基于特征匹配的目标实时识别方法与流程
本发明涉及计算机视觉领域,尤其是涉及特征匹配与目标识别领域。
背景技术:
近几年,随着计算机视觉的蓬勃发展和相关技术的日臻完善,催生了许多基于计算机视觉技术的相关应用,如图书识别、商标检索、车牌识别以及文字识别等。如何利用实现目标的实时精确识别,已成为计算机视觉领域的热点问题。在计算机视觉中,特征匹配一直是众多学者研究的热点问题,随着研究的深入,已有一些经典特征匹配算法相继提出,从而使得高效的特征匹配算法可以应用到目标的实时精确识别中。
在特征匹配方面,学者做了大量工作:Lowe提出并完善了尺度不变特征匹配算法(scale invariant feature transform,SIFT)。该算法在高斯差分(difference ofGaussians,DoG)空间内进行非极值抑制,然后剔除低对比度的点,并减弱边缘影响,最后利用梯度直方图计算特征方向,生成128维描述向量。该算法具有有照度、JPEG压缩、模糊、视点、尺度与旋转不变性,但算法的鲁棒性与实时性不强。Bay等人提出了快速鲁棒性特征算法(speeded up robust features,SURF)。该算法在尺度空间内使用快速海森矩阵检测得到候选点,然后利用小波扇形环绕法定向,同时利用小波响应生成64维描述向量。虽然该算法的实时性与鲁棒性较SIFT大幅增强,但快速海森矩阵鲁棒性较弱,所以该算法的鲁棒性仍待加强。Leutenegger提出了二进制鲁棒性尺度不变的特征算法(Binary Robust Invariant Scalable Keypoints,BRISK)。该算法在近似尺度空间中利用基于加速段检验的自适应通用角点检测子(Adaptive and Generic corner detection based on the Accelerated Segment Test,AGAST)计算特征分数,同时利用长距离迭代法定向,使运行效率大幅提升,但尺度空间构建没有进行滤波,所以该算法的鲁棒性不强。Alahi等人提出一种快速视网膜特征描述子(Fast Retina Keypoint,FREAK)。该描述子利用扫视匹配搜索,速度完全满足实时需求,但各方面鲁棒性还是较弱。Pablo等人提出一种风式特征算法(KAZE)。该算法采用任意步长来构造稳定的非线性尺度空间,采用海森矩阵检测特征点,同时考虑了区域交叠带,使其对于各种变换比SURF、BRISK等更加稳健,但非线性尺度空间运算复杂,运行效率大幅下降。Pablo等人对KAZE进行了改良,提出一种快速风式特征算法(Accelerated-KAZE)。该算法利用快速显示扩散方程(Fast Explicit Diffusion,FED),动态改善了非线性尺度空间的构建,使得检测的运行效率与鲁棒性大幅增强,同时提出一种改进的局部差异二进制描述符(Modified-Local Difference Binary,M-LDB),使得描述子的速度大大提高,但描述子的鲁棒性弱于KAZE描述子。
技术实现要素:
本发明旨在进一步加强目标识别的可靠性与实时性,提出了基于特征匹配的目标实时识别方法,使得可靠性较强的目标实时识别成为可能。
本发明采用以下技术方案,基于特征匹配的目标实时识别方法,包括以下步骤:
步骤一:获取已有目标的不同角度的图像,并根据获取的图像为每一个已有目标建立一个模板库,所有已有目标的模板库构成一个模板库集合;
