一种基于半监督学习的文本敏感信息识别方法与流程
本发明涉及信息安全技术领域,特别是一种基于半监督学习的文本敏感信息识别方法。
背景技术:
对于现代社会而言,数据是企业的资产,数据是人们的隐私,更是众多行业核心竞争力的体现。对企业的关键敏感数据进行有效保护,就能使企业自身在激烈的商业竞争中立于不败之地;对个人敏感信息进行保护,就能防止其泄露产生社会危害。因此近些年来催生了对敏感数据识别的火热研究。该问题涉及文本挖掘和信息安全等多个领域,是数据安全产品数据防护泄漏DLP(Data Leakage Prevention)的核心技术。
现有的敏感信息识别方法包括基础检测技术和高级检测技术两类。基础检查技术包括正则表达式检测、关键字匹配以及文档属性判别等方法;高级检测技术包括精确数据对比(EDM)、指纹文档对比(IDM)等方法。但是这些方法无一例外需要依赖专家搜集的敏感信息数据集,首先通过对这个数据集进行抽象、分析以及学习形成先验知识(敏感词集或其它),然后利用这些先验知识来判别未知样本的敏感程度。在这个过程中,被用于学习的敏感信息数据集合必须尽可能真实完整的反应所属问题域的敏感信息,否则算法的准确性就会大打折扣。然而现实情况是,标注文档性质的人工成本较高,大量的未知文档更易获取,我们很难得到这样一个完备的敏感数据集,导致这些方法的使用受到了限制。
由此可见,目前的敏感信息识别方法还存在问题,亟待提出一种解决上述问题的方案。
技术实现要素:
本发明所要解决的技术问题是:针对上述存在的问题,提供了一种基于半监督学习的文本敏感信息识别方法。
本发明采用的技术方案如下:一种基于半监督学习的文本敏感信息识别方法,具体包括以下过程:步骤1、基于有标注的敏感文档集和未标注的未知文档集中的学习样本,进行半监督学习,得到分类策略知识库;步骤2、对于待检测的文档进行中文分词和去停词处理,得到该文档中的特征元数据;步骤3、用特征向量对特征元数据进行表示,并提取特征值;步骤4、用分类策略知识库对特征值进行敏感文档性质判断,给出为敏感文档或安全文档的判断结果。
进一步的,所述步骤1中,半监督学习过程为:步骤11、构造敏感文档集和未知文档集;步骤12、根据敏感文档集中的样本训练分类器,获取分类器;步骤13、构造未知文档集的子集U’,利用分类器进行子集U’中文档X′的类别判断;步骤14、若类别判断文档X′为敏感文档,则将文档X′标注加入敏感文档集中,如果类别判断文档X′为安全文档,则从未知文档集中删除文档X′;步骤15、迭代步骤11到步骤14直到未知文档集为空集,输出分类策略知识库。
进一步的,训练分类器的过程为:(1)对敏感文档集的文档进行中文分词和去停词处理;(2)利用SVM算法对处理后的敏感文档集进行特征表示;(3)利用信息增益方法对特征进行提取,保留有效的文本特征;(4)采用libsvm工具训练分类器;(5)进行分类器模型评估,改进训练分类器;(6)结束训练,输出分类器。
进一步的,所述步骤3的具体过程为:步骤31、采用向量空间模型,将文档表示成向量x=(t1,t2,…,tk,…,tn),其中tk表示第k个特征项,用向量xi=(wi1,wi2,…,wik,…,wi|V|),其中wik表示特征tk的权重,即在文档X中的重要程度,其中N为敏感文档集的文档总数,Nk为敏感文档集中出现特征项tk的文档数,TF(tK)为特征项出现的频率;步骤32、采取信息增益方法的特征提取算法来提取特征值。
与现有技术相比,采用上述技术方案的有益效果为:本发明对少量敏感文档进行标注,对大量位置的位置文档集进行半监督学习,提高了敏感信息识别的可扩展能力和实用性;采用该方法形成的分类策略知识库进行待检测文档的分类判断,有效的检测出待检测文档是敏感文档还是安全文档。
