一种基于随机森林的停电投诉风险预测方法与流程
本发明涉及电力自动化领域,特别涉及一种基于随机森林的停电投诉风险预测方法。
背景技术:
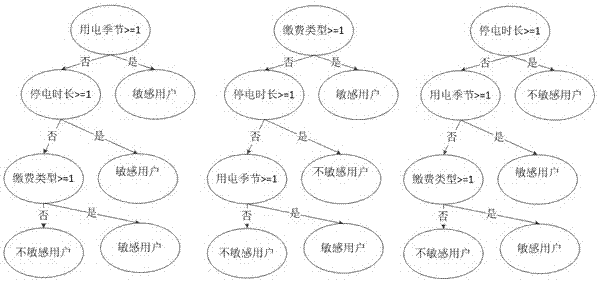
:随着社会经济的快速发展,企业和人民群众对供电可靠性的要求越来越高,但是停电情况还时有发生,如何在发生停电的情况下,准确地判别用户对停电状况的敏感程度,为采取不同的安抚和引导策略提供参考,减少客户来电风险,是困扰电力企业客服人员的难题。技术实现要素:本发明为解决上述问题,提供了一种基于随机森林的停电投诉风险预测方法,其特征在于,包括:步骤100:获取用户的用电信息,所述用电信息包括但不仅限于用户档案信息,停电相关信息与诉求工单信息,建立用户历史停电情况表,作为训练集;步骤200:制定规则对训练集中的用户进行类别标记;步骤300:对训练集进行预处理;步骤400:设定第一阈值,利用信息增益算法对训练集进行特征选择;步骤500:在特征选择后的训练集上执行随机森林算法,确定停电投诉风险模型;步骤600:输入待预测的用户停电情况表,作为测试集;步骤700:对测试集进行预处理;步骤800:设定第二阈值,利用信息熵算法对测试集进行特征选择;步骤900:预测用户的停电敏感类别与敏感度。本发明可以在发生停电的情况下,准确地判别用户对停电状况的敏感程度,为采取不同的安抚和引导策略提供参考,减少客户来电风险,树立了电力公司良好的社会形象。附图说明图1是本发明的判断停电投诉风险的流程图。图2是本发明的随机森林示意图。具体实施方式为使本发明的目的、技术方案和优点更加清楚,下面将对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。在本发明的描述中,需要理解的是,术语“纵向”、“横向”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。本发明实施例一公开了一种基于随机森林的停电投诉风险预测方法,其特征在于,包括:步骤100:获取用户的用电信息,所述用电信息包括但不仅限于用户档案信息,停电相关信息与诉求工单信息,建立用户历史停电情况表,作为训练集;步骤200:制定规则对训练集中的用户进行类别标记;对用户进行类别标记的方法为:其中type或为用户类别,为0时表示敏感用户,为1时表示不敏感用户,u.cpl表示投诉诉求量,u.sgt表示意见诉求量,u.rpr表示报修诉求量,u.clt表示咨询诉求量。步骤300:对训练集进行预处理;所述步骤300中进行预处理的方法进一步包括:步骤320:对训练集进行数据填充:在用电信息表中,对于分类型字段采用第一填充方式;其他数字值型字段采用第二填充方式,对于投诉诉求量和报修诉求量,采用第三填充方式;第一填充方式为默认值填充方式,对于整个用电信息输入表中,对于分类型字段,即行业分类,用电类型,电压等级,用户类别,行政区域,缴费类型等字段采用默认值填充方式,分别填充一个预先指定的默认类别;第二填充方式为平均值填充方式,其他数字值型字段,包括停电相关的字段,结合台区信息,采用平均值填充;第三填充方式为零值填充方式,投诉诉求量、报修诉求量等,采用零值填充法;步骤340:异常值处理:对于异常值所占的比例低于第一阈值的字段,直接删除包含异常值记录,其余的作为缺失值进行处理;步骤360:规范化:对于模型输入宽表中的所有数值型字段,进行区间规范化;其中normalization为特征原始值规范化处理结果,initial为特征原始值,min为该特征项的最小值,max为该特征项的最大值。