步骤二:实时获取待识别目标的图像;
步骤三:利用灰度均匀化算法对待识别目标的图像与某个模板库中的模板分别进行预处理,得到对应的两张待匹配图像;其中,模板是指模板库中存储的目标的某一角度的图像;
步骤四:利用FARISFD检测子分别对两张待匹配图像进行特征检测获得两组特征点;
步骤五:利用ROGFD描述子分别对两组特征点进行特征描述获得两组特征向量;
步骤六:利用基于KD树的BBF算法与双向匹配法对两组特征向量进行快速匹配得到特征对应关系,再利用PROSAC算法对特征对应关系进行计算,得到两张待匹配图像间的单应性矩阵与内点数目;
步骤七:根据内点数目与模板图像特征点数目计算得到匹配率;
步骤八:重复步骤三至步骤七,直至模板库中的所有模板均与待识别目标的图像进行匹配完毕且得到各自的匹配率;
步骤九:根据模板库中的所有模板分别与待识别目标的图像进行匹配得到的所有匹配率,计算得到该模板库的匹配率平均值;
步骤十:将模板库集合中的每个模板库的匹配率平均值进行比较,将待识别目标判定为匹配率平均值最高的模板库所对应的已有目标;
完成基于特征匹配的目标实时识别。
其中,步骤四具体包括以下步骤:
(401)分别将两张待匹配图像的尺度空间的每组中总层数定为4;
(402)根据两张待匹配图像的行数与列数分别求出两张待匹配图像的尺度空间的总组数;
(403)将两张待匹配图像分别根据各自的尺度空间的总组数与尺度空间的每组中总层数,按照SIFT算法分别构建两个尺度空间,其中高斯滤波函数为其中,x与y分别为像素点的横纵坐标;
(404)在两个尺度空间内的每组的上下两端分别加入过渡层,得到两个新的尺度空间;其中,上端过渡层由本组最上层经过高斯滤波得到,下端过渡层由前组的最上层经过降采样与高斯滤波得到,最底层为原始图像;
(405)利用FAST算子对两个新的尺度空间的每一层的每一个点进行计算,得到所有点的特征分数;
(406)将两个新的尺度空间的除过渡层外的每一层的每一个点的特征分数与上下层以及同层中共26个相邻点的特征分数作比较,若该点的特征分数最大或最小,则判定该点为候选点,比较判定后得到两组候选点;
(407)分别计算两组候选点的特征分数的微分与二阶微分,并根据两组候选点的特征分数的微分与二阶微分计算得到两组候选点的亚像素级横纵坐标;
(408)利用小波扇形环绕对两组具有亚像素级横纵坐标的候选点分别赋予方向得到两组特征点。
其中,步骤五具体包括以下步骤:
(501)利用Scharr算子分别对两张待匹配图像进行计算,得到两张待匹配图像的图像梯度;
(502)根据得到两张待匹配图像的图像梯度分别计算得到两张待匹配图像的二阶标准偏导数;
(503)以特征点为中心,以24σi为边长,以特征点方向为纵轴方向,确定一个正方形邻域;其中,σi为定向的特征点的尺度参数;
(504)将正方形邻域分成16个相同的子正方形邻域,将每个子正方形邻域的大小扩展为9σi×9σi,相邻的扩展后的子正方形邻域有宽度为2σi的交叠带,所有扩展后的子正方形邻域组成描述网格;
(505)利用高斯核为2.5σi的高斯函数对每个扩展后的子正方形邻域内所有点的二阶标准偏导数及其绝对值进行加权求和,得到4维向量;
(506)连接16个扩展后的子正方形邻域内的4维向量得到一个64维向量,对该64维向量归一化处理到单位长度后得到该特征点的特征向量;
