一种面向特定领域的问题解答方法与流程
本发明涉及面向特定领域的问题解答方法。
背景技术:
问答系统(Question Answering System,QA)是信息检索系统的一种高级形式,它能用准确、简洁的自然语言回答用户用自然语言提出的问题。对于当代的我们来说,时间是极为宝贵的,因而构建特定领域的问答系统是有意义的。
目前没有很多关于特定领域问答系统构建的相关资料,但是有基于结构化数据的问答系统的相关资料,基于结构化数据的问答系统的主要思想是通过分析问题,把问题转化为一个查询(query),然后在结构化数据中进行查询,返回的查询结果即为问题的答案。主要数据处理流程如下:(1)根据问题特点来分析问题,产生一个结构数据的查询语言格式的查询(对应于问答系统的问题分析部分)。(2)将产生的查询提交给管理结构数据的系统(如数据库等),系统根据查询的限制条件筛选数据(对应于问答系统的信息检索部分,即缩小答案可能存在的范围)。(3)把匹配的数据作为答案返回给用户。针对特定领域的问答难点如下:
一.难以精准分词,经常容易把相关事件、专业名词等在分词时分隔开;
二.难以识别问句中关键词与属性,即难以识别问题的真正意图,例如:阅读材料三,结合材料,分析“鲁迅对话雨果”交流活动的文化意义;
三.难以对于问句中所识别出的关键词进行扩展;
四.难以将关键词与属性与知识库中所存条目进行准确对应。
现有技术对人名、地名、机构名等实体识别较为准确,对特定领域的专有名称识别不准。特定领域为历史、医疗、化学等领域。
技术实现要素:
本发明的目的是为了解决现有技术对人名、地名、机构名等实体识别较为准确,对特定领域的专有名称识别不准的问题,而提出一种面向特定领域的问题解答方法。
一种面向特定领域的问题解答方法具体过程为:
步骤一、构建特定领域词表,利用词表对输入问题进行分词;
步骤二、对分词后的输入问题进行问题分析,识别问题类型及问题成分;
步骤三、对问题成分进行语义及字符串层面的扩展,得到答案候选词;
步骤四、在知识库中进行答案候选词-属性检索,得到答案候选段落;
步骤五、从答案候选段落筛选候选答案句。
本发明的有益效果为:
本发明的一种面向特定领域的复杂问题解答方法针对特定领域的复杂问题,特定领域为历史、医疗、化学等领域。通过构建特定领域词表、对问句进行问题分析、对关键词进行语义及字符串层面的扩展、在知识库中进行检索、从候选段落筛选候选答案句这5个流程进行解答。该专利方法能回答面向特定领域的复杂问题,和传统的事实性问答系统相比较更加有实用意义。本发明涉及机器人人机交互方法,本发明设计了一套针对特定领域的复杂问题的解答流程,而不是针对简单类型问题的问答。利用多种模型投票确定问题类型,识别问题成分,提出了一种基于知识库的答案候选词-属性检索方法。图3为历史学科问答系统初始界面示意图;图4为输入问题概括分封制的内容示意图;图5为输入问题概括分封制的内容后点击查询的结果示意图;结合图3、图4、图5可得出将本发明应用于历史领域时,在高中历史课本的课后题上测试,准确率可以达到68%。
附图说明
图1为CNN分类器示意图;
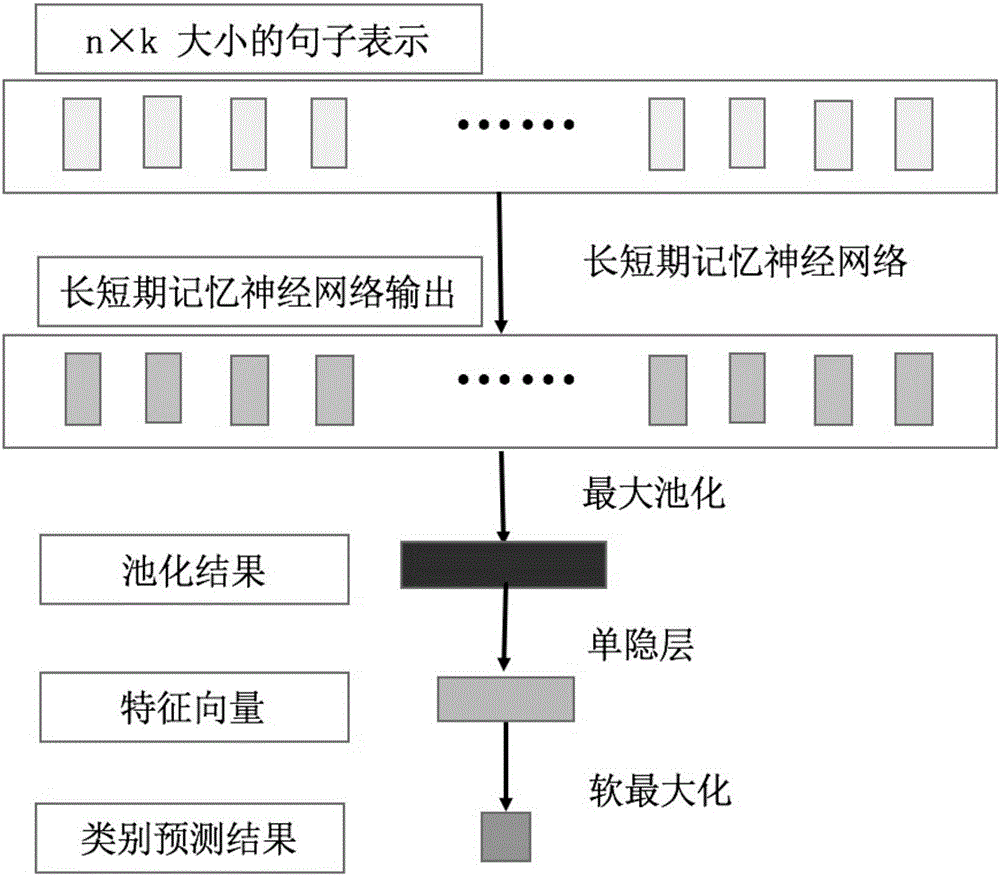
图2为LSTM模型示意图;
图3为历史学科问答系统初始界面截图;
图4为输入问题概括分封制的内容截图;