附图说明
图1是本发明半监督学习的敏感信息识别方法示意图。
图2是本发明半监督学习流程示意图。
图3是本发明分类器训练流程示意图。
具体实施方式
下面结合附图对本发明做进一步描述。
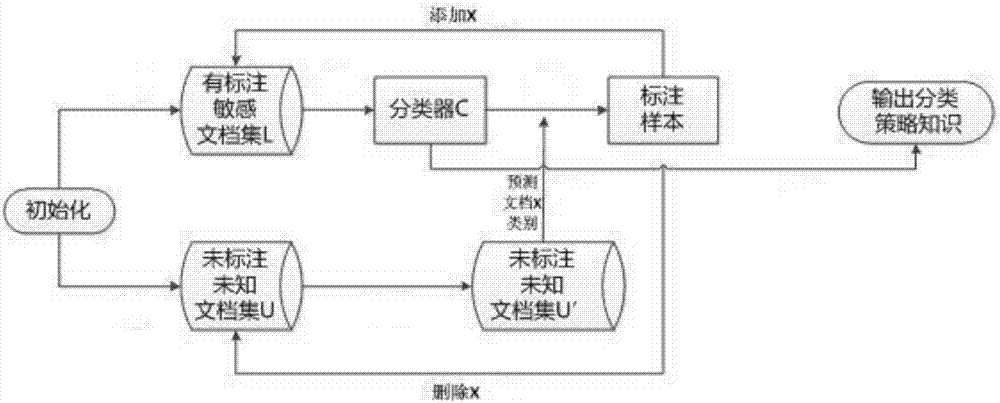
如图1所示,一种基于半监督学习的文本敏感信息识别方法,具体包括以下过程。
(1)基于有标注的敏感文档集L和未标注的未知文档集U中的学习样本,进行半监督学习,得到分类策略知识库。
半监督学习的目的是综合利用有标注和未标注的文档样本形成分离策略知识,在敏感识别问题中,文档分为敏感文档和安全文档(非敏感文档)。如图2所示,半监督学习过程为:
①构造有标注的敏感文档集L和未标注的未知文档集U;
敏感文档集L中存放的是已确认的敏感信息文档集合,未知文档集U中存放的是文档性质不确定的文档集合;类别标签集合C={c1,c2},其中c1表示敏感文档,c2表示安全文档,设有标注的敏感文档集L是带有类别标签的训练集,L={(d1,c1),…,(dN,c1)},其中di表示第i个文档,未标注的未知文档集U为U={x1,…,xN}。
②根据敏感文档集L中的样本训练分类器,获取分类器C;
为了得到分类器C,分类算法可采用K近邻分类算法、贝叶斯分类算法、关联规则分类算法和支持向量机SVM等多种算法。本实施例采用支持向量机SVM算法。训练过程依照图3中所示。训练分类器的过程为:(1)对敏感文档集L的文档进行中文分词和去停词处理;本实施例采用中科院发布的文档词法分析系统(ICTCLAS)进行预处理;(2)利用SVM算法对处理后的敏感文档集进行特征表示;(3)利用信息增益方法对特征进行提取,保留有效的文本特征,缩减文本向量空间的规模;(4)采用libsvm工具训练分类器C;libsvm是台湾大学林智仁副教授开发的一个开源SVM工具软件包。Libsvm提供了训练分类器的工具svmtrain命令,该命令同时提供了对训练过程多种参数的选择,非常灵活和易操作;训练前将上一步得到的数据转化为工具所需要的格式,并存入data_file中;这里设置命令“svmtrain–s 0–c 2–t 1–g 1–r 1–d 3data_file model_file”进行训练,训练结果存入model_file文件中;(5)若分类器准确度不高或者不稳定需要对模型进行调整继续利用上一步骤训练,评估方法采用精度(Precision)和召回率来度量模型的好坏;令TP(cj)表示属于cj类的样本且被正确分为cj的样本数;FN(cj)表示属于cj类样本,但是没有被分为cj类的样本数;FP(cj)表示不属于cj类的样本但是被分为cj类的样本数。精度采用公式计算,召回率采用公式计算;(5)结束训练,输出分类器C,用model_file中训练参数表示。
③构造未知文档集U的子集U',利用分类器C进行子集U'中文档X′的类别判断;用分类器C对U’中的每个文档X′进行预测,使用libsvm提供的类别判断命令svmpredict进行预测,将结果输出到文件output_x_file中。
④若根据output_x_file中的结果,类别判断文档X′为敏感文档,则将文档X′标注加入敏感文档集L中,如果根据output_x_file中的结果,类别判断文档X′为安全文档,则从未知文档集U中删除文档X。
⑤迭代步骤①到步骤④直到未知文档集U为空集,在整个迭代过程中,分类器C不断被更新,最终输出的是依据集合敏感文档集L和未知文档集U中置信度较高的敏感文件得到的最优分类器C,用model_file中的各项参数来描述C,输出分类策略知识库。
(2)对于待检测的文档X进行中文分词和去停词处理,得到该文档X中的特征元数据;
