一种出版物发行分析系统和方法与流程
本发明实施例涉及出版发行技术领域,尤其涉及种一种出版物发行分析系统和方法。
背景技术:
随着互联网行业的日益发展,传统出版行业正逐步与互联网接轨。在过去信息量贫乏和渠道单一的时代,出版物的发行和销售一直都处于监控难,信息收集慢的境况。而对于出版发行后的市场反馈信息,更是稀疏不齐。在信息爆炸时代,读者消费出版产品呈现“碎片化”和“瞬变化”特征。图书选题,一直是出版社工作决策的关键一步。及时了解时下热点议题,悉知大众最新的阅读期待和阅读需求,洞见热点图书选题的发展趋势和分布,是出版单位对数据支撑系统的普遍需求。然而现有出版行业信息化程度高,自动化程度低。缺少对出版物发行分析的有效方法,无法为出版发行提供有效的决策信息。
技术实现要素:
本发明提供一种出版物发行分析系统和方法,以对海量数据进行分析和挖掘,为出版发行提供精确和有效的决策信息。
第一方面,本发明实施例提供了一种出版物发行分析系统,该系统包括:
数据采集子系统,用于获取出版物关联的互联网爬虫数据和/或地面销售数据;
清洗层,用于对获取的数据进行清洗,得到原始数据;
数据层,用于存储所述原始数据;
处理层,用于读取所述数据层的原始数据,对所述原始数据进行调度和挖掘分析,得到基础分析数据;
应用分析子系统,用于根据所述基础分析数据得到出版发行分析结果数据;
展现层,用于根据所述出版发行分析结果数据展现分析结果。
第二方面,本发明实施例还提供了一种出版物发行分析方法,该方法包括:
获取出版物关联的互联网爬虫数据和/或地面销售数据;
对获取的数据进行清洗,得到原始数据;
存储所述原始数据;
读取所述数据层的原始数据,对所述原始数据进行调度和挖掘分析,得到基础分析数据;
根据所述基础分析数据得到出版发行分析结果数据;
根据所述出版发行分析结果数据展现分析结果。
本发明实施例提供的技术方案,通过获取出版物关联的互联网爬虫数据和/或地面销售数据,对这些数据进行存储的和相应的处理,得到出版发行分析结果数据,并展示分析结果。即依托丰富的互联网爬虫数据和地面销售数据,基于调度、挖掘和分析,得到出版物发行分析结果数据,分析的维度更加丰富,得出的结果更精确。提供一种有效的出版发行分析方法,为出版发行提供精确和有效的决策信息。
附图说明
图1a是本发明实施例提供的一种出版物发行分析系统的结构示意图;
图1b是本发明实施例提供的另一种出版物发行分析系统的结构示意图;
图1c是本发明实施例提供的另一种出版物发行分析系统的结构示意图;
图2是本发明实施例提供的一种出版物发行分析方法的流程示意图。
具体实施方式
下面结合附图和实施例对本发明作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释本发明,而非对本发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本发明相关的部分而非全部结构。
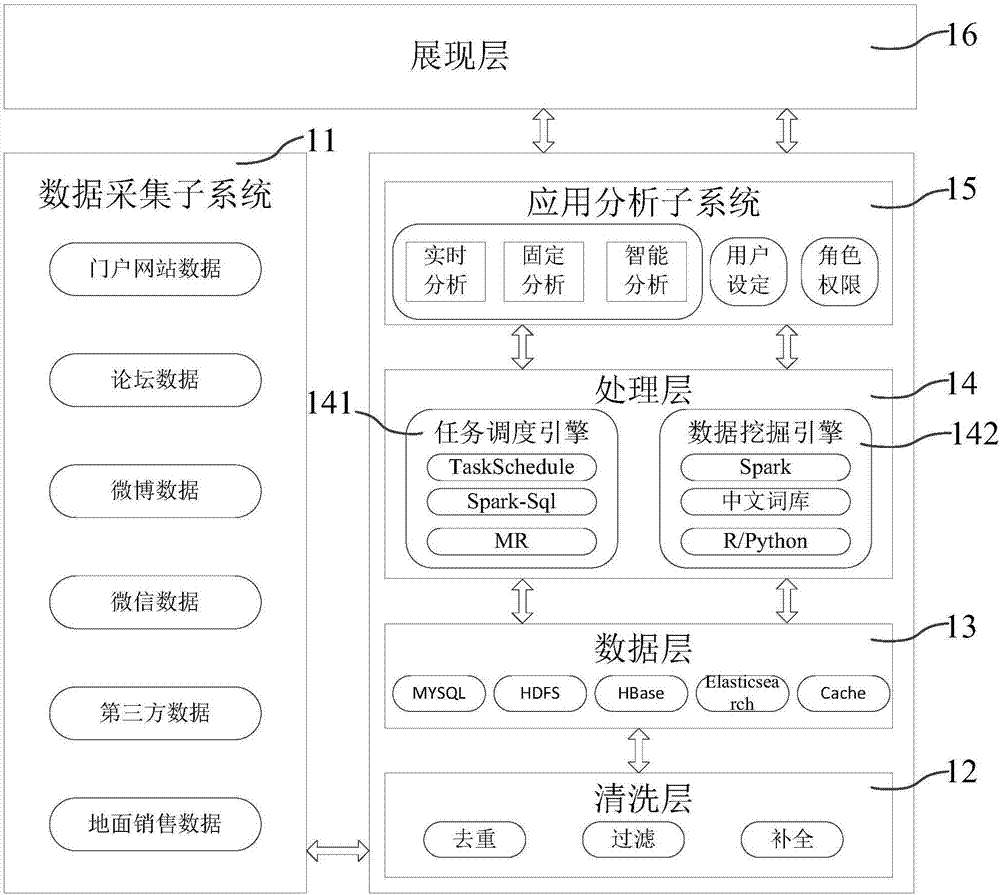
图1a是本发明实施例提供的一种出版物发行分析系统的结构示意图。本发明实施例可适用于对出版发行进行分析,为用户提供决策信息的情况,所述系统可由硬件和/或软件实现,本发明实施例提供的出版物发行分析系统包括:
数据采集子系统11,用于获取出版物关联的互联网爬虫数据和/或地面销售数据。