图5为输入问题概括分封制的内容后点击查询的结果截图;
图6为本发明问答流程图。
具体实施方式
具体实施方式一:本实施方式的一种面向特定领域的问题解答方法具体过程为:
步骤一、构建特定领域词表,利用词表对输入问题进行分词;
步骤二、对分词后的输入问题进行问题分析,识别问题类型及问题成分;
步骤三、对问题成分进行语义及字符串层面的扩展,得到答案候选词;
步骤四、在知识库中进行答案候选词-属性检索,得到答案候选段落;
步骤五、从答案候选段落筛选候选答案句。
具体实施方式二:本实施方式与具体实施方式一不同的是:所述步骤一中构建特定领域词表,利用词表对输入问题进行分词;具体过程为:
首先爬取特定领域百度百科标题,经过去重操作得到初始特定领域词典,采用初始特定领域词典对特定领域资料进行分词,得到一个初始分词结果,再利用初始分词结果训练特定领域的分词器(通过C RF++工具将标注后的初始分词结果输入,得到特定领域的分词器)。将特定领域资料利用特定领域的分词器进行分词,然后提取每个未登录词语的词频(词语在特定领域资料中出现的次数),将词频大于特定阈值并且在初始特定领域词典中不存在的未登录词提取出来作为候选词;特定阈值为人为设定;将词频小于等于特定阈值时,不作为候选词;
在得到候选词集合后,使用候选词邻接熵与候选词互信息两种特征对候选词按邻接熵与互信息的线性和从高到低进行排序;
邻接熵是衡量词语周围出现其他词语丰富程度的特征。通常对于候选词来说,周围出现的词语越丰富,那么成词置信度也就越高。相反,如果候选词周围仅仅出现一些特定的词语,那么它很大的可能是因为一些错误的切分所产生的。候选词邻接熵的计算方式如下:
式中,E为左或右熵;p(ω)为ω出现的概率;ω为左或右邻接词集合;C为左或右邻接词集合;
候选词互信息是指候选词内部凝聚力,候选词内部凝聚度越高,那么它成为词语概率也就越大;片段的内部信息定义为:片段的概率/(子序列概率的积),如果将其取个对数,就得到了互信息:
式中,MI为互信息;p(ω1)为ω1出现的概率;p(ω2)为ω2出现的概率;p(ω1,ω2)为ω1,ω2在给定语料中的联合概率分布;ω1为字符或字符串;ω2为字符或字符串;ω1ω2连在一起为一个候选词;比如电影院可以是“电影院”也可以是“电影院”,ω1、ω2就是电影院的分割;
互信息与邻接熵两个特征相辅相成,前者反应词语内部的凝聚程度,后者反应词语外部上下文的丰富程序。最终使用线性加和(候选词邻接熵的权重与候选词互信息的权重加和为1)将两个特征结合起来。取排序后的候选词集合中的前N个(按邻接熵与互信息的线性和从高到低的前N个)与初始特定领域词典相结合即为构建特定领域词表;N为正整数;
其它步骤及参数与具体实施方式一相同。
具体实施方式三:本实施方式与具体实施方式一或二不同的是:所述步骤二中对分词后的输入问题进行问题分析,识别问题类型及问题成分;具体过程为:
问题分析包括问题分类和问题成分标注;
问题分类既可以指导答案候选段落检索,如比较型需要建立多个查询,又可以对最终的答案生成起到辅助作用。
问题分类的分类体系依据参考教辅中给出的答题模式;很明显的一点是,中国的高考有一些固定的公式,因此根据参考资料中的答题方法进行分类可以从某种意义上提高最终的得分。有些类可以分成小类,比如比较型问题,可以分成比较相同点、不同点、异同点,但是只要知道了是比较型就可以用关键词匹配非常准确地确定具体的某个小类,因此只使用了一级分类而没有采用多级分类。问题分类看做是一个句子分类问题,使用基于规则的、基于SVM、基于CNN、基于LSTM的方法得到问题分类结果,对问题分类结果进行综合判断;具体过程为:
①基于规则的方法是利用正则表达式对输入问题进行匹配,得到问题分类结果;如因果类问题有提示词“原因”、“后果等”,最终得到的规则比较多而且遇到有些问题就无法匹配或者匹配多个。
②基于SVM的方法,利用文本分类的思路,通过开方检验对输入问题每类提取出前100词作为对分类有帮助的词,通过SVM模型,得到问题分类结果;,去掉无用的词,从而提高准确率。
③基于CNN的方法,使用一个四层的CNN网络,如图1所示:
一个四层的CNN网络包括一个输入层,一个卷积层,一个pooling(处理)层,和一个全连接的输出分类层,通过把一个长度为n的句子(长度不够时padding)表示成n*k的矩阵,其中k为词向量的维度,n为词的个数,取值为正整数;k取值为正整数;卷积层使用一个h*k维的卷积核,其中h为所卷积的词的窗口的大小,h取值为正整数;pooling层使用pooling最大值,最后是一个全连接的输出分类层使用一个全连接softmax层来进行预测,得到问题分类结果;max pooling为最大池化;
④基于LSTM的方法,如图2所示,输入为输入问题的文字序列,隐含层记录了前文的信息,输出层使用softmax层输出该问题属于每一个类(原因类、比较类)的概率,得到问题分类结果。
针对四种方法给出的结果用投票法得出最终的分类结果;
问题成分用来进行答案候选段落的检索,依据知识库中章节内容的包含关系准确进行知识库的内容定位;其中答案候选段落为利用CRF分析出来的问题成分在知识库中进行检索;知识库中包括实体与实体属性(以分封制为例,实体名就是分封制,实体属性为内容、影响、时间等);
其它步骤及参数与具体实施方式一或二相同。
具体实施方式四:本实施方式与具体实施方式一至三之一不同的是:所述利用CRF分析出来的问题成分的过程具体为:
问题成分的标注选取了一些对答题起到重要作用的成分,如材料序号,通过识别材料序号可以获得回答问题所需的上下文,显然,这对答题至关重要。问题中的事件可以指导进行检索,通过教材中总结的每一部分所包含的事件可以把答案范围准确地缩小到很小的范围内。问题中的焦点可以用来指导应该回答什么内容,比如原因,意义等。问题中时间也可以用来检索发生的历史事件,提高答题的准确率。问题成分标注主要使用序列标注的方法,观测序列是句子,标记序列是对应的类别标签,本文为每种类别使用三种标记:B-TYPE对应于成分的开始,I-TYPE对应于成分的中间部分,E-TYPE对应于成分的结尾。对于其他无用的部分标记为O。(概括分封制的历史原因中概为B-TYPE,括为E-TYPE,分为B-TYPE,封为I-TYPE,制为E-TYPE,的为O)。
其它步骤及参数与具体实施方式一至三之一相同。
具体实施方式五:本实施方式与具体实施方式一至四之一不同的是:所述步骤三中对问题成分进行语义及字符串层面的扩展,得到答案候选词;具体过程为:
当问题成分在知识库中没有一模一样的词条时,需要对问题成分进行问题成分的扩展;
