一种采用稀疏编码的自然语言语义深度解析算法的制作方法
本发明涉及神经网络对自然语言处理的领域,尤其涉及采用深置信度神经网络和稀疏编码方法,对自然语言进行语义深度解析的一种采用稀疏编码的自然语言语义深度解析算法。
背景技术:
现如今,自然语言语义解析在各个领域的应用十分广泛。对于文本特征选择时,存在语义表征不明确的问题,这主要是由于文本中词语间出现歧义或近义而难以辨析所导致。这一问题的解决与否几乎决定了自然语言处理的效果。由于稀疏编码算法是一种无监督学习方法,通过寻找一组“超完备”基向量来更高效地表示样本数据。同时其还具备编存储能力大,具有联想记忆能力,计算简便,使自然信号的结构更加清晰的优点。所以本专利采用稀疏编码的方式处理现存的这一问题,在本专利中采用稀疏编码的方法将作为样本数据的词与词间的向量空间距离拉大,使原本有相近或歧义含义的词间的细微差别扩大化,有效的将具有歧义或近义的词分开,使得文本中的整体语义更加符合文本作者的真实意图,为提高处理大量自然语言语义解析的准确性提供了便利。
技术实现要素:
本发明的目的就在于为了解决上述问题而提供一种采用稀疏编码的自然语言语义深度解析算法。
本发明通过以下技术方案来实现上述目的:
本发明包括以下步骤:
1)采用基于统计的分词方法。在训练文本中,通过计算字x与字y的组合度大小,从而来判断字x与字y是否是同一个单词。其组合度的计算公式如下:
其中,hxy为字x与字y的组合度大小,k为文本中xy组合的个数,n1为文本中字x的个数,n2为文本中字y的个数,n为文本的总字数。
2)采用word2vec对分好的词组进行转化。将分好词的文本语料作为word2vec的输入文件并指定合适的训练参数,进行中文词向量的训练,得到最佳的词语对应的词向量。
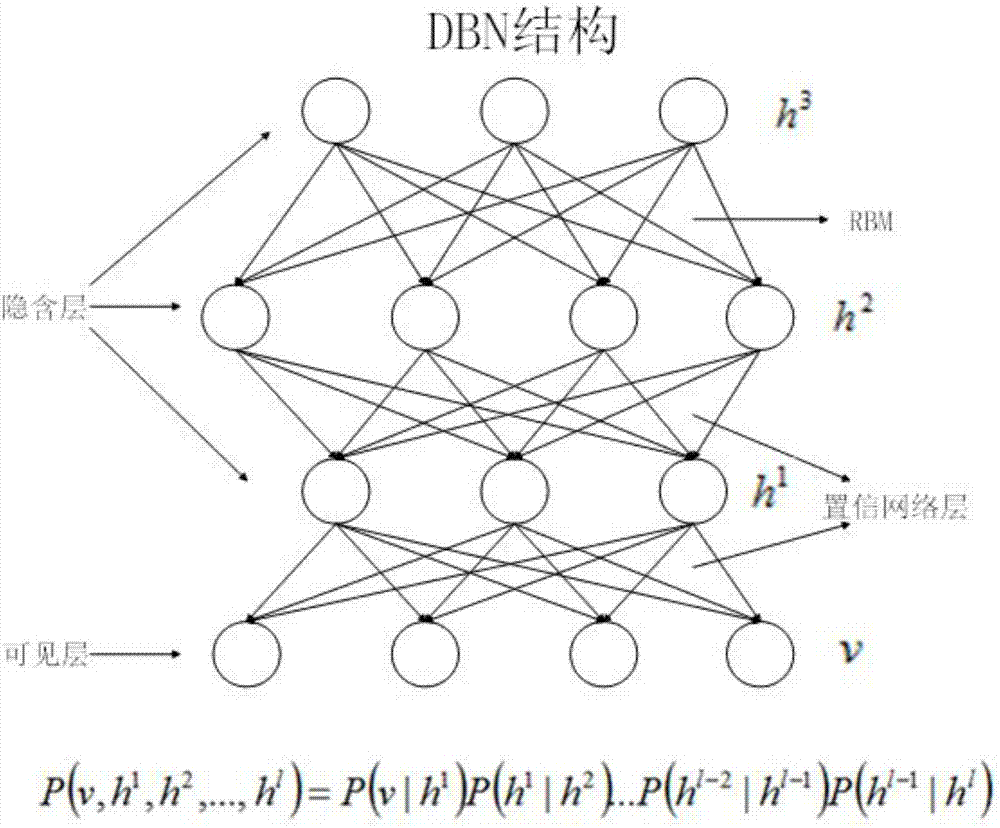
3)搭建dbn神经网络,将转换好的词向量输入dbn神经网络中进行稀疏编码神经网络的训练,得到训练好的稀疏编码器。稀疏编码将多维的数据进行线性分解,进行线性转换,表达如下:
s=mx(2)
其中,m为稀疏变换矩阵,其每一个行向量类似于小波变换中的小波基;s为线性转换后的稀疏分量,满足稀疏分布的要求。
4)通过步骤3)的训练,将训练文本的词向量序列输入这个训练好的稀疏编码器中,得到文本的稀疏特征。
5)将步骤4)中得到的稀疏特征进行分类和解析。搭建dbn神经网络,将稀疏特征输入dbn中,对其进行训练,得到语义的解析结果。这个过程包括以下算法:
搭建深度置信神经网络dbn,利用tf-idf方法选取特征项,经过受限玻尔兹曼机rbm网络预训练和反向传播bp神经网络微调来训练dbn网络模型,拟合训练数据集的分布,重构出测试数据集的分类模型。
其条件分布可表示为:
其中,σ=1/(1+e-x),为sigmoid激活函数。
rbm作为一个系统,其能量函数形式如下:
其中,θ=(w,a,b)是rbm的参数。
基于能量函数,可得到(v,h)的联合分布概率为:
p(v,h|θ)=1/(z(θ))e-e(v,h|θ)(6)
其中,z(θ)为归一化因子,为所有可视层和隐含层概率的和,即:
p(v,h|θ)对h的边缘分布为:
rbm采用迭代的方式进行训练,求出参数θ=(w,a,b)的最优值。利用最大似然学习可得参数的更新公式如下:
δai=ε(<vi>data-<vi>model)(11)
δbj=ε(<hj>data-<hj>model)(12)
其中,t为输入样本数目;<>data表示训练集所定义的分布之上的数学期望;<>model表示初始模型所定义的分布之上的数学期望;ε为学习率。
本发明的有益效果在于:
本发明是一种采用稀疏编码的自然语言语义深度解析算法。在对含有歧义、近义词语或是有不同语义段落的文本进行解析时,与其它方法相比,本专利采用了将词向量进行稀疏编码的方式且充分利用稀疏编码具备编存储能力大,具有联想记忆能力,计算简便,使自然信号的结构更加清晰的优点,将作为样本数据的词与词间的向量空间距离拉大,使原本有相近或歧义含义的词间的细微差别扩大化不仅有效的将具有歧义或近义的词分开,同时还使得文本中的整体语义更加符合文本作者的真实意图,为提高处理大量自然语言语义解析的准确性提供了便利。
附图说明
图1为整体结构流程框图。
图2为dbn网络结构图。
具体实施方式
如图1、2所示,本发明各部分具体实施细节如下:
1、预训练文本。该过程包含以下3个步骤:
(1)将预训练文本进行分词得到词组;
(2)将上述分好的词通过word2vc转换成词向量;
(3)搭建dbn神经网络,将完成转换的词向量输入dbn中,得到稀疏编码器。
2、训练文本。该过程包含以下4个步骤:
(1)将训练文本进行分词得到词组;
(2)将上述分好的词通过word2vc转换成词向量;
(3)把完成转换的词向量输入上述步骤1中得到的稀疏编码器中,从而得到词组的稀疏编码特征;
(4)搭建dbn神经网络,将上述得到的稀疏编码特征输入dbn中进行训练,得到训练好的dbn网络语义解析器。
3、测试文本。该过程包含以下3个步骤:
(1)将测试文本进行分词得到词组;
(2)将上述分好的词通过word2vc转换成词向量;
(3)把上述完成转换的词向量输入步骤2中训练好的dbn网络语义解析器中,得到最终的自然语言语义解析结果。
以上显示描述了本发明的基本原理和主要特征及本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
- 还没有人留言评论。精彩留言会获得点赞!