(507)重复步骤(503)至步骤(506),直至两张待匹配图像中的所有特征点均被特征描述完毕且得到各自的特征向量。
本发明相比背景技术的优点在于:
本发明提出基于特征匹配的目标实时识别方法,首先利用快速自适应鲁棒性尺度不变的特征检测子(fast adaptive robust invariant scalable feature detector,FARISFD)与鲁棒性交叠的标准特征描述子(robust overlapped gauge feature descriptor,ROGFD)来增强算法的鲁棒性与实时性,其次利用基于KD(k-dimensional)树的BBF(bestbin first)算法与双向匹配结合的方法提高搜索效率,再次利用PROSAC(Progressive Sample Consensus)去除错误点完成匹配,最后根据平均匹配率完成目标识别。FARISFD与ROGFD较传统特征检测子与描述子具有更强的鲁棒性与实时性,基于特征匹配的目标实时识别方法能够实现可靠性较强的目标实时识别。
附图说明
图1表示算法流程示意图。
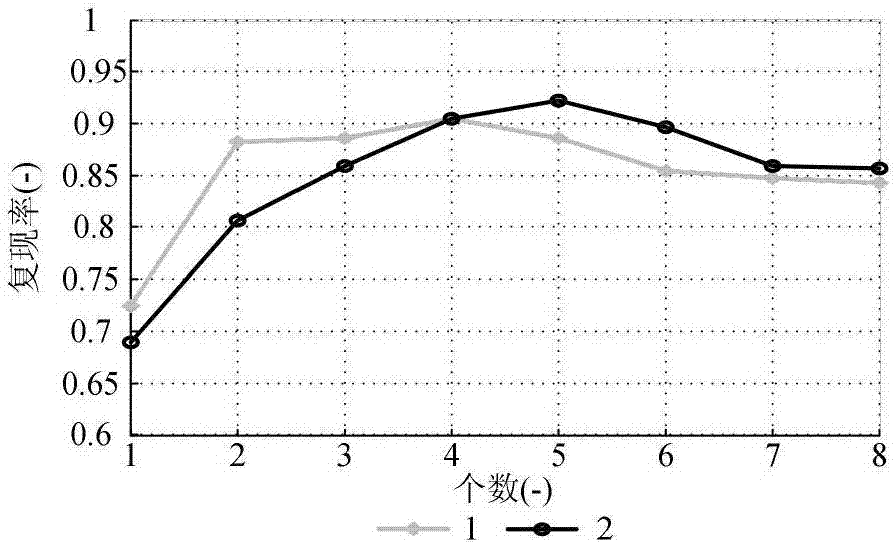
图2表示尺度空间的总组数与尺度空间的每组中总层数对FARISFD复现率的影响。
图3表示图像尺寸对尺度空间的总组数最优值的影响。
图4表示FARISFD尺度空间示意图。
图5表示ROGFD描述网格示意图。
具体实施方式
下面结合附图和具体实施例对本发明做进一步描述。
本实施方式阐述了基于特征匹配的目标实时识别的原理,按照图像预处理、特征检测、特征描述、特征匹配、紧致化、目标判别的思路进行计算,着重对目标实时识别算法流程进行优化改进,并分别将特征检测子和特征描述子与传统算法进行鲁棒性和实时性对比,同时实现基于特征匹配的目标实时识别方法以说明本发明的优势所在。其具体步骤如下:
步骤一:获取已有目标的不同角度的图像,并根据获取的图像为每一个已有目标建立一个模板库,所有已有目标的模板库构成一个模板库集合;
步骤二:实时获取待识别目标的图像;
步骤三:利用灰度均匀化算法对待识别目标的图像与某个模板库中的模板分别进行预处理,得到对应的两张待匹配图像;其中,模板是指模板库中存储的目标的某一角度的图像;
步骤四:利用FARISFD检测子分别对两张待匹配图像进行特征检测获得两组特征点;
(401)分别将两张待匹配图像的尺度空间的每组中总层数定为4;
(402)根据两张待匹配图像的行数与列数分别求出两张待匹配图像的尺度空间的总组数;
为使特征点具备尺度不变性,需建立尺度空间。尺度空间的构建一般由组与层构成,逐组进行降采样,逐层进行滤波。对于不同尺寸图像,总组数O与每组中总层数Q过大会导致构造尺度空间耗时较长,检测点过多;O与Q过小会导致匹配率下降,因此研究如何选取尺度空间O与Q具有重要意义。按照Lowe等人的理论、实验方法及实验图像数据,本文详细测定了总层数与总组数对FARISFD鲁棒性的影响,经Lowe等人说明,该实验方法与实验图像数据是具有代表性的。
如图2所示,1图线为:O定为4,FARISFD的复现率随Q变化的图线,2图线为:Q定为4,FARISFD的复现率随O变化的图线,将实验结果分析如下:
(1)随着Q的增加,FARISFD的鲁棒性先增强后减弱。
这是由于随着Q增加,滤波程度加深,经过非极值抑制计算出的极值点增多,但极值点的稳定性下降,Q增加到一定程度后,极值点在变换后的图像中就难以检测到了,导致检测子的鲁棒性先增强后减弱。实验测定Q为4时,FARISFD鲁棒性最强。
