一种在不同神经网络结构间进行知识迁移的方法与流程
本发明涉及深度学习和知识迁移的算法领域,尤其涉及一种在不同神经网络结构间进行知识迁移的方法。
背景技术:
深度学习正在蓬勃发展,在识别、检测、追踪等多个领域都取得了非常瞩目的进展,学术界的研究成果的工业化、产品化也在有条不紊地进行着。然而,面对不同的产品需求,其对网络精度、运行速度、存储量的要求都不一样。在处理同一个问题上,对于精度要求高的平台往往要用到比较大的模型,而对于运行在移动端等运行速度优先的任务往往要用到较为精简的网络。在已有一个训练好的模型的情况下,根据不同的精度、运行速度需求再重新训练一个模型是十分费时耗力的。于是,如何将训练好的网络中的知识快速迁移到另外一个结构不同、复杂度不同的网络上变得尤为重要。
目前,学术界的研究人员也有对此展开研究的,以net2net、networkmorphism、deepcompression这些论文为代表,前两者讲的就是如何将一个小网络的参数无损地拓展到另一个大网络中,对网络结构的设计存在一定限制,而后者讲的是一套网络压缩的方法,工程量比较大。在同样的背景下,hinton提出了“老师-学生”训练方法,但其仅仅通过已训练好的网络生成软标签用于训练小网络而已,并未过多涉及网络的内部结构,其迁移收敛速度不够快速。
技术实现要素:
为了满足不同的工业化、产品化需求,将已训练完毕的神经网络中的知识快速迁移到另一个网络结构不同、复杂度不同的模型上,本发明提出一种在不同神经网络结构间进行知识迁移的方法。
本发明的技术方案是这样实现的:
一种在不同神经网络结构间进行知识迁移的方法,包括步骤
s1:将已经训练好的神经网络纵向划分为多个子网络,并且使得每个子网络的输入和输出为所述已经训练好的神经网络不同尺度大小下的特征信息;
s2:根据不同的需求设计需要进行知识转移的目标网络,并使得所述需要进行知识转移的目标网络能划分为与所述已经训练好的神经网络具有相同数量的子网络,然后,需要进行知识转移的目标网络重新学习已经训练好的神经网络中各个子网络的输入和输出之间的映射关系;
s3:将目标设定为:已经训练好的神经网络与需要进行知识转移的目标网络输入相同的情况下,最小化相对应的子网络的输出特征图之间的距离,对所述需要进行知识转移的目标网络进行优化;
s4:提取所述需要进行知识转移的目标网络,以低于已经训练好的神经网络的学习率,对所述需要进行知识转移的目标网络进一步优化。
进一步地,步骤s1中,已经训练好的神经网络纵向划分为多个子网络的方法包括但不限于:将一个卷积层或全连接层级联上一个池化层和激活层划为一个子网络,或,以池化层为分界线划分子网络,或,残差网络则以步长为2的层为分界线划为子网络。
进一步地,步骤s2中,设计需要进行知识转移的目标网络时,还要使得需要进行知识转移的目标网络的输出特征图的通道数、高和宽都和所述已经训练好的神经网络中对应的子网络相同,且确保已经训练好的神经网络和需要进行知识转移的目标网络的输出特征图之间的误差能够被计算。
进一步地,步骤s3中,对所述需要进行知识转移的目标网络进行优化包括步骤:在所述需要进行知识转移的目标网络的对应的子网络后连接一个损失层,且在误差回传更新参数时,每个损失层得到的梯度只用于更新当前子网络的参数,不向上一个子网络继续回传。
进一步地,步骤s4中,对所述需要进行知识转移的目标网络进一步优化是在原数据集上进行的,如果用户目标是扩展网络,即希望得到比已经训练好的神经网络精度更高或者泛化性更高的需要进行知识转移的目标网络,则在扩大数据集或进行数据增强后进一步调优。
本发明的有益效果在于,与现有技术相比,本发明进一步地拓展了知识迁移模式,在精度上、迁移收敛速度上、灵活性上都具有显著的优势;而且实现简单方便,用户只需简单改写一下网络定义文件,就可以实现大部分的功能,因此具有一定的工程意义。
