一种含大用户用水信息的城市供水管网节点需水量反演方法与流程
本发明属于城市供水管网节点需水量的预测方法,具体是一种基于scada数据和管网模型的节点流量反演方法。
背景技术:
管网模型中的管道糙率和节点流量参数是影响管网模拟精度的主要因素。一般情况下,管道糙率变化范围不大,随时间变化也非常稳定。而节点流量是随时间和空间变化非常大。传统的管网建模过程时节点流量的校验是非常复杂的过程,需要进行现场实测和提取典型用水模式。然而现场实测的典型用水模式往往不能准确反映所有节点的用水特征。模型校验时需要人工调整,节点数越多,复杂度越大,工作量越大,往往需要数月才能完成。即便经过校验后的模型,一般在半年之后误差变大,需重新校验,人力物力投入很大,该问题一直是管网水力建模的瓶颈。通过开展建立大规模管网节点流量的反演技术,可以解决超大规模管网模型的节点流量校验技术,摆脱繁琐的人工调试,实现给水管网的快速校验。
同时,随着供水企业对数据采集与监视控制系统(scada)的不断完善,一般大用户配有远传水表,可以及时获取大用户的需水量。而目前节点流量反演算法一般只考虑节点压力传感器与管道流量传感器提供的监测信息,反演结果容易偏离真实结果。由于一般大用户需水量占管网需水量比重高,部分地区大用户需水量占到整个供水管网的30%-50%,引入大用户需水量信息,将有利于提高现有节点需水量反演精度。
供水管网中的监测仪器随着使用年限的增加,部分监测仪器可能存在故障,或者是数据采集精度降低。通过对监测点数据进行同化处理,可以排查故障监测点,提高采集的数据可靠度。
本发明首先对供水管网中的监测数据进行同化处理,提高监测数据的可靠度。然后将大用户需水量信息引入到节点需水量反演算法中,进而缩小节点算法搜索空间,使得反演的结果更接近真实值。
技术实现要素:
本发明之目的在于克服现有技术的不足,在原有的节点流量反演算法基础上,对监测点数据进行预处理,提高数据可靠度。同时,引入大用户需水量信息,建立大用户灵敏度矩阵,提高节点流量反演精度。
为实现以上目的,本发明采取以下步骤:
对于某一供水管网,有nn个节点,np个管段,ns个水源。其中压力监测点数目为nh,流量监测点数目为nq,大用户节点数目为nm。
1.对压力监测信息进行数据同化,排除故障监测点,对正常监测点数据进行平滑处理。
(1)建立监测点相关系数矩阵。
对各监测点24h监测数据,进行相关性分析,获取相关系数矩阵r。
其中,rij表示监测点i与监测点j之间的相关系数。rii=1。
(2)剔除r矩阵的主对角线元素(rii=1),然后对每一行求平均值与标准差。对均值与标准差较小的监测点进行故障排查。
(3)采用移动平均法对监测点数据进行平滑处理,周期可依照监测点采样频率确定,一般可为20min-40min,不超过1h。