(2)随着O的增加,FARISFD的总体鲁棒性先增强后减弱。
这是由于随着O增加,降采样程度加深,经过非极值抑制计算出的极值点增多,但极值点的稳定性下降,导致检测子的鲁棒性先增强后减弱。由于降采样的影响,使输入图像尺寸对于极值点个数影响较大,从而影响了O的最优值。如图3所示,经过实验测定,O的最优值与图像尺寸的对数正相关。
为改善特征检测子处理不同图像的鲁棒性与运行效率,本文提出一种尺度空间组数自适应选取方法:将每组中层数定为4,且各组层数相等,根据图像尺寸的对数来自适应选取O,公式如下:
式中,X与Y分别为原始图像的行数与列数,[]表示取整(四舍五入)。
(403)将两张待匹配图像分别根据各自的尺度空间的总组数与尺度空间的每组中总层数,按照SIFT算法分别构建两个尺度空间,其中高斯滤波函数为其中,x与y分别为像素点的横纵坐标;
广泛使用的滤波方法包括高斯滤波与非线性滤波,虽然KAZE与Accelerated-KAZE使用非线性尺度空间取得了巨大成功,但经本实验测试,在非线性尺度空间内检测与在高斯尺度空间内相比各方面鲁棒性与速度均较低。又由于降采样的影响,尺度空间中组与组的图像尺寸不同,两组之间层的点对应性较差,导致尺度空间连续性较弱。综合考虑鲁棒性与速度,提出一种基于过渡层的尺度空间构建方法,原理如下:
如图4所示,尺度空间的每组是由原始图像逐次进行0.5倍降采样获得,每层是由原始图像逐次进行高斯滤波获得,进化方向由下至上,尺度空间构建公式如下:
式中,o表示组,s表示层,S为总层数,x与y分别为像素点的横纵坐标,Lo×S+s(x,y)为o组s层进化图像,G(x,y)为高斯函数,I(x,y)为原始图像。
(404)在两个尺度空间内的每组的上下两端分别加入过渡层,得到两个新的尺度空间;其中,上端过渡层由本组最上层经过高斯滤波得到,下端过渡层由前组的最上层经过降采样与高斯滤波得到,最底层为原始图像;
在每组两端构建尺度过渡层(图4中红色层),构建公式如下:
式中,Zo(x,y)为o组的下端过渡层,Ho(x,y)为o组的上端过渡层。
(405)利用FAST算子对两个新的尺度空间的每一层的每一个点进行计算,得到所有点的特征分数;
选择合适的特征分数计算方法是在尺度空间中找到特征点的必要条件。在众多特征分数计算方法中,FAST的鲁棒性与速度优势是极为显著的,与海森矩阵等检测法相比,该算法大幅提高了运行速度,同时保证了检测效果。鉴于BRISK引入AGAST计算分数取得的成功,本实验引入FAST计算特征分数,这是因为AGAST虽然改进了FAST的决策树,提高了检测效率,但二者计算特征分数方法相同,且OpenCV对FAST计算分数的优化强于AGAST,在实验中基于FAST计算分数比基于AGAST计算更快。
计算特征分数的模板为:以待检测点为圆心,半径为3个像素的Bresenham圆。经Rosten测试,9个像素参与比较的模板检测性能较强。所以本文利用FAST9-16(圆周上共有16个像素,需比较像素的个数为9)计算特征分数,其原理如下式所示:
Sbright={x|Ip→x≥Ip+t} (5)
Sbark={x|Ip→x≤Ip-t} (6)
式中,V为特征分数,x为圆周上任意一点,Ip→x为圆周上任意一点灰度值,Ip为圆心灰度值,t为阈值,Sbright与Sbark分别为亮点集与暗点集。按此法计算尺度空间每一层的特征分数V。
