网页信息获得方法及系统与流程
本发明涉及信息处理技术领域,特别是涉及网页信息获得方法及系统。
背景技术:
新闻是互联网信息的主要承载体,从各大门户、媒体等新闻生产者处获取新闻后,可以对其进行研究,从而得出互联网信息的某些特征及趋势。
为了获取大量的新闻,需要对新闻列表页进行监控。现有技术下需要通过人工寻找各大门户、媒体的新闻列表页,无法快速、准确的获得大量网站的新闻列表页。
技术实现要素:
本发明实施例的目的在于提供一种网页信息获得方法及系统,以实快速、准确的获得大量网站的新闻列表页。具体技术方案如下:
一种网页信息获得方法,包括:
获得用户输入的网页关键词;
通过搜索引擎对所述网页关键词进行检索,获得与该网页关键词对应的多个网页的网络链接;
通过所述网络链接获得所述多个网页的网页源代码;
对所述网页源代码进行分析处理,从所述网页源代码中获得正文网页列表页的网络链接。
可选的,在所述通过所述网络链接获得所述多个网页的网页源代码之前,所述方法还包括:
从所述网络链接中选出正文网页的网络链接;
所述通过所述网络链接获得所述多个网页的网页源代码,包括:通过所述正文网页的网络链接获得所述正文网页的网页源代码。
可选的,所述对所述网页源代码进行分析处理,从所述网页源代码中获得正文网页列表页的网络链接,包括:
对所述网页源代码进行分析处理,获得网页的文档对象模型htmldom;
对所述htmldom中的所有节点进行遍历,获得网页的导航栏标签列表,其中,所述导航栏标签列表中各导航栏标签依次排列;
将所述导航栏标签列表中的倒数第二个导航栏标签对应的网络链接确定为该网页对应的正文网页列表页的网络链接。
可选的,所述对所述htmldom中的所有节点进行遍历,获得网页的导航栏标签列表,包括:
判断所述htmldom中的body节点是否存在子节点,如果存在,则将所述body节点的一个子节点确定为当前节点;
判断当前节点的文本text中是否包含有导航栏的间隔符,如果包含有导航栏的间隔符,则判断当前节点是否存在未遍历的兄弟节点;如果不包含有导航栏的间隔符,则将所述body节点的另一子节点确定为当前节点并返回执行所述判断当前节点的text中是否包含有导航栏的间隔符的步骤;
如果存在未遍历的兄弟节点,则将当前节点的未遍历的兄弟节点确定为当前节点并判断当前节点是否具有预设的标签特征,如果具有预设的标签特征,则将当前节点放入网页的导航栏标签列表中并返回执行所述判断当前节点是否存在未遍历的兄弟节点的步骤;如果不具有预设的标签特征,则返回执行所述判断当前节点是否存在未遍历的兄弟节点的步骤;
如果不存在未遍历的兄弟节点,则判断是否已对所述body节点的所有子节点进行遍历,如果已对所述body节点的所有子节点进行遍历,则确定放入网页的导航栏标签列表中的节点即为网页的导航栏标签列表中的全部节点;如果未对所述body节点的所有子节点进行遍历,则将所述body节点的另一子节点确定为当前节点并返回执行所述判断当前节点的text中是否包含有导航栏的间隔符的步骤。
可选的,所述预设的标签特征,包括如下特征中的任意个:
位于标题上方;
与导航链接之间设置有标识符;
具有标签形式。
一种网页信息获得装置,包括:关键词获得单元、检索单元、源代码获得单元和源代码分析单元,
所述关键词获得单元,用于所述获得用户输入的网页关键词;
所述检索单元,用于通过搜索引擎对所述网页关键词进行检索,获得与该网页关键词对应的多个网页的网络链接;
所述源代码获得单元,用于通过所述网络链接获得所述多个网页的网页源代码;
所述源代码分析单元,用于对所述网页源代码进行分析处理,从所述网页源代码中获得正文网页列表页的网络链接。