附图说明
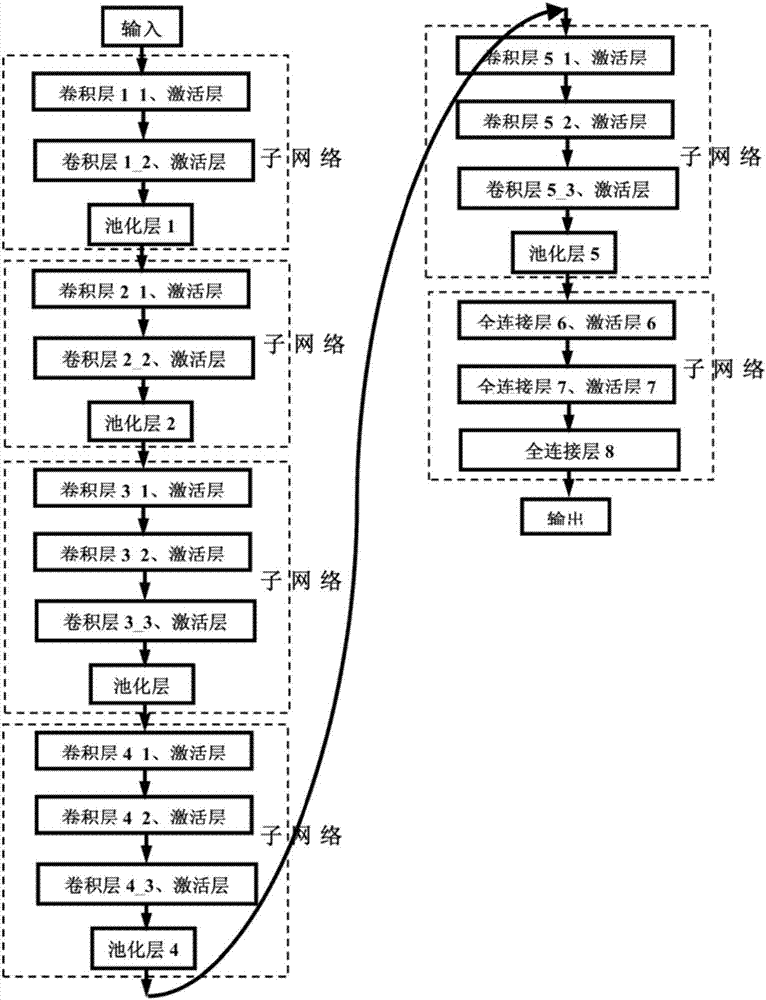
图1是本发明一种在不同神经网络结构间进行知识迁移的方法流程图;
图2是本发明中vgg网络结构及其子网络划分示意图;
图3是本发明中残差网络结构及其子网络划分示意图;
图4是残差网络中的“瓶颈”结构示意图;
图5a和图5b是两种感受野大小为3的子网络选用模块;
图6是一种感受野大小为5的子网络选用模块;
图7是一种感受野大小为7的子网络选用模块;
图8是本发明中扩展子网络的一种方案示意图;
图9是本发明中“老师-学生”训练模式。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
面对不同的产品化需求,本发明提出一种更为灵活,实现更为简单而又高效的通用方法。本发明在“老师-学生”训练方法的启发下,提出一种更为高效的“老师-学生”训练方法,以用于不同神经网络结构间的知识快速迁移,其中“老师”网络代表了已经训练好的神经网络,“学生”网络代表了需要进行知识转移的目标网络。
请参见图1,本发明一种在不同神经网络结构间进行知识迁移的方法,包括步骤
s1::将“老师”网络纵向划分为几个子网络。
根据“老师”网络的结构不同有多种划分模式,对于一般的网络可以将一个卷积层(或全连接层)级联上一个池化层、激活层划为一个子网络。
对于一些特殊的网络也可以有特殊的划分方式,例如论文verydeepconvolutionalnetworksforlarge-scaleimagerecognition提出的vgg网络可以以池化层为分界线划分子网络,图2示例了vgg网络的划分方式:以池化层为分界线划分子网络;论文deepresiduallearningforimagerecognition提出的残差网络则可以以步长为2的层为分界线划为子网络。“老师”网络的划分,跟后面“学生”网络结构的设计息息相关,图3示例了残差网络的划分方式:以步长为2的层为分界线划分子网络。这样的划分是有它的意义的,例如图2中以池化层为分界线划分子网络,是为了在“学生”网络中将池化层与上面级联的卷积层合成一个带步长的卷积层,可减少了池化层这一层,同时也降低了卷积运算量;图3中以步长为2的卷积层位分界线是为了方便增加或者减少子网络中的残差单元。所以,“老师”网络的划分是跟用户目标相关的。
s2:根据不同的需求设计“学生”网络。
这里唯一的限制就是,“学生”网络可划分为与“老师”网络相同数量的子网络,同时各个子网络的输出大小与“老师”网络中对应的子网络相同,具体指相同通道数、高、宽。这里设计“学生“网络中的子网络的思路与用户需求密切相关,一般需求可分为两大类:1)压缩网络;2)拓展网络。
用于压缩网络可使用一些较为精简的模块,目前学术界、工业界使用得比较多的是goingdeeperwithconvolutions这篇论文提到的inception模块(该模块特点是有多个分支,每个分支有不同核大小的卷积操作负责)及其变形,因此本发明以多种该模块的变形为例进行阐述。
这里设计了三种感受野大小不同的inception模块,如图5a、图6、图7所示。“学生”子网络可用图5a模块来学习逼近“老师”子网络中3x3大小的卷积层;可用图6模块或者两层图5a模块来学习逼近5*5大小的卷积层;可用图7模块或三层图5a模块来学习逼近7x7大小的卷积层。当然还有更多的变形,例如图6和图7中的5x5以及7x7核大小的卷积层可以用多个3x3核大小的卷积层级联替代。