出版物可包括图书、杂志、报纸、音像读物等。在本发明实施中,出版物优选为图书。数据采集子系统11可通过灵活的自定义爬虫,通过丰富的网络资源进行目标数据爬取。采取多线程并发、共享任务池、横向扩展等方式来提高性能。例如通过三节点爬虫组可支撑百万级数据爬取与解析。数据采集子系统11可基于标题、作者、发布时间、正文、来源、编辑、点击量和评论数等数据采集指标,获取出版物关联的互联网爬虫数据和/或地面销售数据,也就是说,获取的数据是与出版物的标题、作者、发布时间、正文、来源、编辑、点击量和评论数相关数据。在本发明实施例中,优选的,数据采集子系统11可爬取与出版物关联的门户网站数据、论坛数据、微博数据、微信数据和第三方数据中的至少一种数据,获取出版物关联的地面销售数据。用户可定向关注,自定义爬取源,选择需要的解析模板,例如用户可以选择爬取与出版物关联的主流书评网站数据,或者选择爬取与出版物关联的论坛数据,也可选择从多个互联网的数据源爬取数据,而地面销售数据一般是被导入到系统中,可直接获取。
清洗层12,用于对获取的数据进行清洗,得到原始数据。
例如,清洗层12可通过rpc协议,与数据采集子系统11进行高效通信,通过分布式消息服务保证数据的高可靠性传输。通过配置中心管理多节点,高效接收流式数据,批量进行数据分发处理。具体地,清洗层12用于对数据采集子系统11获取的数据进行过滤、去重和补全等操作,例如清洗噪声数据、异常数据、重复数据等。
数据层13,用于存储原始数据。
数据层13具有高可靠数据存储能力,基于streaming的实时高效数据处理,采取orc文件的高效读写。数据层支持orc、txt、csv等常规大小文件,同时支持lzo、gzip、snappy等多种压缩格式,以节省存储资源,减少文件流网络成本。存储的数据类型支持结构化和非结构化数据,包括稀疏数据的存储,热点数据映射。例如包括基于hdfs分布式文件存储和基于hbase的非结构化稀疏数据的列式存储,hbase基于rowkey和region的优化、elasticsearch基于api和dsl的封装。可适应不同上层引擎的处理需求。并且提供高效的基于文档的多维度搜索和毫秒级数据定位能力。
处理层14,用于读取数据层13的原始数据,对原始数据进行调度和挖掘分析,得到基础分析数据。处理层14可对原始数据进行基本的分析,得到粗粒度数据或周期数据,处理层14输出的粗粒度数据或周期数据将作为应用分析子系统的基础数据源。
应用分析子系统15,用于根据基础分析数据得到出版发行分析结果数据。
应用分析子系统15主要为展现层16提供灵活的定制分析。应用分析子系统15可定时分析数据采集子系统11采集的数据,经过语义分析、内容聚合、分类等操作,生成各种选题推荐数据,市场监测数据,定向关注,预警数据等。用户可以根据当前市场热销图书的相关信息,发起临时分析任务,应用分析子系统15根据用户输入的关键词等信息,从已采集数据中和处理层14输出的基础分析数据中抽取、聚合、分类相关信息,生成选题推荐相关数据。用户也可通过配置应用分析子系统15的分析参数,如相似度阈值、分类种子等数据,对关注的相关图书或者选题信息进行动态分析,生成选题推荐相关数据,如选题排行、作者分析、读者分析数据等。例如,对于图书,可以基于热点、热评、热销等分析指标,对基础分析数据进行趋势分析、溯源分析、发布人分析、粉丝数变化曲线、热度趋势分析、媒反馈分析、专家名人分析等,得到畅销书排行分析结果数据、选题排行分析结果数据、作者排行分析结果数据、图书查重分析结果数据等。
