一种基于多级特征的问题和答案句子相似度计算方法与流程
本发明涉及自动问答技术领域,具体涉及一种计算问题句子和答案句子相似度的方法。
背景技术:
自动问答系统是一种输入自然语言问句后能够直接返回精确答案的系统。根据自动问答系统背后的数据源的类型可以将其分为两类,分别是基于知识图谱的自动问答系统和基于非结构化文档的自动问答系统。基于非结构化文档的自动问答系统的数据源是大量非结构化的文本文档,其检索答案的过程主要包括以下几个步骤:
(1)根据关键词匹配算法,检索出与问题相关的段落。
(2)将第一步检索出的段落切分成句子,形成答案句子候选集。
(3)计算问题和候选答案句子相似度并排序。
(4)选择最相似度最高的答案句子进行答案抽取,返回给用户。
其中的第三步,计算问题和答案句子相似度是非常重要的一步。传统的计算句子相似度的算法主要包括三种:
(1)基于词的算法。该方法不对语句进行语法结构分析,只利用句子的表层信息,即组成句子的词的词频、词性等信息。该方法不能考虑句子的整体结构和语义相似性。
(2)基于句法的算法。该方法对语句进行句法分析,找出依存关系,并在依存关系分析结果的基础上进行相似度计算。该方法能衡量句子的句法结构相似性,但是不能衡量句子的语义相似性。
(3)基于深度神经网络的算法。该方法将语句中每个词的词向量输入到卷积神经网络或循环神经网络中,输出为一个句子的向量表达。该方法能够衡量句子的语义相似性,但是词和句法的相似性并不能得到充分表达。
传统的计算句子相似度的方法各有优缺点,都不能全面的衡量两个句子之间的相似性。
技术实现要素:
为了克服传统的计算句子相似度算法的不足,本发明提供了一种基于多级特征的问题和答案句子相似度计算算法,该算法能够全面衡量两个句子之间的相似性。
该算法公式定义如下:
其中,q是给定的一个问题句子,s是给定的一个候选答案句子。定义衡量两个句子相似度的函数为r(q,s),r(q,s)是一个线性函数,是多个相似度得分函数的集成。这里的hk(s,q)代表第k个相关性函数。
本发明设计了五种特征来衡量两个句子之间的相关性,这些特征包含了不同的级别,分别是单词特征、短语特征、句子语义特征、句子结构特征、答案类型特征。
1.单词特征
单词级别的特征是从单词出发,计算两个句子在单词方面相似度。本发明使用了四种单词级别的特征,分别如下:
(1)共同的单词数特征,每个单词共现次数都要乘以idf权重。定义为hwm(q,s)。
(2)单词翻译特征,直接使用成熟的翻译模型giza++,以及问题和相关问题的语料库来得到问题句子和答案句子之间的翻译概率,以此作为两个句子之间的相关性得分。定义为hwt(q,s)。
(3)词向量平均特征,将每个句子中的单词对应的词向量相加求平均作为该句子的句子向量,然后求答案句子向量和问题句子向量之间的余弦距离。定义为hwv(q,s)。
(4)词向量转移距离(wmd)特征,采用wmd计算相似度的方法(该方法可参考:kusnermj,suny,kolkinni,etal.fromwordembeddingstodocumentdistances),将两个句子去除停止词,然后计算词向量转移的最小距离作为两个句子之间的相关性。定义为hwmd(q,s)。
2.短语特征
假设抽取的短语列表为pp={<si,ti,p(ti|si),p(si,ti)>},其中si是答案句子中的一个短语,ti是问题句子中的一个短语,p(ti|si)和p(si,ti)分别代表从si翻译成ti和从ti翻译成si的概率。
接着,定义基于短语的相似性得分函数如下:
其中,q,s分别是问题和答案句子,
(1)如果
(2)否则如果有
(3)否则,
简单可以描述为,当答案句子中的短语直接出现在问题句子中时,该短语的得分就是1,如果该短语与问题句子中的某些短语出现在短语表中,意味着两个短语是同义的短语或者相关短语时,该短语得分就是短语表中短语互相翻译概率的乘积,是一个0,1之间的值。如果该短语不满足以上两种情况,那么该短语的得分就是0。计算答案句子中一到n元语法包含的所有短语与问题句子的相关性得分,最后对n求平均。
3.句子语义特征
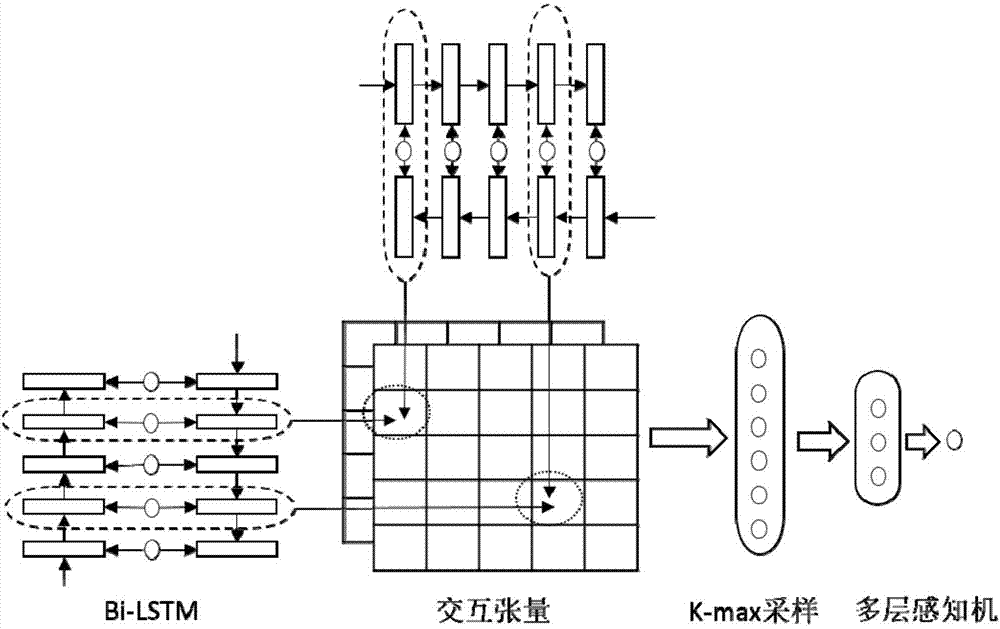