步骤380:采用等宽法将具有连续属性的字段进行离散化,区间的个数由设计者指定;步骤400:设定第一阈值,利用信息增益算法对训练集进行特征选择;所述步骤400中计算信息增益的方法进一步包括:步骤420:根据公式(2)得出分类系统的熵;其中变量c是类别字段,而p(c)为每一个类别出现的概率,n为类别的总数;步骤440:针对各个特征,由公式(3)计算条件熵;其中t为某一特征,p(ci|t)表示当存在特征t时类别为ci的概率,为t不存在时类别为ci的概率,p(t)为t存在的概率,而为t不存在的概率;步骤460:计算特征t给系统带来的信息增益,根据公式(4)可计算得出;ig(t)=h(c)-h(c|t)公式(4)其中h(c)为系统原本的熵,h(c|t)为固定特征t后的条件熵;优选的一种选择方式为,用户指定选择数量为l个,那么选择信息增益最大的l个特征。特征选择的具体实施方式为:如果训练集的预处理后的用电信息输入表如下表所示:用电季节合同容量停电时长缴费类型敏感用户11101111110.5110000.510000000000110.5001010.51011000000.500010.50100.50.51100.5100000.5111其中用电季节字段中数值1表示夏季,0表示冬季,0.5表示春季或者秋季;合同容量字段中数值1表示合同电量在1000kw以上,0表示合同电量在100kw以下,0.5表示合同电量在100kw-1000kw之间;停电时长字段中1表示停电时间在24小时以上,0表示在24小时以内;缴费类型字段中数值0表示用户为预付费用户,1表示用户为后付费用户;敏感字段用户字段中数值1表示用户为敏感用户,0表示为不敏感用户。根据公式(2),可以得出分类系统的熵:h(敏感)=-(9/14)*log2(9/14)-(5/14)*log2(5/14)=0.94;根据公式(3),可以得出已知用电季节时用户敏感的条件熵h(敏感|季节):h(敏感|季节)=5/14*h(活动|夏)+(4/14)*h(活动|春秋)+(5/14)*h(活动|冬)=(5/14)*0.971+(4/14)*0+(5/14)*0.971=0.693;同理可得h(敏感|容量)=0.911;h(敏感|停电时长)=0.789;h(敏感|缴费类型)=0.892;其中h(敏感|容量)为已知合同容量时用户敏感的条件熵;h(敏感|停电时长)为已知合同容量时用户敏感的条件熵;h(敏感|缴费类型)为已知合同容量时用户敏感的条件熵;根据公式(4),可以得出各特征带来的信息增益:i(敏感|季节)=h(敏感)-h(敏感|季节)=0.94-0.693=0.247;i(敏感|容量)=h(敏感)-h(敏感|容量)=0.94-0.911=0.029;i(敏感|停电时长)=h(敏感)-h(敏感|停电时长)=0.94-0.789=0.151;i(敏感|缴费类型)=h(敏感)-h(敏感|缴费类型)=0.94-0.892=0.048;显然可见信息增益按从大到小拍列顺序为用电季节,停电时长,缴费类型和合同容量,如果用户指定特征选择为2个,那么就选择用电季节和停电时长;如果用户设定第一阈值为0.03,那么就选择用电季节、停电时长和缴费类型。步骤500:在特征选择后的训练集上执行随机森林算法,确定停电投诉风险模型;所述步骤500进一步包括:步骤510:对于给定的处理后的用电信息数据训练集s和其特征维数f,设定随机森林的相关参数:使用到的分类树的数量g,每棵树的最大深度d,每个节点使用到的特征数量f;并制定终止条件:节点上最少样本数s,节点上最少的信息增益m;步骤520:有放回地从s中随机抽取大小和s一样的训练集s(i),并将其作为根节点的样本,从根节点开始训练;步骤530:若当前节点满足终止条件,则设置当前节点为叶子节点,该叶子节点的预测输出为当前节点样本集合中数量最多的那一类c(j),定义概率p为c(j)占当前样本集的比例。