由于t的设定与图像灰度密切相关,为防止t无法适应不同图像的处理,所以先将输入图像经过光照均衡化处理,然后根据BRISK的理论分析与实验数据,t取30。
(406)将两个新的尺度空间的除过渡层外的每一层的每一个点的特征分数与上下层以及同层中共26个相邻点的特征分数作比较,若该点的特征分数最大或最小,则判定该点为候选点,比较判定后得到两组候选点;
(407)分别计算两组候选点的特征分数的微分与二阶微分,并根据两组候选点的特征分数的微分与二阶微分计算得到两组候选点的亚像素级横纵坐标;
特征点的亚像素级位置对于几何测量和三维重建等是极为重要的,传统亚像素级矫正方法(如:SIFT与SURF等)将候选点的尺度特性引入方程加强收敛,但尺度特性对方程收敛影响较小,同时增加了计算量,有时还因尺度空间连续性差而减弱了检测子的鲁棒性。而BRISK针对AGAST分数提出的亚像素级矫正方法精度不高。基于以上原因,本文简化了传统亚像素级矫正方法,提出了基于特征分数的亚像素级矫正方法,其求解方程如下:
Dxx=V(x+1,y)+V(x-1,y)-2V(x,y) (10)
Dyy=V(x,y+1)+V(x,y-1)-2V(x,y) (11)
Dxy=V(x+1,y+1)+V(x-1,y-1)/4-V(x+1,y-1)-V(x-1,y+1)/4 (12)
式中,dx与dy分别为待求的候选点亚像素级横纵坐标,V(x,y)为候选点的特征分数,x与y分别为候选点的横纵坐标。
(408)利用小波扇形环绕对两组具有亚像素级横纵坐标的候选点分别赋予方向得到两组特征点。
步骤五:利用ROGFD描述子分别对两组特征点进行特征描述获得两组特征向量;
(501)利用Scharr算子分别对两张待匹配图像进行计算,得到两张待匹配图像的图像梯度;
图像梯度是基于灰度分布描述子的基础。在众多梯度计算方法中,Scharr算子的鲁棒性与速度优势是极为显著的。针对图像邻域相关性不大、信号随机性较强的特点,Scharr算子改进了Sobel算子,使用标准差相对较小的高斯函数进行邻域平滑,即利用更瘦高的固定模板求取图像梯度,所以Scharr算子对突变信号有较强的响应,具有更好的旋转与模糊不变性。与SURF等算子采用的小波响应相比,该算子大幅度增强了鲁棒性,同时保证了运行效率。Scharr算子包含横纵两个模板,通过与图像卷积产生对应的梯度矢量,其原理如下式所示:
式中,Gx表示一阶横向偏导数矩阵;Gy表示一阶纵向偏导数矩阵,I表示待处理图像;G表示梯度值矩阵;θ表示梯度方向矩阵。
(502)根据得到两张待匹配图像的图像梯度分别计算得到两张待匹配图像的二阶标准偏导数;
仅利用图像梯度或近似梯度进行描述具有较高的运行效率,但会导致描述子区分力不高,且模糊、照度及旋转不变性较弱,为改善描述子的鲁棒性,ROGFD引入标准坐标系(Gauge Coordinates)下的二阶偏导数Lww与Lvv。标准微分响应是计算机视觉中十分重要的工具,在尺度变换下能够保持良好的旋转不变性与照度不变性,在不同尺度下,Lww能够测量模糊变换的相关信息,同时Lvv具有良好的边缘响应,所以标准微分响应对模糊具有较强的鲁棒性。标准微分响应的原理如下式所示:
式中,Lww、Lvv表示二阶标准偏导数,dx、dy为灰度一阶偏导数,dxx、dyy与dxy为二阶灰度偏导数。一、二阶偏导数由Scharr算子计算得到。
