一种面向大数据中任意形状数据簇的快速聚类方法与流程
本发明属于数据挖掘领域,尤其涉及一种面向大数据中任意形状数据簇的快速聚类方法。
背景技术:
在大数据环境下,有很多的应用场景需要使用到任意形状聚类算法来解决实际问题。例如,在处理地图等地理信息数据时,地图中的山脉,河流等地形往往呈现出各种不规则的形状,可以使用任意形状聚类算法来识别这些地形地貌。在医药学领域,生物的蛋白质的空间结构也是非常不规则的,使用任意形状聚类算法可以有效的识别蛋白质的空间结构,帮助研究者更好的认知蛋白质的组成、功能等。具体来说,聚类算法通过一个数据集中各个数据样本之间的相似性,将相似的数据样本划分到同一个聚类中,从而实现将原始数据集的样本划分为多个聚类的目标。一般来说,聚类算法更加倾向于用欧式距离来度量两个样本之间的相似性。
传统的一般聚类算法往往倾向于将数据集切分成各种凸型,超球型聚类,因此这类聚类算法并不适用于任意形状聚类场景,而现有的任意形状聚类算法由于要对数据集进行比较复杂的分析,因此都具有较高的时间复杂度。这些特征使得现有的聚类算法、任意形状聚类算法都不适合应用于大数据环境下的任意形状聚类问题。
因此,需要设计面向大数据的任意形状聚类方法,用于对大数据进行聚类。一种可行的思路是通过对原始数据集进行采样,减少需要处理的样本数量,从而实现快速聚类。由于聚类算法通过分析数据样本之间的距离作为相似性来实现对样本的聚类。因此,如何在采样的基础上,能够维持原始数据集的形状信息是关键与难点。
技术实现要素:
为了解决上述技术问题,本发明提出了一种面向大数据的快速聚类方法。其思路是对原始的海量数据进行采样,并在采样数据集上运行任意形状聚类算法,从而减少需要处理的数据量,达到提升算法效率的目的。由于聚类算法主要是通过数据集中数据样本分布的形状信息来对数据样本进行聚类,因此,为了能够实现在采样数据集上的准确聚类,需要保证采样样本的分布能够准确反映原始数据集的数据分布信息。现有的采样算法相比与数据集的形状信息,更倾向于保留数据集的概率分布信息。因此,现有的采样算法不具备在采样的基础上,保留数据集形状信息的能力。
因此,本文提出一种新型的采样方法,通过使用该方法通过对原始数据集进行采样,并同时保留数据集的形状信息,通过在采样数据集上进行聚类,能够得到与在原始数据集上相同的聚类结果,从而实现对海量数据的快速聚类。
本发明按下述方案解决该问题:
一种面向大数据的快速聚类方法,其特征在于,对于含有N个数据样本的大数据集D={d1,d2,…,dN},给定采样比例r,具体包括:
步骤1:设定迭代次数t与常数c。从原始数据集中随机采样M=N*r个样本作为初始代表点集合X={x1,x2,…,xM}。并迭代地在更新每个样本的位置,在每一次迭代中,对于代表点样本xi,其新的坐标为:
循环本步骤,迭代t次,转至下一步骤;
步骤2:给定阈值τ,将每个原始数据样本划分给与其距离最近的代表点。对于任意代表点xi,都对应着一个属于该代表点的原始样本集合,令该集合为其中包含ki个原始样本。对于每个代表点样本,更新其位置信息。具体来说,对于代表点样本xi,其新位置为:
迭代执行本步骤将直到所有代表点的位移量总和小于τ,转至下一步骤;
