一种图书馆智能搜索排序方法及系统与流程
本发明涉及图书自动检测技术领域,特别是一种精确预测和推荐的图书馆智能搜索排序方法及系统。
背景技术:
现有的图书馆图书检索方式普遍采用关键字匹配,同时为了减少工作量和复杂度,大部分检索系统均采用书名以及作者的关键词的匹配,这虽然符合大众需求,但是对于使用者给出的不与书名等匹配的关键字的检索将检索失败;
因此,需要一种能精确预测和推荐的图书馆智能搜索排序方法及系统。
技术实现要素:
本发明的目的是提出一种精确预测和推荐的图书馆智能搜索排序方法及系统。
本发明的目的是通过以下技术方案来实现的:
本发明提供的图书馆智能搜索排序方法,包括以下步骤:
获取检索信息;
利用循环卷积网络处理检索信息,提取特征向量;
将特征向量送入卷积神经网络,输出与图书馆图书数目相同维度的预测向量;
利用softmax函数对预测向量进行归一化计算生成对应于每本图书的预测概率;
对预测概率进行排序,按概率从高到低输出排序结果;
将图书预测排序结果存入数据库中。
进一步,还包括以下步骤:
根据排序结果和用户对输入检索信息所点击选择图书按照以下公式计算出用于衡量模型预测错误程度的累积误差值β:
式中,n为累积预测次数,pi,1为第i次预测时预测结果中排序最大的概率值,pi,j为第i次预测时用户对输入检索信息所点击选择图书对应的预测概率值,j为其对应的排序位置;
判断累积误差值β与设定门限值的关系,并按照以下方式对智能检索预测排序模块模型进行更新:
当更新调度模块检测到累积误差值β大于设定门限值时,从数据库中随机选择多个样本组成训练集,启动智能检索模型训练器,对模型进行重新训练;并且对训练的多个模型对在数据库中随机选取的N个样本计算累积误差值β,选择其中累积误差值最小的模型更新智能检索预测排序模块模型;
所述从数据库中选择样本包括:用户输入检索信息、用户检索时间、模型预测排序结果及用户对应输入检索信息所点击选择图书。
进一步,所述智能模型检索训练器训练过程中,softmax函数所在层学习率根据样本采集时间和训练时间按照以下公式进行计算:
式中,λ0为固定学习率,t为模型训练时间,单位为秒,为对应样本保存时间,即为样本用户检索时间,单位为秒。
进一步,所述的循环卷积网络采用长短时记忆模型LSTM;所述的卷积神经网络采用GoogleNet网络模型结构。
本发明还提供了一种图书馆智能搜索排序系统,包括数据库、智能检索模型训练器、更新调度模块以及智能检索预测排序模块;
所述数据库用于存储图书馆所有图书的检索信息;
所述智能检索模型训练器,根据数据库存储的检索信息和输入信息对卷积神经网模型进行训练,存储训练完成的网络模型;
所述智能检索预测排序模块,通过智能检索模型训练器训练完成的网络模型,对用户输入的检索信息进行计算,对图书馆图书按预测概率大小进行从大到小排序,输出排序结果;
所述更新调度模块,用于对智能检索模型训练器的启动和智能检索预测排序模块中模型进行更新。
进一步,所述更新调度模块按照以下公式来实现智能检索预测排序模块的更新:
按照以下公式计算模型预测错误程度:
式中,n为累积预测次数,pi,1为第i次预测时预测结果中排序最大的概率值,pi,j为第i次预测时关键字对应的感兴趣图书对应的概率值,j为其对应的排序位置;