展现层16,用于根据出版发行分析结果数据展现分析结果。
在得到出版发行分析结果数据之后,展现层16可根据这些分析结果数据,以文字、图表等形式展现分析结果。
本发明实施例提供的技术方案,通过获取出版物关联的互联网爬虫数据和/或地面销售数据,对这些数据进行存储的和相应的处理,得到出版发行分析结果数据,并展示分析结果。依托丰富的互联网爬虫数据和地面销售数据,基于调度、挖掘和分析,基于文本分析和机器学习等大数据处理,等得到出版物发行分析结果数据,分析的维度更加丰富,得出的结果更精确。提供一种有效的出版发行分析方法,为出版发行提供精确和有效的决策信息。
本发明实施还提供了另一种出版物发行分析系统。参见图1b,在图1a所示出版物发行分析系统的基础上,在本发明实施例提供的出版物发行分析系统中,处理层14包括:任务调度引擎141和数据挖据引擎142。
任务调度引擎141用于对原始数据进行周期调度处理得到周期数据。
任务调度引擎141可对海量数据离线处理。如全网书籍热度分析、热门书目分析、网络文学分析、分类图书分析、市场动态分析、营销内容分析、读者评论分析、选题分析等周期调度处理任务。为了满足灵活多变的分析任务,任务调度引擎可在基础模板之上,自定义工作流,支持组合方式进行任务提交,支持任务周期设定,多数据源接入,支持本地shell、远程ssh、java、mr等多类型任务。分布式部署的方式,并根据计数器和数据分片的策略进行任务分配,以保障负载均衡的能力。
其中,周期性数据包括销售数据、评论数据、媒体热点数据、畅销榜单数据、作家影响力数据和读者反馈相关数据;例如,数据采集子系统11采集的数据可能是某种图书每一天的销售数据,而对于出版物发行分析时,可能需要几十天或者几个月的销售数据,可将数据采集子系统11采集到的多天的销售数据进行叠加,得到周期性的销售数据。
数据挖据引擎142,用于对周期数据的内容进行归类、中文分词、词性标注和语义分析处理,得到挖掘结果数据。
数据挖掘引擎142作为复杂的自然语言处理核心,提供丰富的数据挖掘处理,完成多维度、多数据集的聚类、lda、贝叶斯分类、hnunlp等核心算法的应用。例如采用lda进行文本主题分析,训练模型析出文本-主题概率矩阵主;采用贝叶斯分类对文本自动归类,采用hnunlp算法进行中文分词,词性标注,语义分析。
应用分析子系统15用于对周期数据、挖掘结果数据和/或原始数据进行实时分析、固定分析和智能分析,生成选题推荐相关数据、出版物营销相关数据、出版物反馈相关数据和出版市场相关数据中的至少一类数据。需要说明书是,图中的箭头可表示各个层和子系统与其他层和子系统的数据交换,应用分析子系统15可对处理层14处理后的数据进行分析,也可对清洗层清洗后的数据进行分析,也可从数据层读取相应的数据进行分析,可以根据展示层的不同应用需要,从相应的层和/或子系统获取数据进行分析。另外,任务调度引擎141和数据挖掘引擎142输出的数据可直接输出至展现层16使用。
上述实施方式,运用大数据对采集到的出版物关联的数据信息进行加工计算,并分不同方面不同层次进行分析,生成选题推荐相关数据、出版物营销相关数据、出版物反馈相关数据和出版市场相关数据等,并根据这些数据展现分析结果。更精准地切入大众兴趣点,筛选出出版物的热卖选题,为出版物发行提供精确和有效的分析。分析出大众及媒体专家对特定图书的态度倾向,通过不同类型图表的形式较清晰地向用户呈现出书评全方位分析结果,更精准地切入大众兴趣点,筛选出图书热卖选题,另一方面又可帮助用户找出图书热卖渠道,找到有效的营销宣传方式。