该特征使用最新的基于深度学习的计算两个句子相似度的模型来获得语义相似度得分(可参考wans,lany,guoj,etal.adeeparchitectureforsemanticmatchingwithmultiplepositionalsentencerepresentations)。将该特征定义为hsem(s,q),该模型首先将问题句子和答案句子分别用bi-lstm(bidirectionallongshorttermmemory)计算两个句子每个位置的向量表达,两个句子的不同位置进行交互形成新的矩阵和张量,然后接k-max采样层和多层感知机进行降维。最后输出两个句子的相似度。bi-lstm是将句子序列正向输入一次lstm,然后再反向输入一次lstm。这样每个时刻都有两个向量表达,分别是前向的
其中,u,v分别代表两个向量,wi,i∈[1,…,c]是张量的一个切片。wuv和b是线性变换的参数。f是非线性函数。经过张量函数变换后的结果是一个向量。
接来下利用k-max采样从交互张量的每一个切片中选择出k个最大的值,然后将所有切片的值拼接成一个向量。最后需要用多层感知机将高维的向量降到一维的标量,这个标量经过线性变换后就是两个句子的相似度得分。公式如下:
r=f(wrq+br)
s=wsr+bs
其中,wr和ws是参数矩阵,br和bs是相应的偏置向量。
最后,我们需要设计损失函数。本文的任务是排序,因此直接使用合页损失函数(hingeloss)。给定一个三元组
其中,
4.句子结构特征
本发明使用了两种句子结构特征:
(1)依存树根匹配
定义为hrm(s,q),这是一个取值为0,1,2的特征。如果问题句子和答案句子对应的依存关系拥有相同的根,则hrm(s,q)=2,否则如果答案句子包含问题句子的根或者问题句子包含答案句子的根,则hrm(s,q)=1。如果上面两种情况都不存在则,hrm(s,q)=0。
(2)依存关系匹配。
定义为hdm(s,q)。首先找到两个句子中共同的词,这里称为一对锚点。在两个句子中可能会出现多对锚点。然后分别计算出两个句子的依存关系。统计两个依存树从根出发到锚点的相同依存关系的数目,即得到hdm(s,q)。两个句子依存树的根并不一定相同,因此这里的相同的依存关系指的是关系,而忽略词汇的差异。
5.答案类型特征
首先对问题进行分析,根据问题的疑问词来判断问题类型。同时根据事先定义好的分类目录表来找到所需的答案类型。本发明定义了答案类型匹配特征ham(s,q)。算法步骤如下:
(1)首先,分析问题,推理出所需答案类型。
(2)对答案句子进行命名实体识别和词性标注。
(3)判断答案句子中命名实体是否包含问题所需答案类型,如果包含则,ham(s,q)=1,如果不包含,ham(s,q)=0。对于有比较明确的答案类型,比如“money,number,person”等,可以根据命名实体识别来识别,对于“nnp”词性的答案,可以根据词性标注进行识别。最后,对于命名实体识别和词性标注都无法确定的答案类型,比如“reason”或者“manner”等默认ham(s,q)=1。
将上述五种级别中所有特征的相似度得分进行加权求和得到总体的相似度得分;即得到两个句子之间的相似度。
综上,本方法的主要优点在于,该方法使用多级特征全面衡量两个句子之间的相似性,克服了传统方法中计算句子相似度时过于片面的缺点。
附图说明
图1是本发明计算句子相似度的整体架构图;
图2是本发明所述句子语义特征模型示意图;
图3是本发明所述句子结构特征依存关系示意图。
具体实施方式
下面将结合附图和实例对本发明作进一步的详细说明。
如图1所示,本发明提出的衡量问题和答案句子相似度的方法共包括五种特征函数,每种特征函数分别用来衡量两个句子之间不同角度的相似性。其中,单词级别的特征是从单词出发,计算两个句子在单词方面相似程度。短语级别的特征能够处理局部上下文依赖问题,能够很好的匹配到习语和常用词的搭配。句子语义特征能够衡量两个句子在含义方面的相似性。句子结构特征能够衡量两个句子在语法和句法方面的相似性。答案类型特征能够衡量答案句子中是否包含问题所需答案类型。最后,通过线性函数将这五种特征函数进行加权求和,形成基于多级特征的问题和答案句子相似度算法。该算法能够全方面衡量问题句子和答案句子之间的相似性。
关于数据集