可选的,所述装置还包括:链接挑选单元,用于在所述源代码获得单元获得网页源代码之前,从所述网络链接中选出正文网页的网络链接;
所述源代码获得单元,具体用于:通过所述正文网页的网络链接获得所述正文网页的网页源代码。
可选的,所述源代码分析单元,包括:模型获得子单元、节点遍历子单元和链接确定子单元,
所述模型获得子单元,用于对所述网页源代码进行分析处理,获得网页的文档对象模型htmldom;
所述节点遍历子单元,用于对所述htmldom中的所有节点进行遍历,获得网页的导航栏标签列表,其中,所述导航栏标签列表中各导航栏标签依次排列;
所述链接确定子单元,用于将所述导航栏标签列表中的倒数第二个导航栏标签对应的网络链接确定为该网页对应的正文网页列表页的网络链接。
可选的,所述节点遍历子单元,包括:子节点判断子单元、第一当前节点确定子单元、第二当前节点确定子单元、间隔符判断子单元、兄弟节点判断子单元、标签特征判断子单元、节点放入子单元,
所述子节点判断子单元,用于判断所述htmldom中的body节点是否存在子节点,如果存在,则触发所述第一当前节点确定子单元;
所述第一当前节点确定子单元,用于将所述body节点的一个子节点确定为当前节点;
所述间隔符判断子单元,用于判断当前节点的文本text中是否包含有导航栏的间隔符,如果包含有导航栏的间隔符,则触发所述兄弟节点判断子单元;如果不包含有导航栏的间隔符,则触发所述第二当前节点确定子单元;
所述兄弟节点判断子单元,用于判断当前节点是否存在未遍历的兄弟节点;如果存在未遍历的兄弟节点,则触发所述标签特征判断子单元;如果不存在未遍历的兄弟节点,则触发所述遍历完成确定子单元;
所述第二当前节点确定子单元,用于将所述body节点的另一子节点确定为当前节点并触发所述间隔符判断子单元;
所述标签特征判断子单元,用于将当前节点的未遍历的兄弟节点确定为当前节点并判断当前节点是否具有预设的标签特征,如果具有预设的标签特征,则触发所述节点放入子单元;如果不具有预设的标签特征,则触发所述兄弟节点判断子单元;
所述节点放入子单元,用于将当前节点放入网页的导航栏标签列表中并触发所述兄弟节点判断子单元;
所述遍历完成确定子单元,用于判断是否已对所述body节点的所有子节点进行遍历,如果已对所述body节点的所有子节点进行遍历,则触发列表确定子单元;如果未对所述body节点的所有子节点进行遍历,则触发所述第二当前节点确定子单元;
所述列表确定子单元,用于确定放入网页的导航栏标签列表中的节点即为网页的导航栏标签列表中的全部节点。
可选的,所述预设的标签特征,包括如下特征中的任意个:
位于标题上方;
与导航链接之间设置有标识符;
具有标签形式。
本发明实施例提供的一种网页信息获得方法及装置,可以获得用户输入的网页关键词,通过搜索引擎对所述网页关键词进行检索,获得与该网页关键词对应的多个网页的网络链接,通过所述网络链接获得所述多个网页的网页源代码,对所述网页源代码进行分析处理,从所述网页源代码中获得正文网页列表页的网络链接。可见,本发明实现了正文网页列表页的自动获取,可以快速、准确的获得大量网站的正文网页列表页。
当然,实施本发明的任一产品或方法必不一定需要同时达到以上所述的所有优点。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例提供的一种网页信息获得方法的流程图;
图2为本发明实施例提供的另一种网页信息获得方法的流程图;
图3为本发明实施例提供的步骤s400的流程图;
图4为本发明实施例提供的步骤s420的流程图;
图5为本发明实施例提供的一种网页信息获得装置的结构示意图;