在本发明实施中,数据挖掘引擎142还用于:
根据用户的配置和输入的信息,对存储的数据进行抽取、聚合和分类,生成挖掘结果数据。例如,用户输入某些关键词,数据挖掘引擎142可以根据用户输入的关键词,从存储的数据中搜索与用户输入的关键词关联的数据,然后对搜索的数据进行抽取、聚合和分类,生成选题推荐相关数据,如选题排行、作者分析、读者分析数据等。
本发明实施例还提供了一种出版物发行分析系统。参见图1c,在本发明任意实施例提供的出版物发行分析系统的基础上,展现层16包括:
出版市场监测子系统161,用于根据出版市场相关数据展现出版社信息、行业政策信息、定向关注信息和预警信息中的至少一种信息。
出版市场监测子系统161可由市场动态分析(包括本社信息和行业政策信息)、定向关注、预警系统等模块构建,通过数据采集子系统11和清洗层12对互联网海量数据抓取整理,对数据进行分析得到出版市场相关数据,使用出版市场相关数据展现的出版社信息、行业政策信息、定向关注信息和预警信息。可使出版工作者能在第一时间了解产业市场动态、把握政策导向和定向关注一些自己感兴趣的内容。
选题支撑子系统162,用于根据选题推荐相关数据展现畅销书排行与分析信息、网络文学排行与分析信息、选题排行与分析信息、作者排行与分析信息、以及图书查重信息中的至少一种信息。
选题支撑子系统163可由畅销书排行与分析、网络作品排行与分析、热点选题分析、潜在热点排行与分析、选题库分析、热门作家分析、潜在作家挖掘与分析、图书查重等模块构成。选题支撑子系统163可综合网络热点话题和各类型图书销售情况,结合媒体热点、畅销书榜单、作家自身影响力等权重,通过对历史选题和出版数据比对,得到畅销书排行与分析,畅销书排行与分析信息、网络文学排行与分析信息、选题排行与分析信息、作者排行与分析信息、以及图书查重信息。辅助进行书目及选题查重。
传统的选题策划主要依靠编辑人员根据一定的方针和主客观条件,开发出版资源,设计选题的创造性活动。而选题支持子系统展现的畅销书排行与分析信息、网络文学排行与分析信息、选题排行与分析信息、作者排行与分析信息、以及图书查重信息,起到出版编辑人员把握出版工作方向、落实出版工作方针、保障出版生产秩序,提高出版物质量以及塑造出版单位品牌形象等重要作用。
营销决策支撑子系统163,用于根据出版物营销相关数据展现出版物检索定位信息、读者特征分析信息、营销渠道分析信息和市场分析信息中的至少一种信息。
营销决策支撑子系统163可由图书检索定位、读者特征分析、营销渠道分析、营销宣传分析、立体市场分析、营销数据综合分析等功能模块构成。营销决策支撑子系统163综合网络热点话题和各类型图书销售情况,结合媒体热点、畅销书榜单、作家自身影响力等权重;通过对历史选题和出版数据比对,辅助进行书目及选题查重。通过应用分析子系统15对营销数据进行全方位、多角度的整合、分析,营销决策支撑子系统163根据出版物营销相关数据提供全面准确的市场信息,深度展示出版市场反应及销售行情,并在此基础对出版物未来销售走势做出预判,使图书投放更加精准有效,帮助出版社优化营销策略、创新营销方式。