当然,设计方案是多样的:1)例如图5b所示的感受野大小为3x3的扁平化的“瓶颈”结构可用于学习逼近“老师”网络中3x3核大小的卷积层,设计思路是将3x3核大小的卷积层分解为3x1和1x3两层“扁平”的卷积层级联,另外可在上、下各级联一层1x1核大小的卷积层,主要用于降低中间卷积层的通道数,进而减少网络存储大小及运算复杂度,其他卷积核大小的以此类推;2)例如用残差单元比较少的“学生”网络去学习逼近残差单元比较多的“老师”网络。总之,“学生”子网络的设计思路为设计尽可能精简但又足够容纳或者逼近“老师”子网络中的“知识”。
同时,从参数量化这个角度看,目前很多网络都是用32位宽的浮点数来表示一个参数的,但事实是,对于很多任务,4位宽或6位宽等低位宽的数据类型已经足够表示一个参数,后者相对前者可以降低网络存储量数倍之多。本发明提出的方法,也可以用于快速将高位宽的“老师”网络转化为低位宽的“学生”网络。
上述提到的多种操作都可以融合到同一个网络之中。
第二个用途用于拓展网络,主要是为了增加“学生”网络的容纳能力,将“老师”网络中知识快速迁移到“学生”网络之后,在此基础上继续调优,使得“学生”网络的精度或者泛化性比“老师”网络更优。
拓展网络可以从网络深度、网络宽度、卷积核的大小三个方面去进行:
1)拓展网络的深度的例子可参见图8,“学生”子网络可以在“老师”网络的基础上叠加多个残差单元,加深网络深度提高网络的表征能力,为后面的进一步调优做准备。
2)拓展网络宽度由于限制于输出特征图的通道数必须与“老师”网络相同,在扩展宽度之后要在后面接一层1x1核大小的卷积层用于维持输出通道数的不变。
3)拓展卷积核的大小可直接加大,例如“老师”子网络3x3核大小的卷积层可通过设计5x5核大小的卷积层作为“学生”子网络进行拟合逼近。多出的参数可用于后续的调优以及性能提升。
s3:优化目标为,在“老师”网络与“学生”网络输入相同的情况下,各个子网络的输出特征图尽可能相近。
这一步是本发明较为关键的一步,主要的思想是将原来端到端的任务切分为多个小任务,每个小任务由一个损失层负责,主要为学习不同尺度下特征信息的映射关系。切分为多个小任务的好处在于降低网络的寻优空间、加快“学生”网络的收敛。
以图9为例,左侧的虚线框为“老师”网络,右侧的虚线框为“学生”网络,根据上述提及的原则划分好子网络。在各个相对应的子网络间连接损失层,通过误差回传训练当前的“学生”子网络。需要注意的是,这里的误差只回传到当前子网络,不往上面的子网络回传。损失层可选择l1误差或欧式距离误差,一般选择l1误差效果会更好些。同时,每个子网络的输入为上一子网络的输出,这样的好处在于可弥补上一子网络学习产生的误差。
在训练完图9整个过程之后,可单独提取“学生”网络,在较低的学习率下进一步调优。训练的时候可以采用无标签数据集,因为“老师”网络潜在里已经给出了数据标签。当然,在后续调优时还是要用上带标签数据,因为调优过程已经脱离了“老师”网络。调优这一步根据精度要求可选择性地进行。当然,如果为了得到比“老师”网络精度和泛化性更好的“学生”网络(即拓展网络),则需要扩大训练集或者进行数据增强等操作。
本发明提供的一种在不同神经网络结构间进行知识迁移的方法,能快速地将原网络的“知识”迁移到新的网络,主要可用于拓展网络以及压缩加速原网络,在大部分的样例中,其训练速度和精度都要优于直接从零重新训练一个新的网络。本发明提供了一种新的“老师-学生”学习方法。在“老师”网络(即已训练完毕的神经网络)的帮助下,将原本一个端到端的学习任务(输入到输出的映射关系)分解为多个较为简单的子任务(由“老师”网络给出的多个中间特征信息间的映射关系),大大降低了“学生”网络(即将要进行知识迁移的目标网络)的参数寻优空间,使得“老师”模型的知识能快速迁移到“学生”模型上。这种方法可同时用于模型拓展以及模型压缩加速,相对于直接从零开始重新训练一个网络,在精度以及训练速度上都具有一定的优势。
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!