图6为本发明实施例提供的一种网页信息获得装置中源代码分析单元的结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
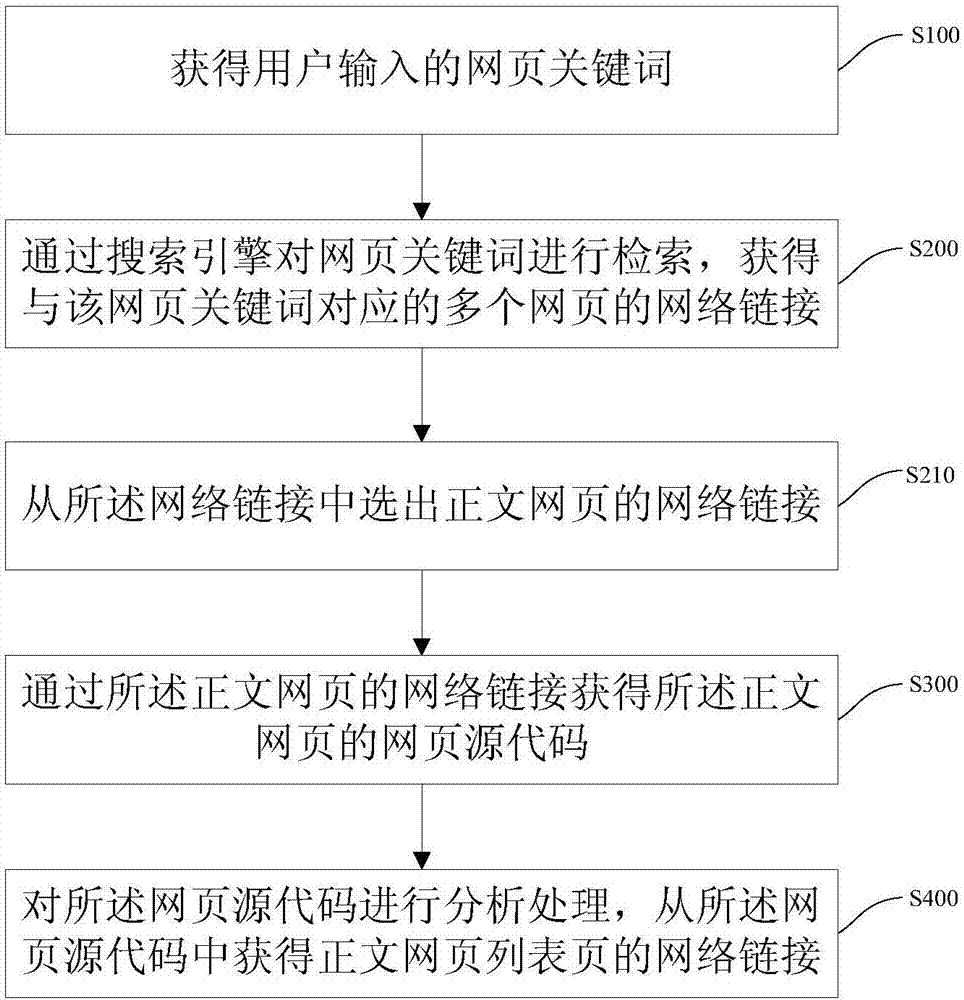
如图1所示,本发明实施例提供的一种网页信息获得方法,可以包括:
s100、获得用户输入的网页关键词;
s200、通过搜索引擎对所述网页关键词进行检索,获得与该网页关键词对应的多个网页的网络链接;
其中,步骤s200可以通过元搜索技术使用多种搜索引擎进行检索。
具体的,在通过搜索引擎对所述网页关键词进行检索后,还可以对检索结果进行处理后再获得与网络关键词对应的多个网页的网络链接。具体的处理可以有多种,如消重处理,以去除相同的检索结果;再如:对检索结果进行筛选,仅选取前n页的检索结果,其余的检索结果则丢弃。
s300、通过所述网络链接获得所述多个网页的网页源代码;
具体的,本发明可以通过浏览器的下载模块获得网页源代码,如:firefox下载模块。firefox下载模块整合了javascript执行器和css渲染器,因此可以通过firefox下载得到包含ajax执行结果和css渲染结果的网页源代码。
s400、对所述网页源代码进行分析处理,从所述网页源代码中获得正文网页列表页的网络链接。
本发明实施例提供的一种网页信息获得方法,可以获得用户输入的网页关键词,通过搜索引擎对所述网页关键词进行检索,获得与该网页关键词对应的多个网页的网络链接,通过所述网络链接获得所述多个网页的网页源代码,对所述网页源代码进行分析处理,从所述网页源代码中获得正文网页列表页的网络链接。可见,本发明实现了正文网页列表页的自动获取,可以快速、准确的获得大量网站的正文网页列表页。
如图2所示,在本发明其他实施例中,图1所示方法中步骤s300之前,还可以包括:
s210、从所述网络链接中选出正文网页的网络链接;
可以理解的是,本发明可以通过正文网页的网络链接与网站首页网络链接、正文网页列表页的网络链接的区别来从网络链接中选出正文网页的网络链接。例如:正文网页的网络链接的尾部一般均包含一串数字,而网站首页网络链接和正文网络列表页网络链接则不包含。可以根据该特征选出正文网页的网络链接。
步骤s300可以具体包括:通过所述正文网页的网络链接获得所述正文网页的网页源代码。
如图3所示,图1及图2实施例中的步骤s400可以包括:
s410、对所述网页源代码进行分析处理,获得网页的文档对象模型htmldom;
其中,htmldom可以把html文档呈现为带有元素、属性和文本的节点树。
s420、对所述htmldom中的所有节点进行遍历,获得网页的导航栏标签列表,其中,所述导航栏标签列表中各导航栏标签依次排列;
s430、将所述导航栏标签列表中的倒数第二个导航栏标签对应的网络链接确定为该网页对应的正文网页列表页的网络链接。
其中,倒数第一个导航栏标签为正文网页对应的标签,因此倒数第二个导航栏标签即为正文网页列表页对应的标签。
如图4所示,图3所示实施例中步骤s420可以包括:
s421、判断所述htmldom中的body节点是否存在子节点,如果存在,则执行步骤s422;
其中,body节点是html中的最重要根节点,网页中可视的元素通常都位于body节点之中。
body节点的子节点是指:对于dom树而言,位于body节点下方的所有节点。
网页中的可视的元素通常仅仅位于body节点中,和body并列的其他根节点只包含网页的初始化信息,无需处理,因此仅处理body节点及其子节点即可。
s422、将所述body节点的一个子节点确定为当前节点;