出版物反馈分析子系统164,用于根据出版物反馈相关数据展现大众反馈分析信息、网络媒体反馈分析信息和专家名人反馈分析信息中的至少一种信息。出版物反馈分析子系统164可包括大众反馈分析、网络媒体反馈分析、专家名人反馈分析模块等。运用大数据对所抓取到的信息进行加工计算,并分不同方面不同层次进行分析,分析出大众及媒体专家对特定图书的态度倾向,最后通过不同类型图表的形式较清晰地向用户呈现出书评全方位分析结果,更精准地切入大众兴趣点,筛选出图书热卖选题,另一方面又可帮助用户找出图书热卖渠道,找到有效的营销宣传方式。
继续参见图1c,该系统还包括系统接口17,可以通过系统接口17与外部系统进行通信,提供对外服务。系统之间可以进行内部通信和数据共享。
本发明实施例提供的技术方案,填补了计算机辅助出版行业进行出版市场监测、出版选题、出版营销决策和出版物反馈的空白,而且获取的信息源的维度更加丰富,能够精确地进行选题分析、营销决策分析、市场分析和出版物反馈分析,为出版物出版发行提供有效的辅助决策信息。
图2是本发明实施例提供的一种出版物发行分析方法的流程示意图。该方法可由本发明任意实施例提供的出版物发行分析系统来执行。参见图2,该方法包括:
s210、获取出版物关联的互联网爬虫数据和/或地面销售数据。
s220、对获取的数据进行清洗,得到原始数据。
s230、存储原始数据。
s240、读取数据层的原始数据,对原始数据进行调度和挖掘分析,得到基础分析数据。
s250、根据基础分析数据得到出版发行分析结果数据。
s260、根据出版发行分析结果数据展现分析结果。
优选的,获取出版物关联的互联网爬虫数据和/或地面销售数据包括:
爬取与出版物关联的门户网站数据、论坛数据、微博数据、微信数据和第三方数据中的至少一种数据;
获取出版物关联的地面销售数据。
进一步的,对原始数据进行调度和挖掘分析,得到基础分析数据包括:
对原始数据进行周期调度处理得到周期数据;
对周期数据的内容进行归类、中文分词、词性标注和语义分析处理,得到挖掘结果数据;
其中,周期性数据包括销售数据、评论数据、媒体热点数据、畅销榜单数据、作家影响力数据和读者反馈相关数据;
根据基础分析数据得到出版发行分析结果数据,包括
对周期数据、挖掘结果数据和/或原始数据进行实时分析、固定分析和智能分析,生成选题推荐相关数据、出版物营销相关数据、出版物反馈相关数据和出版市场相关数据中的至少一类数据。
进一步的,对原始数据进行调度和挖掘分析,得到基础分析数据还包括:
根据用户的配置和输入的信息,对存储的数据进行抽取、聚合和分类,生成挖掘结果数据。
进一步的,根据出版发行分析结果数据展现分析结果包括:
根据出版市场相关数据展现出版社信息、行业政策信息、定向关注信息和预警信息中的至少一种信息;
根据选题推荐相关数据展现畅销书排行与分析信息、网络文学排行与分析信息、选题排行与分析信息、作者排行与分析信息、以及图书查重信息中的至少一种信息;
根据出版物营销相关数据展现出版物检索定位信息、读者特征分析信息、营销渠道分析信息和市场分析信息中的至少一种信息;
根据出版物反馈相关数据展现大众反馈分析信息、网络媒体反馈分析信息和专家名人反馈分析信息中的至少一种信息。
注意,上述仅为本发明的较佳实施例及所运用技术原理。本领域技术人员会理解,本发明不限于这里所述的特定实施例,对本领域技术人员来说能够进行各种明显的变化、重新调整和替代而不会脱离本发明的保护范围。因此,虽然通过以上实施例对本发明进行了较为详细的说明,但是本发明不仅仅限于以上实施例,在不脱离本发明构思的情况下,还可以包括更多其他等效实施例,而本发明的范围由所附的权利要求范围决定。
- 还没有人留言评论。精彩留言会获得点赞!