关的技术可以找出所有的稀有类数据,但是稀有类分类技术需要大量已知的稀有类数据作为训练集来进行分类器的训练,而实际生活中这些数据是难以获取的,稀有类聚类技术虽然不需要训练数据,但是在聚类过程中没有利用一些已知的有价值稀有类数据信息,可能造成结果的不准确。因而如何利用仅有的少量稀有类数据找到所有稀有类数据是一个重要且极具挑战的问题。
技术实现要素:
为了解决上述技术问题,本发明提供了一种面向大数据中稀有类数据的快速查询技术。首先通过已知的一个稀有类样本点和一个较小的k近邻值来找到一个小范围的稀有类区域,然后根据这个小范围区域计算出新的k值和距离阈值,再根据新的k和距离阈值来继续寻找新的稀有类数据点。
本发明所采用的技术方案是:
一种面向大数据中稀有类数据的快速查询技术,其特征在于,包括以下步骤:
步骤1:对于给定的数据集为d,首先将d中的每个点标记为未知点。使用集合n记录用来寻找稀有类的数据集合,初始时n中仅包含一个已知的稀有类数据点n0,即n={n0}。设置k为较小的值k0,设置距离阈值τd为一个正数,该正数大于数据集d中任意两点之间的最大欧式距离;步骤2:对于n中的每个点ni,在d中找到与ni最近的k个点(称为ni的k近邻),记为knn(ni),将n中所有点的k近邻组成集合knn(n),然后在d中找到knn(n)中每个点的k近邻,将knn(n)中所有点的k近邻组成集合knn(knn(n)),将n中的点标为已知点,并对n中每个点ni对应的knn(ni)中的点进行筛选,直至筛选的次数达到设定的阈值τi;
步骤3:根据筛选后的knn(n)结果进行选择:
选择步骤一:若筛选后的knn(n)中的点包含未知点,则更新n中每个点的坐标,并记录下该点已更新的次数,若更新次数超过给定阈值τt,则该点的坐标不再更新,初始化一个空集合n’,将更新后得到的新坐标点加入集合n’,并更新n=knn(n)∪n',然后返回步骤2;n中点的坐标更新规则为:
其中,(ni)old表示点ni的原始坐标;(ni)new表示更新后的坐标;nij表示点ni的k近邻knn(ni)中的第j个点;knnj(ni)表示点nij的坐标;d(nij,ni)表示点ni和点nij之间的欧式距离;
选择步骤二:若筛选后的knn(n)中的点均为已知点并且k等于k0,将d中所有已知点加入集合r;将k的值逐步增加,每次增加1,直至r在新的k值下找到的k近邻集合knn(r)中包含有未知点,并记录此时的k值,记为knew,更新k=knew;然后对于r中的每个点nr,在d中找到nr的k近邻knn(nr),计算nr和knn(nr)中每个点的距离,并计算这些距离的均值,记录最大的均值,记为
选择步骤三:若筛选后的knn(n)中的点均为已知点并且k不等于k0,则算法停止,然后将r集合中的数据作为最后找到的稀有类结果返回。
在上述的一种面向大数据中稀有类数据的快速查询技术,所述的步骤2中,对n中每个点ni的k近邻knn(ni)中的点进行筛选的过程如下:
步骤2.1:对于knn(ni)中的每个数据点nij,在d中找到nij的k近邻knn(nij),计算nij与knn(nij)中每个点的距离,并计算这些距离的均值,记为
步骤2.2:使用集合x={x1,x2,...,xs}来代表knn(ni),xi代表knn(ni)中的第i个数,s代表knn(ni)包含的数据个数;构造一个s×s的矩阵a,a中的元素aij表示数据xi和xj之间的相似性similarity(xi,xj);初始化一个s维的向量x,x中每个元素为1/s,即x={1/s,1/s,...,1/s};xi和xj之间相似性similarity(xi,xj)的计算为:
其中similarity(xi,xj)表示xi,xj之间的相似性值;d(xi,xj)表示xi,xj之间的欧式距离;knn(xl)t表示xl的k近邻集合中的第t个点;
步骤2.3:初始化三个空集合x+,x-,x0,然后对每个i∈{1,2,...,s},初始化一个对应的向量ei,ei的第i个元素为1,其余元素为0,计算ei和x的亲和度π(ei,x);若π(ei,x)>0,则将i加入到集合x+;若π(ei,x)<0,将i加入到x-;若π(ei,x)=0,将i加入到x0;记录下使得π(ei,x)的绝对值最大对应的i,记为imax;亲和度π(ei,x)的计算为:
其中
步骤2.4:构造一个s维的向量y,y的取值由下列规则确定:
步骤2.5:若y=x,找出x中大于0的位置,并将x中在这些位置上的数据作为筛选得到的结果rx,即rx={xi|xi∈x,xi>0},筛选过程结束;否则更新x,并返回步骤2.3;更新x的方法为:
其中
在上述的一种面向大数据中稀有类数据的快速查询技术,所述步骤1中,3≤k0≤5且k0为整数。
在上述的一种面向大数据中稀有类数据的快速查询技术,所述步骤2中,1≤τi≤3且τi为整数。
在上述的一种面向大数据中稀有类数据的快速查询技术,所述步骤3中,m∈[1,10],1≤τt≤50且τt为整数。
因此,本发明具有如下优点:本发明能够利用已知的较少的稀有类样本找到所有的稀有类,即利用了已知的稀有类信息,又避免了要寻找大量稀有类数据作为训练集,从而有效准确地找到所有稀有类。
附图说明
图1是本发明实施例的流程图。
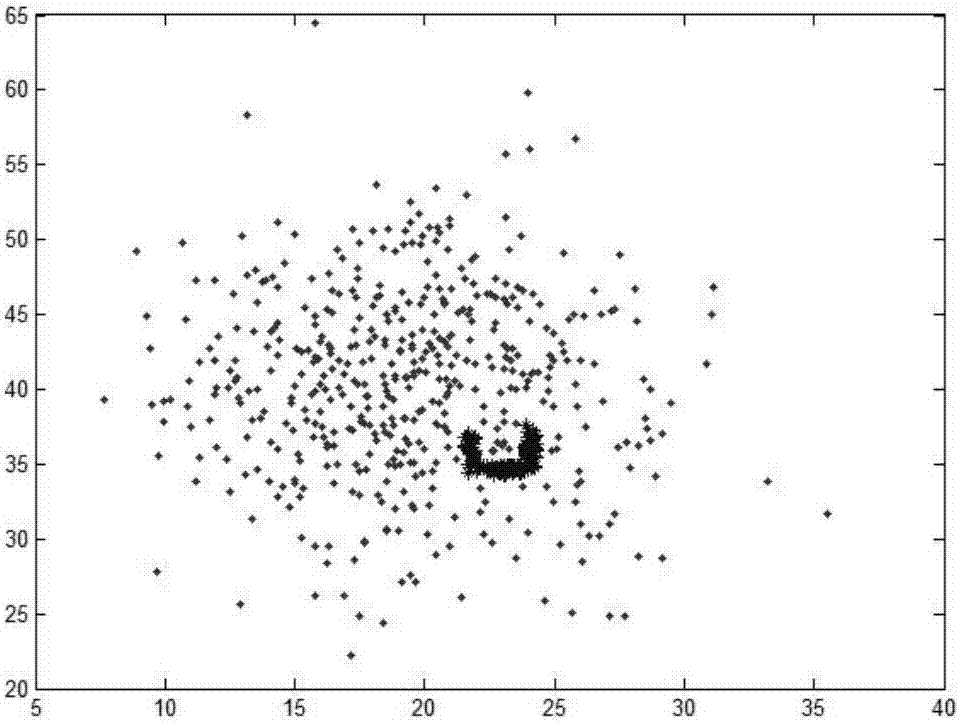
图2a是本发明实施例的测试数据图。
图2b是本发明实施例的测试数据中稀有类数据的详细分布图。
图3a是本发明实施例的实验结果图。
图3b是本发明实施例的实验结果的稀有类数据的详细分布图。
具体实施方式
为了便于本领域普通技术人员理解和实施本发明,下面结合附图及实施例对本发明作进一步的详细描述,应当理解,此处所描述的实施示例仅用于说明和解释本发明,并不用于限定本发明。
本发明提供了一种面向大数据中稀有类数据的快速查询技术,给定一个稀有类数据点,然后根据这个已知的稀有类样本点从给定的数据集中找出所有的稀有类数据。
请见图1,本发明包括以下步骤:
步骤1:对于给定的数据集为d,首先将d中的每个点标记为未知点。使用集合n记录用来寻找稀有类的数据集合,初始时n中仅包含一个已知的稀有类数据点n0,即n={n0}。设置k为较小的值k0=4,设置距离阈值τd为一个正数,该正数大于数据集d中任意两点之间的最大欧式距离;
步骤2:对于n中的每个点ni,在d中找到与ni最近的k个点(称为ni的k近邻),记为knn(ni),将n中所有点的k近邻组成集合knn(n),然后在d中找到knn(n)中每个点的k近邻,将knn(n)中所有点的k近邻组成集合knn(knn(n)),将n中的点标为已知点,并对n中每个点ni对应的knn(ni)中的点进行2次筛选。
步骤3:根据筛选后的knn(n)进行选择:
若筛选后的knn(n)中的点包含未知点,则更新n中每个点的坐标,并记录下该点已更新的次数,若更新次数超过10次,则该点的坐标不再更新,初始化一个空集合n’,将更新后得到的新坐标点加入集合n’,并更新n=knn(n)∪n',然后返回步骤2。n中点的坐标更新规则为:
其中,(ni)old表示点ni的原始坐标;(ni)new表示更新后的坐标;nij表示点ni的k近邻knn(ni)中的第j个点;knnj(ni)表示点nij的坐标;d(nij,ni)表示点ni和点nij之间的欧式距离。
若筛选后的knn(n)中的点均为已知点并且k等于k0,将d中所有已知点加入集合r。将k的值逐步增加,每次增加1,直至r在新的k值下找到的k近邻集合knn(r)中包含有未知点,并记录此时的k值,记为knew,更新k=knew。然后对于r中的每个点nr,在d中找到nr的k近邻knn(nr),计算nr和knn(nr)中每个点的距离,并计算这些距离的均值,记录最大的均值,记为
若筛选后的knn(n)中的点均为已知点并且k不等于k0,则算法停止,然后将r集合中的数据作为最后找到的稀有类结果返回。
在步骤2中,对n中每个点ni的k近邻knn(ni)中的点进行筛选的过程如下:
步骤2.1:对于knn(ni)中的每个数据点nij,在d中找到nij的k近邻knn(nij),计算nij与knn(nij)中每个点的距离,并计算这些距离的均值,记为
步骤2.2:使用集合x={x1,x2,...,xs}来代表knn(ni),xi代表knn(ni)中的第i个数,s代表knn(ni)包含的数据个数。构造一个s×s的矩阵a,a中的元素aij表示数据xi和xj之间的相似性similarity(xi,xj)。初始化一个s维的向量x,x中每个元素为1/s,即x={1/s,1/s,...,1/s}。xi和xj之间相似性similarity(xi,xj)的计算为:
其中similarity(xi,xj)表示xi,xj之间的相似性值;d(xi,xj)表示xi,xj之间的欧式距离;knn(xl)t表示xl的k近邻集合中的第t个点。
步骤2.3:初始化三个空集合x+,x-,x0,然后对每个i∈{1,2,...,s},初始化一个对应的向量ei,ei的第i个元素为1,其余元素为0,计算ei和x的亲和度π(ei,x)。若π(ei,x)>0,则将i加入到集合x+;若π(ei,x)<0,将i加入到x-;若π(ei,x)=0,将i加入到x0。记录下使得π(ei,x)的绝对值最大对应的i,记为imax。亲和度π(ei,x)的计算为:
其中
步骤2.4:构造一个s维的向量y,y的取值由下列规则确定:
步骤2.5:若y=x,找出x中大于0的位置,并将x中在这些位置上的数据作为筛选得到的结果rx,即rx={xi|xi∈x,xi>0},筛选过程结束。否则更新x,并返回步骤2.3。更新x的方法为:
其中
本发明研究了一种面向大数据中稀有类数据的快速查询技术,通过利用一个已知的稀有类点,使用逐步查询k近邻的方法来找到所有的稀有类,避免了训练样本的收集,同时利用了已知的稀有类信息,从而有效准确地找到所有的稀有类数据。
应当理解的是,本说明书未详细阐述的部分均属于现有技术,上述针对较佳实施例的描述较为详细,并不能因此而认为是对本发明专利保护范围的限制,本领域的普通技术人员在本发明的启示下,在不脱离本发明权利要求所保护的范围情况下,还可以做出替换或变形,均落入本发明的保护范围之内,本发明的请求保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!