s423、判断当前节点的文本text中是否包含有导航栏的间隔符,如果包含有导航栏的间隔符,则执行步骤s424;如果不包含有导航栏的间隔符,则执行步骤s425;
其中,间隔符可以有多种形式,如:“>”、“/”等。
s424、判断当前节点是否存在未遍历的兄弟节点;如果存在未遍历的兄弟节点,则执行步骤s426;如果不存在未遍历的兄弟节点,则执行步骤s428;
s425、将所述body节点的另一子节点确定为当前节点;返回执行所述步骤s423;
s426、将当前节点的未遍历的兄弟节点确定为当前节点并判断当前节点是否具有预设的标签特征,如果具有预设的标签特征,则执行步骤s427;如果不具有预设的标签特征,则返回执行所述步骤s424;
具体的,步骤s426可以按照深度优先或广度优先等方式依次将各节点确定为当前节点。
其中,所述预设的标签特征,可以包括如下特征中的任意个:
位于标题上方;
与导航链接之间设置有标识符;
具有标签形式。
其中,在当前节点的文本携带有链接且文本的文字数量不超过预设阈值时,可以确定当前节点具有标签形式。s427、将当前节点放入网页的导航栏标签列表中,返回执行所述步骤s424;
s428、判断是否已对所述body节点的所有子节点进行遍历,如果已对所述body节点的所有子节点进行遍历,则执行步骤s429;如果未对所述body节点的所有子节点进行遍历,则返回执行步骤s425。
s429、确定放入网页的导航栏标签列表中的节点即为网页的导航栏标签列表中的全部节点。
与上述方法实施例相对应,本发明还提供了一种网页信息获得装置。
如图5所示,本发明实施例提供的一种网页信息获得装置,可以包括:关键词获得单元100、检索单元200、源代码获得单元300和源代码分析单元400,
所述关键词获得单元100,用于所述获得用户输入的网页关键词;
所述检索单元200,用于通过搜索引擎对所述网页关键词进行检索,获得与该网页关键词对应的多个网页的网络链接;
具体的,在通过搜索引擎对所述网页关键词进行检索后,还可以对检索结果进行处理后再获得与网络关键词对应的多个网页的网络链接。具体的处理可以有多种,如消重处理,以去除相同的检索结果;再如:对检索结果进行筛选,仅选取前n页的检索结果,其余的检索结果则丢弃。
所述源代码获得单元300,用于通过所述网络链接获得所述多个网页的网页源代码;
具体的,本发明可以通过浏览器的下载模块获得网页源代码,如:firefox下载模块。firefox下载模块整合了javascript执行器和css渲染器,因此可以通过firefox下载得到包含ajax执行结果和css渲染结果的网页源代码。
所述源代码分析单元400,用于对所述网页源代码进行分析处理,从所述网页源代码中获得正文网页列表页的网络链接。
本发明实施例提供的一种网页信息获得装置,可以获得用户输入的网页关键词,通过搜索引擎对所述网页关键词进行检索,获得与该网页关键词对应的多个网页的网络链接,通过所述网络链接获得所述多个网页的网页源代码,对所述网页源代码进行分析处理,从所述网页源代码中获得正文网页列表页的网络链接。可见,本发明实现了正文网页列表页的自动获取,可以快速、准确的获得大量网站的正文网页列表页。
在本发明其他实施例中,图5所示装置还可以包括:链接挑选单元,用于在所述源代码获得单元300获得网页源代码之前,从所述网络链接中选出正文网页的网络链接;
所述源代码获得单元300,具体用于:通过所述正文网页的网络链接获得所述正文网页的网页源代码。