本发明用于衡量英语问题和答案句子之间的相似度,选用squad数据集对模型进行训练。squad数据集包含了536篇维基百科中的文章,共23215个段落,每个段落都人工提问不超过5个问题。总共的问题数超过十万。原数据集只公开了训练集和验证集。为了完成模型的评价,本文将原有的训练集和验证集进行合并,重新按照8:1:1的比例划分训练集,验证集和测试集。划分过程中每个段落和这个段落的所有问题是一个基本的划分单元。
将段落切分成句子,将每个段落切分成答案句子候选集,这样每个问题只需要对所属段落中的句子进行排序来找到答案句子,候选集规模比较小。虽然数据集中并没有给出问题所对应的答案句子。但是给出了每个问题答案的起始位置,我们根据答案的起始位置可以设计算法定位该问题所对应的句子。本发明直接使用corenlp对段落进行句子的切分。
使用corenlp对段落中的句子以及该段落的问题进行分词、词性标注、命名实体识别、句法分析树和依存关系分析。本文使用java语言调用公开的corenlp工具包。
本实例从单词特征、短语特征、句子语义特征、句子结构特征、答案类型特征共五级特征来衡量两个句子之间的相关性,分别是:
1.单词特征实施方式
首先对于单词特征函数hwt(q,s),本发明使用giza++来训练一个有11.6m个问题和相关问题的平行语料库,该语料库是从wikianswers网站上爬取的。对于hwv(q,s)函数,本发明直接使用word2vec模型训练维基百科语料库。
2.短语特征实施方式
对于短语特征函数hpp(s,q),本发明直接使用moses来训练squad数据集。squad数据集先经过预处理步骤,然后将训练集中的每个问题和对应的答案句子放在一起形成一个问题到答案的平行语料库,共有81345对句子。然后输入到moses中训练得到短语表。
3.句子语义特征实施方式
如图2所示,问题句子和答案句子输入到bi-lstm中,得到每个时刻的向量表达。然后将两个句子的各个时刻的向量进行交互,形成交互张量。接来下利用k-max采样从每一个切片中选择出k个最大的值,然后将所有切片的值拼接成一个向量。最后需要用多层感知机将高维的向量降到一维的标量,这个标量经过线性变换后就是两个句子的相似度得分。
对于句子语义特征函数hs(s,q),本发明首先构建正负样本的集合。对于一个问题,其对应的正确句子为正样本,对应段落中的其他句子作为负样本。训练集中每个问题有一个正样本,同时随机采样两个负样本。这样每个问题对应了三个训练样本,共244035个样本。验证集和测试集采取同样的方式,分别有30144和30864个样本。我们使用基于theano的keras实现双向的lstm模型。训练过程中批的大小为128,优化器选择adagrad。模型训练的终止条件是验证集上的错误率不再下降。
4.句子结构特征实施方式
图3是问题句子和答案句子的依存关系示意图。图中的箭头代表依存关系,箭头的发出单词是支配词,箭头的接受端是被支配词。在实际的问答当中,问题句子和答案句子的依存关系往往存在相似性,比如对于问题句子“wherewasobamaborn?”和答案句子“obamawasborninhonolulu.”。可以看出两句话的依存关系基本一样。“where”和“honolulu”刚好对应,都是“born”的修饰词。
首先找到两个句子中共同的词,这里称为一对锚点。在两个句子中可能会出现多对锚点。然后分别计算出两个句子的依存关系。统计两个依存树从根出发到锚点的相同依存关系的数目。两个句子依存树的根并不一定相同,因此这里的相同的依存关系指的是关系,而忽略词汇的差异。以图3中的问题和答案句子为例,两个句子的拥有相同的根,因此hrm(s,q)=2,两个句子除根外有两个共同单词,而且根到这两对锚点的依存关系相同,因此hdm(s,q)=2。
5.答案类型特征实施方式
数据集预处理之后,每个句子都进行了命名实体识别,问题句子在问题处理模块中也有相应的答案类型。根据简单的匹配就可以计算出来。
以上是所有特征函数的实现细节,在所有特征函数训练和计算完成后,我们需要把这些特征函数进行线性加权融合。线性模型的参数为每个特征函数的权重值。线性模型的目标函数公式为:
其中sx代表问题句子,
- 还没有人留言评论。精彩留言会获得点赞!