步骤3:使用现有的任意形状聚类算法在采样数据集上进行聚类,并将对代表点数据集的聚类结果映射回原始数据集。具体来说,对于每个代表点xi及其对应的原始样本集合对每一个原始样本都贴上与代表点相同的类别标签。
在上述的一种面向大数据的快速聚类方法,步骤1中迭代更新代表点位置的方法,迭代次数t≤10。
在上述的一种面向大数据的快速聚类方法,步骤2中根据原始数据样本分布更新代表点位置的方法,对于标准化在[0,1]区间的数据集,阈值τ≤0.01。
附图说明
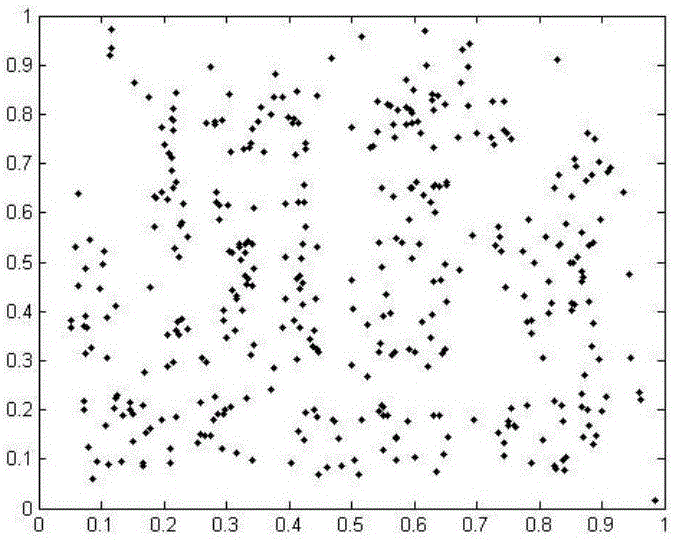
图1是本发明用于处理的原始数据集。
图2a是本发明在步骤1中初始随机选取的代表点数据集分布图。
图2b是本发明在经过步骤1位置调整后的代表点分布图。
图2c是本发明经过步骤2处理后的代表点数据分布图。
图3是本发明的方法流程示意图。
具体实施方式
为了便于本领域普通技术人员理解和实施本发明,下面结合附图及实施例对本发明作进一步的详细描述,应当理解,此处所描述的实施示例仅用于说明和解释本发明,并不用于限定本发明。
在本实施例中,我们使用了含有8000个点的数据集(如图1所示)。本发明包括以下步骤:
步骤1:设定迭代次数t与常数c。从原始数据集中随机采样M=N*r个样本作为初始代表点集合X={x1,x2,…,xM}。并迭代地在更新每个样本的位置,在每一次迭代中,对于代表点样本xi,其新的坐标为:
该步骤将迭代进行t次。经过该步骤处理以后,所选取的代表点分布如图2b所示。在该步骤中,一般选取迭代次数t≤10。
步骤2:给定阈值τ,将每个原始数据样本划分给与其距离最近的代表点。这样一来,对于任意代表点xi,都对应着一个属于该代表点的原始样本集合,令该集合为其中包含ki个原始样本。对于每个代表点样本,更新其位置信息。具体来说,对于代表点样本xi,其新位置为:
该步骤将迭代执行,直到所有代表点的位移量总和小于τ。经过该步骤处理以后,代表点的分布如图2c所示。从图中可以看出,代表点的分布准确地反映了原始数据集中数据分布的形状信息。在该步骤中,对于标准化在[0,1]区间上的数据集,阈值τ≤0.01。
步骤3:使用现有的任意形状聚类算法如DBSCAN,CHAMELEON等算法在采样数据集上进行聚类,并将对代表点数据集的聚类结果映射回原始数据集。具体来说,对于每个代表点xi及其对应的原始样本集合对每一个原始样本都贴上与代表点相同的类别标签。
本发明研究了大数据环境下的聚类问题,通过对数据集进行采样,在保留原始数据集中数据分布的形状信息的同时,极大地缩减了数据集中样本的数量。通过在采样后的数据集上运行聚类算法,并将算法结果投影回原始数据集,实现对大数据集的快速聚类。
应当理解的是,本说明书未详细阐述的部分均属于现有技术,上述针对较佳实施例的描述较为详细,并不能因此而认为是对本发明专利保护范围的限制,本领域的普通技术人员在本发明的启示下,在不脱离本发明权利要求所保护的范围情况下,还可以做出替换或变形,均落入本发明的保护范围之内,本发明的请求保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!