(503)以特征点为中心,以24σi为边长,以特征点方向为纵轴方向,确定一个正方形邻域;其中,σi为定向的特征点的尺度参数;
(504)将正方形邻域分成16个相同的子正方形邻域,将每个子正方形邻域的大小扩展为9σi×9σi,相邻的扩展后的子正方形邻域有宽度为2σi的交叠带,所有扩展后的子正方形邻域组成描述网格;
描述子的分块方式对描述子的区分性与不变性具有直接影响。传统描述子的分块方式过分分割了空间,破坏了描述网格的连续性,导致描述子的性能下降,为解决此问题,ROGFD构建了描述网格交叠带,来减小网格分割空间影响。ROGFD描述网格如图5所示。以特征点为中心,以24σi为边长(σi为特征点的尺度参数)确定一个正方形邻域,将正方形邻域分成16个相同的子正方形邻域,将每个子正方形邻域的大小扩展为9σi×9σi,扩展后的相邻子正方形邻域有宽度为2σi的交叠带,所有子正方形组成ROGFD描述网格。
(505)利用高斯核为2.5σi的高斯函数对每个扩展后的子正方形邻域内所有点的二阶标准偏导数及其绝对值进行加权求和,得到4维向量;
(506)连接16个扩展后的子正方形邻域内的4维向量得到一个64维向量,对该64维向量归一化处理到单位长度后得到该特征点的特征向量;
首先旋转网格,使网格y轴正方向与特征方向一致。然后使用Scharr算子计算每一个子正方形区域内所有点,得到一阶偏导数dx、dy,进而计算二阶标准偏导数Lww、Lvv。再对每个扩展后的子正方形邻域内所有点的Lww、Lvv、|Lww|、|Lvv|进行加权求和,得到一个4维向量V(∑Lww,∑Lvv,∑|Lww|,∑|Lvv|),连接16个子块区域的向量得到4×4×4=64维向量,最后为使描述符具有照度不变性,将该向量归一化到单位长度得到ROGFD描述符。
由于二阶标准偏导数本质上是加权的梯度函数,其权重与图像结构密切相关,所以在连接16个子块区域时,不需要进行高斯加权处理,从而提高了运行速度。同时二阶标准偏导数具有较强的旋转不变性,因此只需旋转网格即可保证描述子的旋转不变性。
(507)重复步骤(503)至步骤(506),直至两张待匹配图像中的所有特征点均被特征描述完毕且得到各自的特征向量。
步骤六:利用基于KD树的BBF算法与双向匹配法对两组特征向量进行快速匹配得到特征对应关系,再利用PROSAC算法对特征对应关系进行计算,得到两张待匹配图像间的单应性矩阵与内点数目;
步骤七:根据内点数目与模板图像特征点数目计算得到匹配率;
步骤八:重复步骤三至步骤七,直至模板库中的所有模板均与待识别目标的图像进行匹配完毕且得到各自的匹配率;
步骤九:根据模板库中的所有模板分别与待识别目标的图像进行匹配得到的所有匹配率,计算得到该模板库的匹配率平均值;
步骤十:将模板库集合中的每个模板库的匹配率平均值进行比较,将待识别目标判定为匹配率平均值最高的模板库所对应的已有目标;
本方法以目标图像与模板库的平均匹配率作为评判标准,平均匹配率越高,则判定目标与模板库越相似。平均匹配率为待识别目标图像的已匹配特征点数与某个模板库中每个模板的总特征点数比值的平均值,定义式如下:
式中,H为平均匹配率,k为模板库中模板总数,Mi为待识别目标图像与第i个模板匹配的特征点数,Ni为第i个模板中的总特征点数。
完成基于特征匹配的目标实时识别。
- 还没有人留言评论。精彩留言会获得点赞!