当更新调度模块检测到累积误差值β大于设定门限值时,启动智能检索模型训练器,对模型进行重新训练;并且对训练的多个模型对在数据库中随机选取的N个样本计算累积误差值β,选择其中累积误差值最小的模型更新智能检索预测排序模块模型。
进一步,所述softmax函数中的学习率根据样本采集时间和训练时间按照以下公式进行计算:
式中,λ0为固定学习率,t为模型训练时间,单位为秒,为对应样本保存时间,单位为秒。
由于采用了上述技术方案,本发明具有如下的优点:
本发明提供的搜索排序方法使用神经网络的机器学习方法训练图书馆搜索预测系统,相较于传统的标题、作者关键字匹配的搜索系统更灵活,对于搜索关键字不在图书标题的搜索准确性提高,如文学类书籍;
由于具备了智能检索模型训练器和数据库,使得系统具备了自适应学习能力,减少了人工参与,节省了人力资源和使用难度,能更方便的布局具有图书馆自身图书特色和众多使用者习惯的智能搜索排序系统。
智能检索模型训练过程中,依赖时间特性的可变学习率计算使得系统更好,更快适应最新图书和使用者习惯、兴趣的变化。
关于更新调度模块依据累积误差率的调度和模型更新,在保证系统预测精度的情况下,避免了实时更新系统模型参数所引入的计算资源增加、能耗增加问题,保证了系统的预测效率、节省成本。
本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
附图说明
本发明的附图说明如下。
图1为本发明的方案框图。
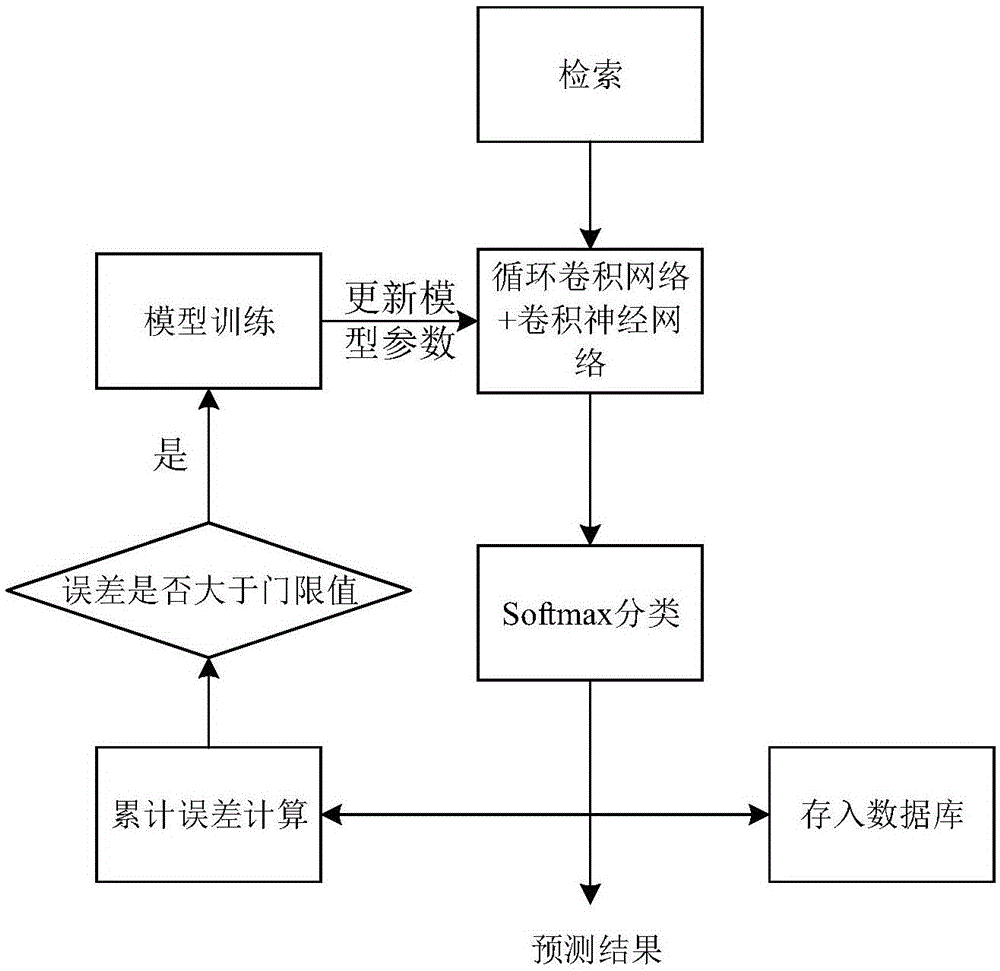
图2为本发明的流程图。
具体实施方式
下面结合附图和实施例对本发明作进一步说明。
如图所示,本实施例提供的图书馆智能搜索排序方法,包括以下步骤:
获取检索信息;
利用循环卷积网络处理检索信息,提取特征向量;
将特征向量送入卷积神经网络,输出与图书馆图书数目相同维度的预测向量;
利用softmax函数对预测向量进行归一化计算生成对应于每本图书的预测概率;
对预测概率进行排序,按概率从高到低输出排序结果;
将图书预测排序结果存入数据库中。
还包括以下步骤:
根据排序结果和用户对输入检索信息所点击选择图书按照以下公式计算出用于衡量模型预测错误程度的累积误差值β:
式中,n为累积预测次数,pi,1为第i次预测时预测结果中排序最大的概率值,pi,j为第i次预测时用户对输入检索信息所点击选择图书对应的预测概率值,j为其对应的排序位置;
判断累积误差值β与设定门限值的关系,并按照以下方式对智能检索预测排序模块模型进行更新:
当更新调度模块检测到累积误差值β大于设定门限值时,从数据库中随机选择多个样本组成训练集,启动智能检索模型训练器,对模型进行重新训练;并且对训练的多个模型对在数据库中随机选取的N个样本计算累积误差值β,选择其中累积误差值最小的模型更新智能检索预测排序模块模型;
所述从数据库中选择样本包括:用户输入检索信息、用户检索时间、模型预测排序结果及用户对应输入检索信息所点击选择图书。
所述智能模型检索训练器训练过程中,softmax函数所在层学习率根据样本采集时间和训练时间按照以下公式进行计算:
式中,λ0为固定学习率,t为模型训练时间,单位为秒,为对应样本保存时间,即为样本用户检索时间,单位为秒。
所述的循环卷积网络采用长短时记忆模型LSTM;所述的卷积神经网络采用GoogleNet网络模型结构。
本实施例提供的图书馆智能搜索排序系统,包括数据库、智能检索模型训练器、更新调度模块以及智能检索预测排序模块;