在字符串的层面计算问题成分与知识库中词的最长公共子序列,设定阈值,当问题成分与知识库中词的最长公共子序列长度大于设定的阈值时,认为问题成分与知识库中词有关联,作答时,将词的知识库内容作为问题成分候选答案;阈值为人为设定;
在字符串的层面上来说,以历史领域的“罗马法”与“古罗马的法律”为例,在知识库中,存储的是“古罗马的法律”,但识别出的问题中出现的关键词为“罗马法”,此时,我们可以计算问题成分与知识库中词的最长公共子序列,本实验设置的阈值为3,即当问题成分1与知识库中词2的最长公共子序列长度大于3时,认为两者是有关联的,那么在作答时,要将2的相关内容作为候选。
在语义层面上,采用word2vec模型进行资料训练,使用的资料是经过特定领域的分词器分词后的特定领域专业书籍、特定领域百科类数据(包括特定领域资料)等;word2vec模型采用的是CBOW(continuous Bag-of-words);
CBOW是已知上下文,估算当前词语的语言模型。CBOW学习目标是最大化对数似然函数,其中,ω表示资料d中任意一个词:资料经过特定领域的分词器分词后的词的似然函数为:
L为对数似然函数;Context(ω)表示资料d中任意一个词的上下文;
CBOW的计算采用Hierarchical Softmax算法,Hierarchical Softmax算法通常结合Huffman(哈夫曼)编码;非叶子节点相当于一个神经元,二分类决策输出1或0,分别代表向下左转或向下右转;每个叶子节点代表语料库中的一个词语,于是每个词语都可以被01唯一地编码,并且其编码序列对应一个事件序列,于是我们可以计算条件概率p(ω|Context(ω))。
通过word2vec模型,得到资料经过特定领域的分词器分词后的所有词语的词向量,计算出问题成分词与知识库词汇的余弦相似度,找出与问题成分词余弦相似度最高的知识库词汇作为答案候选词;
同时以历史高考题为例,任何考点都是围绕大纲词汇的,因而需要计算题目中的关键字与大纲词汇的相似度,不仅要回答出该词的相关内容,也要回答出与之距离最近的大纲词汇的内容。
其它步骤及参数与具体实施方式一至四之一相同。
具体实施方式六:本实施方式与具体实施方式一至五之一不同的是:所述步骤四中在知识库中进行答案候选词-属性检索,得到答案候选段落;具体过程为:
在检索过程中,对步骤三扩展后的问题成分采用多粒度检索,检索过程中使用的分词方法为正向迭代最细粒度切分算法;以“中华人民共和国”为例,假设“中”单个字也是字典里的一个词,那么过程是这样的:“中”是词元也是前缀(因为有各种中开头的词),加入词元“中”;继续下一个词“华”,由于中是前缀,那么可以识别出“中华”,同时”中华“也是前缀因此加入“中华”词元,并把其作为前缀继续;接下来继续发现“华人”是词元,“中华人”是前缀,以此类推。将最细粒度切分后词以及最细粒度切分后词属性在知识库中进行倒排索引,得到候选段落,一个未经处理的数据库中,一般是以文档ID作为索引,以文档内容作为记录。而倒排索引指的是将单词或记录作为索引,将文档ID作为记录,这样便可以方便地通过单词或记录查找到其所在的文档。
其它步骤及参数与具体实施方式一至五之一相同。
具体实施方式七:本实施方式与具体实施方式一至六之一不同的是:所述步骤五中从答案候选段落筛选候选答案句;具体过程为:
首先将答案候选段落按结束分隔符(句号、问号或叹号)进行分句,通过一个多层卷积网络分别将问题与答案候选段落中的分句表示成向量的形式,通过计算两个向量的点积得出句子的得分,从而筛选出置信度最高的候选答案句,将其作为答案输出。