可以理解的是,本发明可以通过正文网页的网络链接与网站首页网络链接、正文网页列表页的网络链接的区别来从网络链接中选出正文网页的网络链接。例如:正文网页的网络链接的尾部一般均包含一串数字,而网站首页网络链接和正文网络列表页网络链接则不包含。可以根据该特征选出正文网页的网络链接。
其中,如图6所示,所述源代码分析单元400,可以包括:模型获得子单元410、节点遍历子单元420和链接确定子单元430,
所述模型获得子单元410,用于对所述网页源代码进行分析处理,获得网页的文档对象模型htmldom;
所述节点遍历子单元420,用于对所述htmldom中的所有节点进行遍历,获得网页的导航栏标签列表,其中,所述导航栏标签列表中各导航栏标签依次排列;
所述链接确定子单元430,用于将所述导航栏标签列表中的倒数第二个导航栏标签对应的网络链接确定为该网页对应的正文网页列表页的网络链接。
其中,倒数第一个导航栏标签为正文网页对应的标签,因此倒数第二个导航栏标签即为正文网页列表页对应的标签。
具体的,所述节点遍历子单元420,可以包括:子节点判断子单元、第一当前节点确定子单元、第二当前节点确定子单元、间隔符判断子单元、兄弟节点判断子单元、标签特征判断子单元、节点放入子单元,
所述子节点判断子单元,用于判断所述htmldom中的body节点是否存在子节点,如果存在,则触发所述第一当前节点确定子单元;
所述第一当前节点确定子单元,用于将所述body节点的一个子节点确定为当前节点;
所述间隔符判断子单元,用于判断当前节点的文本text中是否包含有导航栏的间隔符,如果包含有导航栏的间隔符,则触发所述兄弟节点判断子单元;如果不包含有导航栏的间隔符,则触发所述第二当前节点确定子单元;
所述兄弟节点判断子单元,用于判断当前节点是否存在未遍历的兄弟节点;如果存在未遍历的兄弟节点,则触发所述标签特征判断子单元;如果不存在未遍历的兄弟节点,则触发所述遍历完成确定子单元;
所述第二当前节点确定子单元,用于将所述body节点的另一子节点确定为当前节点并触发所述间隔符判断子单元;
所述标签特征判断子单元,用于将当前节点的未遍历的兄弟节点确定为当前节点并判断当前节点是否具有预设的标签特征,如果具有预设的标签特征,则触发所述节点放入子单元;如果不具有预设的标签特征,则触发所述兄弟节点判断子单元;
所述节点放入子单元,用于将当前节点放入网页的导航栏标签列表中并触发所述兄弟节点判断子单元;
所述遍历完成确定子单元,用于判断是否已对所述body节点的所有子节点进行遍历,如果已对所述body节点的所有子节点进行遍历,则触发列表确定子单元;如果未对所述body节点的所有子节点进行遍历,则触发所述第二当前节点确定子单元;
所述列表确定子单元,用于确定放入网页的导航栏标签列表中的节点即为网页的导航栏标签列表中的全部节点。
其中,所述预设的标签特征,可以包括如下特征中的任意个:
位于标题上方;
与导航链接之间设置有标识符;
具有标签形式。
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
本说明书中的各个实施例均采用相关的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于系统实施例而言,由于其基本相似于方法实施例,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
以上所述仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内所作的任何修改、等同替换、改进等,均包含在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!