所述数据库用于存储图书馆所有图书的检索信息;
所述智能检索模型训练器,根据数据库存储的检索信息和输入信息对卷积神经网模型进行训练,存储训练完成的网络模型;
所述智能检索预测排序模块,通过智能检索模型训练器训练完成的网络模型,对用户输入的检索信息进行计算,对图书馆图书按预测概率大小进行从大到小排序,输出排序结果;
所述更新调度模块,用于对智能检索模型训练器的启动和智能检索预测排序模块中模型进行更新。
所述更新调度模块按照以下公式来实现智能检索预测排序模块的更新:
根据排序结果和用户输入关键字所选中的感兴趣图书,可以通过累积计算误差值用于衡量模型预测的错误程度,按照以下公式计算模型预测错误程度,具体如下:
式中,n为累积预测次数,pi,1为第i次预测时预测结果中排序最大的概率值,pi,j为第i次预测时关键字对应的感兴趣图书对应的概率值,j为其对应的排序位置。预测概率差值越大说明模型预测结果误差越大,位置越靠后说明误差越大。
当更新调度模块检测到累积误差值β大于设定门限值时,启动智能检索模型训练器,对模型进行重新训练;并且对训练的多个模型对在数据库中随机选取的N个样本计算累积误差值β,选择其中累积误差值最小的模型更新智能检索预测排序模块模型。
本实施例中softmax函数中的学习率采用学习率与样本采集时间和训练时间相关的特性,具体计算如下:
式中,λ0为固定学习率,t为模型训练时间,单位为秒,为对应样本保存时间,单位为秒;通过固定学习率乘以时间相关的因子,保证了离训练时间越近的样本权重越大,时间越久远样本权重越小,从而使得模型更适应最新情况,如图书馆增加图书等。使得时间越近的样本学习率越大,使得系统更适应当前环境。
本实施例提供的数据库存储有图书馆所有图书信息,包括书名、作者、出版社、出版时间,并对所有图书进行一一对应编号;以及使用检索系统的检索历史记录,包括检索关键字、感兴趣图书编号以及检索时间。
对于图书馆,根据图书馆藏书量巨大特性,采用神经网络对智能检索模型进行训练,即采用当前最高效、实用的卷积神经网络提取样本特征,由于输入关键字个数不定,所以在在卷积网络之前添加循环卷积网络处理可变长关键字,最后对卷积神经网络特征采用softmax函数进行归一化计算,及智能检索训练器网络模型由循环卷积网络+卷积神经网络+softmax组成。
智能检索模型训练器根据数据库统计的检索关键字和对应的感兴趣图书编号对网络模型进行训练,存储多个训练完成的网络模型。区别于传统的深度神经网络训练中softmax层学习率固定递减或指数递减规则。
智能检索预测排序模块通过训练完成的网络模型,对用户输入的检索关键字进行计算,对图书馆图书按预测概率大小进行从大到小排序,输出排序结果。
更新调度模块主要负责智能检索模型训练器的启动和智能检索预测排序模块中模型的更新。当更新调度模块检测到累积误差值β大于设定门限值时,启动智能检索模型训练器,对模型进行重新训练;并且对训练的多个模型对在数据库中随机选取的N个样本计算累积误差值β,选择其中累积误差值最小的模型更新智能检索预测排序模块模型。
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本技术方案的宗旨和范围,其均应涵盖在本发明的保护范围当中。
- 还没有人留言评论。精彩留言会获得点赞!