其它步骤及参数与具体实施方式一至六之一相同。
采用以下实施例验证本发明的有益效果:
实施例一:
本实施例一种面向特定领域的问题解答方法具体是按照以下步骤制备的:
根据上面提到的方法,我们搭建了一个历史学科问答系统;系统的使用和运行如图3~图5所示。
整个历史学科问答系统如图6所示,按照前端、中间控制层、后台系统的三个层次分布。前端就是用户与历史学科问答系统进行交互的界面,负责接受用户输入的人问题并传送给控制层,然后接受控制层返回的结果和信号。中间层是负责连接前端和后台的,根据前端的输入和信号量控制后台的系统,同时接受后台的运行结果反馈给前端界面。后台的系统主要是历史学科问答系统。前端界面是网页的形式主要用html和css等实现,这里主要介绍后台的历史学科问答系统的实现。
首先我们先构建了领域词典。爬取历史类百科数据的title结合大纲词汇作为初步的领域词典,历史百科类数据、历史课本以及历史百科全书作为语料。使用哈工大分词器结合词典在语料上进行分词,人工纠正及标注一部分分词结果,利用正确的标注结果结合CRF++工具,训练出历史领域的分词器。在语料上使用历史领域的分词器进行分词,其中会出现一些未登录词,去除停用词后,将词频大于阈值5并且在词表中不存在的未登录词提取出来作为候选词。使用左右信息熵与互信息两种特征对候选词进行排序。其中互信息代表内部凝聚力,左右信息熵代表该词左右两边词语的丰富程度,两种熵都是值越大代表成词概率越高。最终,经过去重等一系列操作,最终我们得到的词表大小为21.0419万。
在用户输入问题之后,我们通过分词器结合词表进行分词与词性标注,识别出问题类型以及问题成分,其中问题类型识别所采用的模型是SVM、CNN和LSTM,通过投票确定最终的问题类型。问题成分识别采用CRF++工具训练模型,识别出问题中的关键成分。
之后针对关键词进行字符串以及语义层面的扩展。字符串层面上我们采用最长公共子序列的方式,即关键词与知识库所存条目的最长公共子序列长度大于3,即默认二者有关联,在作答时要将该条目相关属性作为候选答案。在语义层面上,我们利用语料上的分词结果,采用word2vec模型进行训练,得到词语的词向量,通过计算它们之间的余弦相似度,即可得到他们之间语义的相关性。在作答时,当关键词在知识库中找不到答案时,可以答出与之语义最相近的知识库词汇。
在知识库中进行检索时,采用多粒度检索以及倒排索引,多粒度检索采用的算法是“正向迭代最细粒度切分算法”,他的优点是不会错过关键词,将传入的关键词组合成所有能成词的词。倒排索引是关键词到文档的映射,这样便可以方便地通过单词或记录查找到其所在的文档,而不用一个文档一个文档的遍历一遍,加快了速度。
在索引出的答案段落中,若知识库中有答案,则直接找出答案作答;否则需要找出候选答案句,具体方法是对段落进行分句,计算每个分句关于问题的得分,选出得分最高的10个句子组成答案。
本发明还可有其它多种实施例,在不背离本发明精神及其实质的情况下,本领域技术人员当可根据本发明作出各种相应的改变和变形,但这些相应的改变和变形都应属于本发明所附的权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!