例如,待检测的文档X包括语句“国新办有关南海问题的发布会即将开始,现场已架起了数台摄像机,记者们聚集在现场等待发布会召开”,中文分词的方法有基于词典的最大匹配法、最小分词法,以及基于统计的分词方法等,本实施例选择中科院发布的文档词法分析系统(ICTCLAS)进行处理,中文分词结果为{国新办,有关,南海,问题,的,发布会,即将,开始,现场,已,架起,了,数,台,摄像机,记者,们,聚集,在,现场,等待,发布会,召开};经过分词的文档得到了零散的单词,存在着大量对文本挖掘无用的词语,也就是无关特征,例如“的”、“所以”、“我们”,这类词在文本中出现的频率很高,但是对分析文本并没有太多贡献;另外文档中有一些稀有词,它们出现频率比较低,同样不具有代表性;这两种词语都应该删除,否则会影响文本分析;经过去停词处理后得到特征元数据为{国新办,南海,发布会,架起,摄像机,记者,聚集,等待,发布会,召开}。
(3)用特征向量对特征元数据进行表示,文档X的可以表示为x=(t1,t2,…,tk,…,tn),并提取特征值;
文本特征表示模型有布尔逻辑模型、向量空间模型(Vector Space Model,VSM)、潜在语义索引(Latent Semantic Indexing,LSI)和概率模型等。
本实施例采用向量空间模型。舍弃了各个特征项之间的顺序信息之后,一个文本就表示成向量,也即是文档集中的一个点。具体过程为:(1)采用向量空间模型,将文档X表示成向量x=(t1,t2,…,tk,…,tn),其中tk表示第k个特征项,用向量xi=(wi1,wi2,…,wik,…,wiV),其中wik表示特征tk的权重,即该特征项在文档X中的重要程度,权重用TF-IDF表示,即其中N为敏感文档集L的文档总数,Nk为敏感文档集L中出现特征项tk的文档数,TF(tK)为特征项出现的频率;(2)、采用向量空间模型表示元数据的向量的维数往往会很高,如此高维的特征大大增加分析学习时间。因此需要通过特征提取的过程来提高程序的效率,保证有意义的特征和防止过拟合。特征提取算法包括逆文本频率(TF-IDF)、信息增益(Information Gain)、期望交叉熵(Expected Cross Entropy)。本实施例选用信息增益方法来提取特征值,信息增益的评估函数公式定义如下:
其中,s表示特征项单词词出现,表示特征项单词s不出现,P(s)表示特征项单词s出现的概率,表示特征词s不出现的概率;P(cj)是类cj的先验概率,P(cj|s)是基于s的cj的条件概率,是基于的cj的条件概率。
(4)用分类策略知识库对特征值进行敏感文档性质判断,给出为敏感文档或安全文档的判断结果;
半监督学习训练出来的分类器C输出的分类策略知识库为svm分类器的训练结果,通过libsvm工具获取的训练结果存放在model_file文件中,文件包括了支持向量样本数、支持向量样本以及拉格朗日系数等必须的参数。
libsvm工具包提供了分类预测工具svmpredict,利用svmpredict和model_file可以判断待测试文档X的类别,即敏感文档或安全文档。设test_file为经过格式处理的待检测文档,通过命令“svmpredict test_file model_file output_file”将判断结果存入output_file文件中。
本发明并不局限于前述的具体实施方式。本发明扩展到任何在本说明书中披露的新特征或任何新的组合,以及披露的任一新的方法或过程的步骤或任何新的组合。如果本领域技术人员,在不脱离本发明的精神所做的非实质性改变或改进,都应该属于本发明权利要求保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!