然后继续训练其他节点。如果当前节点没有达到终止条件,则从f维特征中无放回地随机选取f维特征。利用这f维特征,寻找分类效果最好的一维特征k及其阈值th,当前节点上样本第k维特征小于th的样本被划分到左节点,其余的被划分到右节点。继续训练其他节点;步骤540:如果重复所有节点都训练过了或者被标记为叶子节点,那么转入步骤550;否则转入步骤520;步骤550:如果所有分类树都被训练过,那么结束;否则转入步骤520。构造随机森林的具体实施方式为:假设特征选择之后确定的特征为用电季节、停电时长和缴费类型,训练集如下表所示:用电季节停电时长缴费类型敏感用户11110.51000100对于给定的处理后的用电信息数据训练集s如上表,其特征维数f=3,设定随机森林的相关参数:使用到的分类树的数量g=3,每棵树的最大深度d=4,每个节点使用到的特征数量f=1;并制定终止条件:节点上最少样本数s=1,节点上最少的信息增益m=0.001;有放回地从s中随机抽取大小和s一样的训练集s(i),并将其作为根节点的样本,从根节点开始训练;分别取{(1,1,1,1),(0.5,1,0,0),(1,1,1,1)},{(0,1,0,0),(0.5,1,0,0),(1,1,1,1)},{(0,1,0,0),(0.5,1,0,0),(0,1,0,0)},按照所述步骤530~550的方法,可以得到如图2所示的三棵分类树,从而完成了森林的构造。步骤600:输入待预测的用户停电情况表,作为测试集;步骤700:对测试集进行预处理;步骤800:设定第二阈值,利用信息熵算法对测试集进行特征选择;步骤900:预测用户的停电敏感类别与敏感度;所述步骤900进一步包括:步骤910:获取需要预测的新的用电信息数据t;步骤920:将新的用电信息数据t代入到步骤500所生成的随机森林模型;步骤930:从第一棵树的根节点开始,比较新的用电信息数据t与当前节点的阈值th,如果t<th,那么进入左节点,如果t≥th,那么进入右节点,直到到达某个叶子节点,并输出预测值;步骤940:获取所有g棵树的预测值;步骤960:将g棵树中超过半数的树的预测类别,作为用户最终的预测类别;如果树的数量为g,预测用户为敏感用户的树的数量为g1,预测用户为不敏感用户的树的数量为g2,显然有g=g1+g2,那么确定用户类别的方法为:步骤980:把用户预测为敏感类别的树占全部树的比例,作为用户的敏感度;用户敏感度sen=g1/g。数据量偏最小二乘判别分析随机森林200.850.95500.880.921000.830.875000.780.8510000.790.91100000.770.881000000.740.89将本发明和偏最小二乘判别分析方法做对比,同样数据量下考察二者的准确率,由上表可以看出,偏最小二乘判别分析方法大致在0.8左右,并且随着数据的增加呈缓慢下降趋势;本发明方法准确率大致在0.9左右,并且随着数据的增加基本保持稳定。数据表明,本发明的方法准确率更高。在使用本发明的方法预测停电风险投诉之前,只能依靠人工查阅用户资料来判断的方法,每个用户大致要花两分钟左右的时间,使用本发明方法之后,可以批量导入数据分析用户敏感度,每个用户只需要花费50ms的时间,由此可见,本发明的方法极大的提高了分析效率,方便电网快捷的判断每个用户的停电投诉风险,从而采取相应措施,提高用户满意度。本发明实施例可以在发生停电的情况下,准确地判别用户对停电状况的敏感程度,为采取不同的安抚和引导策略提供参考,减少客户来电风险,树立了电力公司良好的社会形象。最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1