2.初始化节点需水量,进行管网平差计算,对比scada数据获取实测值与模型计算值的误差。
通过水厂计量数据获取供水管网总需水量q。根据管网拓扑结构计算各节点初始需水量权重wi,进而计算出节点初始需水量。
qi=wiq
式中,q为管网总需水量,qi为i节点初始化需水量,li为i节点相连的管段长度,l为管网管段总长度。
然后使用epanet进行管网平差计算,获取监测仪器所在节点的模型计算值。
3.计算当前需水量下的水源、压力、流量以及大用户监测点的灵敏度矩阵,建立线性方程组。通过求解线性方程组,获取节点需水量迭代步长,更新节点需水量;
(1)灵敏度矩阵
根据水力学基本方程,可得
其中,
考虑管网总需水量不变,同时对该方程两边进行差分可得:
σδqn=0
上述方程组即节点需水量反演线性方程组,第一项为压力灵敏度方程组;第二项为管段流量灵敏度方程组;第三项为水源出水量灵敏度方程组,第四项为大用户灵敏度方程组。方程组矩阵形式如下:
该方程组行数为nh+nq+ns+m。待求向量为δqn,共nn-nm个未知数。一般而言nh+nq+ns+m<nn-nm。故此方程组的系数矩阵为奇异矩阵。通过求解该奇异矩阵的广义逆矩阵,进而求得δqn。然后通过δqn对节点需水量qn进行迭代,即:qn+1=qn+δqn
然后将qn+1作为第n+1迭代初始条件,进行新的迭代。
4.计算当前实测值与模型计算值的误差,当误差小于允许值时,终止迭代。
本发明属于供水管网节点需水量的反演方法。本方法通过引入供水管网大用户需水量信息,提高节点需水量反演精度,为供水管网建模,压力管理等提供科学依据。供水管网中的监测仪器随着使用年限的增加,部分监测仪器可能存在故障,或者是数据采集精度降低。通过对监测点数据进行同化处理,可以排查故障监测点,提高采集的数据可靠度。本发明首先对供水管网中的监测数据进行同化处理,提高监测数据的可靠度。然后将大用户需水量信息引入到节点需水量反演算法中,进而缩小节点算法搜索空间,使得反演的结果更接近真实值。
附图说明:
图1为j市供水管网图;
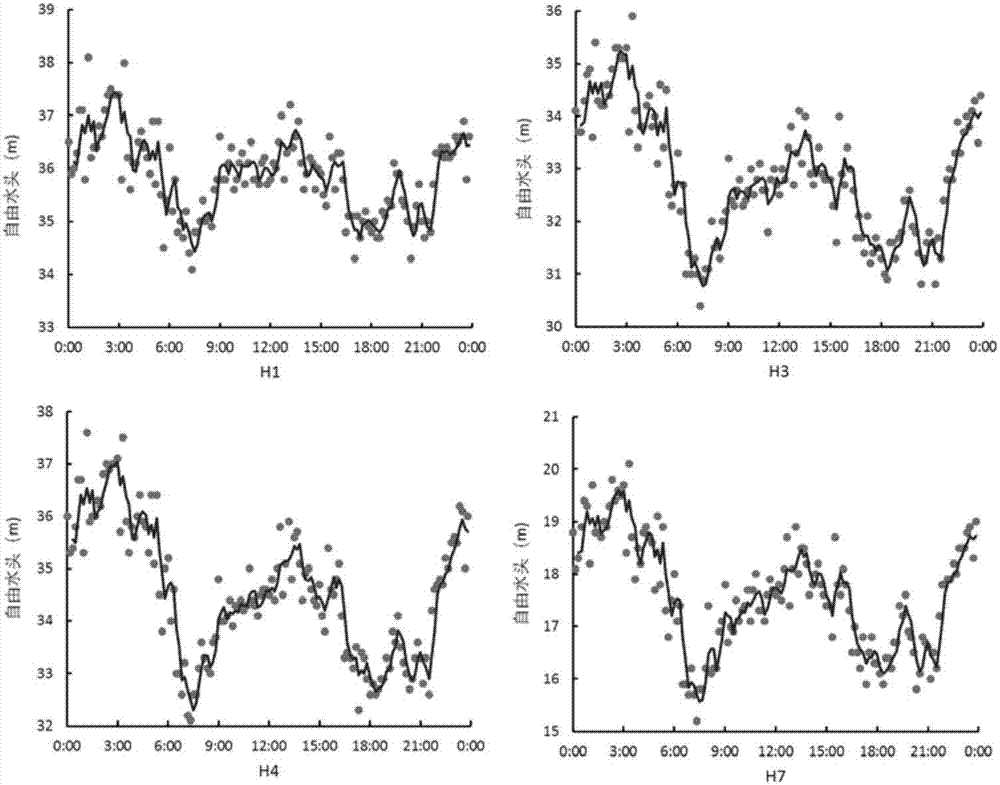
图2部分压力监测点24小时变化图;
图3为j市不同大用户需水量占比情况下的反演误差图。
具体实施方式
本发明的目的是提供一个引入大用户节点需水量的节点需水量反演算法。通过对监测点数据进行预处理,提高了数据可靠度。通过构建含大用户的节点需水量反演灵敏度矩阵,缩小了变量的搜索空间,提高了节点需水量反演精度。该发明为供水管网初步建模、压力管理和运营调控提供技术支撑。下面结合附图,对本发明具体实施方式作进一步详细描述。
如图1所示,j市共有水源3个,需水节点491个,管段640个,管段总长433.52千米,有部分压力监测点,水厂出水量已知。具体步骤如下:
步骤1:对压力监测信息进行数据同化,排除故障监测点,对正常监测点数据进行平滑处理。
表1给出了部分监测点24h压力日报表,表2给出了其相关性矩阵,表3给出了节点相关系数的均值与标准差。
表1部分压力监测点24h日报表(m)
表中h1-h11为监测点编号
表2部分压力监测点相关性矩阵
表3部分压力监测数据相关性均值与标准差
从表3中可以看出,h2、h5、h6、h8、h10、h11号监测点相关性均值较低。节点2相关性均值与标准差均较小,说明其与所有节点相关性均较低,为疑似故障点。节点h5、h6、h8、h10、h11,标准差较大,说明这些监测点相关性系数较为离散。从表2中可以看出,节点h5、h6、h8之间相关性高,这三个节点出现同步调故障的概率较低,因此不是故障点。节点h10、h11相关性较高,这两个节点出现同步调故障的概率较低,因此也不是故障点。
综上,h2号监测点为疑似故障点,经现场确认,h2号监测点确实为故障点。
在排除故障监测点后,采用移动平均法对监测点数据进行平滑处理,周期为30min。图2给出了部分压力监测点平滑处理后的24h压力变化曲线。
步骤2:初始化需水量,进行管网平差,对比scada数据获取平差结果的误差值。
选取7:00-7:30作为反演工况。以该时段水源实测数据作为总需水量,通过调用epanet工具箱函数,读取各节点相连的管段长度,读取总管段长度,计算各节点需水量初始化权重,初始化节点需水量。表4给出了三个节点的初始化需水量:
表4节点初始化需水量
管网总需水量16822cmh,管段总长度433520m
获取节点需水量后,调用epanet工具箱函数,进行水力平差计算。计算监测点实测值与模型计算值的误差。表5给出了部分监测点的误差:
表5部分监测点误差计算
由表5可知线性方程组右侧误差矩阵如下:
步骤3:计算当前需水量下的水源、压力、流量以及大用户监测点的灵敏度矩阵,建立线性方程组。通过求解线性方程组,获取节点需水量迭代步长,更新节点需水量。
由epanet工具箱读取管网关联矩阵
ash=(a21a11a12)-1
asq=a11a12ash
构建节点流量反演线性方程组:
通过求解上述方程组,将解得的δqn用于更新节点需水量。表6给出了经过一次迭代部分节点需水量调整过程。
表6部分节点需水量调整
步骤4:计算当前监测点实测值与模型计算值的误差,当误差小于允许值时,终止迭代。否则,将更新后的节点需水量qn+1用于下一次迭代。直至监测点误差满足终止准则。
图3给出了不同监测点数目下,所有节点压力相对误差平均值随大用户需水量占比的变化情况。同样条件下,随着已知的大用户用水信息占比增加,管网节点用水量反演精度得到有效提高。尤其是当管网其他监测点数目不是很充足的情况下,有效利用大用户数据对于反演精度的提高更加明显。
- 还没有人留言评论。精彩留言会获得点赞!